Vad är distributionspipelines?
Kommentar
Artiklarna i det här avsnittet beskriver hur du distribuerar innehåll till din app. Versionskontroll finns i dokumentationen för Git-integrering .
Microsoft Fabrics verktyg för distributionspipelines ger innehållsskapare en produktionsmiljö där de kan samarbeta med andra för att hantera livscykeln för organisationsinnehåll. Distributionspipelines gör det möjligt för skapare att utveckla och testa innehåll i tjänsten innan det når användarna. Se den fullständiga listan över objekttyper som stöds som du kan distribuera.
Kommentar
- Det nya användargränssnittet för distributionspipelinen är för närvarande i förhandsversion. Information om hur du aktiverar eller använder det nya användargränssnittet finns i Börja använda det nya användargränssnittet.
- Några av objekten för distributionspipelines finns i förhandsversion. Mer information finns i listan över objekt som stöds.
Lär dig hur du använder distributionspipelines
Du kan lära dig hur du använder verktyget för distributionspipelines genom att följa dessa länkar.
Skapa och hantera en distributionspipeline – en Learn-modul som vägleder dig genom hela processen med att skapa en distributionspipeline.
Kom igång med distributionspipelines – en artikel som förklarar hur du skapar en pipeline och viktiga funktioner som distribution, jämför innehåll i olika steg och skapar distributionsregler.
Objekt som stöds
När du distribuerar innehåll från en pipelinefas till en annan kan det kopierade innehållet innehålla följande objekt:
- Aktivare
- Instrumentbräda
- datapipeline(förhandsversion)
- Dataflöden gen2(förhandsversion)
- Datamart(förhandsversion)
- Environment(förhandsversion)
- Eventhouse- och KQL-databas
- EventStream(förhandsversion)
- KQL-frågeuppsättning
- Lakehouse(förhandsversion)
- Speglad databas(förhandsversion)
- Notebook-fil
- Org-app (förhandsversion)
- Sidnumrerad rapport
- Power BI-dataflöde
- Instrumentpanel i realtid
- Rapport (baserat på semantiska modeller som stöds)
- Semantisk modell (som kommer från en .pbix-fil och inte är en PUSH-datauppsättning)
- SQL-databas (förhandsversion)
- Warehouse(förhandsversion)
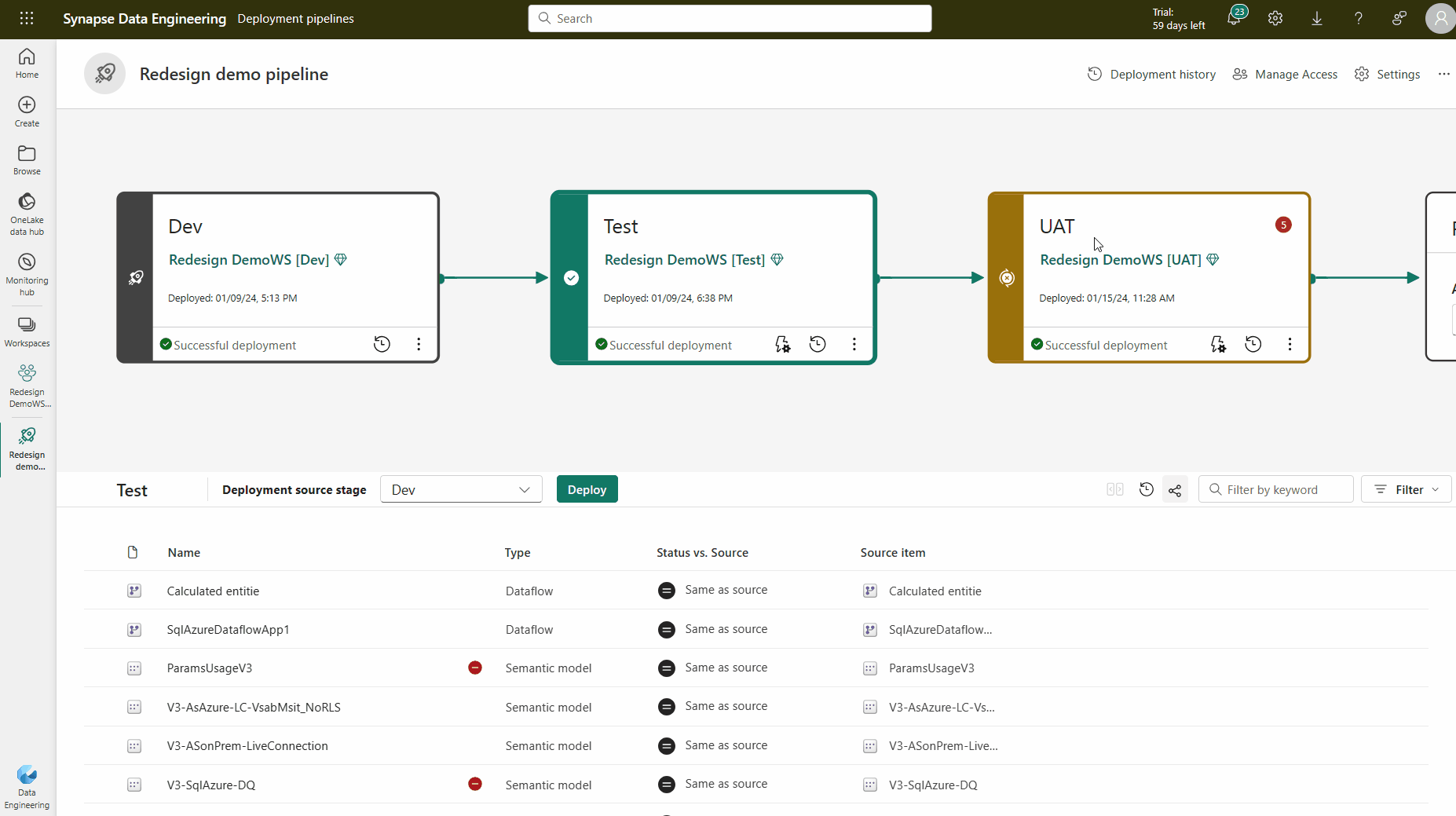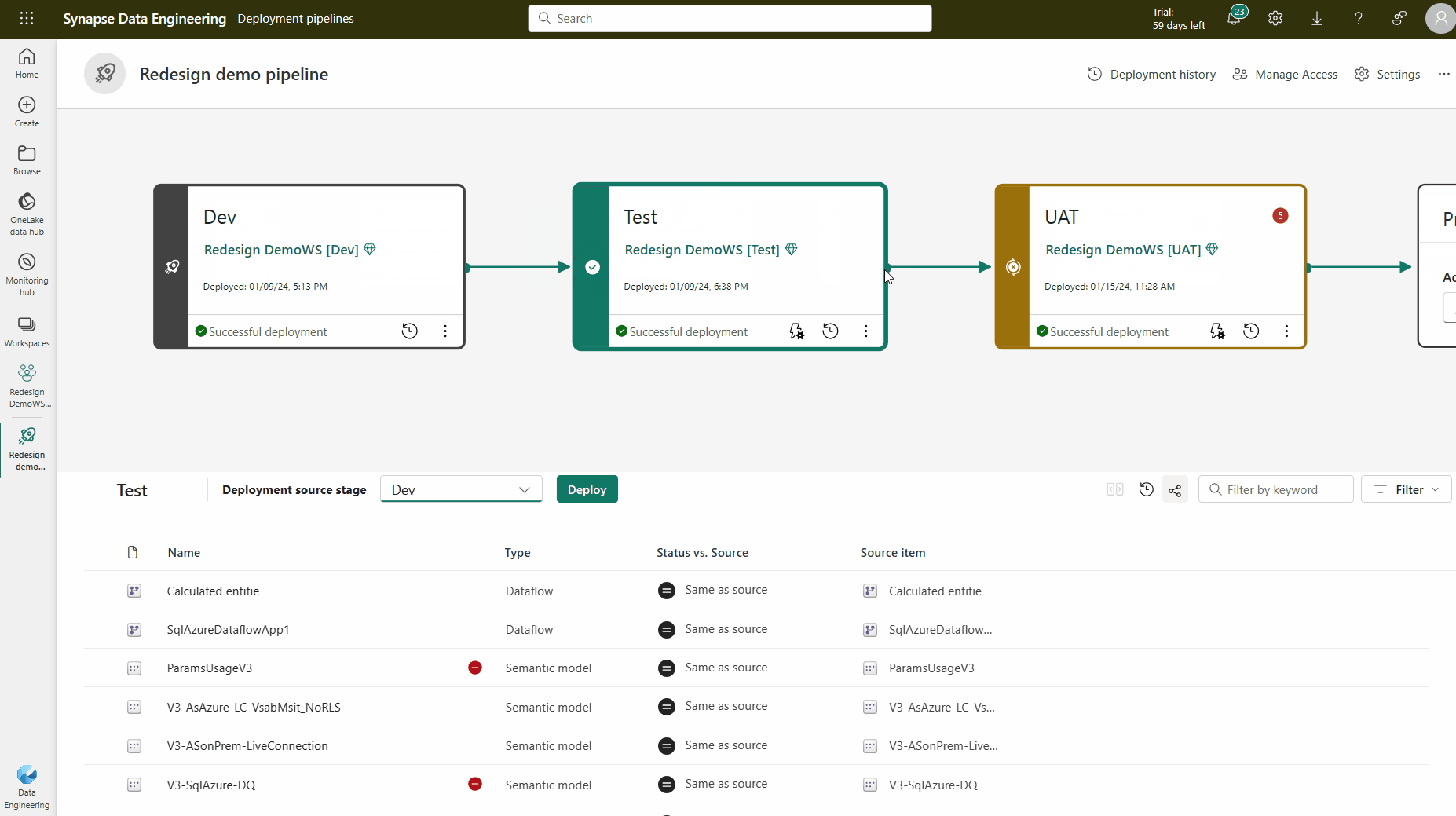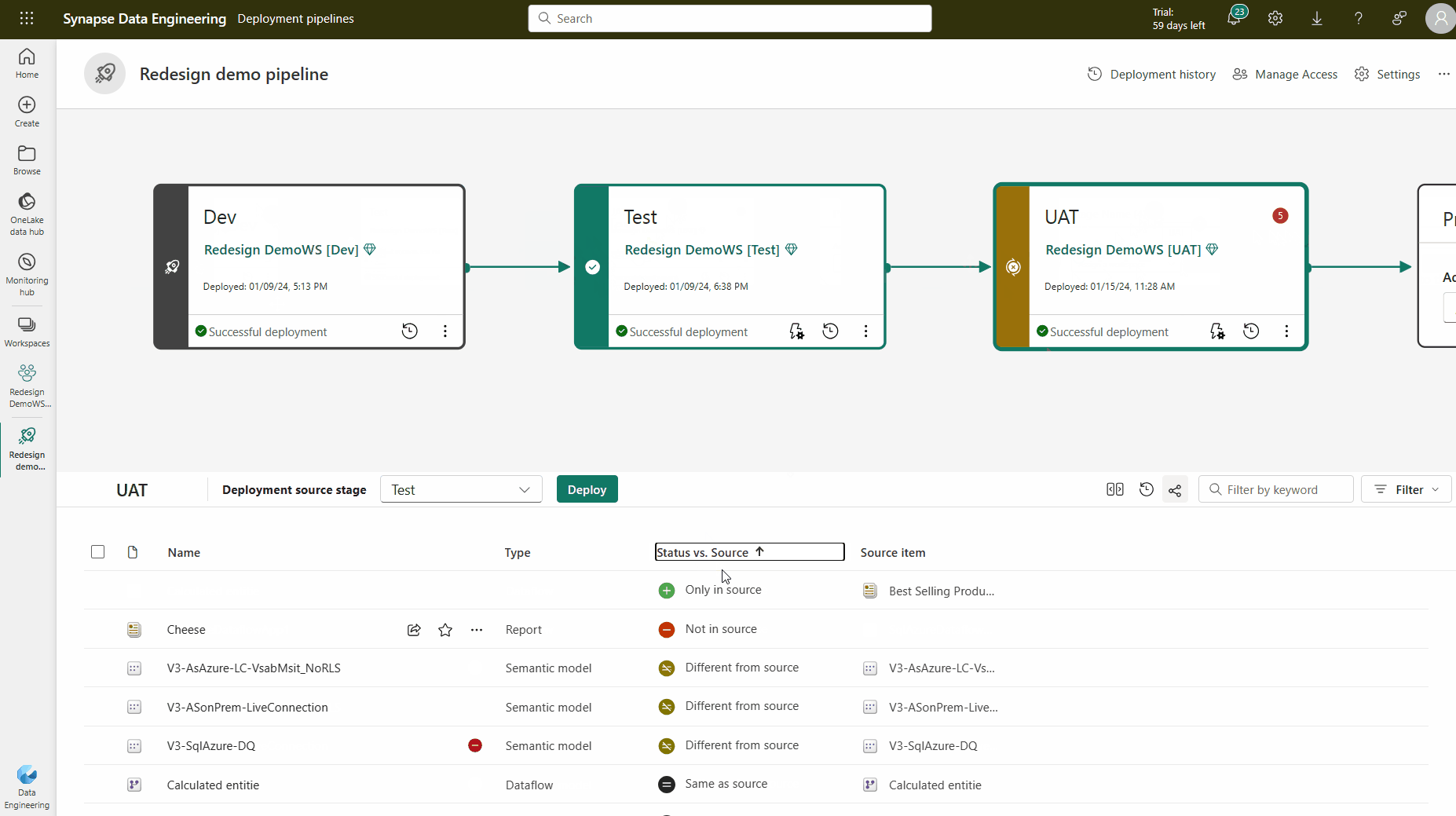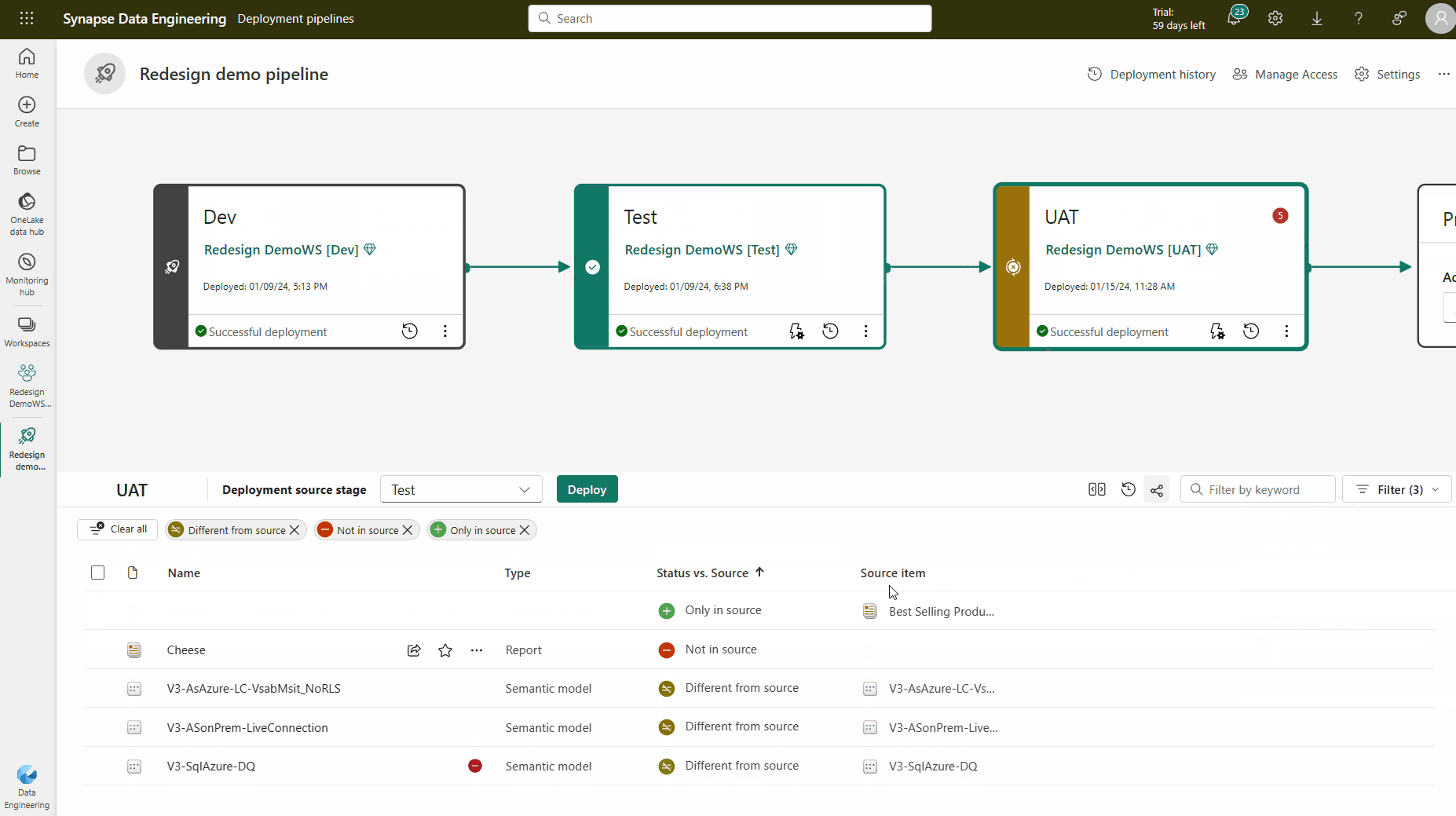
Pipelinestruktur
Du bestämmer hur många steg du vill ha i distributionspipelinen. Det kan finnas allt från två till tio steg. När du skapar en pipeline anges de tre standardstegen som en startpunkt, men du kan lägga till, ta bort eller byta namn på stegen efter dina behov. Oavsett hur många steg det finns är de allmänna begreppen desamma:
-
Det första steget i distributionen är när du laddar upp nytt innehåll med dina medskapare. Du kan utforma bygge, utveckla här eller i ett annat skede.
-
När du har genomfört alla nödvändiga ändringar i innehållet är du redo att gå in i testfasen. Ladda upp det ändrade innehållet så att det kan flyttas till det här teststeget. Här är tre exempel på vad som kan göras i testmiljön:
Dela innehåll med testare och granskare
Läsa in och köra tester med större datavolymer
Testa din app för att se hur den ser ut för slutanvändarna
-
När du har testat innehållet använder du produktionssteget för att dela den slutliga versionen av ditt innehåll med företagsanvändare i hela organisationen.
Parkoppling av objekt
Parkoppling är den process som ett objekt (till exempel en rapport, instrumentpanel eller semantisk modell) i ett steg i distributionspipelinen associeras med samma objekt i den intilliggande fasen. Parkoppling sker när du tilldelar en arbetsyta till en distributionsfas eller när du distribuerar nytt obetalt innehåll från en fas till en annan (en ren distribution).
Det är viktigt att förstå hur parkoppling fungerar för att förstå när objekt kopieras, när de skrivs över och när en distribution misslyckas när du använder distributionsfunktionen.
Om objekten inte är kopplade, även om de verkar vara samma (har samma namn, typ och mapp), skriver de inte över en distribution. I stället skapas en duplicerad kopia och paras ihop med objektet i föregående steg.
Länkade objekt visas på samma rad i pipelineinnehållslistan. Objekt som inte är kopplade visas själva på en rad:
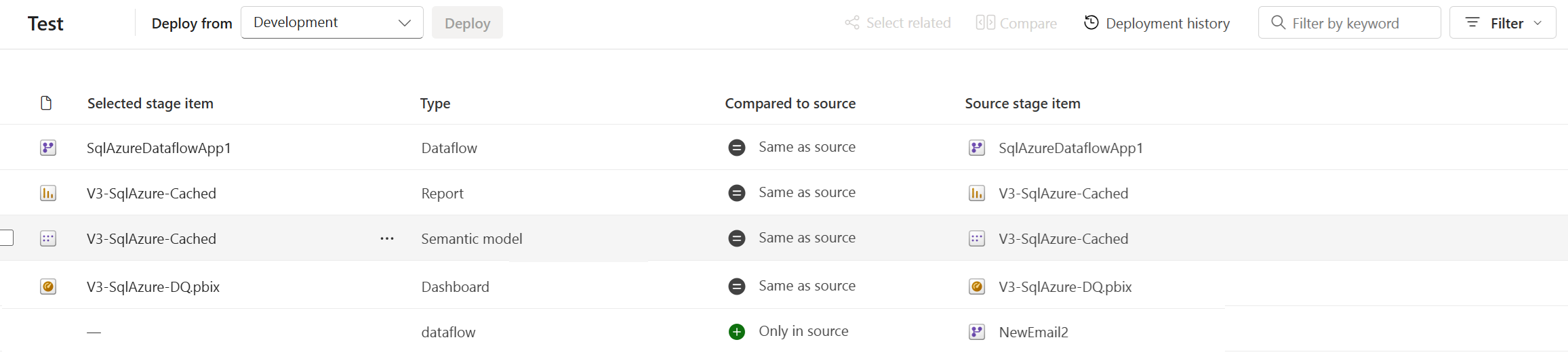
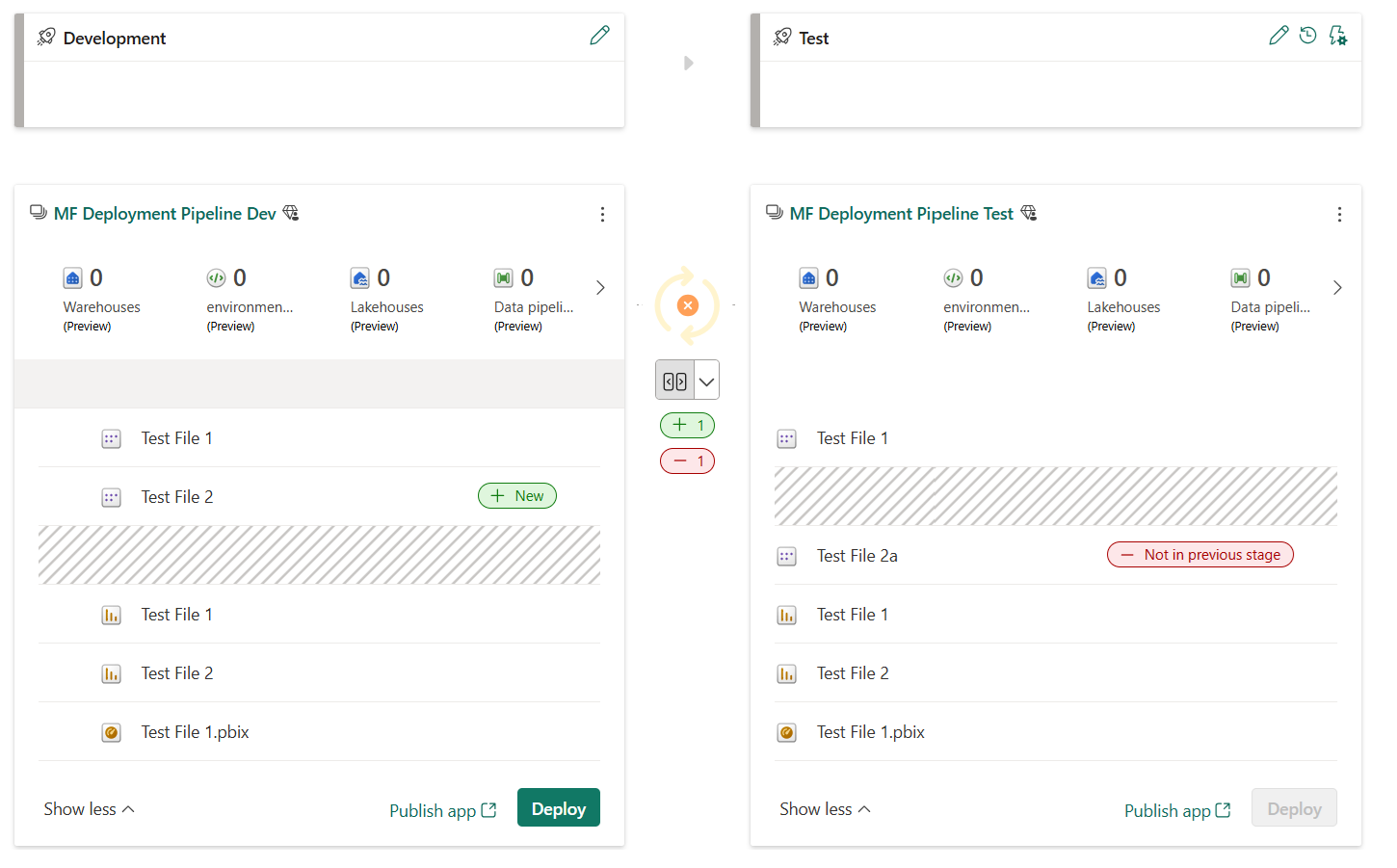
- Objekt som är kopplade förblir parkopplade även om du ändrar deras namn. Därför kan kopplade objekt ha olika namn.
- Objekt som lagts till efter att arbetsytan har tilldelats till en pipeline paras inte ihop automatiskt. Därför kan du ha identiska objekt i angränsande arbetsytor som inte är kopplade.
En detaljerad förklaring av vilka objekt som är kopplade och hur parkoppling fungerar finns i Objektparkoppling.
Distributionsmetod
Om du vill distribuera innehåll till en annan fas måste minst ett objekt väljas. När du distribuerar innehåll från en fas till en annan skriver objekten som kopieras från källsteget över det kopplade objektet i den fas som du befinner dig i enligt parkopplingsreglerna. Objekt som inte finns i källfasen förblir som de är.
När du har valt Distribuera får du ett bekräftelsemeddelande.
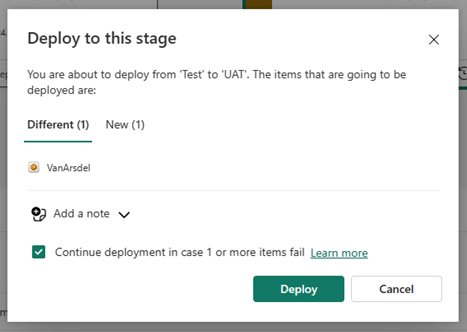
Läs mer om vilka objektegenskaper som kopieras till nästa steg och vilka egenskaper som inte kopieras i Förstå distributionsprocessen.
Automation
Du kan också distribuera innehåll programmatiskt med hjälp av REST API:er för distributionspipelines. Läs mer om automatiseringsprocessen i Automatisera din distributionspipeline med API:er och DevOps.