Konfigurera AutoML för att träna modeller för visuellt innehåll
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
I den här artikeln får du lära dig hur du tränar modeller för visuellt innehåll på bilddata med automatiserad ML. Du kan träna modeller med hjälp av Azure Machine Learning CLI-tillägget v2 eller Azure Machine Learning Python SDK v2.
AutoML har stöd för modellträning för uppgifter med datorseende som bildklassificering, objektidentifiering och instanssegmentering. Du kan för närvarande redigera AutoML-modeller för uppgifter med datorseende via Azure Machine Learning Python SDK. Resulterande experimenteringsförsök, modeller och utdata är tillgängliga från användargränssnittet för Azure Machine Learning-studio. Läs mer om automatiserad ml för uppgifter om visuellt innehåll på bilddata.
Förutsättningar
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
- En Azure Machine Learning-arbetsyta. Information om hur du skapar arbetsytan finns i Skapa arbetsyteresurser.
- Installera och konfigurera CLI (v2) och se till att du installerar
mltillägget.
Välj aktivitetstyp
Automatiserad ML för avbildningar stöder följande uppgiftstyper:
| Uppgiftstyp | AutoML-jobbsyntax |
|---|---|
| bildklassificering | CLI v2: image_classification SDK v2: image_classification() |
| multietikett för bildklassificering | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| identifiering av bildobjekt | CLI v2: image_object_detection SDK v2: image_object_detection() |
| segmentering av bildinstans | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Den här aktivitetstypen är en obligatorisk parameter och kan anges med hjälp av task nyckeln.
Till exempel:
task: image_object_detection
Tränings- och valideringsdata
För att generera modeller för visuellt innehåll måste du ta med märkta bilddata som indata för modellträning i form av en MLTable. Du kan skapa en MLTable från träningsdata i JSONL-format.
Om dina träningsdata har ett annat format (t.ex. pascal VOC eller COCO) kan du använda hjälpskripten som ingår i exempelanteckningsböckerna för att konvertera data till JSONL. Läs mer om hur du förbereder data för uppgifter med visuellt innehåll med automatiserad ML.
Kommentar
Träningsdata måste ha minst 10 bilder för att kunna skicka ett AutoML-jobb.
Varning
Skapande av data i JSONL-format stöds endast med hjälp av MLTable SDK och CLI för den här funktionen. Det går inte att MLTable skapa via användargränssnittet just nu.
JSONL-schemaexempel
Strukturen för TabularDataset beror på vilken uppgift som finns. För aktivitetstyper för visuellt innehåll består den av följande fält:
| Fält | beskrivning |
|---|---|
image_url |
Innehåller filepath som ett StreamInfo-objekt |
image_details |
Informationen om bildmetadata består av höjd, bredd och format. Det här fältet är valfritt och kan därför inte finnas. |
label |
En json-representation av bildetiketten baserat på aktivitetstypen. |
Följande kod är en JSONL-exempelfil för bildklassificering:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Följande kod är en JSONL-exempelfil för objektidentifiering:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Använda data
När dina data är i JSONL-format kan du skapa träning och validering MLTable enligt nedan.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Automatiserad ML medför inga begränsningar för tränings- eller valideringsdatastorleken för uppgifter med visuellt innehåll. Maximal datamängdsstorlek begränsas endast av lagringslagret bakom datamängden (exempel: bloblager). Det finns inget minsta antal bilder eller etiketter. Vi rekommenderar dock att du börjar med minst 10–15 exempel per etikett för att säkerställa att utdatamodellen är tillräckligt tränad. Ju högre det totala antalet etiketter/klasser, desto fler exempel behöver du per etikett.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Träningsdata är en obligatorisk parameter och skickas med hjälp av training_data nyckeln. Du kan också ange en annan MLtable som valideringsdata med validation_data nyckeln. Om inga valideringsdata anges används 20 % av dina träningsdata som standard för validering, såvida du inte skickar validation_data_size argument med ett annat värde.
Målkolumnnamnet är en obligatorisk parameter och används som mål för övervakad ML-uppgift. Den skickas med hjälp av target_column_name nyckeln. Ett exempel:
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Beräkning för att köra experiment
Ange ett beräkningsmål för automatiserad ML för att genomföra modellträning. Automatiserade ML-modeller för uppgifter med visuellt innehåll kräver GPU-SKU:er och stöd för NC- och ND-familjer. Vi rekommenderar NCsv3-serien (med v100 GPU:er) för snabbare träning. Ett beräkningsmål med en SKU för virtuella datorer med flera GPU:er använder flera GPU:er för att också påskynda träningen. När du konfigurerar ett beräkningsmål med flera noder kan du dessutom utföra snabbare modellträning genom parallellitet när du justerar hyperparametrar för din modell.
Kommentar
Om du använder en beräkningsinstans som beräkningsmål kontrollerar du att flera AutoML-jobb inte körs samtidigt. Kontrollera också att är max_concurrent_trials inställt på 1 i dina jobbgränser.
Beräkningsmålet skickas in med hjälp av parametern compute . Till exempel:
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
compute: azureml:gpu-cluster
Konfigurera experiment
För uppgifter med visuellt innehåll kan du starta enskilda utvärderingsversioner, manuella svep eller automatiska svep. Vi rekommenderar att du börjar med en automatisk svepning för att få en första baslinjemodell. Sedan kan du prova enskilda utvärderingsversioner med vissa modeller och hyperparameterkonfigurationer. Med manuella svep kan du utforska flera hyperparametervärden nära de mer lovande modellerna och hyperparameterkonfigurationerna. Det här trestegsarbetsflödet (automatisk svepning, enskilda försök, manuella svep) undviker att söka i hela hyperparameterutrymmet, som växer exponentiellt i antalet hyperparametrar.
Automatiska svep kan ge konkurrenskraftiga resultat för många datauppsättningar. Dessutom kräver de inte avancerad kunskap om modellarkitekturer, de tar hänsyn till hyperparameterkorrelationer och de fungerar sömlöst i olika maskinvarukonfigurationer. Alla dessa orsaker gör dem till ett starkt alternativ för det tidiga skedet av experimenteringsprocessen.
Primärt mått
Ett AutoML-träningsjobb använder ett primärt mått för modelloptimering och justering av hyperparametrar. Det primära måttet beror på aktivitetstypen enligt nedan. andra primära måttvärden stöds för närvarande inte.
- Noggrannhet för bildklassificering
- Skärningspunkt över union för multilabel för bildklassificering
- Genomsnittlig genomsnittlig precision för identifiering av bildobjekt
- Genomsnittlig genomsnittlig precision för segmentering av bildinstanser
Jobbgränser
Du kan styra de resurser som spenderas på ditt AutoML Image-träningsjobb genom att timeout_minutesange , max_trials och max_concurrent_trials för jobbet i gränsinställningarna enligt beskrivningen i exemplet nedan.
| Parameter | Detalj |
|---|---|
max_trials |
Parameter för maximalt antal försök att sopa. Måste vara ett heltal mellan 1 och 1000. När du bara utforskar standardhyperparametrar för en viss modellarkitektur anger du den här parametern till 1. Standardvärdet är 1. |
max_concurrent_trials |
Maximalt antal utvärderingsversioner som kan köras samtidigt. Om det anges måste det vara ett heltal mellan 1 och 100. Standardvärdet är 1. OBS! max_concurrent_trials är begränsad max_trials till internt. Om användaren till exempel anger max_concurrent_trials=4, max_trials=2uppdateras värdena internt som max_concurrent_trials=2, max_trials=2. |
timeout_minutes |
Tiden i minuter innan experimentet avslutas. Om inget anges är standardexperimentet timeout_minutes sju dagar (högst 60 dagar) |
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Automatiskt svepande modellhyperparametrar (AutoMode)
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Det är svårt att förutsäga den bästa modellarkitekturen och hyperparametrar för en datauppsättning. I vissa fall kan också den mänskliga tid som allokeras till justering av hyperparametrar begränsas. För uppgifter med visuellt innehåll kan du ange valfritt antal utvärderingsversioner och systemet avgör automatiskt vilken region av hyperparameterutrymmet som ska sopas. Du behöver inte definiera ett hyperparametersökutrymme, en samplingsmetod eller en princip för tidig avslutning.
Utlös automoder
Du kan köra automatiska svep genom att ange max_trials ett värde som är större än 1 in limits och genom att inte ange sökutrymmet, samplingsmetoden och avslutningsprincipen. Vi kallar den här funktionen AutoMode; Se följande exempel.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
limits:
max_trials: 10
max_concurrent_trials: 2
Ett antal utvärderingsversioner mellan 10 och 20 fungerar förmodligen bra på många datauppsättningar. Tidsbudgeten för AutoML-jobbet kan fortfarande anges, men vi rekommenderar att du bara gör det om varje utvärderingsversion kan ta lång tid.
Varning
Det går inte att starta automatiska svep via användargränssnittet just nu.
Individuella utvärderingsversioner
I enskilda utvärderingsversioner styr du direkt modellarkitekturen och hyperparametrar. Modellarkitekturen skickas via parametern model_name .
Modellarkitekturer som stöds
I följande tabell sammanfattas de äldre modeller som stöds för varje uppgift för visuellt innehåll. Om du bara använder dessa äldre modeller utlöses körningar med den äldre körningen (där varje enskild körning eller utvärderingsversion skickas som ett kommandojobb). Se nedan för stöd för HuggingFace och MMDetection.
| Uppgift | modellarkitekturer | Strängliteral syntaxdefault_model* anges med * |
|---|---|---|
| Bildklassificering (flera klasser och flera etiketter) |
MobileNet: Lättviktade modeller för mobila program ResNet: Residualnätverk ResNeSt: Dela upp uppmärksamhetsnätverk SE-ResNeXt50: Squeeze-and-Excitation-nätverk ViT: Vision transformeringsnätverk |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (liten) vitb16r224* (bas) vitl16r224 (stor) |
| Objektidentifiering |
YOLOv5: Objektidentifieringsmodell i ett steg Snabbare RCNN ResNet FPN: Tvåstegsobjektidentifieringsmodeller RetinaNet ResNet FPN: åtgärda obalans i klassen med brännpunktsförlust Obs! Se model_size hyperparameter för YOLOv5-modellstorlekar. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Instanssegmentering | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Modellarkitekturer som stöds – HuggingFace och MMDetection
Med den nya serverdelen som körs på Azure Machine Learning-pipelines kan du dessutom använda valfri bildklassificeringsmodell från HuggingFace Hub som ingår i transformeringsbiblioteket (till exempel microsoft/beit-base-patch16-224), samt alla objektidentifierings- eller instanssegmenteringsmodeller från MMDetection Version 3.1.0 Model Zoo (till exempel atss_r50_fpn_1x_coco).
Förutom att stödja alla modeller från HuggingFace Transfomers och MMDetection 3.1.0 erbjuder vi även en lista över utvalda modeller från dessa bibliotek i azureml-registret. Dessa utvalda modeller har testats noggrant och använder standardhyperparametrar som valts från omfattande benchmarking för att säkerställa effektiv träning. Tabellen nedan sammanfattar dessa utvalda modeller.
| Uppgift | modellarkitekturer | Strängliteral syntax |
|---|---|---|
| Bildklassificering (flera klasser och flera etiketter) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Objektidentifiering |
Gles R-CNN Deformerbar DETR VFNet YOLOF |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Instanssegmentering | Maskera R-CNN | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Vi uppdaterar ständigt listan över utvalda modeller. Du kan få den senaste listan över de utvalda modellerna för en viss uppgift med hjälp av Python SDK:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Utdata:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Om du använder en HuggingFace- eller MMDetection-modell utlöses körningar med hjälp av pipelinekomponenter. Om både äldre modeller och HuggingFace/MMdetection-modeller används utlöses alla körningar/utvärderingar med hjälp av komponenter.
Förutom att styra modellarkitekturen kan du även justera hyperparametrar som används för modellträning. Många av de hyperparametrar som exponeras är modellagnostiska, men det finns instanser där hyperparametrar är aktivitetsspecifika eller modellspecifika. Läs mer om tillgängliga hyperparametrar för dessa instanser.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Om du vill använda standardvärdena för hyperparameter för en viss arkitektur (till exempel yolov5) kan du ange det med hjälp av model_name-nyckeln i avsnittet training_parameters. Ett exempel:
training_parameters:
model_name: yolov5
Manuellt svepande modellhyperparametrar
När modeller för visuellt innehåll tränas beror modellprestandan mycket på de värden för hyperparameter som valts. Ofta kanske du vill justera hyperparametrar för att få optimala prestanda. För uppgifter med visuellt innehåll kan du sopa hyperparametrar för att hitta de optimala inställningarna för din modell. Den här funktionen använder funktionerna för hyperparameterjustering i Azure Machine Learning. Lär dig hur du finjusterar hyperparametrar.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Definiera parameterns sökutrymme
Du kan definiera modellarkitekturer och hyperparametrar för att sopa i parameterutrymmet. Du kan antingen ange en enskild modellarkitektur eller flera.
- Se Enskilda utvärderingsversioner för listan över modellarkitekturer som stöds för varje aktivitetstyp.
- Se Hyperparametrar för hyperparametrar för dataseendeuppgifter för varje aktivitetstyp för visuellt innehåll.
- Se information om distributioner som stöds för diskreta och kontinuerliga hyperparametrar.
Provtagningsmetoder för svepet
När du sveper hyperparametrar måste du ange den samplingsmetod som ska användas för att svepa över det definierade parameterutrymmet. För närvarande stöds följande samplingsmetoder med parametern sampling_algorithm :
| Samplingstyp | AutoML-jobbsyntax |
|---|---|
| Stickprov | random |
| Rutnätssampling | grid |
| Bayesiansk sampling | bayesian |
Kommentar
För närvarande stöder endast slumpmässig sampling och rutnätssampling villkorsstyrda hyperparameterutrymmen.
Principer för tidig uppsägning
Du kan automatiskt avsluta dåliga utvärderingsversioner med en princip för tidig avslutning. Tidig avslutning förbättrar beräkningseffektiviteten och sparar beräkningsresurser som annars skulle ha spenderats på mindre lovande utvärderingar. Automatiserad ML för avbildningar stöder följande principer för tidig avslutning med hjälp av parametern early_termination . Om ingen avslutningsprincip har angetts körs alla utvärderingsversioner till slutförande.
| Princip för tidig uppsägning | AutoML-jobbsyntax |
|---|---|
| Bandit-princip | CLI v2: bandit SDK v2: BanditPolicy() |
| Princip för medianstopp | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Princip för markering av trunkering | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
Läs mer om hur du konfigurerar principen för tidig avslutning för hyperparametersvepningen.
Kommentar
Ett fullständigt exempel på svepkonfiguration finns i den här självstudien.
Du kan konfigurera alla sveprelaterade parametrar enligt följande exempel.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Fasta inställningar
Du kan skicka fasta inställningar eller parametrar som inte ändras under parameterutrymmessvepningen enligt följande exempel.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Dataförstoring
I allmänhet kan prestanda för djupinlärningsmodeller ofta förbättras med mer data. Dataförstoring är en praktisk teknik för att förstärka datastorleken och variabiliteten för en datauppsättning, vilket hjälper till att förhindra överanpassning och förbättra modellens generaliseringsförmåga för osedda data. Automatiserad ML tillämpar olika dataförstoringstekniker baserat på uppgiften visuellt innehåll innan indatabilder matas in till modellen. För närvarande finns det ingen exponerad hyperparameter för att kontrollera dataförstoringar.
| Uppgift | Datauppsättning som påverkas | Dataförstoringsteknik(er) tillämpas |
|---|---|---|
| Bildklassificering (flera klasser och flera etiketter) | Träning Validering och test |
Slumpmässig storleksändring och beskärning, vågrät flip, färg jitter (ljusstyrka, kontrast, mättnad och nyans), normalisering med hjälp av kanalmässigt ImageNets medelvärde och standardavvikelse Ändra storlek, centrera beskärning, normalisering |
| Objektidentifiering, instanssegmentering | Träning Validering och test |
Slumpmässig beskärning runt avgränsningsrutor, expandera, vågrät flip, normalisering, ändra storlek Normalisering, ändra storlek |
| Objektidentifiering med yolov5 | Träning Validering och test |
Mosaik, slumpmässig affin (rotation, översättning, skala, sk shear), vågrät vänd Storleksändring för brevlåda |
För närvarande tillämpas de förhöjda värden som definieras ovan som standard för en automatiserad ML för avbildningsjobb. För att ge kontroll över förstoringar exponerar automatiserad ML för bilder under två flaggor för att inaktivera vissa förhöjda inställningar. För närvarande stöds dessa flaggor endast för objektidentifiering och instanssegmenteringsuppgifter.
- apply_mosaic_for_yolo: Den här flaggan är bara specifik för Yolo-modellen. Om du ställer in den på False inaktiveras mosaikdataförstoringen, som tillämpas vid träningstillfället.
-
apply_automl_train_augmentations: Om du ställer in den här flaggan på false inaktiveras förstoringen som tillämpas under träningstiden för objektidentifierings- och instanssegmenteringsmodellerna. Mer information finns i informationen i tabellen ovan.
- För objektidentifieringsmodeller som inte är yoloobjekt och instanssegmenteringsmodeller inaktiverar den här flaggan endast de tre första förhöjda objekten. Till exempel: Slumpmässig beskärning runt avgränsningsrutor, expandera, vågrät vänd. Normaliseringen och storleksförstoringarna tillämpas fortfarande oavsett den här flaggan.
- För Yolo-modellen inaktiverar den här flaggan den slumpmässiga affinen och vågräta flipförstoringar.
Dessa två flaggor stöds via advanced_settings under training_parameters och kan styras på följande sätt.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Observera att dessa två flaggor är oberoende av varandra och även kan användas i kombination med hjälp av följande inställningar.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
I våra experiment upptäckte vi att dessa förstoringar hjälper modellen att generalisera bättre. När dessa förhöjda program stängs av rekommenderar vi därför att användarna kombinerar dem med andra offlineförstoringar för att få bättre resultat.
Inkrementell träning (valfritt)
När träningsjobbet är klart kan du välja att träna modellen ytterligare genom att läsa in den tränade modellkontrollpunkten. Du kan antingen använda samma datauppsättning eller en annan för inkrementell träning. Om du är nöjd med modellen kan du välja att sluta träna och använda den aktuella modellen.
Skicka kontrollpunkten via jobb-ID
Du kan skicka jobb-ID:t som du vill läsa in kontrollpunkten från.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Skicka AutoML-jobbet
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Om du vill skicka ditt AutoML-jobb kör du följande CLI v2-kommando med sökvägen till din .yml-fil, arbetsytans namn, resursgrupp och prenumerations-ID.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Utdata och utvärderingsmått
De automatiserade ML-träningsjobben genererar utdatamodellfiler, utvärderingsmått, loggar och distributionsartefakter som bedömningsfilen och miljöfilen. Dessa filer och mått kan visas från fliken utdata och loggar och mått i de underordnade jobben.
Dricks
Kontrollera hur du navigerar till jobbresultatet från avsnittet Visa jobbresultat .
Definitioner och exempel på prestandadiagram och mått som tillhandahålls för varje jobb finns i Utvärdera automatiserade maskininlärningsexperimentresultat.
Registrera och distribuera modell
När jobbet är klart kan du registrera den modell som skapades från den bästa utvärderingsversionen (konfiguration som resulterade i det bästa primära måttet). Du kan antingen registrera modellen efter nedladdningen eller genom att ange azureml-sökvägen med motsvarande jobid. Obs! När du vill ändra de slutsatsdragningsinställningar som beskrivs nedan måste du ladda ned modellen och ändra settings.json och registrera med hjälp av den uppdaterade modellmappen.
Få den bästa utvärderingsversionen
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
CLI example not available, please use Python SDK.
registrera modellen
Registrera modellen antingen med hjälp av azureml-sökvägen eller din lokalt nedladdade sökväg.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
När du har registrerat den modell som du vill använda kan du distribuera den med hjälp av den hanterade onlineslutpunkten deploy-managed-online-endpoint
Konfigurera onlineslutpunkt
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Skapa slutpunkten
Med hjälp av det MLClient som skapades tidigare skapar vi slutpunkten på arbetsytan. Det här kommandot startar skapandet av slutpunkten och returnerar ett bekräftelsesvar medan skapandet av slutpunkten fortsätter.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Konfigurera onlinedistribution
En distribution är en uppsättning resurser som krävs för att vara värd för den modell som utför den faktiska inferensen. Vi skapar en distribution för slutpunkten med hjälp av ManagedOnlineDeployment klassen . Du kan använda GPU- eller CPU VM-SKU:er för distributionsklustret.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Skapa distributionen
Med hjälp av den MLClient som skapades tidigare skapar vi nu distributionen på arbetsytan. Det här kommandot startar distributionen och returnerar ett bekräftelsesvar medan distributionen skapas.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
uppdatera trafik:
Som standard är den aktuella distributionen inställd på att ta emot 0 % trafik. du kan ange vilken trafikprocentuell distribution som ska tas emot. Summan av trafikprocenterna för alla distributioner med en slutpunkt får inte överstiga 100 %.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Alternativt kan du distribuera modellen från Azure Machine Learning-studio användargränssnittet. Gå till den modell som du vill distribuera på fliken Modeller i det automatiserade ML-jobbet och välj distribueraoch välj Distribuera till realtidsslutpunkt .
 .
.
Så här ser granskningssidan ut. vi kan välja instanstyp, antal instanser och ange trafikprocent för den aktuella distributionen.
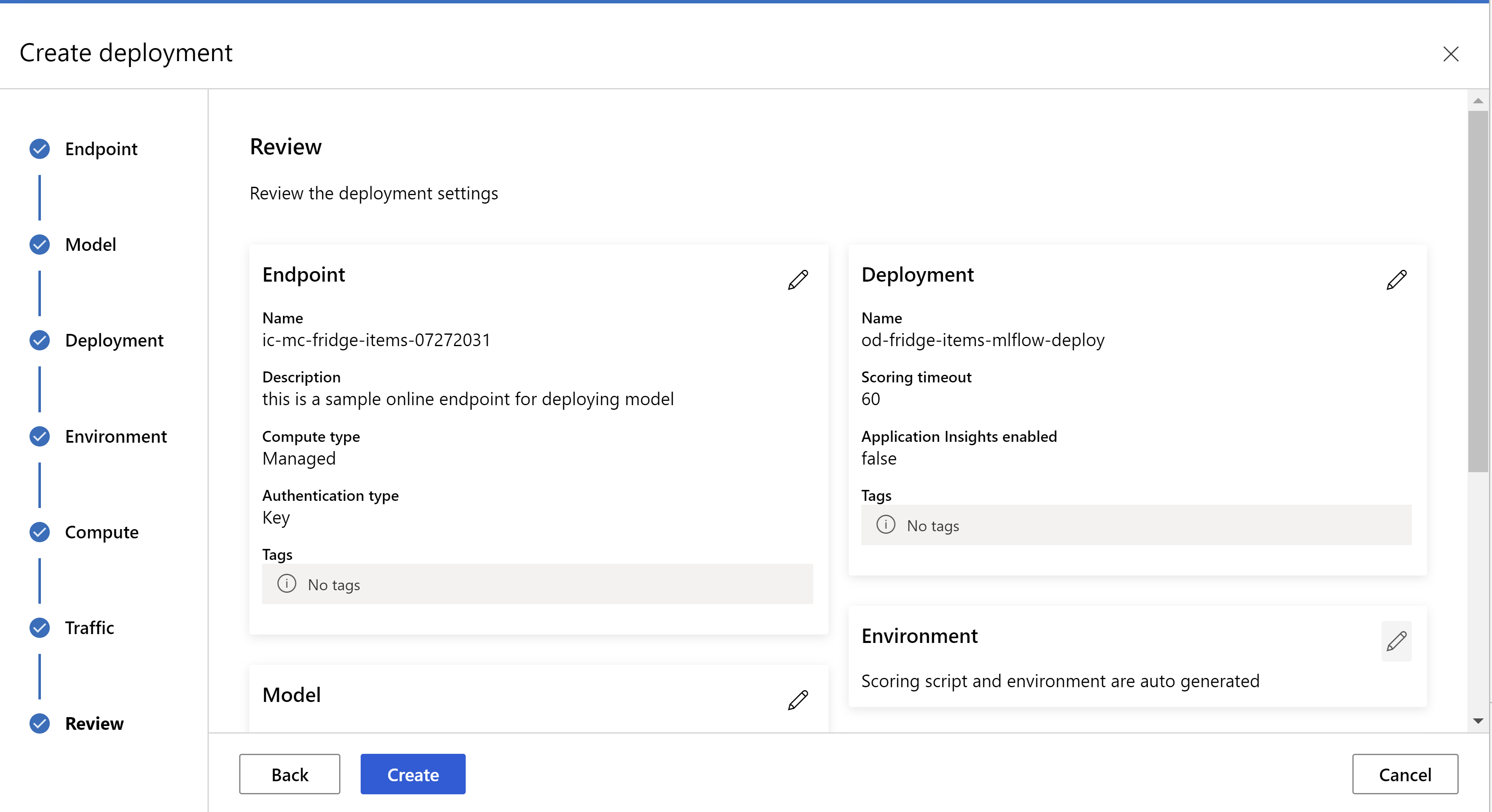 .
.
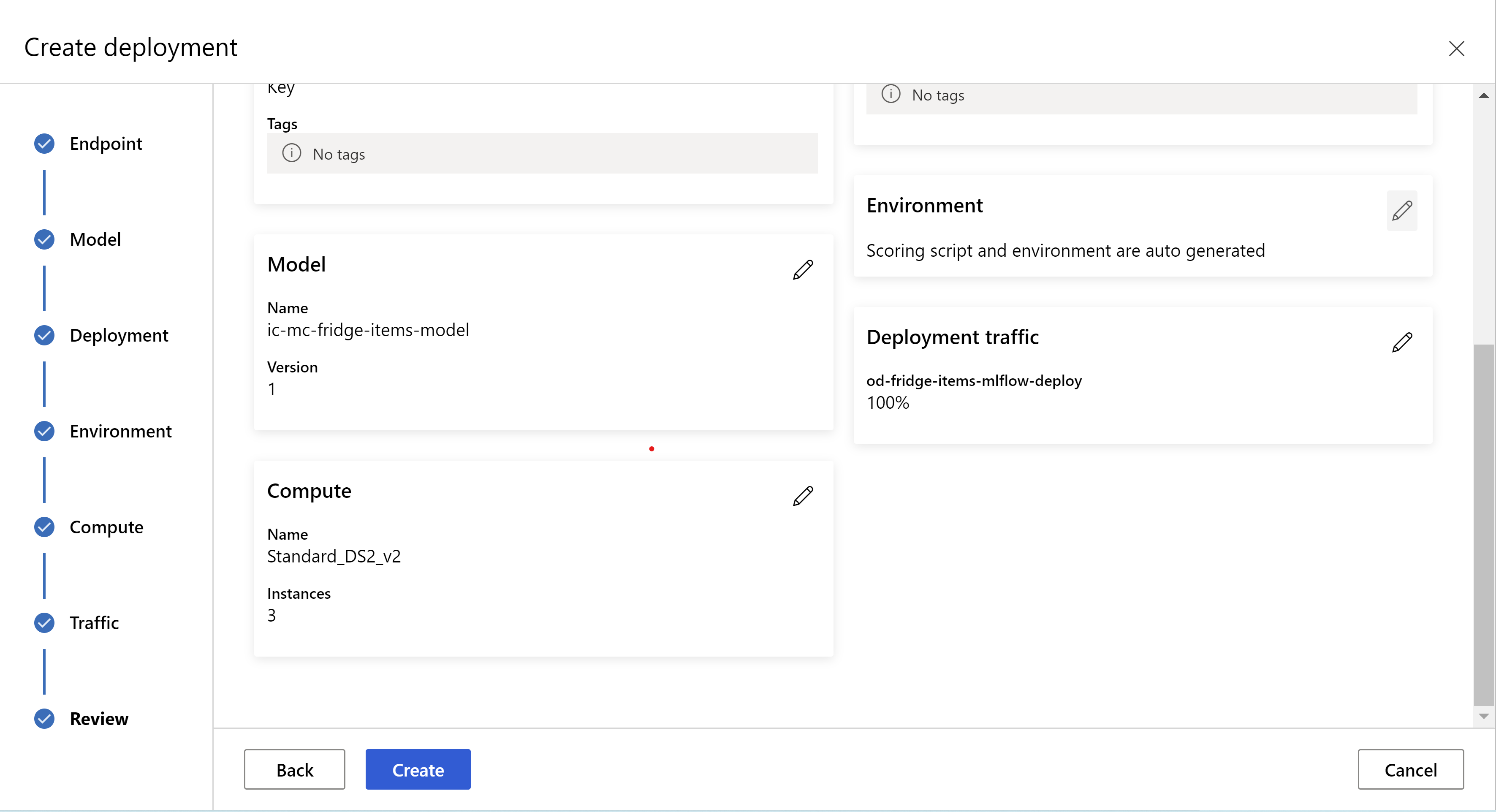 .
.
Uppdatera slutsatsdragningsinställningar
I föregående steg laddade vi ned en fil mlflow-model/artifacts/settings.json från den bästa modellen. som kan användas för att uppdatera slutsatsdragningsinställningarna innan modellen registreras. Även om vi rekommenderar att du använder samma parametrar som träning för bästa prestanda.
Var och en av uppgifterna (och vissa modeller) har en uppsättning parametrar. Som standard använder vi samma värden för de parametrar som användes under träningen och valideringen. Beroende på vilket beteende vi behöver när vi använder modellen för slutsatsdragning kan vi ändra dessa parametrar. Nedan hittar du en lista med parametrar för varje aktivitetstyp och modell.
| Uppgift | Parameternamn | Standardvärde |
|---|---|---|
| Bildklassificering (flera klasser och flera etiketter) | valid_resize_sizevalid_crop_size |
256 224 |
| Objektidentifiering | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Objektidentifiering med hjälp av yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 medel 0,1 0,5 |
| Instanssegmentering | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 Falsk JPG |
En detaljerad beskrivning av uppgiftsspecifika hyperparametrar finns i Hyperparametrar för uppgifter med visuellt innehåll i automatiserad maskininlärning.
Om du vill använda tiling och vill styra plattsättningsbeteendet är följande parametrar tillgängliga: tile_grid_size, tile_overlap_ratio och tile_predictions_nms_thresh. Mer information om dessa parametrar finns i Träna en modell för identifiering av små objekt med AutoML.
Testa distributionen
Kontrollera det här avsnittet Testa distributionen för att testa distributionen och visualisera identifieringarna från modellen.
Generera förklaringar till förutsägelser
Viktigt!
De här inställningarna är för närvarande i offentlig förhandsversion. De tillhandahålls utan ett serviceavtal. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Varning
Modellförklarbarhet stöds endast för klassificering av flera klasser och klassificering med flera etiketter.
Några av fördelarna med att använda Explainable AI (XAI) med AutoML för bilder:
- Förbättrar transparensen i förutsägelserna för den komplexa visionsmodellen
- Hjälper användarna att förstå viktiga funktioner/bildpunkter i indatabilden som bidrar till modellförutsägelserna
- Hjälper dig att felsöka modellerna
- Hjälper till att upptäcka bias
Förklaringar
Förklaringar är funktionsattributioner eller vikter som ges till varje pixel i indatabilden baserat på dess bidrag till modellens förutsägelse. Varje vikt kan vara negativ (negativt korrelerad med förutsägelsen) eller positiv (positivt korrelerad med förutsägelsen). Dessa attribut beräknas mot den förutsagda klassen. För klassificering med flera klasser genereras exakt en attributionsmatris med storlek [3, valid_crop_size, valid_crop_size] per urval, medan för klassificering med flera etiketter genereras en attributionsmatris av storlek [3, valid_crop_size, valid_crop_size] för varje förutsagd etikett/klass för varje exempel.
Med hjälp av förklarande AI i AutoML för avbildningar på den distribuerade slutpunkten kan användarna få visualiseringar av förklaringar (attribut överlagrade på en indatabild) och/eller attribut (flerdimensionell matris med storlek [3, valid_crop_size, valid_crop_size]) för varje bild. Förutom visualiseringar kan användarna också få attributmatriser för att få mer kontroll över förklaringarna (som att generera anpassade visualiseringar med hjälp av attribut eller granska segment av attribut). Alla förklaringsalgoritmer använder beskurna kvadratbilder med storlek valid_crop_size för att generera attribut.
Förklaringar kan genereras antingen från onlineslutpunkten eller batchslutpunkten. När distributionen är klar kan den här slutpunkten användas för att generera förklaringar till förutsägelser. I onlinedistributioner ser du till att skicka request_settings = OnlineRequestSettings(request_timeout_ms=90000) parametern till ManagedOnlineDeployment och ange request_timeout_ms det högsta värdet för att undvika timeout-problem när du genererar förklaringar (se avsnittet registrera och distribuera modell). Några av XAI-metoderna (explainability) förbrukar xrai mer tid (särskilt för klassificering med flera etiketter eftersom vi behöver generera attribut och/eller visualiseringar mot varje förutsagd etikett). Därför rekommenderar vi alla GPU-instanser för snabbare förklaringar. Mer information om indata- och utdataschema för att generera förklaringar finns i schemadokumenten.
Vi stöder följande toppmoderna förklaringsalgoritmer i AutoML för bilder:
- XRAI (xrai)
- Integrerade toningar (integrated_gradients)
- Guidad GradCAM (guided_gradcam)
- Guidad BackPropagation (guided_backprop)
I följande tabell beskrivs de förklarande algoritmspecifika justeringsparametrarna för XRAI och integrerade toningar. Guidad backpropagation och guidad gradcam kräver inga justeringsparametrar.
| XAI-algoritm | Algoritmspecifika parametrar | Standardvärden |
|---|---|---|
xrai |
1. n_steps: Antalet steg som används av uppskattningsmetoden. Ett större antal steg leder till bättre uppskattning av attribut (förklaringar). Intervallet för n_steps är [2, inf), men prestanda för attribut börjar konvergera efter 50 steg. Optional, Int 2. xrai_fast: Om du vill använda snabbare version av XRAI. if True, är beräkningstiden för förklaringar snabbare men leder till mindre exakta förklaringar (attribut) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: Antalet steg som används av uppskattningsmetoden. Ett större antal steg leder till bättre attribut (förklaringar). Intervallet för n_steps är [2, inf), men prestanda för attribut börjar konvergera efter 50 steg.Optional, Int 2. approximation_method: Metod för att approximera integralen. Tillgängliga uppskattningsmetoder är riemann_middle och gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Internt använder XRAI-algoritmen integrerade toningar. Därför n_steps krävs parametern av både integrerade toningar och XRAI-algoritmer. Ett större antal steg förbrukar mer tid för att approximera förklaringarna och det kan leda till timeout-problem på onlineslutpunkten.
Vi rekommenderar att du använder XRAI > Guided GradCAM > Integrated Gradients > Guided BackPropagation-algoritmer för bättre förklaringar, medan guidad BackPropagation > Guidad GradCAM > Integrated Gradients > XRAI rekommenderas för snabbare förklaringar i den angivna ordningen.
En exempelbegäran till onlineslutpunkten ser ut så här. Den här begäran genererar förklaringar när model_explainability är inställd på True. Följande begäran genererar visualiseringar och attribut med snabbare version av XRAI-algoritmen med 50 steg.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Mer information om hur du genererar förklaringar finns i GitHub Notebook-lagringsplatsen för automatiserade maskininlärningsexempel.
Tolka visualiseringar
Distribuerad slutpunkt returnerar base64-kodad avbildningssträng om båda model_explainability och visualizations är inställda på True. Avkoda base64-strängen enligt beskrivningen i notebook-filer eller använd följande kod för att avkoda och visualisera base64-bildsträngarna i förutsägelsen.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
Följande bild beskriver visualiseringen av förklaringar för en exempelinmatningsbild.

Avkodad base64-figur har fyra bildavsnitt inom ett rutnät på 2 x 2.
- Bild i det övre vänstra hörnet (0, 0) är den beskurna indatabilden
- Bild i övre högra hörnet (0, 1) är värmekartan för attribut på en färgskala bgyw (blå grön gul vit) där bidraget från vita bildpunkter i den förutsagda klassen är den högsta och blå pixlarna är den lägsta.
- Bild i det nedre vänstra hörnet (1, 0) är en blandad värmekarta över attribut på beskuren indatabild
- Bild längst ned till höger (1, 1) är den beskurna indatabilden med de översta 30 procenten av pixlarna baserat på attributionspoäng.
Tolka attribut
Distribuerad slutpunkt returnerar attribut om båda model_explainability och attributions är inställda på True. Mer information finns i notebook-filer för klassificering med flera klasser och notebook-filer för klassificering med flera etiketter.
Dessa attribut ger användarna mer kontroll över att generera anpassade visualiseringar eller granska attributpoäng på pixelnivå. Följande kodfragment beskriver ett sätt att generera anpassade visualiseringar med hjälp av attributionsmatris. Mer information om schemat för attribut för klassificering av flera klasser och klassificering med flera etiketter finns i schemadokumenten.
Använd den valda modellens exakta valid_resize_size värden och valid_crop_size värden för att generera förklaringarna (standardvärdena är 256 respektive 224). Följande kod använder Captum-visualiseringsfunktioner för att generera anpassade visualiseringar. Användare kan använda andra bibliotek för att generera visualiseringar. Mer information finns i kaptumvisualiseringsverktygen.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Stora datamängder
Om du använder AutoML för att träna på stora datamängder finns det några experimentella inställningar som kan vara användbara.
Viktigt!
De här inställningarna är för närvarande i offentlig förhandsversion. De tillhandahålls utan ett serviceavtal. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Träning med flera GPU:ar och flera noder
Som standard tränar varje modell på en enda virtuell dator. Om det tar för lång tid att träna en modell kan det hjälpa att använda virtuella datorer som innehåller flera GPU:er. Tiden för att träna en modell på stora datamängder bör minska i ungefär linjär proportion till antalet GPU:er som används. (En modell bör till exempel träna ungefär dubbelt så snabbt på en virtuell dator med två GPU:er som på en virtuell dator med en GPU.) Om tiden för att träna en modell fortfarande är hög på en virtuell dator med flera GPU:er kan du öka antalet virtuella datorer som används för att träna varje modell. I likhet med träning med flera GPU:er bör tiden för att träna en modell på stora datamängder också minska i ungefär linjär proportion till antalet virtuella datorer som används. När du tränar en modell över flera virtuella datorer bör du använda en beräknings-SKU som stöder InfiniBand för bästa resultat. Du kan konfigurera antalet virtuella datorer som används för att träna en enskild modell genom att ange node_count_per_trial egenskapen för AutoML-jobbet.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
properties:
node_count_per_trial: "2"
Strömma bildfiler från lagring
Som standard laddas alla avbildningsfiler ned till disken före modellträningen. Om storleken på avbildningsfilerna är större än tillgängligt diskutrymme misslyckas jobbet. I stället för att ladda ned alla avbildningar till disken kan du välja att strömma avbildningsfiler från Azure Storage när de behövs under träningen. Avbildningsfiler strömmas från Azure Storage direkt till systemminnet och kringgår disken. Samtidigt cachelagras så många filer som möjligt från lagringen på disken för att minimera antalet begäranden till lagring.
Kommentar
Om strömning är aktiverat kontrollerar du att Azure Storage-kontot finns i samma region som beräkning för att minimera kostnader och svarstider.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Exempelnotebook-filer
Granska detaljerade kodexempel och användningsfall på GitHub-lagringsplatsen med automatiserade maskininlärningsexempel. Kontrollera mapparna med prefixet "automl-image-" för exempel som är specifika för att skapa modeller för visuellt innehåll.
Kodexempel
Granska detaljerade kodexempel och användningsfall på lagringsplatsen azureml-examples för automatiserade maskininlärningsexempel.