Översikt över beräkning av miljö-, sociala- och styrningsmått
Viktigt
Några eller alla dessa funktioner ingår som en del av en förhandsversion. Innehållet och funktionerna kan komma att ändras.
Du kan välj och beräkna de fördefinierade måtten med hjälp av de fördefinierade notebook-filer och pipelines som distribueras som en del av den här funktionen.
Obs
Du kan utöka notebook-filer och pipelines för att stödja anpassade mått. Mer information finns i Skapa anpassade mått.
Förutsättningar
Läs in de fördefinierade måttdefinitionerna i tabellerna MetricsDefinitions och MetricsLabels i ComputedESGMetrics_LH sjöhus genom att köra notebook-filen LoadDefinitionsForMetrics . Du behöver bara utföra det här steget en gång. Notebook-filer för måttberäkning extraherar måttets definition från dessa tabeller.
Du kan sedan fråga tabellen MetricsDefinitions för att visa måttdefinitionerna. För varje mätvärde kan du se måttets egenskaper:
- Namn på mått
- mått
- mått
- filter
- Hållbarhetsområde
Du kan också fråga tabellen MetricsLabels för att utforska måtten efter etiketter, till exempel Rapporteringsstandard och datapunkt för upplysning.
Du kan sedan utforska det fördefinierade måttbiblioteket för att fastställa den aggregerade datauppsättning som ska fyllas i för beräkning av respektive fördefinierade mått.
Se Generera aggregerade tabeller för att identifiera respektive ESG-datamodelltabeller och de attribut som ska fyllas i för att generera de aggregerade tabellerna.
Mata in, transformera och läsa in transformerade data i ESG-datamodelltabellerna i ProcessedESGData_LH sjöhus som distribueras som en del av ESG-dataegendomsfunktionen på samma arbetsyta.
Autentisera de fördefinierade semantiska modellerna (DatasetForMetricsMeasures och DatasetForMetricsDashboard) som används i måttberäkningen genom att skapa en anslutning. Du behöver bara utföra det här steget en gång.
Välj den DatasetForMetricsMeasures_DTST semantisk modell från sidan Hanterad kapacitet för att öppna den semantiska modellen. VäljInställningar på Arkiv-menyn . Du kan också öppna objektet från arbetsytans sida.
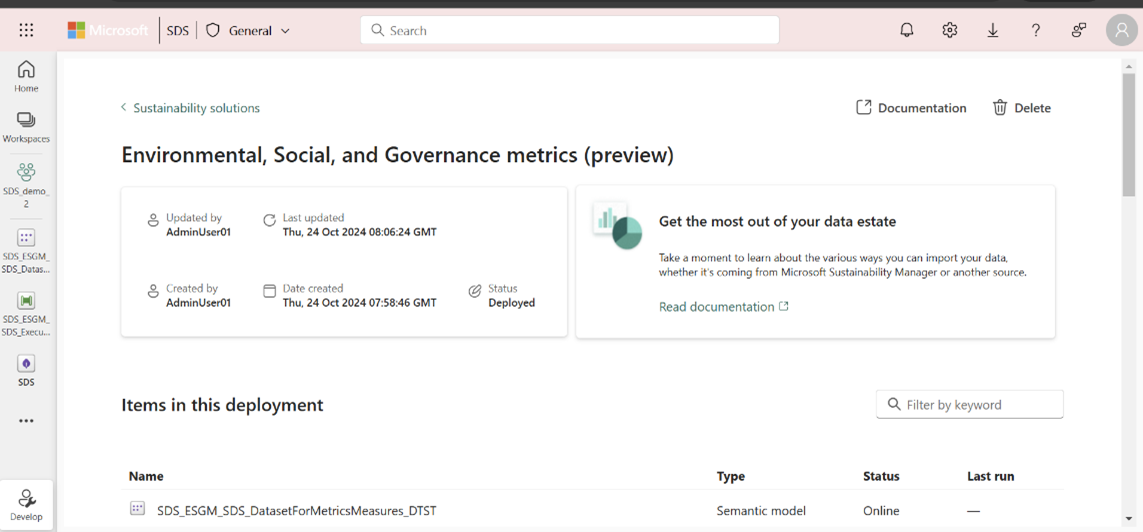
VäljGateway och molnanslutningar och välj sedan Skapa en ny anslutning i listrutan Molnanslutningar . En ny sidopanel för anslutning öppnas.
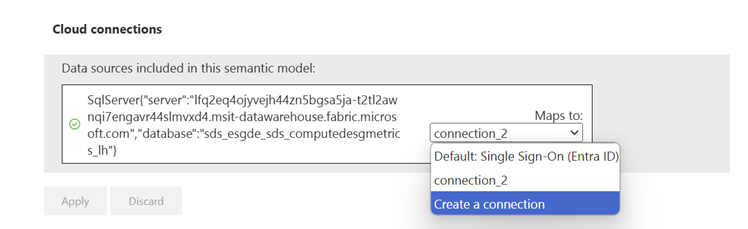
I panelen Ny anslutningssida anger du anslutningsnamnet, anger OAuth 2.0 som autentiseringsmetod, redigerar autentiseringsuppgifterna och välj Skapa.
Välj den skapade anslutningen i Avsnittet Gateway- och molnanslutningar .
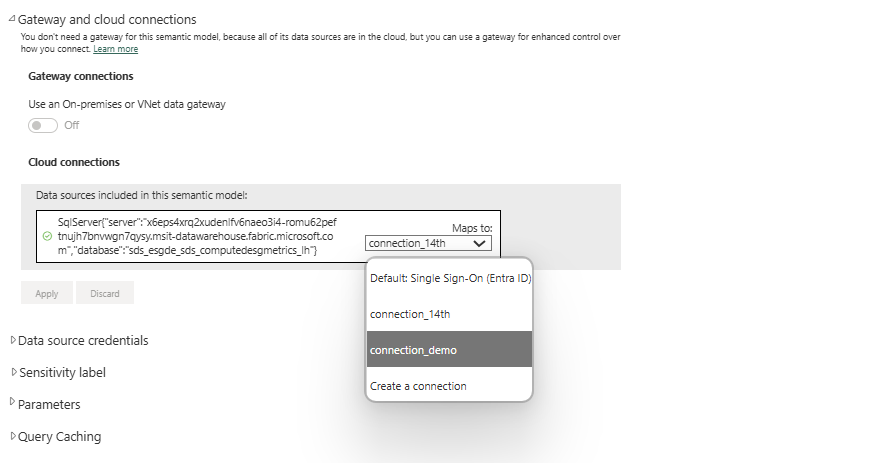
På samma sätt ställer du in en anslutning för den DatasetForMetricsDashboard_DTST semantiska modellen. Öppna den semantiska modellen från arbetsytans sida, Välj Inställningar på Arkiv-menyn , och följ sedan samma steg som du följde för DatasetForMetricsMeasures_DTST.
Använd Apache Spark körning 1.3 (Spark 3.5, Delta 3.2) för att köra fördefinierade notebook-filer och pipelines.

Om du använder den ExecuteComputationForMetrics_DTPL pipelinen för att beräkna mått måste du också utföra följande steg:
Skapa en anslutning för att autentisera aktiviteten Skapa aggregerade tabeller för pipelinen för att använda pipelinen GenerateAggregateForMetrics :
Öppna den ExecuteComputationForMetrics_DTPL pipelinen från sidan för den hanterade funktionen eller arbetsytan.
Välj den Skapa pipelineaktivitet för aggregerade tabeller .
Om du vill konfigurera en anslutning välj du Inställningar.
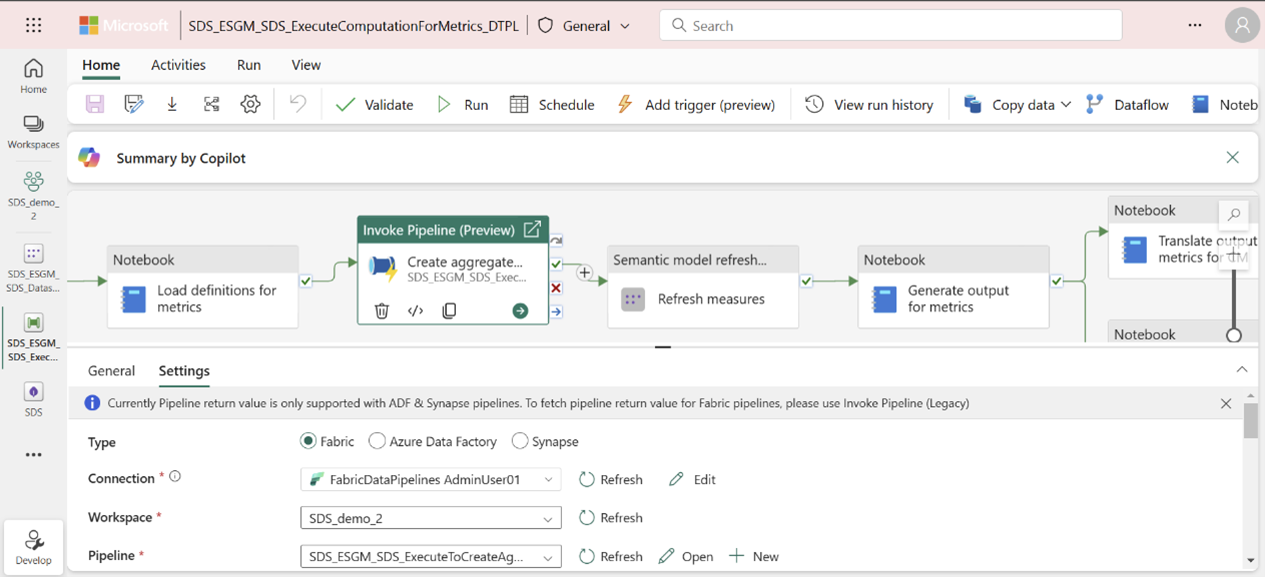
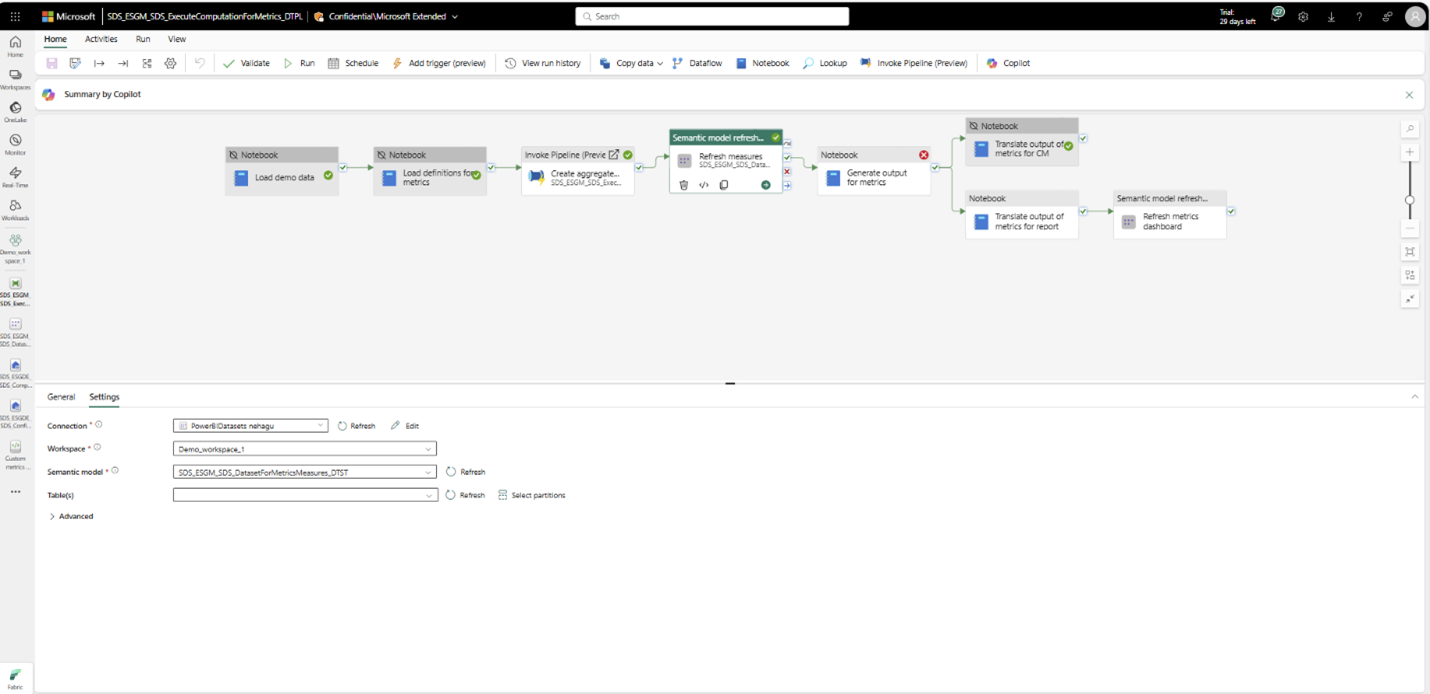
På samma sätt autentiserar du genom att konfigurera anslutningar för uppdateringsmått och uppdateringsmått för pipelinens instrumentpanelsaktiviteter:
Välj aktiviteten.
Välj Inställningar.
Välj en anslutning från Attribut för anslutning .
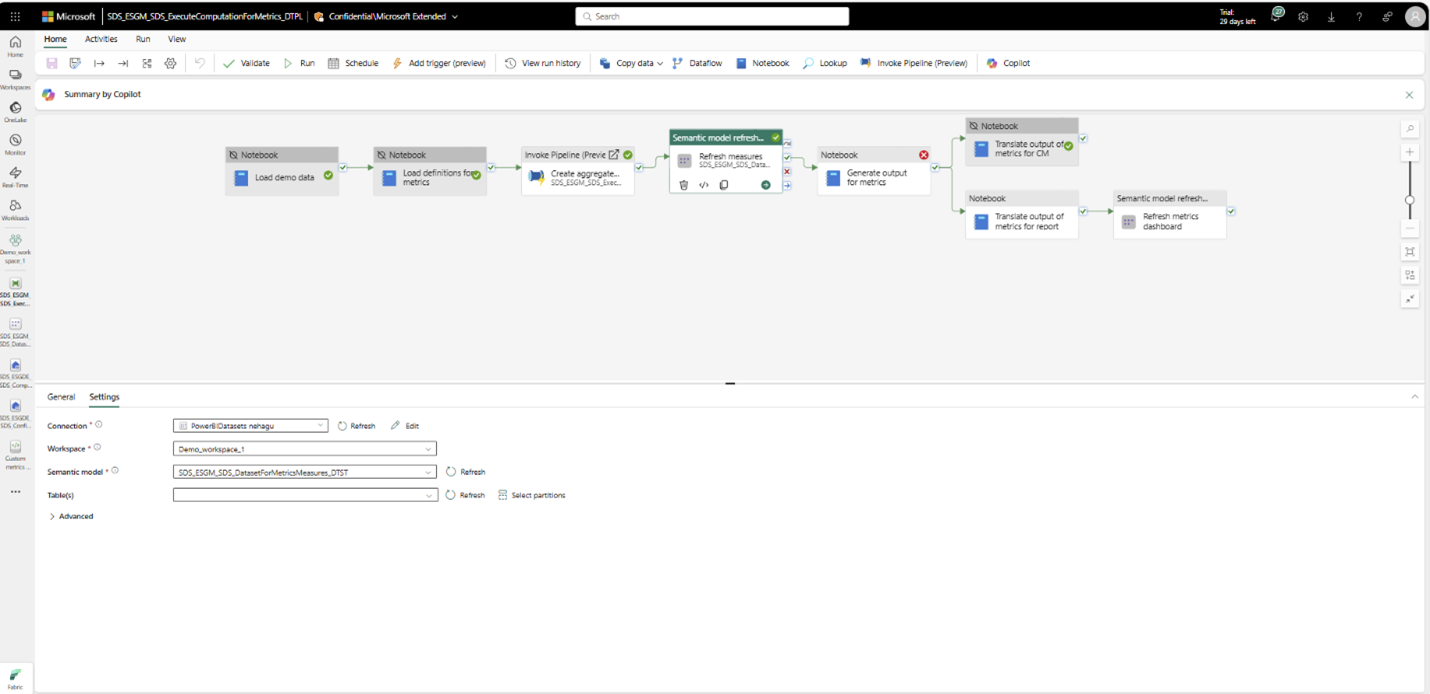


Utforska med demodata
Om du utforskar funktionen med demodata och bara vill visa utdata från alla mått kan du köra ExecuteComputationForMetrics_DTPL-pipelinen . Den här pipelinen ger en upplevelse från slutpunkt till slutpunkt från inläsning av demodata i ProcessedESGData_LH sjöhus för att beräkna de fördefinierade måtten. Om du vill veta mer om hur du ställer in demodata går du till Konfigurera demodata.
Innan du kör pipelinen kontrollerar du att du har följt stegen #3-5 i avsnittet Förutsättningar .
Skapa sedan en anslutning för att autentisera aktiviteten Skapa aggregerade tabeller för pipelinen för att använda GenerateAggregateForMetrics-pipelinen :
Öppna den ExecuteComputationForMetrics_DTPL pipelinen från sidan för den hanterade funktionen eller arbetsytan.
Välj den Skapa pipelineaktivitet för aggregerade tabeller och väljsedan Inställningar för att konfigurera en anslutning.
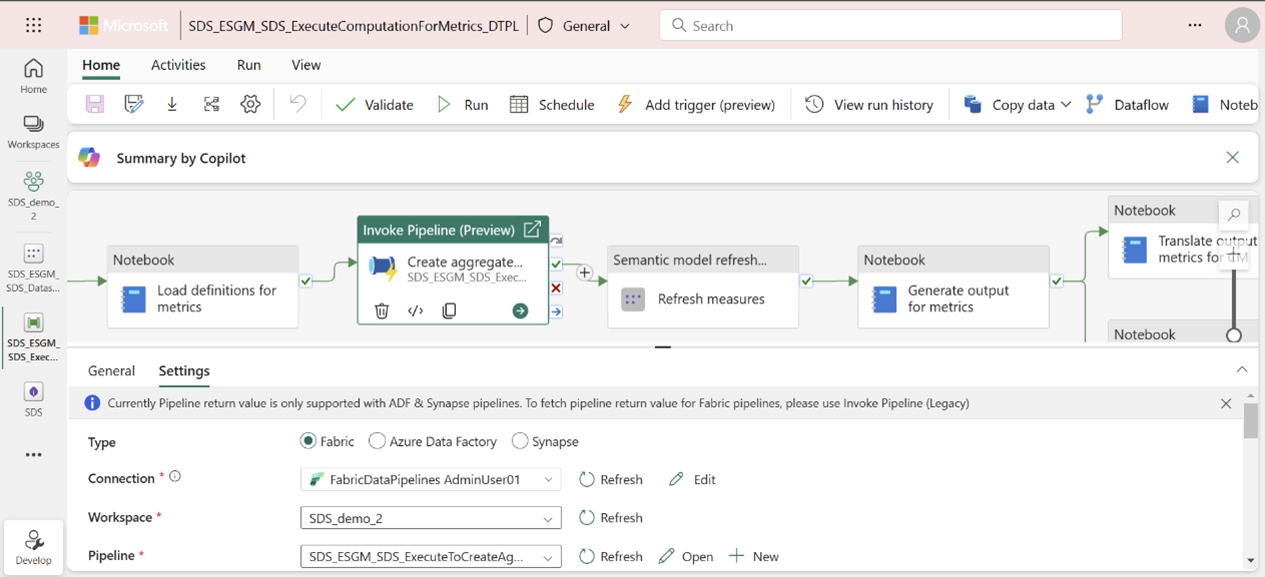
På samma sätt autentiserar du genom att konfigurera anslutningar för uppdateringsmått och uppdateringsmått för pipelinens instrumentpanelsaktiviteter. Välj aktiviteten, väljInställningar och välj sedan en anslutning från attributet Anslutning .
Obs
De här stegen för anslutningskonfiguration är en gång och är inte nödvändiga för efterföljande pipelinekörningar.

När du har slutfört de här stegen väljRun för att köra pipelinen. Du kan övervaka pipelinen genom att välja knappen Visa körningshistorik .
Den här pipelinen utför följande aktiviteter:
Läs in demodata: Läser in demodata som medföljer ESG-dataegendomsfunktionen i ProcessedESGData_LH sjöhus.
Obs
Om du mappade dina källdata i processedESGData sjöhus kan du inaktivera den här aktiviteten innan du kör pipelinen för beräkningsmått.
Läs in måttdefinitioner: Läser in de måttdefinitioner som finns i metrics_definitions_config.json till tabellen MetricsDefinitions i ComputedESGMetrics_LH. Den här tabellen används för att hämta måttenhetsinformation som beräkningslogik, måttnamn och hållbarhetsområde.
Obs
Den här aktiviteten behöver bara utföras en gång. När de fördefinierade måttdefinitionerna har lästs in kan du inaktivera den här pipelineaktiviteten för efterföljande pipelinekörningar, såvida inte måttdefinitionerna uppdateras i den metrics_definitions_config.json filen.
Uppdatera den semantiska modellen för mått genom att följa steg #2 i Generera aggregerade tabeller.
Översätt måttutdata för förbrukning av Efterlevnadshanteraren.
Översätt måttutdata för fördefinierad Power BI instrumentpanelsförbrukning.
Uppdatera den semantiska modellen för instrumentpanelen för mått.
Obs
Om du vill köra en specifik aktivitet i pipelinen kan du inaktivera de andra aktiviteterna. Mer information finns i Inaktivera en aktivitet.
Beräkna måttdata
Om du vill beräkna ESG-måtten följer du anvisningarna i följande artiklar:
