Källkontroll med Warehouse (förhandsversion)
Den här artikeln förklarar hur Git-integrerings- och distributionspipelines fungerar för lager i Microsoft Fabric. Lär dig hur du konfigurerar en anslutning till din lagringsplats, hanterar dina lager och distribuerar dem i olika miljöer. Källkontroll för Fabric Warehouse är för närvarande en förhandsversionsfunktion.
Du kan använda både Git-integrerings - och distributionspipelines för olika scenarier:
- Använd Git- och SQL-databasprojekt för att hantera inkrementell förändring, teamsamarbete, incheckningshistorik i enskilda databasobjekt.
- Använd distributionspipelines för att höja upp kodändringar till olika förproduktions- och produktionsmiljöer.
Git-integrering
Git-integrering i Microsoft Fabric gör det möjligt för utvecklare att integrera sina utvecklingsprocesser, verktyg och bästa praxis direkt i Fabric-plattformen. Det gör att utvecklare som utvecklar i Fabric kan:
- Säkerhetskopiera och versionshanterade sitt arbete
- Återgå till föregående steg efter behov
- Samarbeta med andra eller arbeta ensam med Git-grenar
- Använda funktionerna i välbekanta källkontrollverktyg för att hantera infrastrukturobjekt
Mer information om Git-integreringsprocessen finns i:
- Fabric Git-integrering
- Grundläggande begrepp i Git-integrering
- Kom igång med Git-integrering (förhandsversion)
Konfigurera en anslutning till källkontrollen
På sidan Inställningar för arbetsyta kan du enkelt konfigurera en anslutning till lagringsplatsen för att checka in och synkronisera ändringar.
- Information om hur du konfigurerar anslutningen finns i Kom igång med Git-integrering. Följ anvisningarna för att ansluta till en Git-lagringsplats till antingen Azure DevOps eller GitHub som Git-provider.
- När du är ansluten visas dina objekt, inklusive lager, på kontrollpanelen Källa.
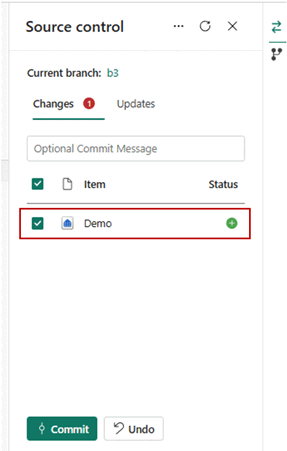
- När du har anslutit lagerinstanserna till Git-lagringsplatsen visas lagermappsstrukturen på lagringsplatsen. Nu kan du köra framtida åtgärder, till exempel skapa en pull-begäran.
Databasprojekt för ett lager i Git
Följande bild är ett exempel på filstrukturen för varje lagerobjekt på lagringsplatsen:

När du checkar in lagerartikeln på Git-lagringsplatsen konverteras lagret till ett källkodsformat som ett SQL-databasprojekt. Ett SQL-projekt är en lokal representation av SQL-objekt som utgör schemat för en enskild databas, till exempel tabeller, lagrade procedurer eller funktioner. Mappstrukturen för databasobjekten ordnas efter schema/objekttyp. Varje objekt i lagret representeras med en .sql fil som innehåller dess definition av datadefinitionsspråk (DDL). Informationslagertabelldata och SQL-säkerhetsfunktioner ingår inte i SQL-databasprojektet.
Delade frågor checkas också in på lagringsplatsen och ärver namnet som de sparas som.
Ladda ned SQL-databasprojektet för ett lager i Fabric
Med SQL Database Projects-tillägget tillgängligt i Azure Data Studio och Visual Studio Code kan du hantera ett lagerschema och hantera lagerobjektändringar som andra SQL-databasprojekt.
Om du vill ladda ned en lokal kopia av ditt lagers schema väljer du Ladda ned SQL Database-projekt i menyfliksområdet.

Den lokala kopian av ett databasprojekt som innehåller definitionen av lagerschemat. Databasprojektet kan användas för att:
- Återskapa lagerschemat i ett annat lager.
- Utveckla lagerschemat ytterligare i klientverktyg som Azure Data Studio eller Visual Studio Code.
Publicera SQL Database-projekt till ett nytt lager
Så här publicerar du lagerschemat till ett nytt lager:
- Skapa ett nytt lager i din infrastrukturarbetsyta.
- På startsidan för det nya lagret går du till Skapa ett lager och väljer SQL-databasprojekt.
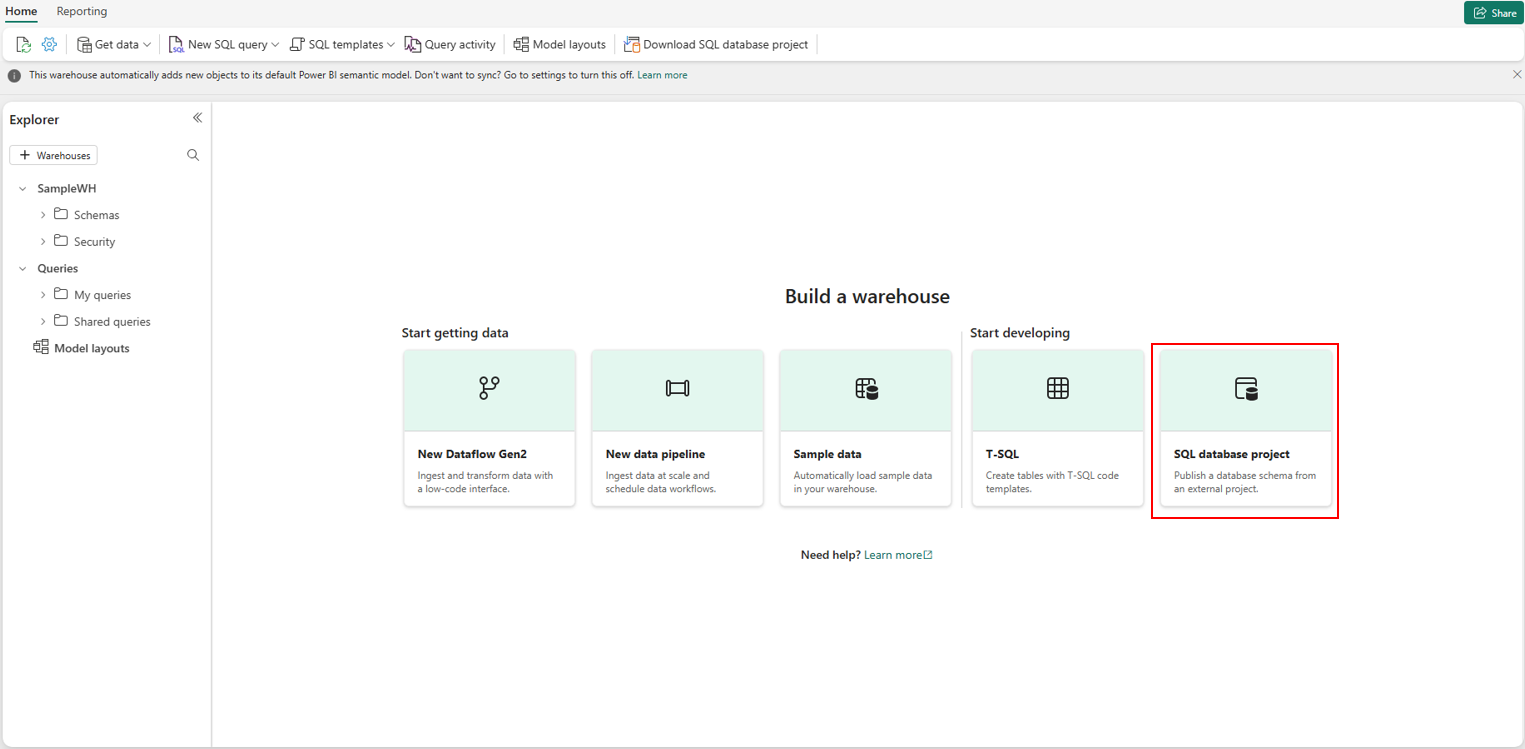
- Välj den .zip fil som laddades ned från det befintliga lagret.
- Lagerschemat publiceras till det nya lagret.

Distributionspipelines
Du kan också använda distributionspipelines för att distribuera din lagerkod i olika miljöer, till exempel utveckling, test och produktion. Distributionspipelines exponerar inte ett databasprojekt.
Följ stegen nedan för att slutföra distributionen av ditt lager med hjälp av distributionspipelinen.
- Skapa en ny distributionspipeline eller öppna en befintlig distributionspipeline. Mer information finns i Kom igång med distributionspipelines.
- Tilldela arbetsytor till olika faser enligt dina distributionsmål.
- Välj, visa och jämför objekt inklusive lager mellan olika faser, som du ser i följande exempel.
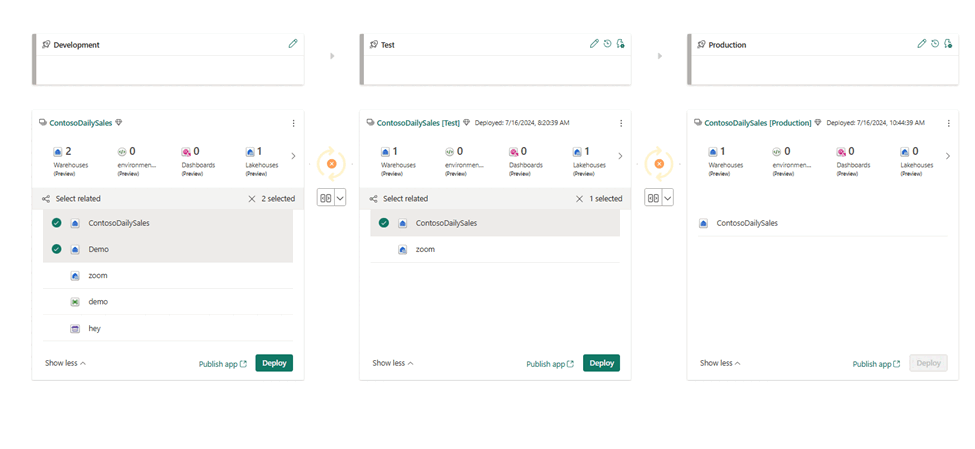
- Välj Distribuera för att distribuera dina lager i utvecklings-, test- och produktionsfaserna.

Mer information om processen för infrastrukturdistributionspipelines finns i Översikt över infrastrukturdistributionspipelines.
Begränsningar i källkontroll
- SQL-säkerhetsfunktioner måste exporteras/migreras med hjälp av en skriptbaserad metod. Överväg att använda ett skript efter distributionen i ett SQL-databasprojekt, som du kan konfigurera genom att öppna projektet med SQL Database Projects-tillägget som är tillgängligt i Azure Data Studio.
Begränsningar i Git-integrering
- Om du för närvarande använder
ALTER TABLEför att lägga till en begränsning eller kolumn i databasprojektet tas tabellen bort och återskapas när du distribuerar, vilket resulterar i dataförlust. Överväg följande lösning för att bevara tabelldefinitionen och data:- Skapa en ny kopia av tabellen i lagret med hjälp av
CREATE TABLEtabellenINSERT, ellerCREATE TABLE AS SELECT, eller Clone. - Ändra den nya tabelldefinitionen med nya begränsningar eller kolumner efter behov med hjälp av
ALTER TABLE. - Ta bort den gamla tabellen.
- Byt namn på den nya tabellen till namnet på den gamla tabellen med hjälp av sp_rename.
- Ändra definitionen av den gamla tabellen i SQL-databasprojektet på exakt samma sätt. SQL-databasprojektet för lagret i källkontrollen och det aktiva lagret bör nu matcha.
- Skapa en ny kopia av tabellen i lagret med hjälp av
- Skapa för närvarande inte ett Dataflöde Gen2 med ett utdatamål till lagret. Incheckning och uppdatering från Git blockeras av ett nytt objekt med namnet
DataflowsStagingWarehousesom visas på lagringsplatsen. - SQL-analysslutpunkten stöds inte med Git-integrering.
Begränsningar för distributionspipelines
- Om du för närvarande använder
ALTER TABLEför att lägga till en begränsning eller kolumn i databasprojektet tas tabellen bort och återskapas när du distribuerar, vilket resulterar i dataförlust. - Skapa för närvarande inte ett Dataflöde Gen2 med ett utdatamål till lagret. Distributionen skulle blockeras av ett nytt objekt med namnet
DataflowsStagingWarehousesom visas i distributionspipelinen. - SQL-analysslutpunkten stöds inte i distributionspipelines.