Tillämpa många-till-många-relationer i Power BI Desktop
Med relationer med kardinaliteten många-till-många i Power BI Desktop kan du ansluta tabeller som använder kardinaliteten många-till-många. Du kan enklare och intuitivt skapa datamodeller som innehåller två eller flera datakällor. Relationer med kardinaliteten många-till-många är en del av de större funktionerna för sammansatta modeller i Power BI Desktop. Mer information om sammansatta modeller finns i Använda sammansatta modeller i Power BI Desktop
Vad en relation med kardinaliteten många-till-många löser
Innan relationer med kardinaliteten många-till-många blev tillgängliga definierades relationen mellan två tabeller i Power BI. Minst en av de tabellkolumner som ingår i relationen måste innehålla unika värden. Men ofta innehöll inga kolumner unika värden.
Två tabeller kan till exempel ha haft en kolumn med namnet CountryRegion. Värdena för CountryRegion var dock inte unika i någon av tabellerna. För att ansluta till sådana tabeller var du tvungen att skapa en lösning. En lösning kan vara att introducera extra tabeller med de unika värden som behövs. Med relationer med kardinaliteten många-till-många kan du ansluta sådana tabeller direkt, om du använder en relation med kardinaliteten många-till-många.
Använda relationer med kardinaliteten många-till-många
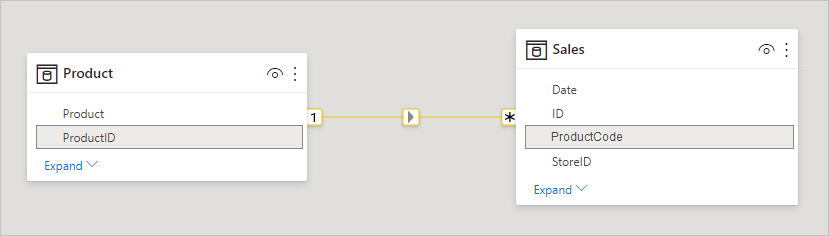
När du definierar en relation mellan två tabeller i Power BI måste du definiera kardinaliteten för relationen. Relationen mellan ProductSales och Product – med hjälp av kolumnerna ProductSales[ProductCode] och Product[ProductCode]– skulle till exempel definieras som Många-1. Vi definierar relationen på det här sättet eftersom varje produkt har många försäljningar och kolumnen i tabellen Produkt (ProductCode) är unik. När du definierar en relations kardinalitet som Många-1, 1-Många eller 1-1 verifierar Power BI den, så kardinaliteten som du väljer matchar faktiska data.
Ta till exempel en titt på den enkla modellen i den här bilden:
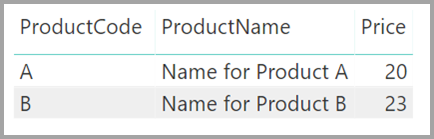
Anta nu att tabellen Produkt bara visar två rader, som du ser:
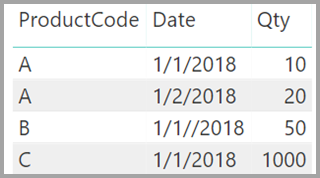
Tänk dig också att tabellen Sales bara har fyra rader, inklusive en rad för en produkt C. På grund av ett referensintegritetsfel finns inte raden produkt C i tabellen Produkt .
ProductName och Price (från tabellen Produkt) tillsammans med den totala kvantiteten för varje produkt (från tabellen ProductSales) visas enligt följande:
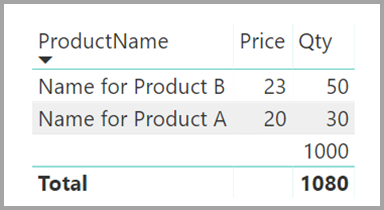
Som du ser i föregående bild associeras en tom ProductName-rad med försäljning för produkt C. Den här tomma raden står för följande överväganden:
Alla rader i tabellen ProductSales där det inte finns någon motsvarande rad i tabellen Produkt . Det finns ett referensintegritetsproblem, som vi ser för produkt C i det här exemplet.
Alla rader i tabellen ProductSales där sekundärnyckelkolumnen är null.
Av dessa skäl står den tomma raden i båda fallen för försäljning där ProductName och Price är okända.
Ibland är tabellerna kopplade till två kolumner, men ingen av kolumnerna är unika. Tänk till exempel på följande två tabeller:
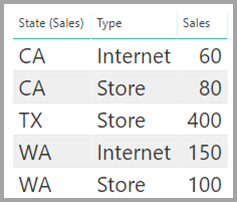
Tabellen Försäljning visar försäljningsdata efter delstat, och varje rad innehåller försäljningsbeloppet för typen av försäljning i det tillståndet. Tillstånden omfattar CA, WA och TX.
Tabellen CityData visar data om städer, inklusive befolkning och delstat (till exempel CA, WA och New York).
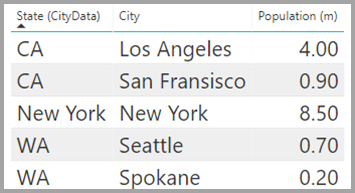
En kolumn för Tillstånd finns nu i båda tabellerna. Det är rimligt att vilja rapportera både den totala försäljningen per delstat och den totala populationen i varje delstat. Det finns dock ett problem: kolumnen State är inte unik i någon av tabellerna.
Föregående lösning
Innan versionen av Power BI Desktop i juli 2018 kunde du inte skapa en direkt relation mellan dessa tabeller. En vanlig lösning var att:
Skapa en tredje tabell som endast innehåller de unika tillstånds-ID:na. Tabellen kan vara något av följande:
- En beräknad tabell (definierad med hjälp av dataanalysuttryck [DAX]).
- En tabell som baseras på en fråga som definieras i Power Query-redigeraren, som kan visa de unika ID:t som hämtats från en av tabellerna.
- Den kombinerade fullständiga uppsättningen.
Relatera sedan de två ursprungliga tabellerna till den nya tabellen med hjälp av vanliga Många-1-relationer .
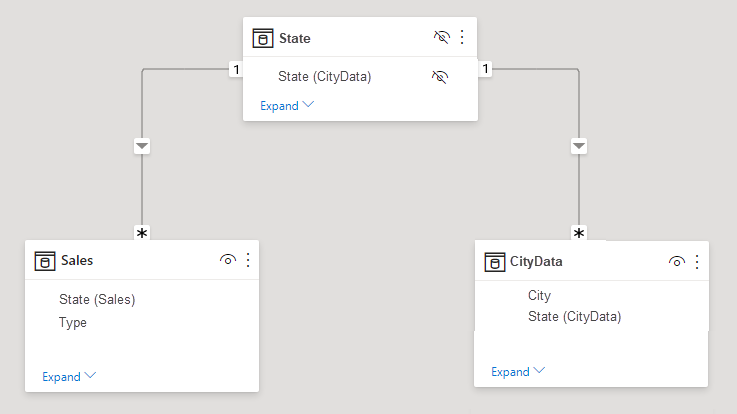
Du kan lämna lösningstabellen synlig. Eller så kanske du döljer den lösningstabellen så att den inte visas i listan Fält . Om du döljer tabellen skulle många-1-relationerna vanligtvis vara inställda på att filtrera i båda riktningarna, och du kan använda fältet Tillstånd från någon av tabellerna. Den senare korsfiltreringen skulle spridas till den andra tabellen. Den metoden visas i följande bild:
Ett visuellt objekt som visar Delstat (från tabellen CityData), tillsammans med total befolkning och total försäljning, visas sedan på följande sätt:
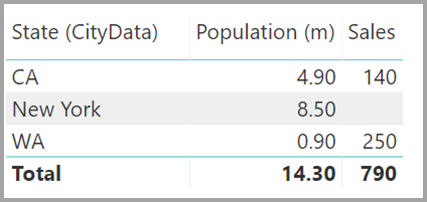
Kommentar
Eftersom tillståndet från tabellen CityData används i den här lösningen är det bara delstaterna i tabellen som visas, så TX utesluts. Till skillnad från många-1-relationer , medan den totala raden innehåller all försäljning (inklusive de för TX), innehåller informationen inte en tom rad som täcker sådana felmatchade rader. På samma sätt skulle ingen tom rad täcka Försäljning där det finns ett null-värde för staten.
Anta att du också lägger till Stad i det visuella objektet. Även om populationen per stad är känd upprepar den försäljning som visas för Stad bara försäljningen för motsvarande delstat. Det här scenariot inträffar normalt när kolumngruppering inte har något samband med något aggregerat mått, som du ser här:
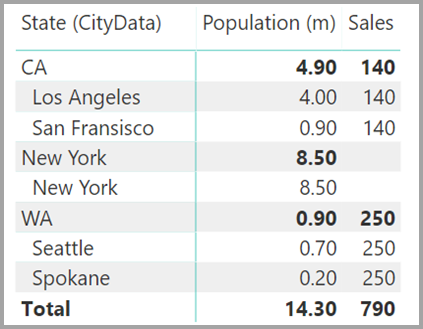
Anta att du definierar den nya tabellen Försäljning som en kombination av alla delstater här, och vi gör den synlig i listan Fält . Samma visuella objekt skulle visa tillstånd (i den nya tabellen), den totala populationen och den totala försäljningen:
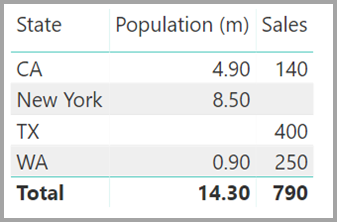
Som du ser skulle TX – med försäljningsdata men okända befolkningsdata – och New York – med kända befolkningsdata men inga försäljningsdata – inkluderas. Den här lösningen är inte optimal och har många problem. För relationer med kardinaliteten många-till-många åtgärdas de resulterande problemen, enligt beskrivningen i nästa avsnitt.
Mer information om hur du implementerar den här lösningen finns i Vägledning för många-till-många-relationer.
Använd en relation med kardinaliteten många-till-många i stället för lösningen
Du kan direkt relatera tabeller, till exempel de som vi beskrev tidigare, utan att behöva använda liknande lösningar. Nu är det möjligt att ange relationens kardinalitet till många-till-många. Den här inställningen anger att ingen av tabellerna innehåller unika värden. För sådana relationer kan du fortfarande styra vilken tabell som filtrerar den andra tabellen. Eller så kan du använda dubbelriktad filtrering, där varje tabell filtrerar den andra.
I Power BI Desktop är kardinaliteten som standard många-till-många när den fastställer att ingen av tabellerna innehåller unika värden för relationskolumnerna. I sådana fall bekräftar ett varningsmeddelande att du vill ange en relation och att ändringen inte är den oavsiktliga effekten av ett dataproblem.
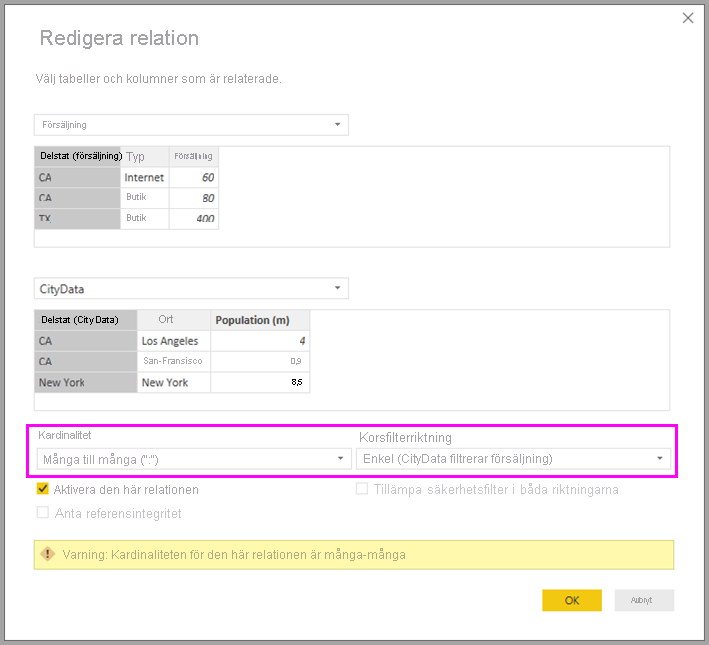
När du till exempel skapar en relation direkt mellan CityData och Sales – där filter ska flöda från CityData till Försäljning – visar Power BI Desktop dialogrutan Redigera relation :
Den resulterande relationsvyn skulle sedan visa den direkta, många-till-många-relationen mellan de två tabellerna. Tabellernas utseende i listan Fält och deras senare beteende när de visuella objekten skapas liknar när vi tillämpade lösningen. I lösningen visas inte den extra tabell som visar distinkta tillståndsdata. Som tidigare beskrivits visas ett visuellt objekt som visar data för delstat, population och försäljning :
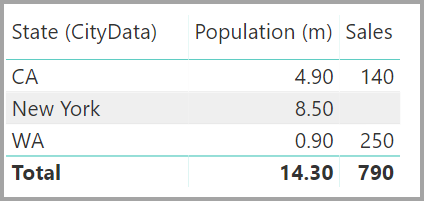
De största skillnaderna mellan relationer med kardinaliteten många-till-många och de mer typiska Många-1-relationerna är följande:
Värdena som visas innehåller inte en tom rad som står för felmatchade rader i den andra tabellen. Värdena tar inte heller hänsyn till rader där kolumnen som används i relationen i den andra tabellen är null.
Du kan inte använda
RELATED()funktionen eftersom mer än en rad kan vara relaterad.ALL()Om du använder funktionen i en tabell tas inte filter som tillämpas på andra relaterade tabeller av en många-till-många-relation bort. I föregående exempel skulle ett mått som definieras som det visas här inte ta bort filter på kolumner i den relaterade CityData-tabellen:![Skärmbild av ett skriptexempel. Exemplet är Sales total = Calculate(Sum('Sales'[Sales]), All('Sales')).](media/desktop-many-to-many-relationships/many-to-many-relationships_13.png)
Ett visuellt objekt som visar data för delstat, försäljning och försäljning totalt skulle resultera i den här bilden:
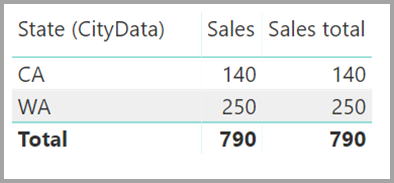
Med föregående skillnader i åtanke kontrollerar du att de beräkningar som använder ALL(<Table>), till exempel % av totalsumman, returnerar de avsedda resultaten.
Beaktanden och begränsningar
Det finns några begränsningar för den här versionen av relationer med kardinaliteten många-till-många och sammansatta modeller.
Följande Live Connect-källor (flerdimensionella) kan inte användas med sammansatta modeller:
- SAP HANA
- SAP Business Warehouse
- SQL Server Analysis Services
- Power BI-semantiska modeller
- Azure Analysis Services
När du ansluter till dessa flerdimensionella källor med DirectQuery kan du inte ansluta till en annan DirectQuery-källa eller kombinera den med importerade data.
De befintliga begränsningarna för att använda DirectQuery gäller fortfarande när du använder relationer med kardinaliteten många-till-många. Många begränsningar finns nu per tabell, beroende på tabellens lagringsläge. En beräknad kolumn i en importerad tabell kan till exempel referera till andra tabeller, men en beräknad kolumn i en DirectQuery-tabell kan fortfarande bara referera till kolumner i samma tabell. Andra begränsningar gäller för hela modellen om några tabeller i modellen är DirectQuery. Funktionerna QuickInsights och Q&A är till exempel inte tillgängliga för en modell om någon tabell i den har ett lagringsläge med DirectQuery.
Relaterat innehåll
Mer information om sammansatta modeller och DirectQuery finns i följande artiklar: