Hyperparameterjustering av en modell (v2)
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Automatisera effektiv hyperparameterjustering med Azure Machine Learning SDK v2 och CLI v2 med hjälp av typen SweepJob.
- Definiera parametersökutrymmet för utvärderingsversionen
- Ange samplingsalgoritmen för ditt svepjobb
- Ange målet att optimera
- Ange en princip för tidig uppsägning för jobb med låga prestanda
- Definiera gränser för svepjobbet
- Starta ett experiment med den definierade konfigurationen
- Visualisera träningsjobben
- Välj den bästa konfigurationen för din modell
Vad är hyperparameterjustering?
Hyperparametrar är justerbara parametrar som gör att du kan styra modellträningsprocessen. Med neurala nätverk bestämmer du till exempel antalet dolda lager och antalet noder i varje lager. Modellprestanda är starkt beroende av hyperparametrar.
Hyperparameterjustering, även kallat optimering av hyperparametrar, är processen att hitta konfigurationen av hyperparametrar som ger bästa prestanda. Processen är vanligtvis beräkningsmässigt dyr och manuell.
Med Azure Machine Learning kan du automatisera hyperparameterjustering och köra experiment parallellt för att effektivt optimera hyperparametrar.
Definiera sökutrymmet
Justera hyperparametrar genom att utforska intervallet med värden som definierats för varje hyperparameter.
Hyperparametrar kan vara diskreta eller kontinuerliga och har en fördelning av värden som beskrivs av ett parameteruttryck.
Diskreta hyperparametrar
Diskreta hyperparametrar anges som en Choice bland diskreta värden. Choice kan vara:
- ett eller flera kommaavgränsade värden
- ett
rangeobjekt - godtyckliga
listobjekt
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
I det här fallet batch_size tar ett av värdena [16, 32, 64, 128] och number_of_hidden_layers ett av värdena [1, 2, 3, 4].
Följande avancerade diskreta hyperparametrar kan också anges med hjälp av en distribution:
QUniform(min_value, max_value, q)- Returnerar ett värde som round(Uniform(min_value, max_value) / q) * qQLogUniform(min_value, max_value, q)- Returnerar ett värde som round(exp(Uniform(min_value, max_value)) / q) * qQNormal(mu, sigma, q)- Returnerar ett värde som round(Normal(mu, sigma) / q) * qQLogNormal(mu, sigma, q)- Returnerar ett värde som round(exp(Normal(mu, sigma)) / q) * q
Kontinuerliga hyperparametrar
Kontinuerliga hyperparametrar anges som en fördelning över ett kontinuerligt värdeintervall:
Uniform(min_value, max_value)– Returnerar ett värde som är jämnt fördelat mellan min_value och max_valueLogUniform(min_value, max_value)- Returnerar ett värde som dras enligt exp(Uniform(min_value, max_value)) så att logaritmen för returvärdet fördelas jämntNormal(mu, sigma)– Returnerar ett reellt värde som normalt distribueras med medelvärdet mu och standardavvikelse sigmaLogNormal(mu, sigma)- Returnerar ett värde som dras enligt exp(Normal(mu, sigma)) så att logaritmen för returvärdet normalt distribueras
Ett exempel på en parameterutrymmesdefinition:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Den här koden definierar ett sökutrymme med två parametrar – learning_rate och keep_probability. learning_rate har en normal fördelning med medelvärdet 10 och en standardavvikelse på 3. keep_probability har en enhetlig fördelning med ett minimivärde på 0,05 och ett maximalt värde på 0,1.
För CLI kan du använda YAML-schemat för svepjobbet för att definiera sökutrymmet i YAML:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Sampling av hyperparameterutrymmet
Ange den parametersamplingsmetod som ska användas över hyperparameterutrymmet. Azure Machine Learning stöder följande metoder:
- Stickprov
- Rutnätssampling
- Bayesiansk sampling
Stickprov
Slumpmässig sampling stöder diskreta och kontinuerliga hyperparametrar. Den stöder tidig avslutning av jobb med låga prestanda. Vissa användare gör en första sökning med slumpmässig sampling och förfinar sedan sökutrymmet för att förbättra resultaten.
Vid slumpmässig sampling väljs hyperparametervärden slumpmässigt från det definierade sökutrymmet. När du har skapat kommandojobbet kan du använda svepparametern för att definiera samplingsalgoritmen.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol är en typ av slumpmässig sampling som stöds av svepjobbtyper. Du kan använda sobol för att återskapa dina resultat med hjälp av frö och täcka distributionen av sökutrymmet jämnare.
Om du vill använda sobol använder du klassen RandomParameterSampling för att lägga till fröet och regeln enligt exemplet nedan.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Rutnätssampling
Rutnätssampling stöder diskreta hyperparametrar. Använd rutnätssampling om du kan budgeta för att fullständigt söka över sökutrymmet. Stöder tidig avslutning av jobb med låga prestanda.
Rutnätssampling gör en enkel rutnätssökning över alla möjliga värden. Rutnätssampling kan endast användas med choice hyperparametrar. Följande blanksteg innehåller till exempel sex exempel:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Bayesiansk sampling
Bayesiansk sampling baseras på Bayesiansk optimeringsalgoritm. Den väljer exempel baserat på hur tidigare exempel gjorde, så att nya exempel förbättrar det primära måttet.
Bayesiansk sampling rekommenderas om du har tillräckligt med budget för att utforska hyperparameterutrymmet. För bästa resultat rekommenderar vi ett maximalt antal jobb som är större än eller lika med 20 gånger det antal hyperparametrar som justeras.
Antalet samtidiga jobb påverkar justeringsprocessens effektivitet. Ett mindre antal samtidiga jobb kan leda till bättre samplingskonvergens, eftersom den mindre graden av parallellitet ökar antalet jobb som drar nytta av tidigare slutförda jobb.
Bayesiansk sampling stöder choiceendast , uniformoch quniform distributioner över sökutrymmet.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Ange målet för svepet
Definiera målet för ditt svepjobb genom att ange det primära måttet och målet som du vill att hyperparameterjusteringen ska optimera. Varje träningsjobb utvärderas för det primära måttet. Principen för tidig avslutning använder det primära måttet för att identifiera jobb med låga prestanda.
primary_metric: Namnet på det primära måttet måste exakt matcha namnet på måttet som loggas av träningsskriptetgoal: Det kan vara antingenMaximizeellerMinimizeoch avgör om det primära måttet ska maximeras eller minimeras när jobben utvärderas.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Det här exemplet maximerar "noggrannheten".
Loggmått för justering av hyperparametrar
Träningsskriptet för din modell måste logga det primära måttet under modellträningen med samma motsvarande måttnamn så att SweepJob kan komma åt det för justering av hyperparametrar.
Logga det primära måttet i träningsskriptet med följande exempelfragment:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Träningsskriptet beräknar val_accuracy och loggar det som det primära måttet "noggrannhet". Varje gång måttet loggas tas det emot av hyperparameterns justeringstjänst. Det är upp till dig att fastställa rapporteringsfrekvensen.
Mer information om loggningsvärden för träningsjobb finns i Aktivera loggning i Azure Machine Learning-träningsjobb.
Ange princip för tidig uppsägning
Avsluta automatiskt dåligt presterande jobb med en princip för tidig uppsägning. Tidig avslutning förbättrar beräkningseffektiviteten.
Du kan konfigurera följande parametrar som styr när en princip tillämpas:
evaluation_interval: hur ofta principen tillämpas. Varje gång träningsskriptet loggar räknas det primära måttet som ett intervall. Enevaluation_intervalav 1 tillämpar principen varje gång träningsskriptet rapporterar det primära måttet. Enevaluation_intervalav två tillämpar principen varannan gång. Om det inte angesevaluation_intervalanges värdet 0 som standard.delay_evaluation: fördröjer den första principutvärderingen för ett angivet antal intervall. Det här är en valfri parameter som undviker för tidig avslutning av träningsjobb genom att tillåta att alla konfigurationer körs under ett minsta antal intervall. Om det anges tillämpar principen varje multipel av evaluation_interval som är större än eller lika med delay_evaluation. Om det inte angesdelay_evaluationanges värdet 0 som standard.
Azure Machine Learning stöder följande principer för tidig avslutning:
Bandit-princip
Bandit-principen baseras på slackfaktor/slack-belopp och utvärderingsintervall. Bandit-principen avslutar ett jobb när det primära måttet inte är inom den angivna slackfaktorn/slack-mängden för det mest lyckade jobbet.
Ange följande konfigurationsparametrar:
slack_factorellerslack_amount: det slack som tillåts med avseende på det bäst presterande träningsjobbet.slack_factoranger det tillåtna slacket som ett förhållande.slack_amountanger det tillåtna slacket som en absolut mängd i stället för ett förhållande.Anta till exempel att en Bandit-princip tillämpas med intervall 10. Anta att det bäst presterande jobbet med intervall 10 rapporterade ett primärt mått är 0,8 med målet att maximera det primära måttet. Om principen anger
slack_factor0,2 avslutas alla träningsjobb vars bästa mått med intervall 10 är mindre än 0,66 (0,8/(1+slack_factor).).evaluation_interval: (valfritt) frekvensen för att tillämpa principendelay_evaluation: (valfritt) fördröjer den första principutvärderingen för ett angivet antal intervall
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
I det här exemplet tillämpas principen för tidig avslutning vid varje intervall när mått rapporteras, med början vid utvärderingsintervall 5. Alla jobb vars bästa mått är mindre än (1/(1+0,1) eller 91 % av de jobb som fungerar bäst avslutas.
Princip för medianstopp
Medianstopp är en princip för tidig avslutning som baseras på löpande medelvärden av primära mått som rapporterats av jobben. Den här principen beräknar löpande medelvärden för alla träningsjobb och stoppar jobb vars primära måttvärde är sämre än medianvärdet för medelvärdena.
Den här principen använder följande konfigurationsparametrar:
evaluation_interval: frekvensen för att tillämpa principen (valfri parameter).delay_evaluation: fördröjer den första principutvärderingen för ett angivet antal intervall (valfri parameter).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
I det här exemplet tillämpas principen för tidig avslutning vid varje intervall som börjar vid utvärderingsintervall 5. Ett jobb stoppas med intervall 5 om det bästa primära måttet är sämre än medianvärdet för de löpande medelvärdena över intervallen 1:5 för alla träningsjobb.
Princip för markering av trunkering
Valet av trunkering avbryter en procentandel av jobb med lägst prestanda vid varje utvärderingsintervall. Jobb jämförs med det primära måttet.
Den här principen använder följande konfigurationsparametrar:
truncation_percentage: procentandelen jobb med lägst prestanda som ska avslutas vid varje utvärderingsintervall. Ett heltalsvärde mellan 1 och 99.evaluation_interval: (valfritt) frekvensen för att tillämpa principendelay_evaluation: (valfritt) fördröjer den första principutvärderingen för ett angivet antal intervallexclude_finished_jobs: anger om slutförda jobb ska undantas när principen tillämpas
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
I det här exemplet tillämpas principen för tidig avslutning vid varje intervall som börjar vid utvärderingsintervall 5. Ett jobb avslutas med intervall 5 om dess prestanda vid intervall 5 har lägst 20 % av prestandan för alla jobb i intervall 5 och exkluderar slutförda jobb när principen tillämpas.
Ingen avslutningsprincip (standard)
Om ingen princip har angetts låter tjänsten för hyperparameterjustering alla träningsjobb köras till slutförande.
sweep_job.early_termination = None
Välja en princip för tidig avslutning
- För en konservativ politik som ger besparingar utan att avsluta lovande jobb, överväg en medianstopppolicy med
evaluation_interval1 ochdelay_evaluation5. Det här är konservativa inställningar som kan ge ungefär 25–35 % besparingar utan förlust på primärmått (baserat på våra utvärderingsdata). - Om du vill ha mer aggressiva besparingar använder du Bandit Policy med en mindre tillåten slack- eller truncation-markeringsprincip med en större trunkeringsprocent.
Ange gränser för ditt svepjobb
Kontrollera resursbudgeten genom att ange gränser för ditt svepjobb.
max_total_trials: Maximalt antal utvärderingsjobb. Måste vara ett heltal mellan 1 och 1000.max_concurrent_trials: (valfritt) Maximalt antal utvärderingsjobb som kan köras samtidigt. Om det inte anges max_total_trials antalet jobb startas parallellt. Om det anges måste det vara ett heltal mellan 1 och 1 000.timeout: Maximal tid i sekunder som hela svepjobbet tillåts köras. När den här gränsen har nåtts avbryter systemet svepjobbet, inklusive alla utvärderingsversioner.trial_timeout: Maximal tid i sekunder som varje utvärderingsjobb tillåts köras. När den här gränsen har nåtts avbryter systemet utvärderingsversionen.
Kommentar
Om både max_total_trials och timeout anges avslutas hyperparameterjusteringsexperimentet när det första av dessa två tröskelvärden nås.
Kommentar
Antalet samtidiga utvärderingsjobb är gated för de resurser som är tillgängliga i det angivna beräkningsmålet. Kontrollera att beräkningsmålet har tillgängliga resurser för önskad samtidighet.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Den här koden konfigurerar hyperparameterjusteringsexperimentet till att använda maximalt 20 totala utvärderingsjobb och kör fyra utvärderingsjobb åt gången med en tidsgräns på 1 200 sekunder för hela svepjobbet.
Konfigurera hyperparameterjusteringsexperiment
Ange följande för att konfigurera hyperparameterjusteringsexperimentet:
- Det definierade sökutrymmet för hyperparametrar
- Din samplingsalgoritm
- Din princip för tidig uppsägning
- Ditt mål
- Resursgränser
- CommandJob eller CommandComponent
- SweepJob
SweepJob kan köra ett hyperparameter-svep på kommando- eller kommandokomponenten.
Kommentar
Beräkningsmålet som används i sweep_job måste ha tillräckligt med resurser för att uppfylla samtidighetsnivån. Mer information om beräkningsmål finns i Beräkningsmål.
Konfigurera ditt hyperparameterjusteringsexperiment:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
command_job Anropas som en funktion så att vi kan använda parameteruttrycken på svepindata. Funktionen sweep konfigureras sedan med trial, sampling-algorithm, objective, limitsoch compute. Kodfragmentet ovan hämtas från exempelanteckningsboken Kör hyperparametersvepning på ett kommando eller kommandokomponent. I det här exemplet justeras parametrarna learning_rate och boosting . Tidiga jobbstopp bestäms av en MedianStoppingPolicy, som stoppar ett jobb vars primära måttvärde är sämre än medianvärdet för medelvärdena för alla träningsjobb.( se MedianStoppingPolicy-klassreferens).
Information om hur parametervärdena tas emot, parsas och skickas till träningsskriptet som ska justeras finns i det här kodexemplet
Viktigt!
Varje hyperparameters svepjobb startar om träningen från grunden, inklusive återskapande av modellen och alla datainläsare. Du kan minimera den här kostnaden genom att använda en Azure Machine Learning-pipeline eller manuell process för att göra så mycket dataförberedelser som möjligt före dina träningsjobb.
Skicka hyperparameterjusteringsexperiment
När du har definierat justeringskonfigurationen för hyperparameter skickar du jobbet:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Visualisera justeringsjobb för hyperparametrar
Du kan visualisera alla dina hyperparameterjusteringsjobb i Azure Machine Learning-studio. Mer information om hur du visar ett experiment i portalen finns i Visa jobbposter i studion.
Måttdiagram: Den här visualiseringen spårar de mått som loggas för varje underordnat hyperdrive-jobb under hyperparameterjusteringens varaktighet. Varje rad representerar ett underordnat jobb och varje punkt mäter det primära måttvärdet vid den iterationen av körningen.
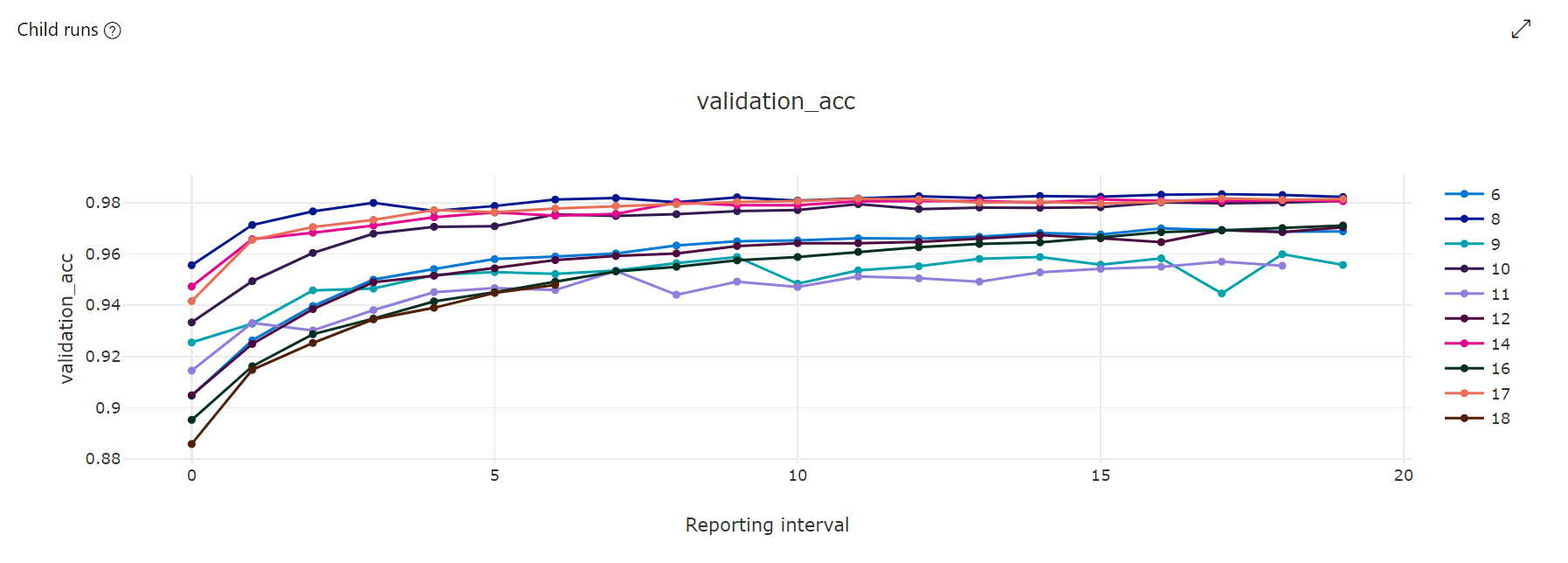
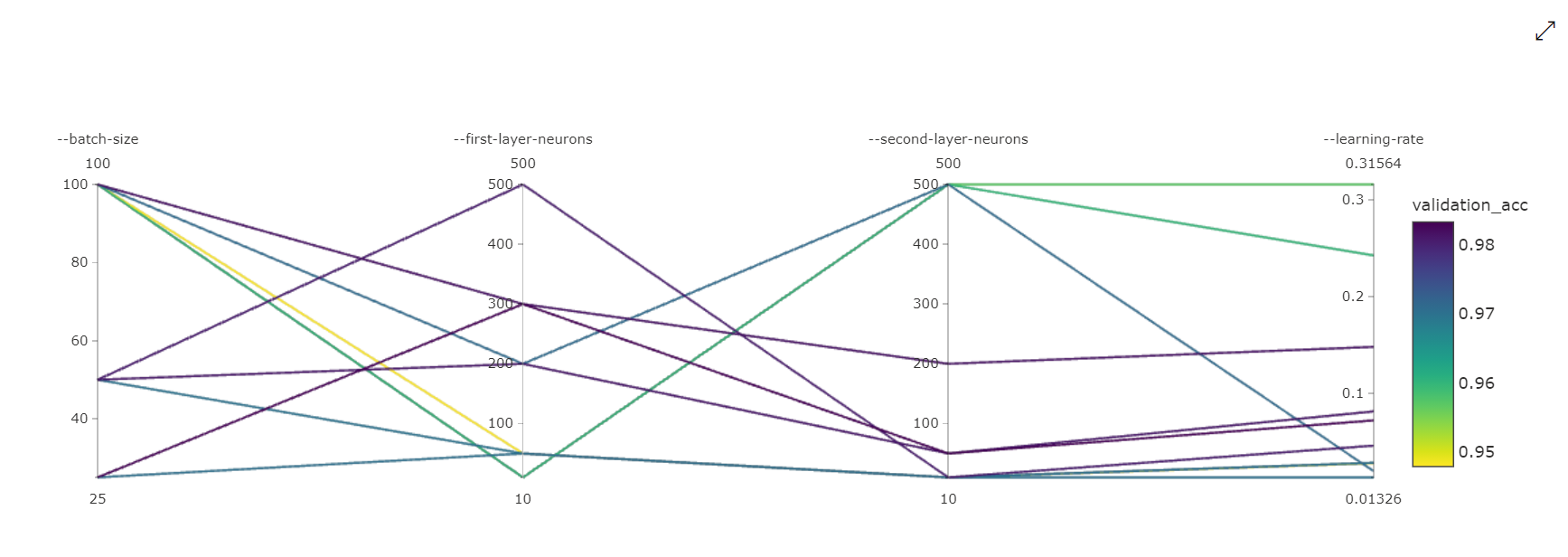
Diagram över parallella koordinater: Den här visualiseringen visar korrelationen mellan primära måttprestanda och enskilda hyperparametervärden. Diagrammet är interaktivt via förflyttning av axlar (markera och dra efter axeletiketten) och genom att markera värden över en enskild axel (markera och dra lodrätt längs en enskild axel för att markera ett intervall med önskade värden). Diagrammet parallella koordinater innehåller en axel i den högra delen av diagrammet som ritar det bästa måttvärdet som motsvarar de hyperparametrar som angetts för den jobbinstansen. Den här axeln tillhandahålls för att projicera diagramtoningsförklaringen på data på ett mer läsbart sätt.
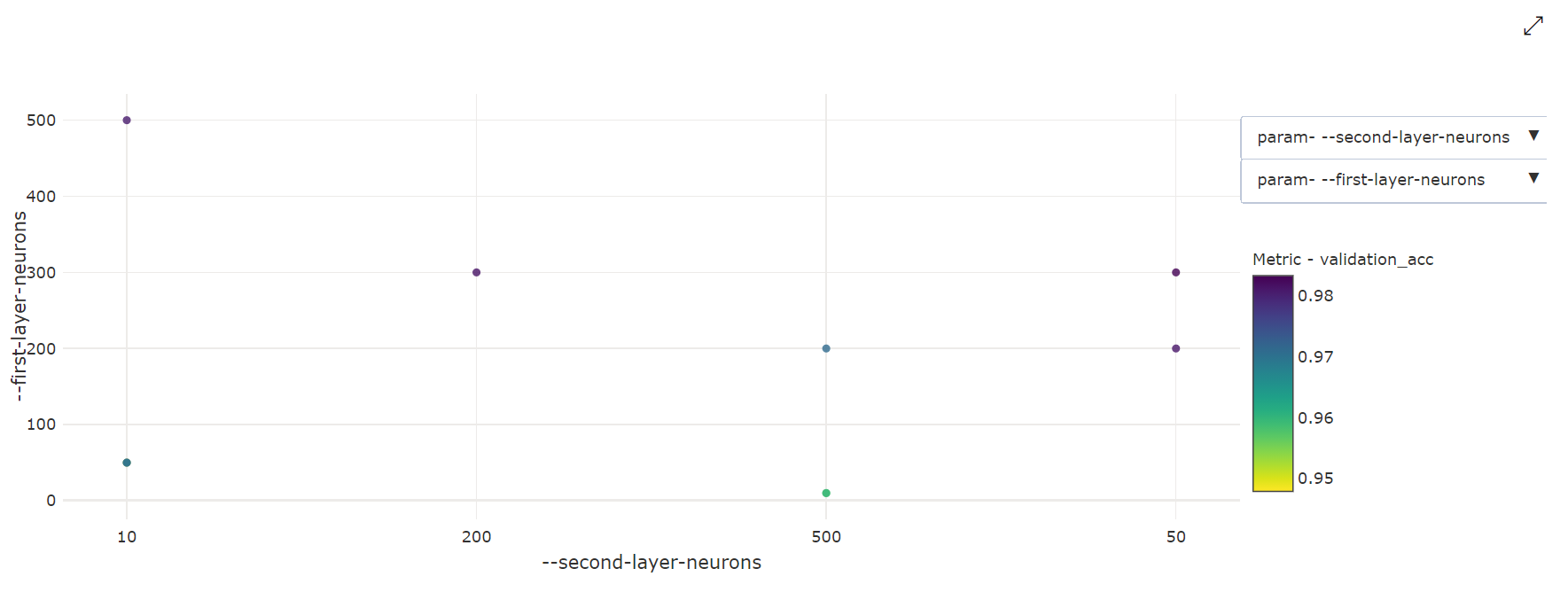
Tvådimensionellt punktdiagram: Den här visualiseringen visar korrelationen mellan två enskilda hyperparametrar tillsammans med deras associerade primära måttvärde.
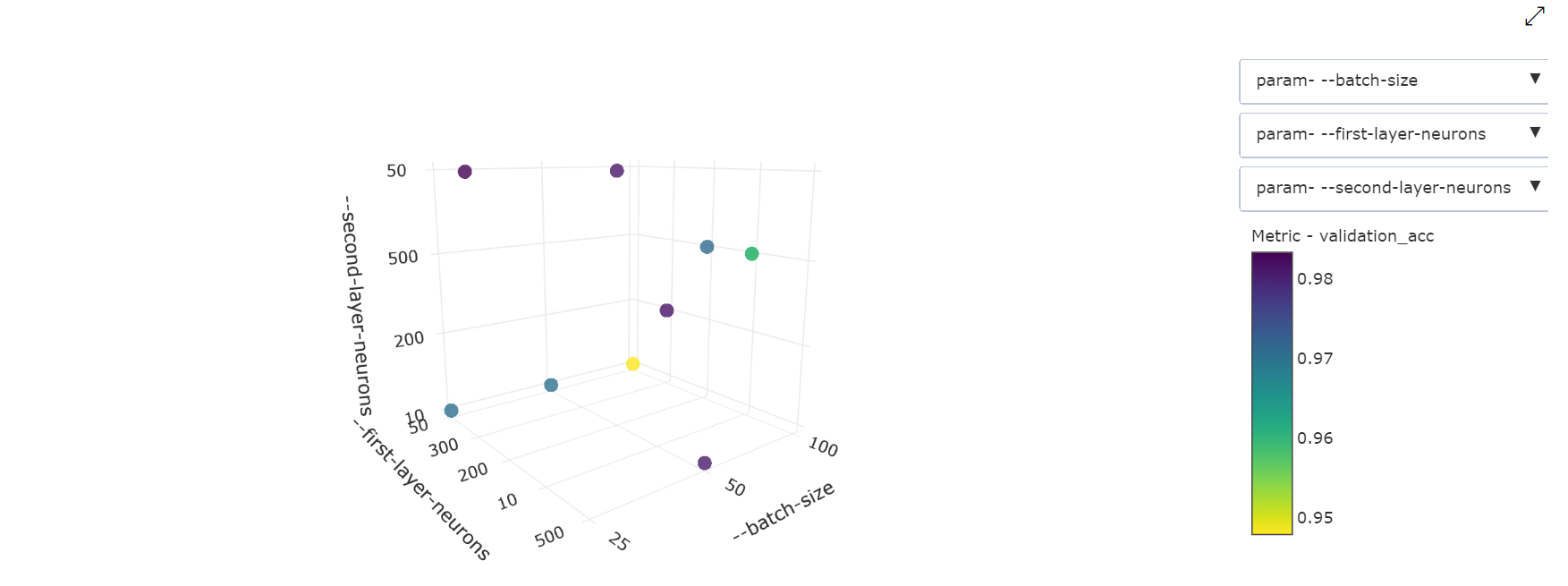
3-dimensionellt punktdiagram: Den här visualiseringen är densamma som 2D men tillåter tre hyperparameterdimensioner av korrelation med det primära måttvärdet. Du kan också välja och dra för att ändra orientering för diagrammet för att visa olika korrelationer i 3D-utrymme.
Hitta det bästa utvärderingsjobbet
När alla hyperparameterjusteringsjobb har slutförts hämtar du dina bästa utvärderingsutdata:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
Du kan använda CLI för att ladda ned alla standardutdata och namngivna utdata från det bästa utvärderingsjobbet och loggarna för svepjobbet.
az ml job download --name <sweep-job> --all
Om du vill kan du endast ladda ned de bästa utvärderingsutdata
az ml job download --name <sweep-job> --output-name model