Generera aggregerade tabeller
Viktigt
Några eller alla dessa funktioner ingår som en del av en förhandsversion. Innehållet och funktionerna kan komma att ändras.
Aggregerade tabeller eller aggregerade datauppsättningar är avnormaliserade datauppsättningar som innehåller aggregerade mätvärden (till exempel CO2e-utsläpp, vattenanvändning eller genererat avfall) från tabellerna för ESG-datamodellen (Environmental, Social and Governance) för en omfattande uppsättning dimensioner, inklusive rapporteringsperiod. ESG-mått beräknas ovanpå dessa aggregerade tabeller.
Funktionen innehåller en uppsättning fördefinierade notebook-filer som du kan använda för att generera dessa aggregerade tabeller för beräkning av fördefinierade och anpassade mått. Notebook-filerna innehåller beräkningslogik för att generera dessa aggregerade tabeller.
| Namn på aggregerad tabell | Fördefinierad notebook-dator |
|---|---|
| UtsläppAggregerad | CreateAggregateForEmissionsMetrics_INTB |
| EmployeeDataAggregate (på engelska) | CreateAggregateForEmployeeMetrics_INTB |
| EmployeeEventsAggregate (på engelska) | CreateAggregateForEmployeeEventMetrics_INTB |
| IncidentDataAggregate (på engelska) | CreateAggregateForIncidentMetrics_INTB |
| NetRevenueAggregate (på engelska) | CreateAggregateForNetRevenueMetrics_INTB |
| PreCalculatedMetricsAggregate | CreateAggregateForPreCalculatedMetrics_INTB |
| ResourceInflowsAggregate (på engelska) | CreateAggregateForResourceInflowMetrics_INTB |
| ResourceOutflowsAggregate (på engelska) | CreateAggregateForResourceOutflowMetrics_INTB |
| HållbarhetInnehållResursInflödenAggregera | CreateAggregateForResourceInflowsSustainabilityContentMetrics_INTB |
| HållbarhetInnehållResursOutflowsAggregera | CreateAggregateForResourceOutflowsSustainabilityContentMetrics_INTB |
| WasteQuantityAggregate (WasteQuantityAggregate) | CreateAggregateForWasteMetrics_INTB |
| WaterStorageAggregate | CreateAggregateForWaterStorageMetrics_INTB |
| VattenUtnyttjandeAggregat | CreateAggregateForWaterUtilizationMetrics_INTB |
Generera aggregerade tabeller
Se det fördefinierade måttbiblioteket för att välj det mått som ska beräknas och ta reda på den aggregerade tabell som krävs för att genereras. Kör sedan motsvarande notebook-fil (från föregående tabell) separat eller kör den ExecuteToCreateAggregates_DTPL pipelinen genom att välja den aggregerade tabellen som ska genereras i pipelineparametern.
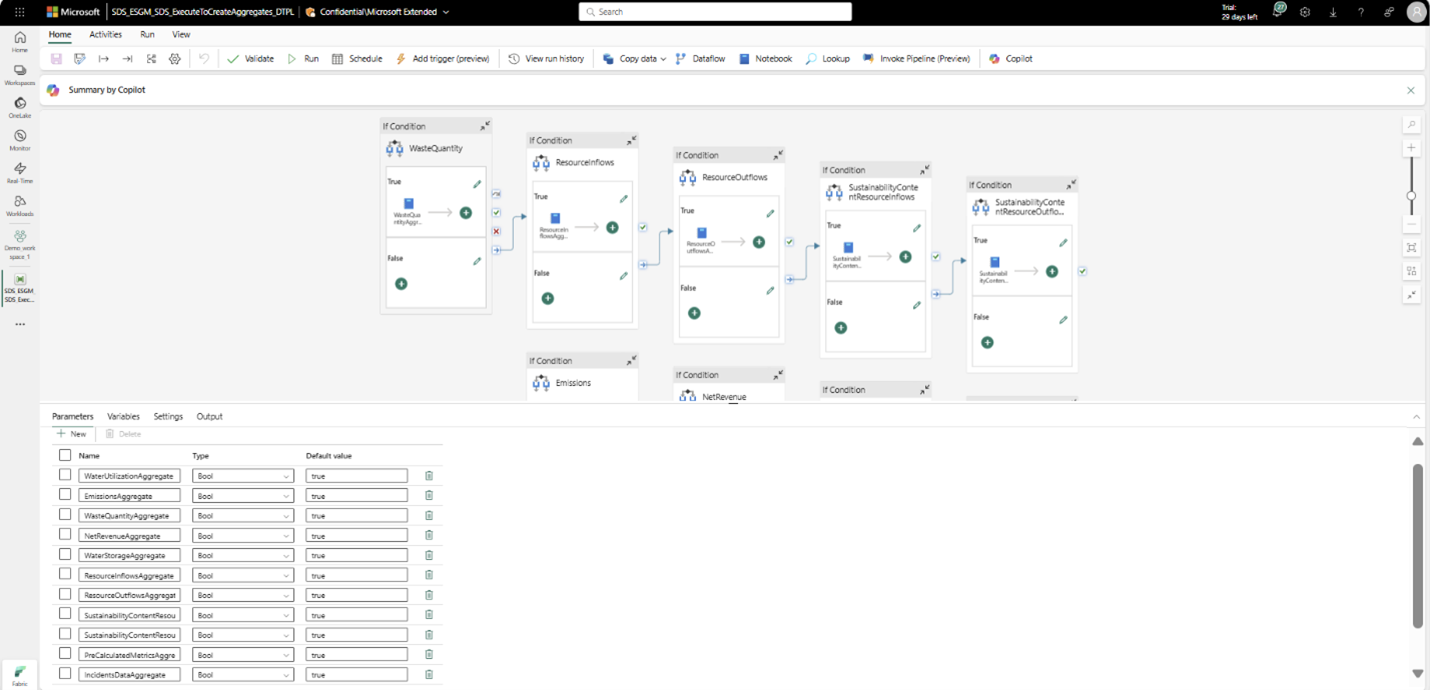
Obs
Som standard genererar pipelinen alla aggregerade tabeller eftersom parametrarna är inställda på True. Om du bara vill generera data för en specifik aggregerad tabell anger du värdet för alla återstående aggregerade tabeller som falskt.
När notebook-filen eller pipelinen körs korrekt ska den aggregerade tabellen genereras och lagras i ComputedESGMetrics sjöhus. Om den aggregerade tabellen redan finns skrivs den över.
Obs
Den här steg motsvarar aktiviteten Skapa aggregerade tabeller i den ExecuteComputationForMetrics_DTPL pipelinen . Den ExecuteToCreateAggregates_DTPL pipelinen anropas som en aktivitet i den här pipelinen. Det innebär att du också kan köra aktiviteten Skapa aggregerade tabeller för att generera de aggregerade tabellerna.
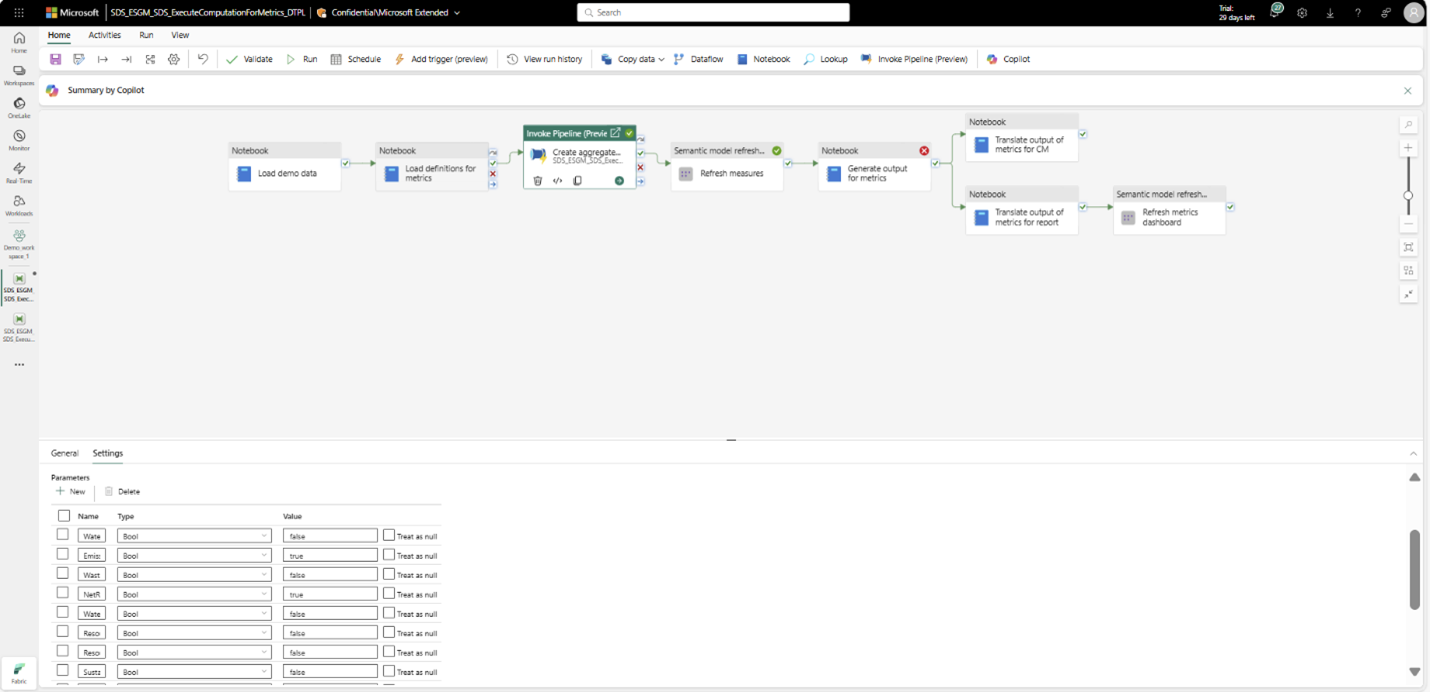
Uppdatera den semantiska modellen för mått (DatasetForMetricsMeasures_DTST) så att de senaste aggregerade tabelldata uppdateras i den semantiska modellen.
För den första uppdateringen måste du autentisera den semantiska modellen genom att skapa en anslutning. Mer information finns i Krav. Öppna sedan den DatasetForMetricsMeasures_DTST semantiska modellen från arbetsytans sida och Välj Uppdatera nu från menyn Uppdatera för att uppdatera den semantiska modellen.
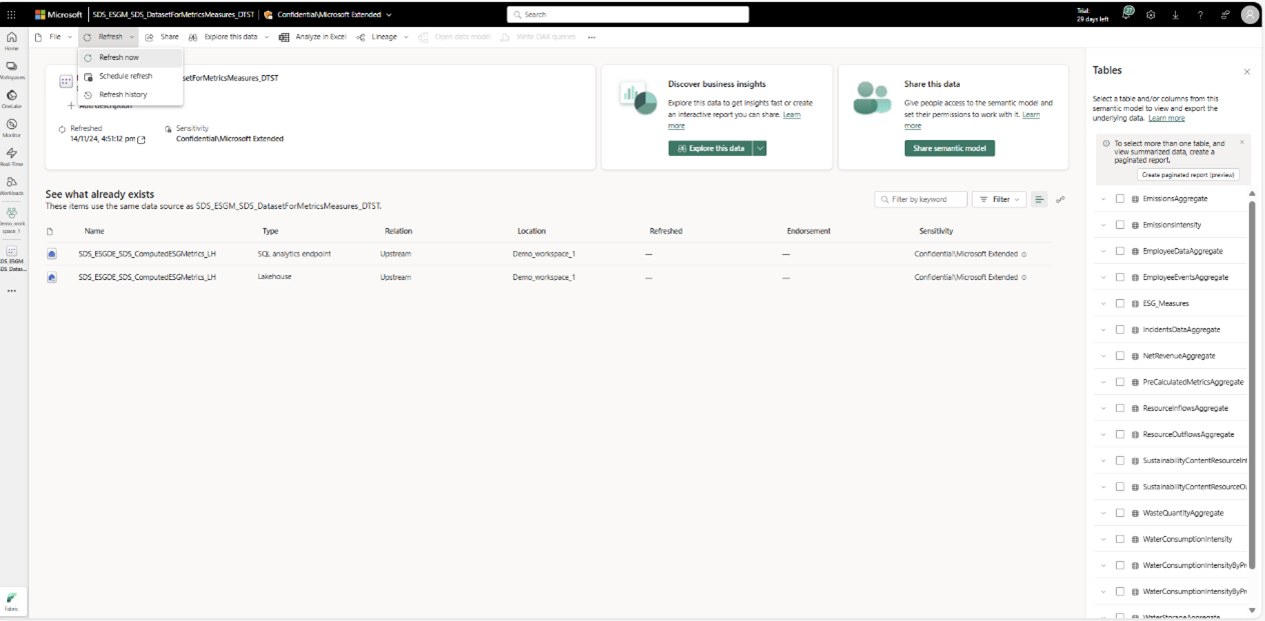
När uppdateringen är klar kan du välj uppdateringshistorik på menyn Uppdatera för att bekräfta uppdateringens status. Om det Dit finns några fel kan du hitta felinformationen i uppdateringshistoriken.
Den här steg motsvarar aktiviteten Uppdatera mått i ExecuteComputationForMetrics_DTPL-pipelinen . Du kan också köra den här aktiviteten för att uppdatera den semantiska modellen.
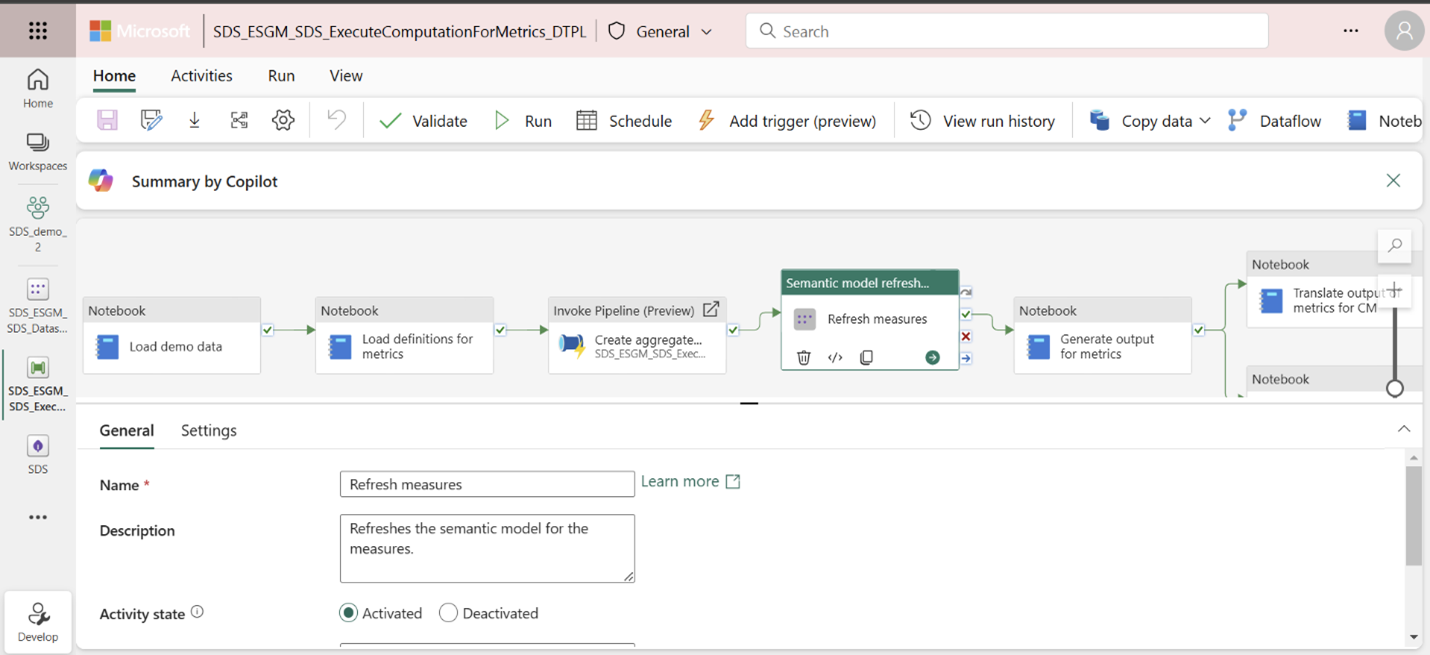
Om det är första gången du kör pipelinen måste du också konfigurera en anslutning för aktiviteten Uppdateringsmått för pipelinen . Mer information om det här steget finns i de krav som nämns i Utforska med demodata.




När de här stegen har körts bör den aggregerade tabellen visas under tabeller i ComputedESGMetrics_LH och den semantiska modellen bör innehålla uppdaterade data.
