Utforska data i din speglade databas med notebook-filer
Du kan utforska data som replikeras från din speglade databas med Spark-frågor i notebook-filer.
Notebook-filer är ett kraftfullt kodobjekt där du kan utveckla Apache Spark-jobb och maskininlärningsexperiment på dina data. Du kan använda notebook-filer i Fabric Lakehouse för att utforska dina speglade tabeller.
Förutsättningar
- Slutför självstudien för att skapa en speglad databas från källdatabasen.
- Självstudie: Konfigurera microsoft fabric-speglad databas för Azure Cosmos DB (förhandsversion)
- Självstudie: Konfigurera Microsoft Fabric-speglade databaser från Azure Databricks (förhandsversion)
- Självstudie: Konfigurera Microsoft Fabric-speglade databaser från Azure SQL Database
- Självstudie: Konfigurera Microsoft Fabric-speglade databaser från Azure SQL Managed Instance (förhandsversion)
- Självstudie: Konfigurera Microsoft Fabric-speglade databaser från Snowflake
Skapa en genväg
Du måste först skapa en genväg från dina speglade tabeller till Lakehouse och sedan skapa notebook-filer med Spark-frågor i Lakehouse.
Öppna Dataingenjör ing i Infrastrukturportalen.
Om du inte redan har skapat ett Lakehouse väljer du Lakehouse och skapar ett nytt Lakehouse genom att ge det ett namn.
Välj Hämta data –> Ny genväg.
Välj Microsoft OneLake.
Du kan se alla dina speglade databaser på arbetsytan Infrastruktur.
Välj den speglade databas som du vill lägga till i Lakehouse som en genväg.
Välj önskade tabeller från den speglade databasen.
Välj Nästa och sedan Skapa.
I Utforskaren kan du nu se valda tabelldata i Lakehouse.
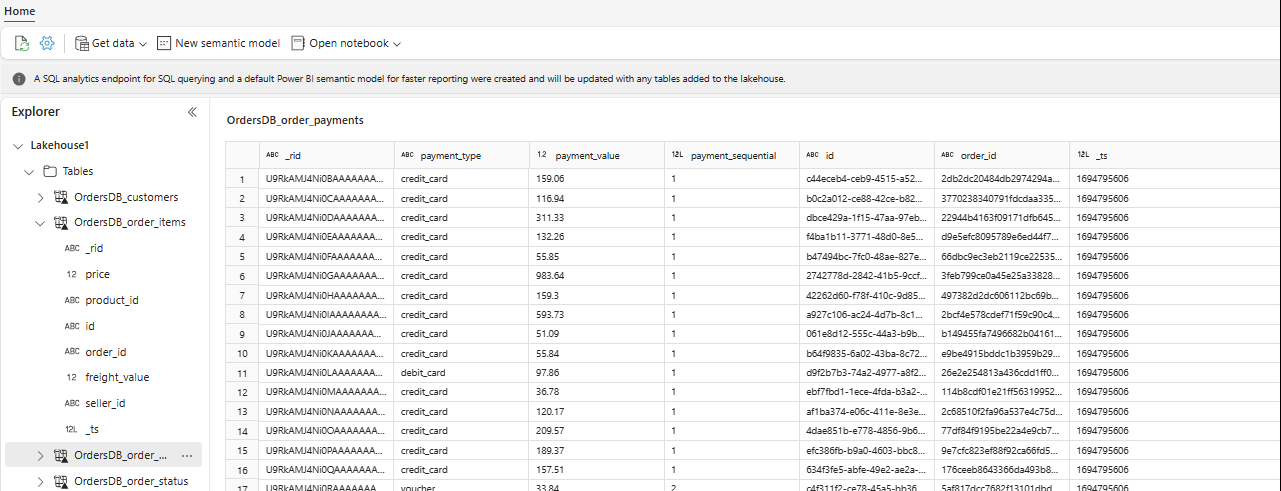
Dricks
Du kan lägga till andra data i Lakehouse direkt eller ta med genvägar som S3, ADLS Gen2. Du kan navigera till SQL-analysslutpunkten för Lakehouse och koppla data mellan alla dessa källor med speglade data sömlöst.
Om du vill utforska dessa data i Spark väljer du
...punkterna bredvid valfri tabell. Välj Ny notebook-fil eller befintlig anteckningsbok för att börja analysera.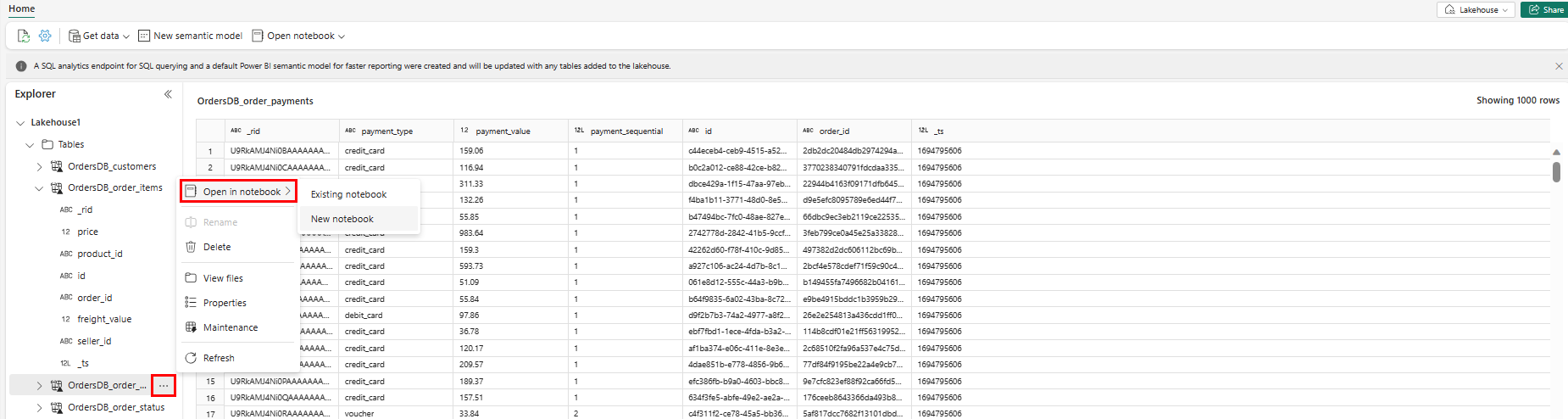
Notebook-filen öppnas automatiskt och dataramen läses in med en
SELECT ... LIMIT 1000Spark SQL-fråga.- Nya notebook-filer kan ta upp till två minuter att läsa in helt. Du kan undvika den här fördröjningen genom att använda en befintlig notebook-fil med en aktiv session.
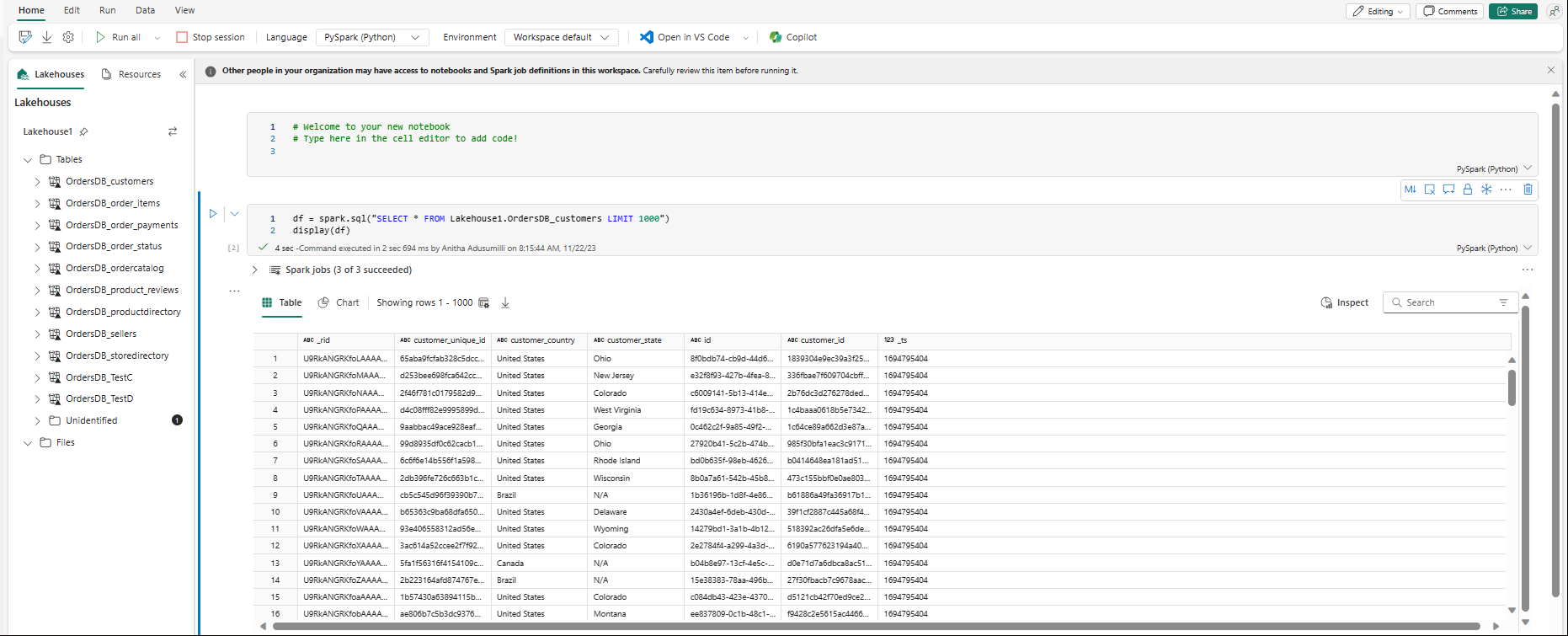
- Nya notebook-filer kan ta upp till två minuter att läsa in helt. Du kan undvika den här fördröjningen genom att använda en befintlig notebook-fil med en aktiv session.


