Forma sökresultat eller ändra sökresultatsammansättning i Azure AI Search
Den här artikeln beskriver sökresultatens sammansättning och hur du utformar sökresultat så att de passar dina scenarier. Sökresultat returneras i ett frågesvar. Formen på ett svar bestäms av parametrarna i själva frågan. Dessa parametrar omfattar:
- Antal matchningar som hittades i indexet (
count) - Antal matchningar som returneras i svaret (50 som standard, kan konfigureras via
top) eller per sida (skipochtop) - En sökpoäng för varje resultat som används för rangordning (
@search.score) - Fält som ingår i sökresultat (
select) - Sortera logik (
orderby) - Markering av termer inom ett resultat, matchning på hela eller delar av termen i brödtexten
- Valfria element från den semantiska rankern (
answershögst upp,captionsför varje matchning)
Sökresultat kan innehålla fält på den översta nivån, men det mesta av svaret består av matchande dokument i en matris.
Klienter och API:er för att definiera frågesvaret
Du kan använda följande klienter för att konfigurera ett frågesvar:
- Sök explorer i Azure Portal med JSON-vyn så att du kan ange valfri parameter som stöds
- Dokument – POST (REST API:er)
- SearchClient.Search-metoden (Azure SDK för .NET)
- SearchClient.Search-metoden (Azure SDK för Python)
- SearchClient.Search-metoden (Azure för JavaScript)
- SearchClient.Search-metoden (Azure för Java)
Resultatsammansättning
Resultaten är mestadels tabellbaserade, består av fält av antingen alla retrievable fält eller begränsade till bara de fält som anges i parametern select . Rader är matchande dokument, vanligtvis rangordnade i relevansordning såvida inte frågelogik utesluter relevansrankning.
Du kan välja vilka fält som ska visas i sökresultaten. Ett sökdokument kan ha ett stort antal fält, men vanligtvis behövs bara ett fåtal för att representera varje dokument i resultatet. I en frågebegäran lägger du till select=<field list> för att ange vilka fält som retrievable ska visas i svaret.
Välj fält som erbjuder kontrast och differentiering mellan dokument, vilket ger tillräckligt med information för att bjuda in ett klickgenomsvar från användarens sida. På en e-handelswebbplats kan det vara ett produktnamn, en beskrivning, ett varumärke, en färg, en storlek, ett pris och ett omdöme. För det inbyggda hotels-sample-indexet kan det vara fälten "select" i följande exempel:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Tips för oväntade resultat
Ibland är frågeutdata inte det du förväntar dig att se. Du kan till exempel upptäcka att vissa resultat verkar vara dubbletter, eller att ett resultat som ska visas nära toppen placeras lägre i resultatet. När frågeresultaten är oväntade kan du prova dessa frågeändringar för att se om resultaten förbättras:
Ändra
searchMode=any(standard) till attsearchMode=allkräva matchningar för alla kriterier i stället för något av kriterierna. Detta gäller särskilt när booleska operatorer ingår i frågan.Experimentera med olika lexikala analysverktyg eller anpassade analysverktyg för att se om det ändrar frågeresultatet. Standardanalysen delar upp bindestreckade ord och reducerar ord till rotformulär, vilket vanligtvis förbättrar robustheten i ett frågesvar. Men om du behöver bevara bindestreck, eller om strängar innehåller specialtecken, kan du behöva konfigurera anpassade analysverktyg för att säkerställa att indexet innehåller token i rätt format. Mer information finns i Partiell termsökning och mönster med specialtecken (bindestreck, jokertecken, regex, mönster).
Räkna matchningar
Parametern count returnerar antalet dokument i indexet som anses vara en matchning för frågan. Om du vill returnera antalet lägger du till count=true i frågebegäran. Söktjänsten har inte infört något maximalt värde. Beroende på din fråga och innehållet i dina dokument kan antalet vara lika högt som varje dokument i indexet.
Antalet är korrekt när indexet är stabilt. Om systemet aktivt lägger till, uppdaterar eller tar bort dokument är antalet ungefärligt, exklusive dokument som inte är helt indexerade.
Antalet påverkas inte av rutinunderhåll eller andra arbetsbelastningar i söktjänsten. Men om du har flera partitioner och en enskild replik kan det uppstå kortsiktiga variationer i antalet dokument (flera minuter) när partitionerna startas om.
Dricks
Om du vill kontrollera indexeringsåtgärder kan du bekräfta om indexet innehåller det förväntade antalet dokument genom att lägga till count=true en tom sökfråga search=* . Resultatet är det fullständiga antalet dokument i ditt index.
När du testar frågesyntaxen count=true kan du snabbt se om dina ändringar returnerar större eller färre resultat, vilket kan vara användbar feedback.
Antal resultat i svaret
Azure AI Search använder sidindelning på serversidan för att förhindra att frågor hämtar för många dokument samtidigt. Frågeparametrar som avgör antalet resultat i ett svar är top och skip.
top refererar till antalet sökresultat på en sida.
skip är ett intervall på top, och visar sökmotorn hur många resultat som ska hoppa över innan nästa uppsättning visas.
Standardstorleken för sidan är 50, medan den maximala sidstorleken är 1 000. Om du anger ett värde som är större än 1 000 och det finns fler än 1 000 resultat i indexet returneras endast de första 1 000 resultaten. Om antalet matchningar överskrider sidstorleken innehåller svaret information för att hämta nästa sida med resultat. Till exempel:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
De översta matchningarna bestäms av sökpoängen, förutsatt att frågan är fulltextsökning eller semantisk. Annars är de översta matchningarna en godtycklig ordning för exakta matchningsfrågor (där uniform @search.score=1.0 indikerar godtycklig rangordning).
Ange top för att åsidosätta standardvärdet 50. Om du använder en hybridfråga i nyare förhandsversions-API:er kan du ange maxTextRecallSize för att returnera upp till 10 000 dokument.
Om du vill styra växlingen av alla dokument som returneras i en resultatuppsättning använder top du och skip tillsammans. Den här frågan returnerar den första uppsättningen med 15 matchande dokument plus ett antal totala matchningar.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
Den här frågan returnerar den andra uppsättningen och hoppar över de första 15 för att hämta nästa 15 (16 till 30):
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
Resultatet av sidnumrerade frågor garanteras inte vara stabilt om det underliggande indexet ändras. Växlingen ändrar värdet skip för för varje sida, men varje fråga är oberoende och fungerar på den aktuella vyn av data som den finns i indexet vid frågetiden (med andra ord finns det ingen cachelagring eller ögonblicksbild av resultat, till exempel de som finns i en databas för generell användning).
Följande är ett exempel på hur du kan få dubbletter. Anta ett index med fyra dokument:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Anta nu att du vill att resultaten ska returneras två i taget, ordnade efter klassificering. Du kör den här frågan för att hämta den första sidan med resultat: $top=2&$skip=0&$orderby=rating desc, vilket ger följande resultat:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
I tjänsten förutsätter du att ett femte dokument läggs till i indexet mellan frågeanrop: { "id": "5", "rating": 4 }. Kort därefter kör du en fråga för att hämta den andra sidan: $top=2&$skip=2&$orderby=rating descoch få följande resultat:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Observera att dokument 2 hämtas två gånger. Det beror på att det nya dokumentet 5 har ett högre värde för klassificering, så det sorterar innan dokument 2 och hamnar på den första sidan. Även om det här beteendet kan vara oväntat är det typiskt för hur en sökmotor beter sig.
Bläddra igenom ett stort antal resultat
En alternativ metod för växling är att använda en sorteringsordning och ett intervallfilter som en lösning för skip.
I den här lösningen tillämpas sortering och filter på ett dokument-ID-fält eller ett annat fält som är unikt för varje dokument. Det unika fältet måste ha filterable och sortable attribution i sökindexet.
Utfärda en fråga för att returnera en fullständig sida med sorterade resultat.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Välj det senaste resultatet som returneras av sökfrågan. Ett exempelresultat med endast ett ID-värde visas här.
{ "id": "50" }Använd det ID-värdet i en intervallfråga för att hämta nästa sida med resultat. Det här ID-fältet bör ha unika värden, annars kan sidnumrering innehålla duplicerade resultat.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Sidnumreringen slutar när frågan returnerar noll resultat.
Kommentar
Attributen filterable och sortable kan bara aktiveras när ett fält först läggs till i ett index. De kan inte aktiveras i ett befintligt fält.
Ordna resultaten
I en fulltextsökningsfråga kan resultaten rangordnas efter:
- en sökpoäng
- en semantisk rerankerpoäng
- en sorteringsordning på ett
sortablefält
Du kan också öka matchningar som finns i specifika fält genom att lägga till en bedömningsprofil.
Ordning efter sökpoäng
För fulltextsökningsfrågor rangordnas resultaten automatiskt efter en sökpoäng med hjälp av en BM25-algoritm, beräknad baserat på termfrekvens, dokumentlängd och genomsnittlig dokumentlängd.
Intervallet @search.score är antingen obundet eller 0 upp till (men inte inklusive) 1,00 på äldre tjänster.
För algoritmen anger lika @search.score med 1,00 en resultatuppsättning som inte har angetts eller inte rangordnats, där 1,0-poängen är enhetlig för alla resultat. Oinspelade resultat inträffar när frågeformuläret är fuzzy-sökning, jokertecken eller regex-frågor eller en tom sökning (search=*). Om du behöver införa en rangordningsstruktur framför resultat som inte är indelade bör du överväga ett orderby uttryck för att uppnå det målet.
Order by the semantic reranker
Om du använder semantisk ranker@search.rerankerScore avgör sorteringsordningen för dina resultat.
Intervallet @search.rerankerScore är 1 till 4,00, där en högre poäng indikerar en starkare semantisk matchning.
Beställ med orderby
Om konsekvent ordning är ett programkrav kan du definiera ett orderby uttryck i ett fält. Endast fält som indexeras som "sorterbara" kan användas för att sortera resultat.
Fält som ofta används i en orderby inkluderad klassificering, datum och plats. Filtrering efter plats kräver att filteruttrycket anropar geo.distance() funktionen, förutom fältnamnet.
Numeriska fält (Edm.Double, Edm.Int32, Edm.Int64) sorteras i numerisk ordning (till exempel 1, 2, 10, 11, 20).
Strängfält (Edm.Stringunderfält Edm.ComplexType ) sorteras i antingen ASCII-sorteringsordning eller Unicode-sorteringsordning, beroende på språk.
Numeriskt innehåll i strängfält sorteras alfabetiskt (1, 10, 11, 2, 20).
Versaler sorteras före gemener (APPLE, Apple, BANANA, Banana, apple, banana). Du kan tilldela en textnormaliserare för att förbearbeta texten innan du sorterar för att ändra det här beteendet. Att använda gemener i ett fält påverkar inte sorteringsbeteendet eftersom Azure AI Search sorterar på en icke-analyserad kopia av fältet.
Strängar som leder med diakritiska tecken visas sist (Äpfel, Öffnen, Üben)
Öka relevansen med hjälp av en bedömningsprofil
En annan metod som främjar ordningskonsekvens är att använda en anpassad bedömningsprofil. Bedömningsprofiler ger dig mer kontroll över rangordningen av objekt i sökresultat, med möjlighet att öka matchningar som finns i specifika fält. Den extra bedömningslogiken kan hjälpa till att åsidosätta mindre skillnader mellan repliker eftersom sökpoängen för varje dokument ligger längre ifrån varandra. Vi rekommenderar rangordningsalgoritmen för den här metoden.
Träffmarkering
Träffmarkering refererar till textformatering (till exempel fet eller gul markeringar) som tillämpas på matchande termer i ett resultat, vilket gör det enkelt att upptäcka matchningen. Markering är användbart för längre innehållsfält, till exempel ett beskrivningsfält, där matchningen inte är omedelbart uppenbar.
Observera att markering tillämpas på enskilda termer. Det finns ingen markeringsfunktion för innehållet i ett helt fält. Om du vill markera över en fras måste du ange matchande termer (eller fras) i en citattät frågesträng. Den här tekniken beskrivs närmare i det här avsnittet.
Hitmarkeringsinstruktioner finns i frågebegäran. Frågor som utlöser frågeexpansion i motorn, till exempel fuzzy- och jokerteckensökning, har begränsat stöd för träffmarkering.
Krav för träffmarkering
- Fält måste vara
Edm.StringellerCollection(Edm.String) - Fält måste hänföras till
searchable
Ange markering i begäran
Om du vill returnera markerade termer tar du med markeringsparametern i frågebegäran. Parametern är inställd på en kommaavgränsad lista med fält.
Som standard är <em>formatmarkeringen , men du kan åsidosätta taggen med hjälp av highlightPreTag och highlightPostTag parametrar. Klientkoden hanterar svaret (till exempel att använda ett fetstilt teckensnitt eller en gul bakgrund).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Som standard returnerar Azure AI Search upp till fem markeringar per fält. Du kan justera det här talet genom att lägga till ett bindestreck följt av ett heltal. Returnerar till exempel "highlight": "description-10" upp till 10 markerade termer för matchande innehåll i beskrivningsfältet.
Markerade resultat
När markeringen läggs till i frågan innehåller svaret ett @search.highlights för varje resultat så att programkoden kan rikta in sig på den strukturen. Listan över fält som angetts för "markering" ingår i svaret.
I en nyckelordssökning genomsöks varje term separat. En fråga för "gudomliga hemligheter" returnerar matchningar för alla dokument som innehåller någon av termerna.
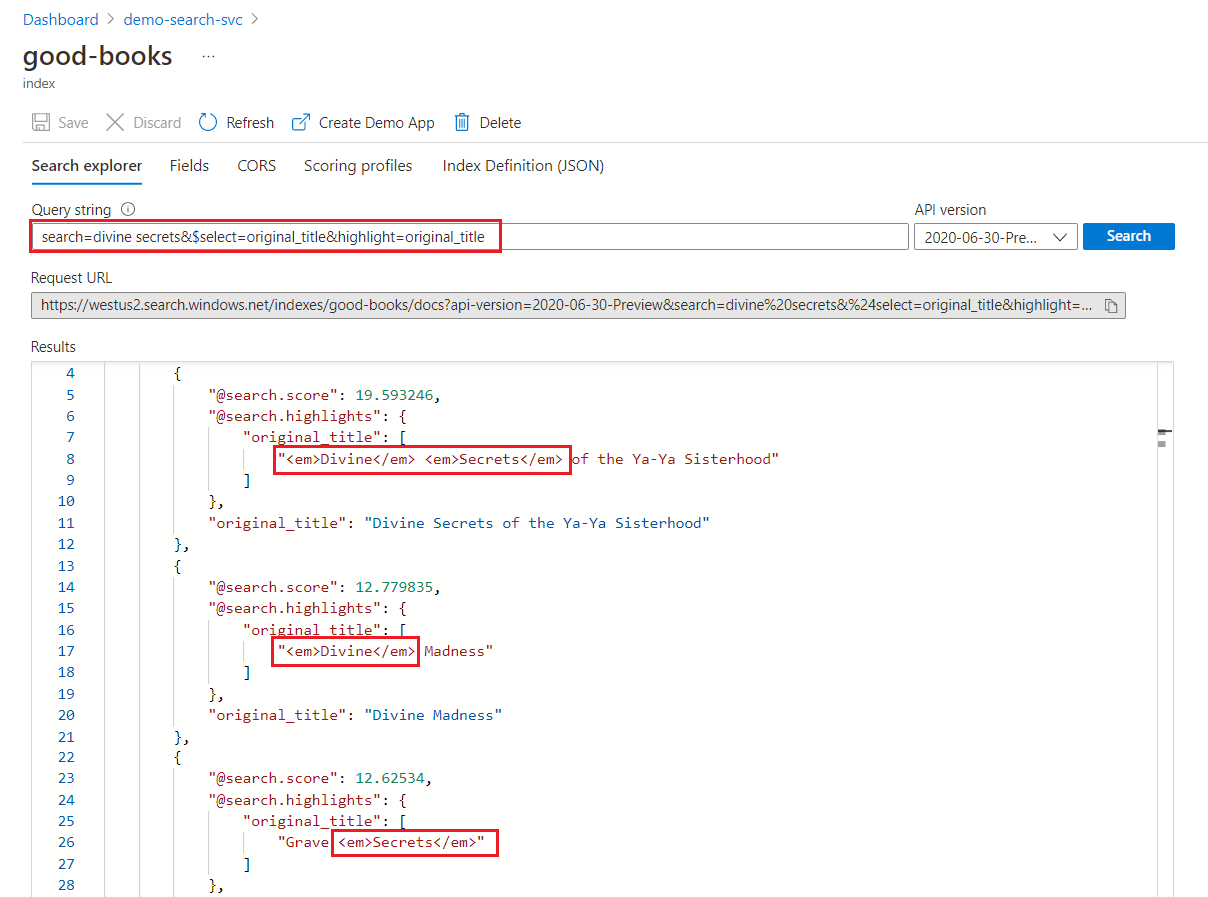
Markering av nyckelordssökning
I ett markerat fält tillämpas formatering på hela termer. Vid en matchning mot "Ya-Ya-systerskapets gudomliga hemligheter" tillämpas formateringen på varje term separat, även om de är på varandra följande.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Markering av frassökning
Heltermsformatering gäller även för en frassökning, där flera termer omges av dubbla citattecken. Följande exempel är samma fråga, förutom att "gudomliga hemligheter" skickas som en citattät fras (vissa REST-klienter kräver att du undantar de inre citattecknen med ett omvänt snedstreck \"):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Eftersom kriterierna nu har båda termerna finns bara en matchning i sökindexet. Svaret på föregående fråga ser ut så här:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Frasmarkering på äldre tjänster
tjänsten Search som skapades före den 15 juli 2020 implementerar en annan markeringsupplevelse för frasfrågor.
I följande exempel antar du en frågesträng som innehåller den citattäta frasen "super bowl". Före juli 2020 markeras en term i frasen:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
För söktjänster som skapats efter juli 2020 returneras endast fraser som matchar den fullständiga frasfrågan i @search.highlights:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Nästa steg
Tänk på följande alternativ för att snabbt generera en söksida för klienten:
Skapa en demoapp i Azure Portal skapar en HTML-sida med ett sökfält, fasetterad navigering och ett miniatyrområde om du har bilder.
Lägg till sökning i en ASP.NET Core-app (MVC) är en självstudiekurs och ett kodexempel som skapar en funktionell klient.
Lägg till sökning i webbappar är en C#-självstudie och ett kodexempel som använder React JavaScript-biblioteken för användarupplevelsen. Appen distribueras med Azure Static Web Apps och implementerar sidnumrering.