Utvärdera resultat från automatiserade maskininlärningsexperiment
I den här artikeln får du lära dig hur du utvärderar och jämför modeller som tränats av ditt automatiserade ML-experiment (automatiserad maskininlärning). Under ett automatiserat ML-experiment skapas många jobb och varje jobb skapar en modell. För varje modell genererar automatiserad ML utvärderingsmått och diagram som hjälper dig att mäta modellens prestanda. Du kan ytterligare generera en ansvarsfull AI-instrumentpanel för att utföra en holistisk utvärdering och felsökning av den rekommenderade bästa modellen som standard. Detta inkluderar insikter som modellförklaringar, rättvise- och prestandautforskaren, datautforskaren, modellfelanalys. Läs mer om hur du kan generera en instrumentpanel för ansvarsfull AI.
Automatiserad ML genererar till exempel följande diagram baserat på experimenttyp.
| Klassificering | Regression/prognostisering |
|---|---|
| Förvirringsmatris | Residualhistogram |
| ROC-kurva | Förutsagt kontra sant |
| Kurva för precision/träffsäkerhet | Prognoshorisont |
| Ökningskurva | |
| Kumulativ ökningskurva | |
| Kalibreringskurva |
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Förhandsversionen tillhandahålls utan ett serviceavtal och rekommenderas inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Förutsättningar
- En Azure-prenumeration. (Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar)
- Ett Azure Machine Learning-experiment som skapats med antingen:
- Azure Machine Learning-studio (ingen kod krävs)
- Azure Machine Learning Python SDK
Visa jobbresultat
När ditt automatiserade ML-experiment har slutförts kan du hitta en historik över jobben via:
- En webbläsare med Azure Machine Learning-studio
- En Jupyter-anteckningsbok med hjälp av Jupyter-widgeten JobDetails
Följande steg och video visar hur du visar körningshistorik och modellutvärderingsmått och diagram i studion:
- Logga in i studion och gå till din arbetsyta.
- I den vänstra menyn väljer du Jobb.
- Välj experimentet i listan över experiment.
- I tabellen längst ned på sidan väljer du ett automatiserat ML-jobb.
- På fliken Modeller väljer du algoritmnamnet för den modell som du vill utvärdera.
- På fliken Mått använder du kryssrutorna till vänster för att visa mått och diagram.
Klassificeringsmått
Automatiserad ML beräknar prestandamått för varje klassificeringsmodell som genereras för experimentet. Dessa mått baseras på implementeringen av scikit learn.
Många klassificeringsmått definieras för binär klassificering i två klasser och kräver genomsnitt över klasser för att producera en poäng för klassificering med flera klasser. Scikit-learn innehåller flera medelvärdesmetoder, varav tre automatiserade ML exponerar: makro, mikro och viktad.
- Makro – Beräkna måttet för varje klass och ta det oviktade genomsnittet
- Micro – Beräkna måttet globalt genom att räkna de totala sanna positiva identifieringarna, falska negativa och falska positiva identifieringar (oberoende av klasser).
- Viktad – Beräkna måttet för varje klass och ta det viktade genomsnittet baserat på antalet exempel per klass.
Varje genomsnittsmetod har sina fördelar, men ett vanligt övervägande när du väljer lämplig metod är klassobalans. Om klasser har olika antal exempel kan det vara mer informativt att använda ett makrogenomsnitt där minoritetsklasser ges samma viktning som majoritetsklasser. Läs mer om binära och flerklassiska mått i automatiserad ML.
I följande tabell sammanfattas de modellprestandamått som automatiserad ML beräknar för varje klassificeringsmodell som genereras för experimentet. Mer information finns i scikit-learn-dokumentationen som är länkad i fältet Beräkning för varje mått.
Kommentar
Mer information om mått för bildklassificeringsmodeller finns i avsnittet bildmått.
| Mätvärde | Beskrivning | Beräkning |
|---|---|---|
| AUC | AUC är området under mottagarens operativa egenskapskurva. Mål: Närmare 1 desto bättre Intervall: [0, 1] Måttnamn som stöds är, AUC_macro, det aritmetiska medelvärdet för AUC för varje klass.AUC_micro, beräknad genom att räkna de totala sanna positiva identifieringarna, falska negativa och falska positiva identifieringar. AUC_weighted, aritmetiskt medelvärde för poängen för varje klass, viktat med antalet sanna instanser i varje klass. AUC_binary, värdet för AUC genom att behandla en specifik klass som true klass och kombinera alla andra klasser som false klass. |
Beräkning |
| accuracy | Noggrannhet är förhållandet mellan förutsägelser som exakt matchar de sanna klassetiketterna. Mål: Närmare 1 desto bättre Intervall: [0, 1] |
Beräkning |
| average_precision | Genomsnittlig precision sammanfattar en precisionsåterkallningskurva som det viktade medelvärdet av precisioner som uppnås vid varje tröskelvärde, med ökningen av återkallande från det tidigare tröskelvärdet som används som vikt. Mål: Närmare 1 desto bättre Intervall: [0, 1] Måttnamn som stöds är, average_precision_score_macro, det aritmetiska medelvärdet för den genomsnittliga precisionspoängen för varje klass.average_precision_score_micro, beräknad genom att räkna de totala sanna positiva identifieringarna, falska negativa och falska positiva identifieringar.average_precision_score_weighted, det aritmetiska medelvärdet för den genomsnittliga precisionspoängen för varje klass, viktat med antalet sanna instanser i varje klass. average_precision_score_binary, värdet för genomsnittlig precision genom att behandla en specifik klass som true klass och kombinera alla andra klasser som false klass. |
Beräkning |
| balanced_accuracy | Balanserad noggrannhet är det aritmetiska medelvärdet av återkallande för varje klass. Mål: Närmare 1 desto bättre Intervall: [0, 1] |
Beräkning |
| f1_score | F1-poäng är det harmoniska medelvärdet av precision och träffsäkerhet. Det är ett balanserat mått på både falska positiva och falska negativa. Det tar dock inte hänsyn till sanna negativa identifieringar. Mål: Närmare 1 desto bättre Intervall: [0, 1] Måttnamn som stöds är, f1_score_macro: det aritmetiska medelvärdet av F1-poängen för varje klass. f1_score_micro: beräknas genom att räkna det totala antalet sanna positiva identifieringar, falska negativa och falska positiva identifieringar. f1_score_weighted: viktat medelvärde efter klassfrekvens för F1-poäng för varje klass. f1_score_binary, värdet för f1 genom att behandla en specifik klass som true klass och kombinera alla andra klasser som false klass. |
Beräkning |
| log_loss | Det här är den förlustfunktion som används i (multinomiell) logistisk regression och tillägg av den, till exempel neurala nätverk, som definieras som den negativa logg-sannolikheten för de sanna etiketterna med tanke på en probabilistisk klassificerares förutsägelser. Mål: Närmare 0 desto bättre Intervall: [0, inf) |
Beräkning |
| norm_macro_recall | Normaliserad makroåterkallning återkallar makro i genomsnitt och normaliseras, så att slumpmässiga prestanda har en poäng på 0 och perfekt prestanda har en poäng på 1. Mål: Närmare 1 desto bättre Intervall: [0, 1] |
(recall_score_macro - R) / (1 - R) där är R det förväntade värdet recall_score_macro för för slumpmässiga förutsägelser.R = 0.5 för binär klassificering. R = (1 / C) för klassificeringsproblem med C-klass. |
| matthews_correlation | Matthews korrelationskoefficient är ett balanserat mått på noggrannhet, som kan användas även om en klass har många fler exempel än en annan. En koefficient på 1 indikerar perfekt förutsägelse, 0 slumpmässig förutsägelse och -1 inverterad förutsägelse. Mål: Närmare 1 desto bättre Intervall: [-1, 1] |
Beräkning |
| precision | Precision är en modells förmåga att undvika att märka negativa exempel som positiva. Mål: Närmare 1 desto bättre Intervall: [0, 1] Måttnamn som stöds är, precision_score_macro, det aritmetiska precisionsvärdet för varje klass. precision_score_micro, beräknas globalt genom att räkna de totala sanna positiva och falska positiva identifieringarna. precision_score_weighted, det aritmetiska precisionsvärdet för varje klass, viktat med antalet sanna instanser i varje klass. precision_score_binary, värdet för precision genom att behandla en specifik klass som true klass och kombinera alla andra klasser som false klass. |
Beräkning |
| återkallande | Recall är möjligheten för en modell att identifiera alla positiva exempel. Mål: Närmare 1 desto bättre Intervall: [0, 1] Måttnamn som stöds är, recall_score_macro: det aritmetiska medelvärdet av återkallande för varje klass. recall_score_micro: beräknas globalt genom att räkna de totala sanna positiva identifieringarna, falska negativa och falska positiva identifieringar.recall_score_weighted: det aritmetiska medelvärdet av återkallande för varje klass, viktat med antalet sanna instanser i varje klass. recall_score_binary, värdet för återkallande genom att behandla en specifik klass som true klass och kombinera alla andra klasser som false klass. |
Beräkning |
| weighted_accuracy | Viktad noggrannhet är noggrannhet där varje prov viktas av det totala antalet prover som hör till samma klass. Mål: Närmare 1 desto bättre Intervall: [0, 1] |
Beräkning |
Klassificeringsmått för binär jämfört med flera klasser
Automatiserad ML identifierar automatiskt om data är binära och tillåter även användare att aktivera binära klassificeringsmått även om data är flerklassiga genom att ange en true klass. Klassificeringsmått för flera klasser rapporteras om en datauppsättning har två eller flera klasser. Binära klassificeringsmått rapporteras endast när data är binära.
Observera att klassificeringsmått för flera klasser är avsedda för klassificering med flera klasser. När de tillämpas på en binär datauppsättning behandlar dessa mått inte någon klass som true klassen, som du kan förvänta dig. Mått som är tydligt avsedda för multiklasser är suffix med micro, macroeller weighted. Exempel är average_precision_score, f1_score, precision_score, recall_scoreoch AUC. I stället för att beräkna återkallande som tp / (tp + fn), medelvärdet för genomsnittligt återkallande av flera klasser (micro, macro, eller weighted) över båda klasserna i en binär klassificeringsdatauppsättning. Detta motsvarar att beräkna återkallelsen true för klassen och false klassen separat och sedan ta medelvärdet av de två.
Även om automatisk identifiering av binär klassificering stöds rekommenderar vi ändå att du alltid anger true klassen manuellt för att se till att de binära klassificeringsmåtten beräknas för rätt klass.
För att aktivera mått för binära klassificeringsdatauppsättningar när själva datauppsättningen är multiklass behöver användarna bara ange vilken klass som ska behandlas som true klass och dessa mått beräknas.
Förvirringsmatris
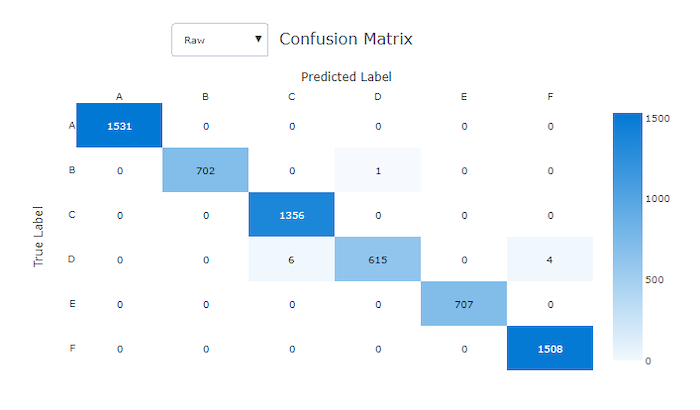
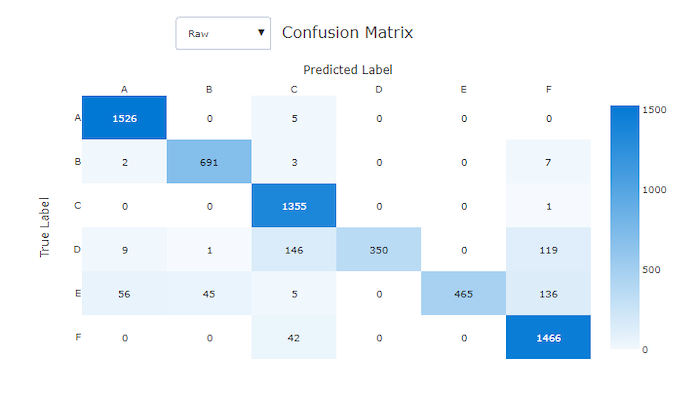
Förvirringsmatriser ger ett visuellt objekt för hur en maskininlärningsmodell gör systematiska fel i sina förutsägelser för klassificeringsmodeller. Ordet "förvirring" i namnet kommer från en modell som är "förvirrande" eller felmärkta exempel. En cell på rad i och kolumn j i en förvirringsmatris innehåller antalet exempel i utvärderingsdatauppsättningen som tillhör klassen C_i och klassificeras av modellen som klass C_j.
I studion indikerar en mörkare cell ett högre antal exempel. Om du väljer Normaliserad vy i listrutan normaliseras över varje matrisrad för att visa den procent av klassen C_i som förutsägs vara klass C_j. Fördelen med standardvyn raw är att du kan se om obalansen i fördelningen av faktiska klasser gjorde att modellen felklassificerade exempel från minoritetsklassen, ett vanligt problem i obalanserade datamängder.
Förvirringsmatrisen för en bra modell har de flesta prover längs diagonalen.
Förvirringsmatris för en bra modell
Förvirringsmatris för en dålig modell
ROC-kurva
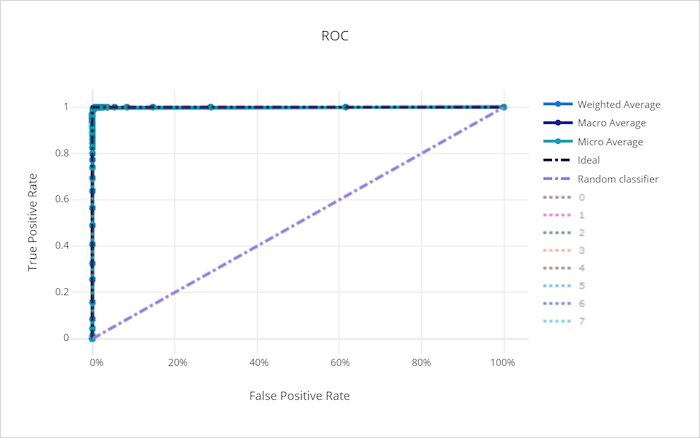
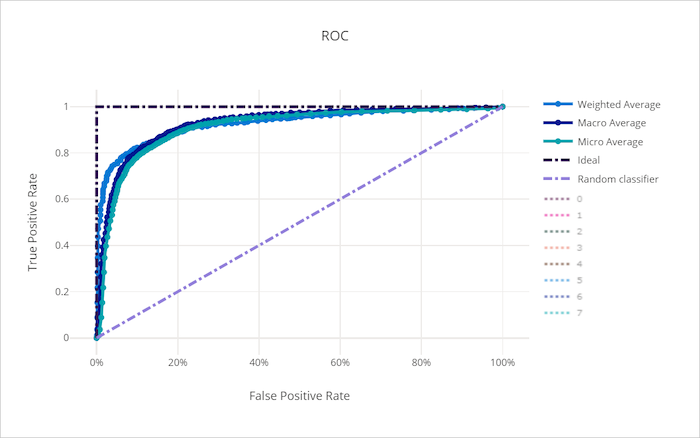
ROC-kurvan (receiver operating characteristic) ritar relationen mellan sann positiv frekvens (TPR) och falsk positiv frekvens (FPR) när beslutströskeln ändras. ROC-kurvan kan vara mindre informativ när du tränar modeller på datauppsättningar med hög klassobalans, eftersom majoritetsklassen kan överrösta bidrag från minoritetsklasser.
Området under kurvan (AUC) kan tolkas som andelen korrekt klassificerade prover. Mer exakt är AUC sannolikheten att klassificeraren rangordnar ett slumpmässigt valt positivt urval högre än ett slumpmässigt valt negativt urval. Kurvans form ger en intuition för relationen mellan TPR och FPR som en funktion av klassificeringströskeln eller beslutsgränsen.
En kurva som närmar sig diagrammets övre vänstra hörn närmar sig en 100 % TPR och 0 % FPR, den bästa möjliga modellen. En slumpmässig modell skulle skapa en ROC-kurva längs y = x linjen från det nedre vänstra hörnet till det övre högra hörnet. En sämre modell än en slumpmässig modell skulle ha en ROC-kurva som sjunker under y = x linjen.
Dricks
För klassificeringsexperiment kan vart och ett av linjediagrammen som skapats för automatiserade ML-modeller användas för att utvärdera modellen per klass eller i genomsnitt för alla klasser. Du kan växla mellan dessa olika vyer genom att klicka på klassetiketter i förklaringen till höger om diagrammet.
ROC-kurva för en bra modell
ROC-kurva för en dålig modell
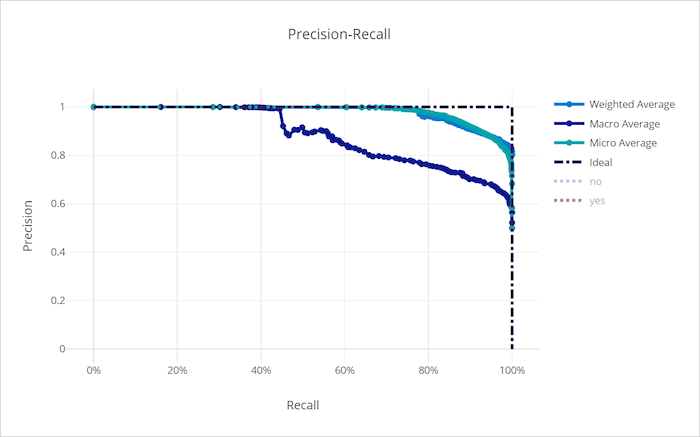
Precisionsåterkallningskurva
Precisionsåterkallningskurvan ritar relationen mellan precision och återkallande när beslutströskeln ändras. Kom ihåg att en modell kan identifiera alla positiva exempel och precision är en modells förmåga att undvika att märka negativa exempel som positiva. Vissa affärsproblem kan kräva högre träffsäkerhet och viss högre precision beroende på den relativa vikten av att undvika falska negativa eller falska positiva identifieringar.
Dricks
För klassificeringsexperiment kan vart och ett av linjediagrammen som skapats för automatiserade ML-modeller användas för att utvärdera modellen per klass eller i genomsnitt för alla klasser. Du kan växla mellan dessa olika vyer genom att klicka på klassetiketter i förklaringen till höger om diagrammet.
Precisionsåterkallningskurva för en bra modell
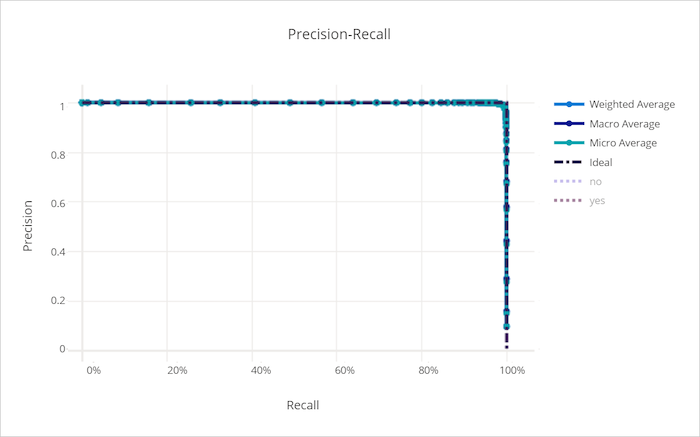
Precisionsåterkallningskurva för en dålig modell
Kumulativ ökningskurva
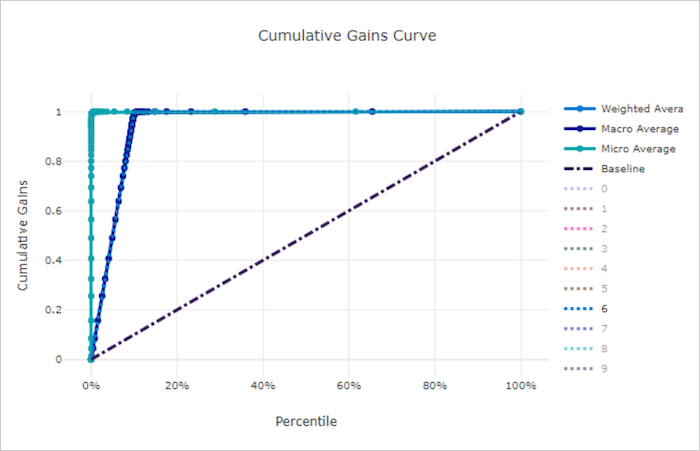
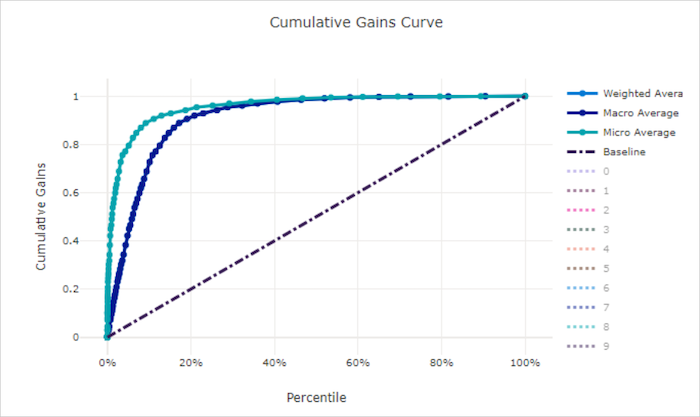
Den kumulativa vinstkurvan ritar procenten av positiva prover korrekt klassificerade som en funktion av procenten av de prover som beaktas när vi överväger prover i den ordning som förutsägs.
Om du vill beräkna vinst sorterar du först alla prover från högsta till lägsta sannolikhet som förutsägs av modellen. x% Ta sedan de högsta konfidensförutsägelserna. Dividera antalet positiva prover som identifierats i det med det x% totala antalet positiva prover för att få vinsten. Kumulativ vinst är procentandelen positiva exempel som vi identifierar när vi överväger några procent av de data som mest sannolikt tillhör den positiva klassen.
En perfekt modell rangordnar alla positiva exempel framför alla negativa exempel som ger en kumulativ vinstkurva som består av två raka segment. Den första är en linje med lutning 1 / x från (0, 0) till (x, 1) där x är fraktionen av exempel som tillhör den positiva klassen (1 / num_classes om klasserna är balanserade). Den andra är en vågrät linje från (x, 1) till (1, 1). I det första segmentet klassificeras alla positiva prover korrekt och kumulativ vinst går till 100% inom det första x% av de prover som beaktas.
Den slumpmässiga baslinjemodellen har en kumulativ vinstkurva y = x där för x% prover som endast anses vara ungefär x% av de totala positiva exemplen upptäcktes. En perfekt modell för en balanserad datamängd har en mikrogenomsnittskurva och en makrogenomsnittslinje som har lutning num_classes tills den kumulativa vinsten är 100 % och sedan horisontell tills dataprocenten är 100.
Dricks
För klassificeringsexperiment kan vart och ett av linjediagrammen som skapats för automatiserade ML-modeller användas för att utvärdera modellen per klass eller i genomsnitt för alla klasser. Du kan växla mellan dessa olika vyer genom att klicka på klassetiketter i förklaringen till höger om diagrammet.
Kumulativ vinstkurva för en bra modell
Kumulativ vinstkurva för en dålig modell
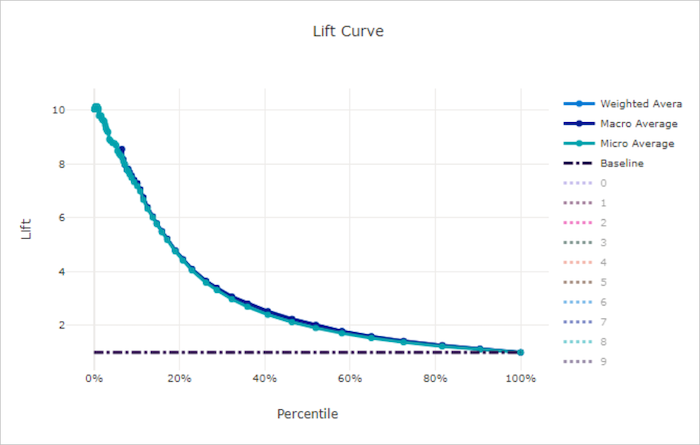
Ökningskurva
Lyftkurvan visar hur många gånger bättre en modell presterar jämfört med en slumpmässig modell. Lyft definieras som förhållandet mellan kumulativ vinst och den kumulativa vinsten av en slumpmässig modell (som alltid ska vara 1).
Den här relativa prestandan tar hänsyn till det faktum att klassificeringen blir svårare när du ökar antalet klasser. (En slumpmässig modell förutsäger felaktigt en högre del av exemplen från en datamängd med 10 klasser jämfört med en datauppsättning med två klasser)
Baslinjelyftkurvan är den y = 1 linje där modellprestandan är konsekvent med den för en slumpmässig modell. I allmänhet är lyftkurvan för en bra modell högre på diagrammet och längre från x-axeln, vilket visar att när modellen är mest säker på sina förutsägelser presterar den många gånger bättre än slumpmässig gissning.
Dricks
För klassificeringsexperiment kan vart och ett av linjediagrammen som skapats för automatiserade ML-modeller användas för att utvärdera modellen per klass eller i genomsnitt för alla klasser. Du kan växla mellan dessa olika vyer genom att klicka på klassetiketter i förklaringen till höger om diagrammet.
Lyftkurva för en bra modell
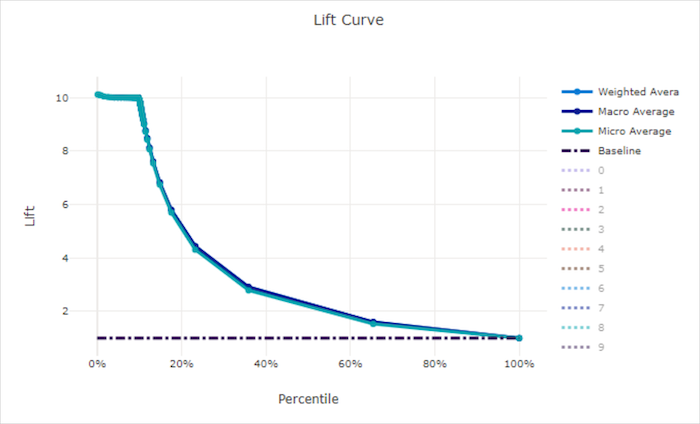
Lyftkurva för en dålig modell
Kalibreringskurva
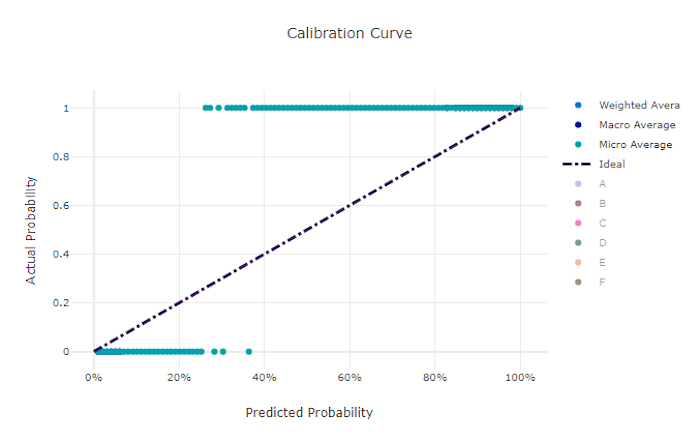
Kalibreringskurvan ritar en modells förtroende för sina förutsägelser mot andelen positiva prover på varje konfidensnivå. En välkalibrerad modell klassificerar korrekt 100 % av de förutsägelser som den tilldelar 100 % konfidens, 50 % av de förutsägelser som tilldelas 50 % konfidens, 20 % av de förutsägelser som tilldelas 20 % konfidens och så vidare. En perfekt kalibrerad modell har en kalibreringskurva som följer linjen y = x där modellen perfekt förutsäger sannolikheten att prover tillhör varje klass.
En översäker modell förutsäger sannolikheter nära noll och en, och är sällan osäker på klassen för varje prov och kalibreringskurvan ser ut ungefär som bakåt "S". En undersäker modell tilldelar i genomsnitt en lägre sannolikhet till den klass som den förutsäger och den associerade kalibreringskurvan ser ut ungefär som ett "S". Kalibreringskurvan visar inte en modells förmåga att klassificera korrekt, utan i stället dess förmåga att korrekt tilldela konfidens till sina förutsägelser. En dålig modell kan fortfarande ha en bra kalibreringskurva om modellen korrekt tilldelar låg konfidens och hög osäkerhet.
Kommentar
Kalibreringskurvan är känslig för antalet prover, så en liten valideringsuppsättning kan ge bullriga resultat som kan vara svåra att tolka. Detta innebär inte nödvändigtvis att modellen inte är väl kalibrerad.
Kalibreringskurva för en bra modell
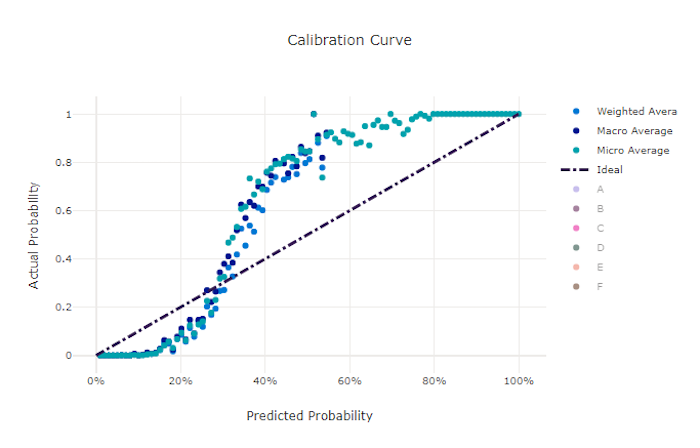
Kalibreringskurva för en dålig modell
Regressions-/prognostiseringsmått
Automatiserad ML beräknar samma prestandamått för varje modell som genereras, oavsett om det är ett regressions- eller prognosexperiment. Dessa mått genomgår också normalisering för att möjliggöra jämförelse mellan modeller som tränats på data med olika intervall. Mer information finns i måttnormalisering.
I följande tabell sammanfattas de modellprestandamått som genererats för regressions- och prognosexperiment. Precis som klassificeringsmått baseras dessa mått också på scikit learn-implementeringarna. Lämplig scikit learn-dokumentation länkas i enlighet med detta i fältet Beräkning .
| Mätvärde | Beskrivning | Beräkning |
|---|---|---|
| explained_variance | Förklarad varians mäter i vilken utsträckning en modell står för variationen i målvariabeln. Det är den procentuella minskningen av variansen för de ursprungliga data till variansen för felen. När medelvärdet för felen är 0 är det lika med bestämningskoefficienten (se r2_score i följande diagram). Mål: Närmare 1 desto bättre Intervall: (-inf, 1] |
Beräkning |
| mean_absolute_error | Genomsnittligt absolut fel är det förväntade värdet för absolut skillnad mellan målet och förutsägelsen. Mål: Närmare 0 desto bättre Intervall: [0, inf) Typer: mean_absolute_error normalized_mean_absolute_error, mean_absolute_error dividerat med dataområdet. |
Beräkning |
| mean_absolute_percentage_error | Genomsnittligt absolut procentfel (MAPE) är ett mått på den genomsnittliga skillnaden mellan ett förutsagt värde och det faktiska värdet. Mål: Närmare 0 desto bättre Intervall: [0, inf) |
|
| median_absolute_error | Absolut medianfel är medianvärdet för alla absoluta skillnader mellan målet och förutsägelsen. Den här förlusten är robust för extremvärden. Mål: Närmare 0 desto bättre Intervall: [0, inf) Typer: median_absolute_errornormalized_median_absolute_error: median_absolute_error dividerat med dataområdet. |
Beräkning |
| r2_score | R2 (bestämningskoefficienten) mäter den proportionella minskningen av genomsnittligt kvadratfel (MSE) i förhållande till den totala variansen av observerade data. Mål: Närmare 1 desto bättre Intervall: [-1, 1] Obs! R2 har ofta intervallet (-inf, 1]. MSE kan vara större än den observerade variansen, så R2 kan ha godtyckligt stora negativa värden, beroende på data och modellförutsägelser. Automatiserade ML-klipp rapporterade R2-poäng vid -1, så ett värde på -1 för R2 innebär sannolikt att den sanna R2-poängen är mindre än -1. Tänk på de andra måttvärdena och egenskaperna för data när du tolkar en negativ R2-poäng . |
Beräkning |
| root_mean_squared_error | RMSE (Root Mean Squared Error) är kvadratroten för den förväntade kvadratskillnaden mellan målet och förutsägelsen. För en opartisk skattare är RMSE lika med standardavvikelsen. Mål: Närmare 0 desto bättre Intervall: [0, inf) Typer: root_mean_squared_error normalized_root_mean_squared_error: root_mean_squared_error dividerat med dataområdet. |
Beräkning |
| root_mean_squared_log_error | Rotvärdets kvadratiska loggfel är kvadratroten för det förväntade kvadratiska logaritmiska felet. Mål: Närmare 0 desto bättre Intervall: [0, inf) Typer: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error dividerat med dataområdet. |
Beräkning |
| spearman_correlation | Spearman-korrelation är ett icke-parametriskt mått på monotoniteten i relationen mellan två datauppsättningar. Till skillnad från Pearson-korrelationen förutsätter inte Spearman-korrelationen att båda datauppsättningarna normalt distribueras. Liksom andra korrelationskoefficienter varierar Spearman mellan -1 och 1 med 0 vilket innebär att ingen korrelation. Korrelationer av -1 eller 1 innebär en exakt monoton relation. Spearman är ett korrelationsmått för rangordning, vilket innebär att ändringar i förutsagda eller faktiska värden inte ändrar Spearman-resultatet om de inte ändrar rangordningen för förutsagda eller faktiska värden. Mål: Närmare 1 desto bättre Intervall: [-1, 1] |
Beräkning |
Måttnormalisering
Automatiserad ML normaliserar regressions- och prognosmått, vilket möjliggör jämförelse mellan modeller som tränats på data med olika intervall. En modell som tränas på data med ett större intervall har ett högre fel än samma modell som tränats på data med ett mindre intervall, såvida inte felet normaliseras.
Även om det inte finns någon standardmetod för normalisering av felmått använder automatiserad ML den gemensamma metoden för att dividera felet med dataintervallet: normalized_error = error / (y_max - y_min)
Kommentar
Dataområdet sparas inte med modellen. Om du drar slutsatsdragning med samma modell på en holdout-testuppsättning y_min och y_max kan ändras beroende på testdata och normaliserade mått kanske inte används direkt för att jämföra modellens prestanda på tränings- och testuppsättningar. Du kan skicka in värdet för y_min och y_max från din träningsuppsättning för att göra jämförelsen rättvis.
Prognostiseringsmått: normalisering och aggregering
Beräkning av mått för utvärdering av prognosmodeller kräver vissa särskilda överväganden när data innehåller flera tidsserier. Det finns två naturliga alternativ för att aggregera mått över flera serier:
- Ett makrogenomsnitt där utvärderingsmåtten från varje serie ges samma vikt,
- Ett mikrogenomsnitt där utvärderingsmått för varje förutsägelse har samma vikt.
Dessa fall har direkta analogier till makro- och mikrogenomsnitt i klassificering med flera klasser.
Skillnaden mellan makro- och mikrogenomsnitt kan vara viktig när du väljer ett primärt mått för modellval. Tänk dig till exempel ett detaljhandelsscenario där du vill prognostisera efterfrågan på ett urval av konsumentprodukter. Vissa produkter säljer till högre volymer än andra. Om du väljer en rmse med mikrogenomsnitt som primärt mått är det möjligt att objekt med stora volymer bidrar med det mesta av modellfelet och därför dominerar måttet. Modellvalsalgoritmen kan gynna modeller med högre noggrannhet på högvolymobjekten än på lågvolymobjekten. Däremot ger en makrogenomsnittsbaserad, normaliserad RMSE objekt med låg volym ungefär lika stor vikt som objekt med hög volym.
I följande tabell visas vilken av AutoML:s prognosmått som använder makro jämfört med mikrogenomsnitt:
| Makro i genomsnitt | Mikrogenomsnitt |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, , normalized_root_mean_squared_errornormalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, , explained_variance, , spearman_correlationmean_absolute_percentage_error |
Observera att makrogenomsnittsmått normaliserar varje serie separat. De normaliserade måtten från varje serie beräknas sedan i genomsnitt för att ge slutresultatet. Rätt val av makro jämfört med mikro beror på affärsscenariot, men vi rekommenderar vanligtvis att du använder normalized_root_mean_squared_error.
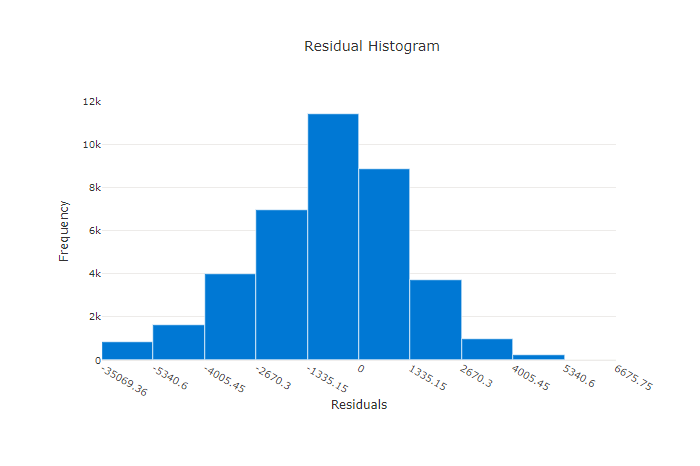
Residualer
Residualdiagrammet är ett histogram över de förutsägelsefel (residualer) som genereras för regressions- och prognosexperiment. Residualer beräknas som y_predicted - y_true för alla exempel och visas sedan som ett histogram för att visa modellförskjutning.
I det här exemplet är båda modellerna något partiska för att förutsäga lägre än det faktiska värdet. Detta är inte ovanligt för en datauppsättning med en skev fördelning av faktiska mål, men indikerar sämre modellprestanda. En bra modell har en residualfördelning som toppar på noll med få rester i extremlägen. En sämre modell har en utspridd residualfördelning med färre prover runt noll.
Residualdiagram för en bra modell
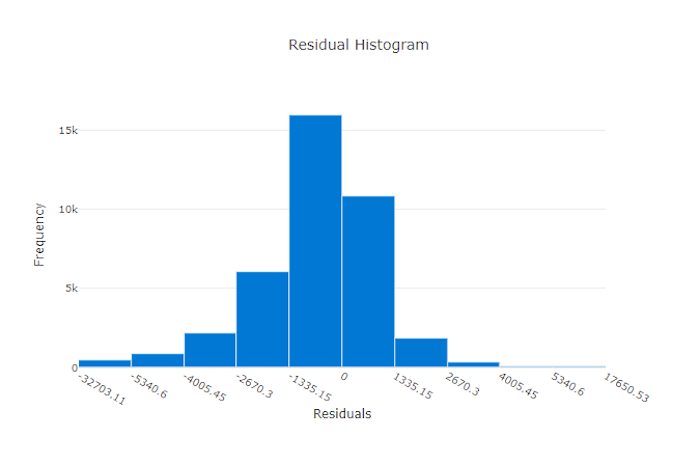
Residualdiagram för en felaktig modell
Förutsagt kontra sant
För regressions- och prognosexperiment ritar det förutsagda eller sanna diagrammet relationen mellan målfunktionen (sanna/faktiska värden) och modellens förutsägelser. De sanna värdena är indelade längs x-axeln och för varje lagerplats ritas det förväntade medelvärdet med felstaplar. På så sätt kan du se om en modell är partisk mot att förutsäga vissa värden. Raden visar den genomsnittliga förutsägelsen och det skuggade området anger variansen för förutsägelser kring det medelvärdet.
Ofta har det vanligaste sanna värdet de mest exakta förutsägelserna med den lägsta variansen. Trendlinjens avstånd från den idealiska y = x linjen där det finns få sanna värden är ett bra mått på modellprestanda på avvikande värden. Du kan använda histogrammet längst ned i diagrammet för att resonera om den faktiska datafördelningen. Om du inkluderar fler dataexempel där fördelningen är gles kan du förbättra modellens prestanda för osedda data.
Observera i det här exemplet att den bättre modellen har en förutsagd kontra sann linje som ligger närmare den idealiska y = x linjen.
Förutsagt kontra sant diagram för en bra modell
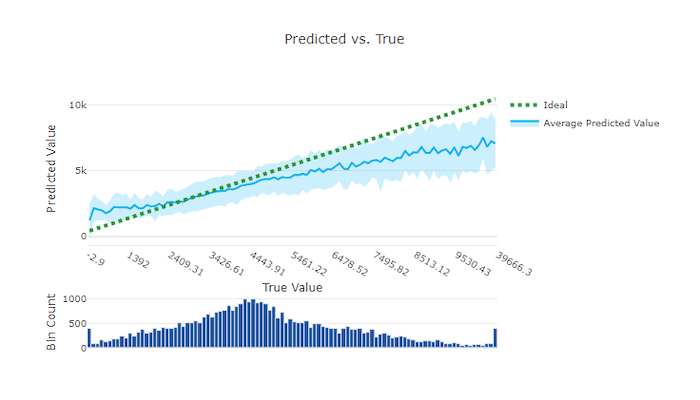
Förutsagt kontra sant diagram för en dålig modell

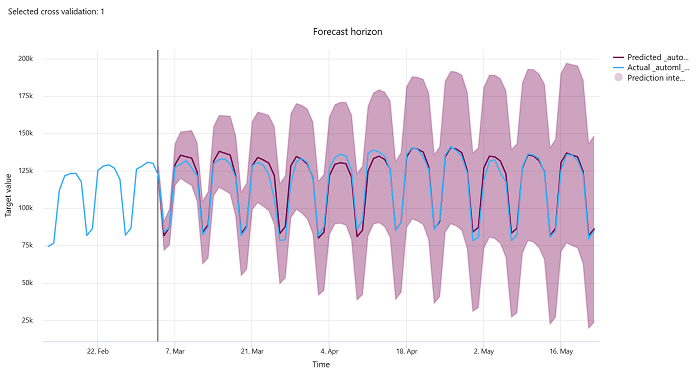
Prognoshorisont
För prognosexperiment ritar prognoshorisontdiagrammet relationen mellan modellernas förutsagda värde och de faktiska värdena som mappas över tid per korsvalideringsveck, upp till fem gånger. X-axeln mappar tid baserat på den frekvens som du angav under träningskonfigurationen. Den lodräta linjen i diagrammet markerar prognoshorisontpunkten som även kallas horisontlinjen, vilket är den tidsperiod då du vill börja generera förutsägelser. Till vänster om prognoshorisontlinjen kan du visa historiska träningsdata för att bättre visualisera tidigare trender. Till höger om prognoshorisonten kan du visualisera förutsägelserna (den lila linjen) mot de faktiska (den blå linjen) för de olika korsvalideringsveckningarna och tidsserieidentifierarna. Det skuggade lila området anger konfidensintervallen eller variansen för förutsägelser kring det medelvärdet.
Du kan välja vilka kombinationer av korsvaliderings- och tidsserieidentifierare som ska visas genom att klicka på den redigerade pennikonen i diagrammets övre högra hörn. Välj bland de första fem korsvalideringsdelegeringarna och upp till 20 olika tidsserieidentifierare för att visualisera diagrammet för dina olika tidsserier.
Viktigt!
Det här diagrammet är tillgängligt i träningskörningen för modeller som genererats från tränings- och valideringsdata samt i testkörningen baserat på träningsdata och testdata. Vi tillåter upp till 20 datapunkter före och upp till 80 datapunkter efter prognosens ursprung. För DNN-modeller visar det här diagrammet i träningskörningen data från den senaste epoken, dvs. efter att modellen har tränats helt. Det här diagrammet i testkörningen kan ha ett mellanrum före horisontlinjen om valideringsdata uttryckligen angavs under träningskörningen. Detta beror på att träningsdata och testdata används i testkörningen och utelämnar valideringsdata, vilket resulterar i luckor.
Mått för bildmodeller (förhandsversion)
Automatiserad ML använder avbildningarna från valideringsdatauppsättningen för att utvärdera modellens prestanda. Modellens prestanda mäts på epoknivå för att förstå hur träningen fortskrider. En epok förflutit när en hel datamängd skickas framåt och bakåt genom det neurala nätverket exakt en gång.
Bildklassificeringsmått
Det primära måttet för utvärdering är noggrannhet för binär- och flerklassiga klassificeringsmodeller och IoU (skärningspunkt över union) för klassificeringsmodeller med flera etiketter. Klassificeringsmåtten för bildklassificeringsmodeller är desamma som de som definieras i avsnittet klassificeringsmått . De förlustvärden som är associerade med en epok loggas också som kan hjälpa till att övervaka hur träningen fortskrider och avgöra om modellen är överpassande eller underpassande.
Varje förutsägelse från en klassificeringsmodell är associerad med en konfidenspoäng, vilket anger den konfidensnivå som förutsägelsen gjordes med. Multilabel-bildklassificeringsmodeller utvärderas som standard med ett poängtröskelvärde på 0,5, vilket innebär att endast förutsägelser med minst den här konfidensnivån betraktas som en positiv förutsägelse för den associerade klassen. Multiklassklassificering använder inte ett poängtröskelvärde, utan i stället betraktas klassen med den maximala konfidenspoängen som förutsägelse.
Mått på epoknivå för bildklassificering
Till skillnad från klassificeringsstatistiken för tabelldatauppsättningar loggar bildklassificeringsmodeller alla klassificeringsmått på epoknivå enligt nedan.
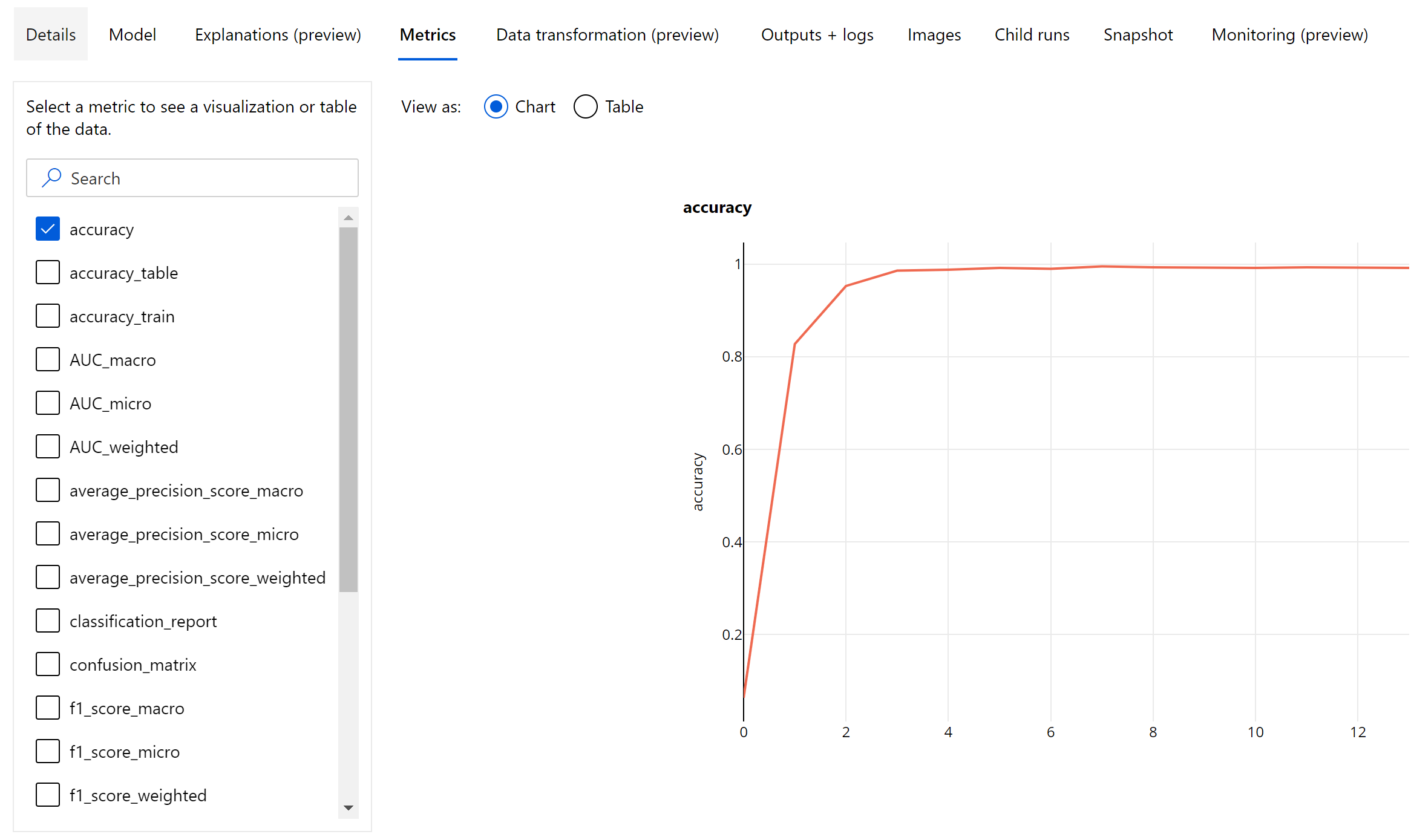
Sammanfattningsmått för bildklassificering
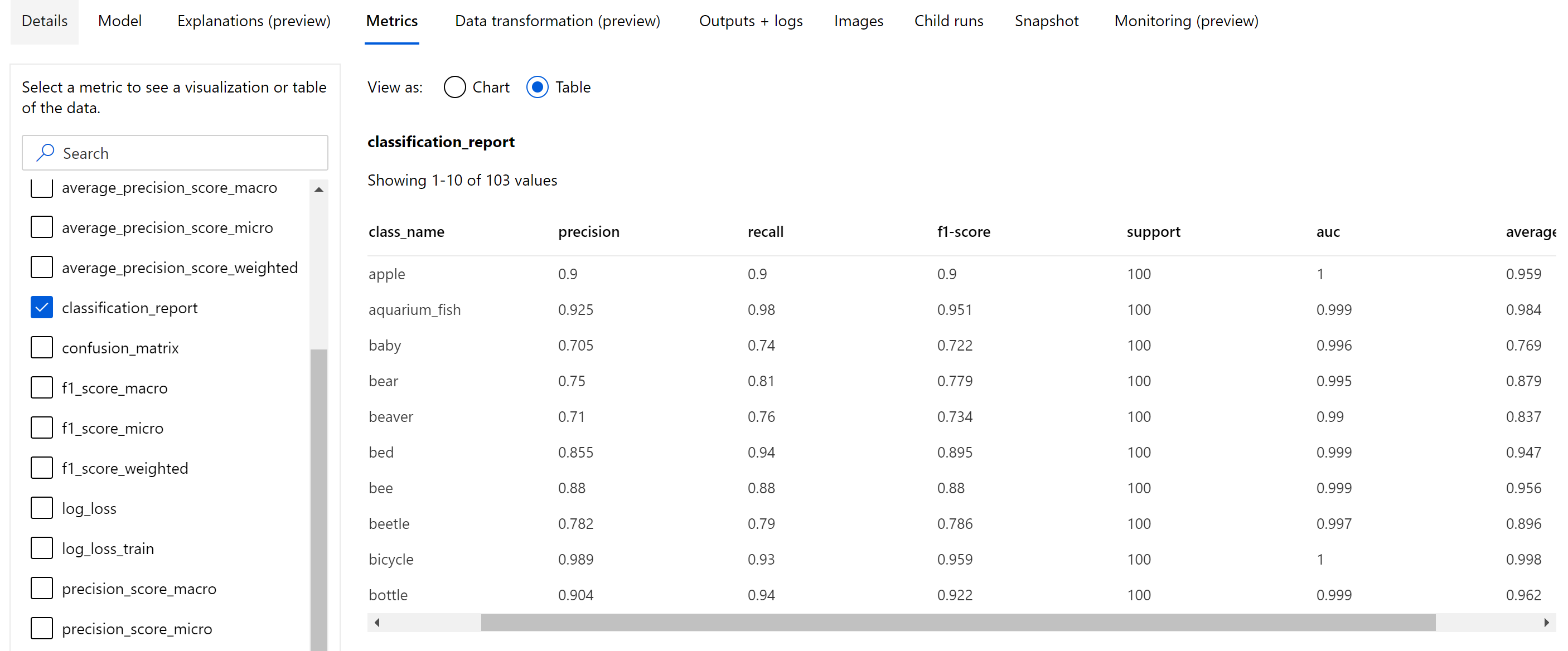
Förutom de skalärmått som loggas på epoknivå loggar bildklassificeringsmodellen även sammanfattningsmått som förvirringsmatris, klassificeringsdiagram inklusive ROC-kurva, precisionsåterkallningskurva och klassificeringsrapport för modellen från den bästa epoken där vi får den högsta primära måttpoängen (noggrannhet).
Klassificeringsrapporten innehåller klassnivåvärden för mått som precision, återkallande, f1-poäng, stöd, auc och average_precision med olika genomsnittsnivå – mikro, makro och viktat enligt nedan. Se måttdefinitionerna från avsnittet klassificeringsmått .
Mått för objektidentifiering och instanssegmentering
Varje förutsägelse från en bildobjektidentifiering eller instanssegmenteringsmodell är associerad med en konfidenspoäng.
Förutsägelserna med förtroendepoäng som är större än poängtröskelvärdet är utdata som förutsägelser och används i måttberäkningen, vars standardvärde är modellspecifikt och kan refereras från hyperparameterns justeringssida (box_score_threshold hyperparameter).
Måttberäkningen för en bildobjektidentifiering och instanssegmenteringsmodell baseras på en överlappningsmätning som definieras av ett mått som kallas IoU (skärningspunkt över union) som beräknas genom att dela överlappningsområdet mellan mark-sanningen och förutsägelserna efter unionsområdet för mark-sanningen och förutsägelserna. Den IoU som beräknas från varje förutsägelse jämförs med ett överlappande tröskelvärde som kallas ett IoU-tröskelvärde, som avgör hur mycket en förutsägelse ska överlappa med en användaranteckningsgrundssanning för att betraktas som en positiv förutsägelse. Om den IoU som beräknas från förutsägelsen är mindre än överlappningströskeln skulle förutsägelsen inte betraktas som en positiv förutsägelse för den associerade klassen.
Det primära måttet för utvärdering av modeller för identifiering av bildobjekt och instanssegmentering är mAP (mean average precision). mAP är det genomsnittliga värdet för den genomsnittliga precisionen (AP) för alla klasser. Automatiserade ML-objektidentifieringsmodeller stöder beräkningen av mAP med hjälp av de två populära metoderna nedan.
Pascal VOC-mått:
Pascal VOC mAP är standardsättet för mAP-beräkning för objektidentifiering/instanssegmenteringsmodeller. Pascal VOC-format mAP-metoden beräknar området under en version av precisionsåterkallningskurvan. First p(ri), som är precision vid recall i beräknas för alla unika återkallningsvärden. p(ri) ersätts sedan med maximal precision som erhålls för alla recall r' >= ri. Precisionsvärdet minskar monotont i den här versionen av kurvan. Pascal VOC mAP-mått utvärderas som standard med ett IoU-tröskelvärde på 0,5. En detaljerad förklaring av det här konceptet finns i den här bloggen.
COCO-mått:
COCO-utvärderingsmetoden använder en 101-punkts interpolerad metod för AP-beräkning tillsammans med i genomsnitt över tio IoU-tröskelvärden. AP@[.5:.95] motsvarar den genomsnittliga AP:en för IoU från 0,5 till 0,95 med en stegstorlek på 0,05. Automatiserad ML loggar alla 12 mått som definierats av COCO-metoden, inklusive AP och AR (genomsnittlig återkallelse) i olika skalor i programloggarna medan måttens användargränssnitt endast visar mAP vid ett IoU-tröskelvärde på 0,5.
Dricks
Utvärderingen av bildobjektidentifieringsmodellen kan använda coco-mått om validation_metric_type hyperparametern är inställd på "coco" enligt beskrivningen i avsnittet för justering av hyperparameter .
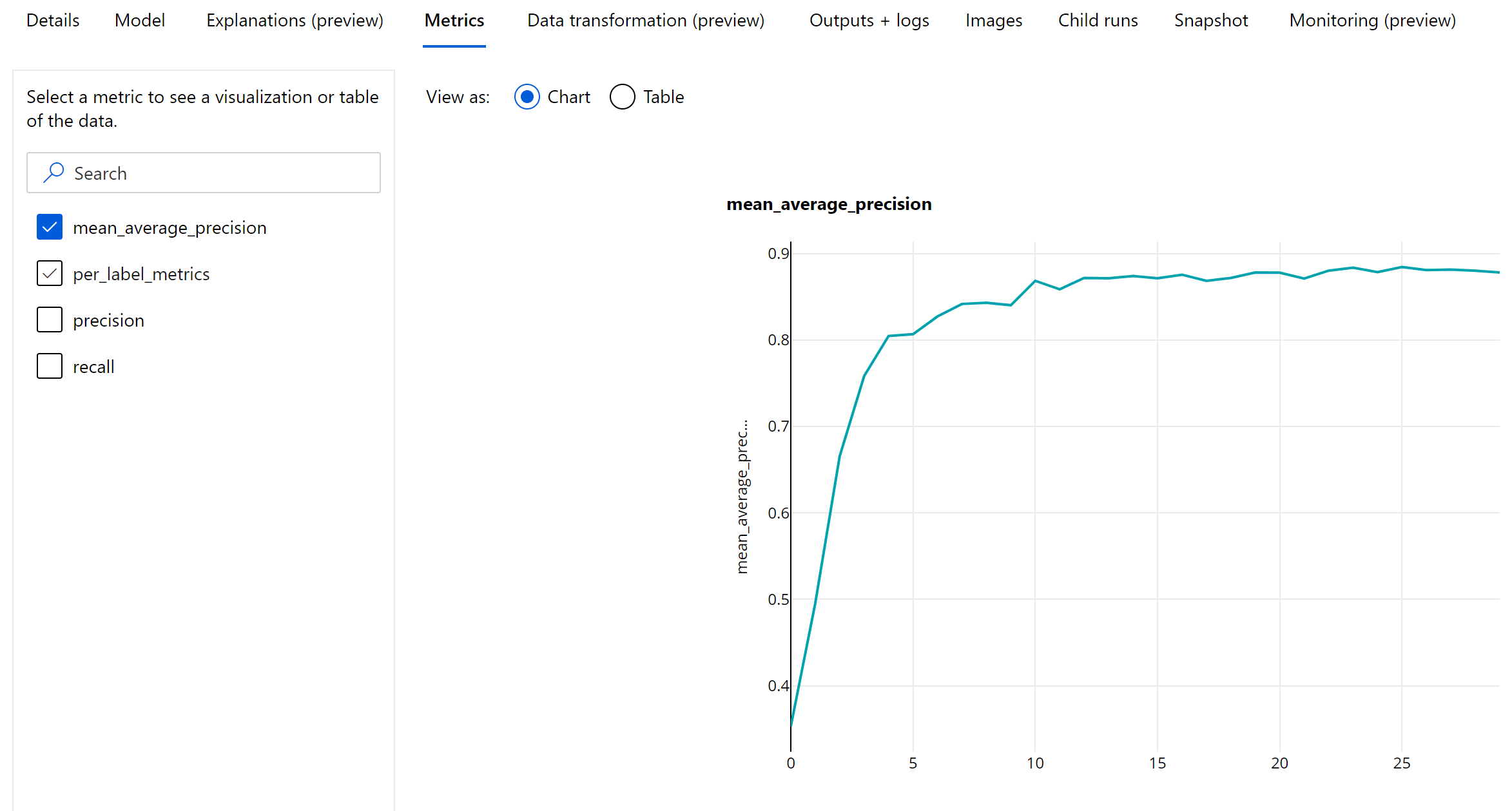
Mått på epoknivå för objektidentifiering och instanssegmentering
Värdena för mAP, precision och träffsäkerhet loggas på epoknivå för modeller för identifiering av bildobjekt/instanssegmentering. Måtten mAP, precision och träffsäkerhet loggas också på klassnivå med namnet "per_label_metrics". "per_label_metrics" ska visas som en tabell.
Kommentar
Mått på epoknivå för precision, återkallande och per_label_metrics är inte tillgängliga när du använder metoden coco.
Ansvarsfull AI-instrumentpanel för bästa rekommenderade AutoML-modell (förhandsversion)
Azure Machine Learning Responsible AI-instrumentpanelen innehåller ett enda gränssnitt som hjälper dig att implementera ansvarsfull AI i praktiken på ett effektivt och effektivt sätt. En ansvarsfull AI-instrumentpanel stöds endast med tabelldata och stöds endast för klassificerings- och regressionsmodeller. Den samlar flera mogna ansvarsfulla AI-verktyg inom följande områden:
- Utvärdering av modellprestanda och rättvisa
- Datautforskning
- Maskininlärningstolkning
- Felanalys
Även om mått och diagram för modellutvärdering är bra för att mäta modellens allmänna kvalitet, är åtgärder som att inspektera modellens rättvisa, visa dess förklaringar (även kallade vilka datamängdsfunktioner en modell som används för att göra sina förutsägelser), att inspektera dess fel och potentiella blinda fläckar är viktiga när du övar ansvarsfull AI. Därför tillhandahåller automatiserad ML en instrumentpanel för ansvarsfull AI som hjälper dig att observera olika insikter för din modell. Se hur du visar instrumentpanelen ansvarsfull AI i Azure Machine Learning-studio.
Se hur du kan generera den här instrumentpanelen via användargränssnittet eller SDK:t.
Modellförklaringar och funktionsvikter
Även om modellutvärderingsmått och diagram är bra för att mäta den allmänna kvaliteten på en modell, är det viktigt att kontrollera vilka datamängdsfunktioner en modell använder för att göra förutsägelser när du övar ansvarsfull AI. Därför tillhandahåller automatiserad ML en instrumentpanel för modellförklaringar för att mäta och rapportera relativa bidrag från datamängdsfunktioner. Se hur du visar instrumentpanelen för förklaringar i Azure Machine Learning-studio.
Kommentar
Tolkning, bästa modellförklaring, är inte tillgänglig för automatiserade ML-prognosexperiment som rekommenderar följande algoritmer som den bästa modellen eller ensemblen:
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Profet
- Genomsnitt
- Naiv
- Säsongsgenomsnitt
- Säsongsmässig naivitet
Nästa steg
- Prova förklaringsexemplet för den automatiserade maskininlärningsmodellen.
- För automatiserade ML-specifika frågor kan du kontakta askautomatedml@microsoft.com.