Självstudie: Konfigurera dbt för Fabric Data Warehouse
Gäller för:✅ Warehouse i Microsoft Fabric
Den här självstudien vägleder dig genom att konfigurera dbt och distribuera ditt första projekt till ett infrastrukturlager.
Introduktion
Dbt-ramverket (Data Build Tool) med öppen källkod förenklar datatransformeringen och analystekniken. Den fokuserar på SQL-baserade transformeringar i analysskiktet och behandlar SQL som kod. dbt stöder versionskontroll, modularisering, testning och dokumentation.
Dbt-adaptern för Microsoft Fabric kan användas för att skapa dbt-projekt, som sedan kan distribueras till ett Infrastrukturdatalager.
Du kan också ändra målplattformen för dbt-projektet genom att helt enkelt ändra adaptern, till exempel. Ett projekt som skapats för en dedikerad SQL-pool i Azure Synapse kan uppgraderas på några sekunder till ett Infrastrukturdatalager.
Krav för dbt-adaptern för Microsoft Fabric
Följ den här listan för att installera och konfigurera kraven för dbt:
Den senaste versionen av dbt-fabric-adaptern från PyPI-lagringsplatsen (Python Package Index) med .
pip install dbt-fabricpip install dbt-fabricKommentar
Genom att ändra
pip install dbt-fabrictillpip install dbt-synapseoch använda följande instruktioner kan du installera dbt-adaptern för synapse-dedikerad SQL-pool.Kontrollera att dbt-fabric och dess beroenden har installerats med hjälp
pip listav kommandot :pip listEn lång lista över paketen och de aktuella versionerna ska returneras från det här kommandot.
Om du inte redan har ett skapar du ett lager. Du kan använda utvärderingskapaciteten för den här övningen: registrera dig för den kostnadsfria utvärderingsversionen av Microsoft Fabric, skapa en arbetsyta och sedan skapa ett lager.
Kom igång med dbt-fabric-adapter
I den här självstudien används Visual Studio Code, men du kan använda önskat verktyg.
Klona jaffle_shop demo dbt-projektet på datorn.
- Du kan klona en lagringsplats med Visual Studio Codes inbyggda källkontroll.
- Du kan till exempel använda
git clonekommandot:
git clone https://github.com/dbt-labs/jaffle_shop.gitÖppna projektmappen
jaffle_shopi Visual Studio Code.
Du kan hoppa över registreringen om du redan har skapat ett lager.
Skapa en
profiles.yml-fil. Lägg till följande konfiguration iprofiles.yml. Den här filen konfigurerar anslutningen till ditt lager i Microsoft Fabric med hjälp av dbt-fabric-adaptern.config: partial_parse: true jaffle_shop: target: fabric-dev outputs: fabric-dev: authentication: CLI database: <put the database name here> driver: ODBC Driver 18 for SQL Server host: <enter your SQL analytics endpoint here> schema: dbo threads: 4 type: fabricKommentar
typeÄndra frånfabrictill försynapseatt växla databaskortet till Azure Synapse Analytics, om så önskas. Alla befintliga dbt-projekts dataplattform kan uppdateras genom att ändra databaskortet. Mer information finns i dbt-listan över dataplattformar som stöds.Autentisera dig själv till Azure i Visual Studio Code-terminalen.
- Kör
az logini Visual Studio Code-terminalen om du använder Azure CLI-autentisering. - För tjänstens huvudnamn eller annan Microsoft Entra-ID(tidigare Azure Active Directory)-autentisering i Microsoft Fabric, se dbt-konfiguration (Data Build Tool) och dbt-resurskonfigurationer. Mer information finns i Microsoft Entra-autentisering som ett alternativ till SQL-autentisering i Microsoft Fabric.
- Kör
Nu är du redo att testa anslutningen. Om du vill testa anslutningen till ditt lager kör du
dbt debugi Visual Studio Code-terminalen.dbt debug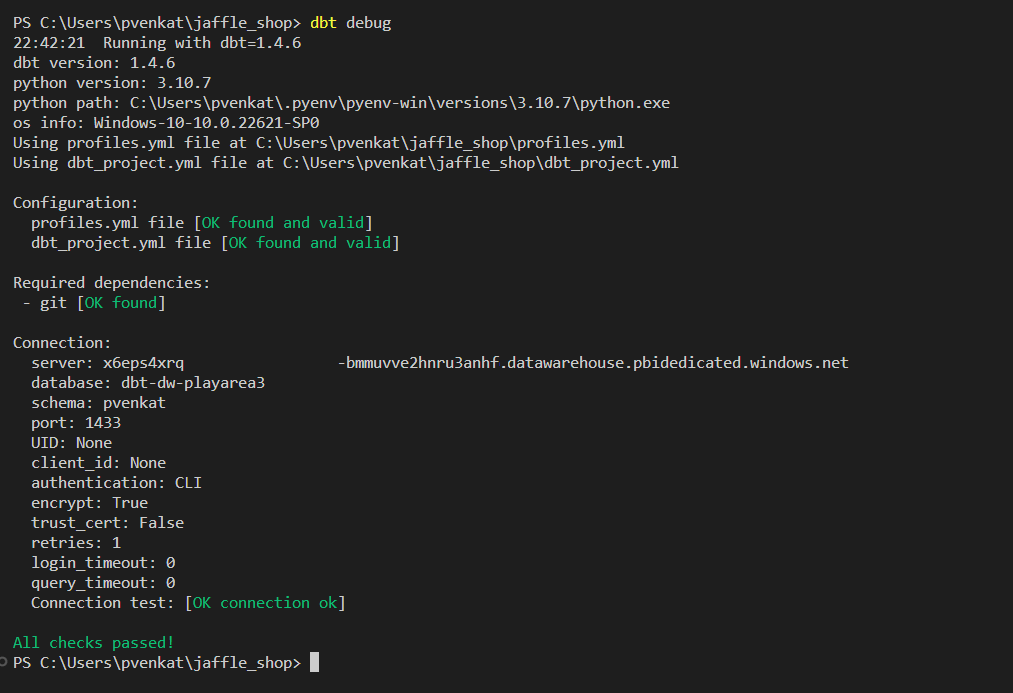
Alla kontroller skickas, vilket innebär att du kan ansluta ditt lager med hjälp av dbt-fabric-adaptern
jaffle_shopfrån dbt-projektet.Nu är det dags att testa om adaptern fungerar eller inte. Kör
dbt seedförst för att infoga exempeldata i lagret.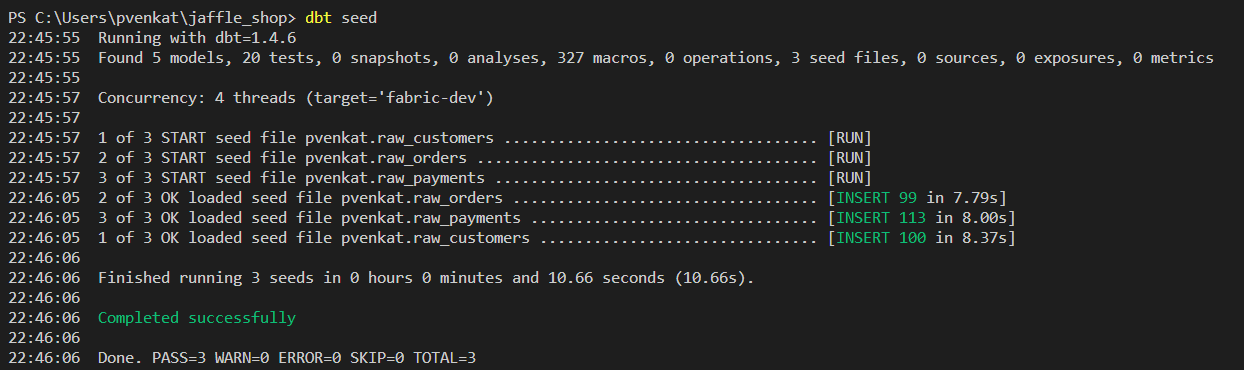
Kör
dbt runför att verifiera data mot vissa tester.dbt run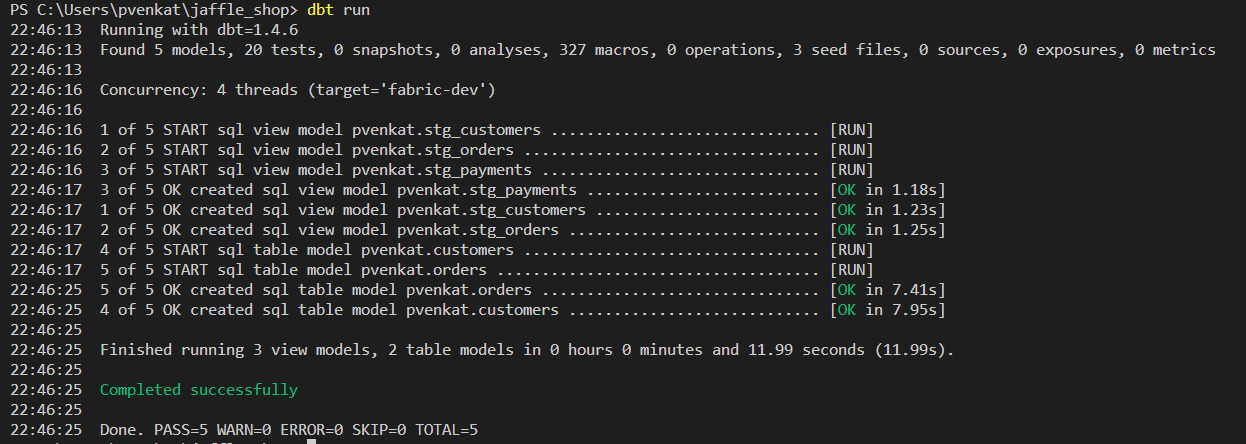
Kör
dbt testför att köra de modeller som definierats i demo dbt-projektet.dbt test




Nu har du distribuerat ett dbt-projekt till Fabric Data Warehouse.
Flytta mellan olika lager
Det är enkelt att flytta dbt-projektet mellan olika lager. Ett dbt-projekt på alla lager som stöds kan snabbt migreras med den här trestegsprocessen:
Installera det nya adaptern. Mer information och fullständiga installationsinstruktioner finns i dbt-kort.
Uppdatera egenskapen
typeiprofiles.ymlfilen.Bygga projektet.
dbt i Fabric Data Factory
När dbt är integrerat med Apache Airflow, ett populärt arbetsflödeshanteringssystem, blir det ett kraftfullt verktyg för att orkestrera datatransformeringar. Med Airflows funktioner för schemaläggning och uppgiftshantering kan datateam automatisera dbt-körningar. Det säkerställer regelbundna datauppdateringar och upprätthåller ett konsekvent flöde av högkvalitativa data för analys och rapportering. Den här kombinerade metoden, med hjälp av dbts transformeringsexpertis med Airflows arbetsflödeshantering, ger effektiva och robusta datapipelines, vilket i slutändan leder till snabbare och mer insiktsfulla datadrivna beslut.
Apache Airflow är en plattform med öppen källkod som används för att programmatiskt skapa, schemalägga och övervaka komplexa dataarbetsflöden. Det gör att du kan definiera en uppsättning uppgifter, så kallade operatorer, som kan kombineras till riktade acykliska grafer (DAG:er) för att representera datapipelines.
Mer information om hur du operationaliserar dbt med ditt lager finns i Transformera data med dbt med Data Factory i Microsoft Fabric.
Att tänka på
Viktiga saker att tänka på när du använder dbt-fabric-adapter:
Granska de aktuella begränsningarna i Microsoft Fabric-datalager.
Fabric stöder Microsoft Entra ID-autentisering (tidigare Azure Active Directory) för användarhuvudnamn, användaridentiteter och tjänstens huvudnamn. Det rekommenderade autentiseringsläget för interaktivt arbete på lager är CLI (kommandoradsgränssnitt) och använder tjänstens huvudnamn för automatisering.
Granska de T-SQL-kommandon (Transact-SQL) som inte stöds i Fabric Data Warehouse.
Vissa T-SQL-kommandon stöds av dbt-fabric-kort med hjälp av
Create Table as Select(CTAS),DROPochCREATEkommandon, till exempelALTER TABLE ADD/ALTER/DROP COLUMN,MERGE,TRUNCATE,sp_rename.Läs Datatyper som inte stöds för att lära dig mer om de datatyper som stöds och som inte stöds.
Du kan logga problem på dbt-fabric-adaptern på GitHub genom att besöka Ärenden · microsoft/dbt-fabric · GitHub.