Konfigurera dataflöden i Azure IoT Operations
Viktigt!
Den här sidan innehåller instruktioner för att hantera Azure IoT Operations-komponenter med hjälp av Kubernetes-distributionsmanifest, som finns i förhandsversion. Den här funktionen har flera begränsningar och bör inte användas för produktionsarbetsbelastningar.
Juridiska villkor för Azure-funktioner i betaversion, förhandsversion eller som av någon annan anledning inte har gjorts allmänt tillgängliga ännu finns i kompletterande användningsvillkor för Microsoft Azure-förhandsversioner.
Ett dataflöde är den sökväg som data tar från källan till målet med valfria transformeringar. Du kan konfigurera dataflödet genom att skapa en anpassad dataflödesresurs eller med hjälp av Azure IoT Operations Studio-portalen. Ett dataflöde består av tre delar: källan, omvandlingen och målet.

För att definiera källan och målet måste du konfigurera dataflödesslutpunkterna. Omvandlingen är valfri och kan omfatta åtgärder som att berika data, filtrera data och mappa data till ett annat fält.
Viktigt!
Varje dataflöde måste ha standardslutpunkten för Azure IoT Operations lokal MQTT-koordinator som antingen källa eller mål.
Du kan använda driftupplevelsen i Azure IoT Operations för att skapa ett dataflöde. Driftupplevelsen tillhandahåller ett visuellt gränssnitt för att konfigurera dataflödet. Du kan också använda Bicep för att skapa ett dataflöde med en Bicep-mallfil eller använda Kubernetes för att skapa ett dataflöde med hjälp av en YAML-fil.
Fortsätt läsa för att lära dig hur du konfigurerar källan, omvandlingen och målet.
Förutsättningar
Du kan distribuera dataflöden så snart du har en instans av Azure IoT Operations med hjälp av standardprofilen och slutpunkten för dataflöde. Du kanske dock vill konfigurera dataflödesprofiler och slutpunkter för att anpassa dataflödet.
Dataflödesprofil
Om du inte behöver olika skalningsinställningar för dina dataflöden använder du standardprofilen för dataflöde som tillhandahålls av Azure IoT Operations. Information om hur du konfigurerar en dataflödesprofil finns i Konfigurera dataflödesprofiler.
Dataflödesslutpunkter
Dataflödesslutpunkter krävs för att konfigurera källan och målet för dataflödet. För att komma igång snabbt kan du använda standardslutpunkten för dataflöde för den lokala MQTT-koordinatorn. Du kan också skapa andra typer av dataflödesslutpunkter som Kafka, Event Hubs eller Azure Data Lake Storage. Information om hur du konfigurerar varje typ av dataflödesslutpunkt finns i Konfigurera dataflödesslutpunkter.
Kom igång
När du har förutsättningar kan du börja skapa ett dataflöde.
Om du vill skapa ett dataflöde i driftmiljön väljer du Dataflöde>Skapa dataflöde. Sedan ser du sidan där du kan konfigurera källan, omvandlingen och målet för dataflödet.
Läs följande avsnitt om du vill lära dig hur du konfigurerar åtgärdstyperna för dataflödet.
Källa
Om du vill konfigurera en källa för dataflödet anger du slutpunktsreferensen och en lista över datakällor för slutpunkten. Välj något av följande alternativ som källa för dataflödet.
Om standardslutpunkten inte används som källa måste den användas som mål. Mer information finns i Dataflöden måste använda den lokala MQTT-koordinatorslutpunkten.
Alternativ 1: Använd standardslutpunkten för meddelandeköer som källa
Under Källinformation väljer du Meddelandekö.
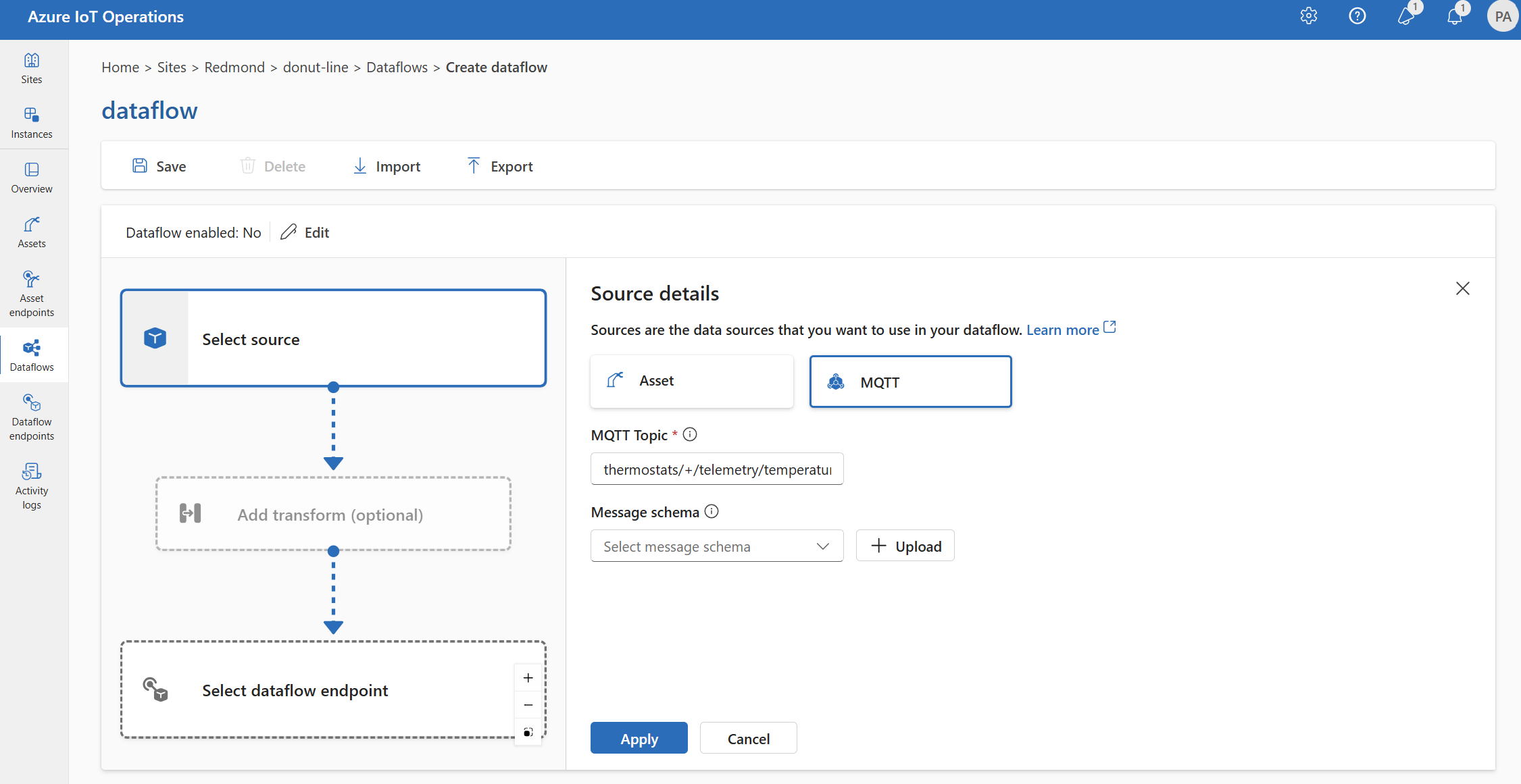
Ange följande inställningar för meddelandekökällan:
Inställning beskrivning Dataflödesslutpunkt Välj standard för att använda standardslutpunkten för MQTT-meddelandekö. Område Ämnesfiltret som du vill prenumerera på för inkommande meddelanden. Se Avsnittet Konfigurera MQTT eller Kafka. Meddelandeschema Schemat som ska användas för att deserialisera inkommande meddelanden. Se Ange schema för att deserialisera data. Välj Använd.
Alternativ 2: Använd tillgången som källa
Du kan använda en tillgång som källa för dataflödet. Användning av en tillgång som källa är endast tillgängligt i driftupplevelsen.
Under Källinformation väljer du Tillgång.
Välj den tillgång som du vill använda som källslutpunkt.
Välj Fortsätt.
En lista över datapunkter för den valda tillgången visas.
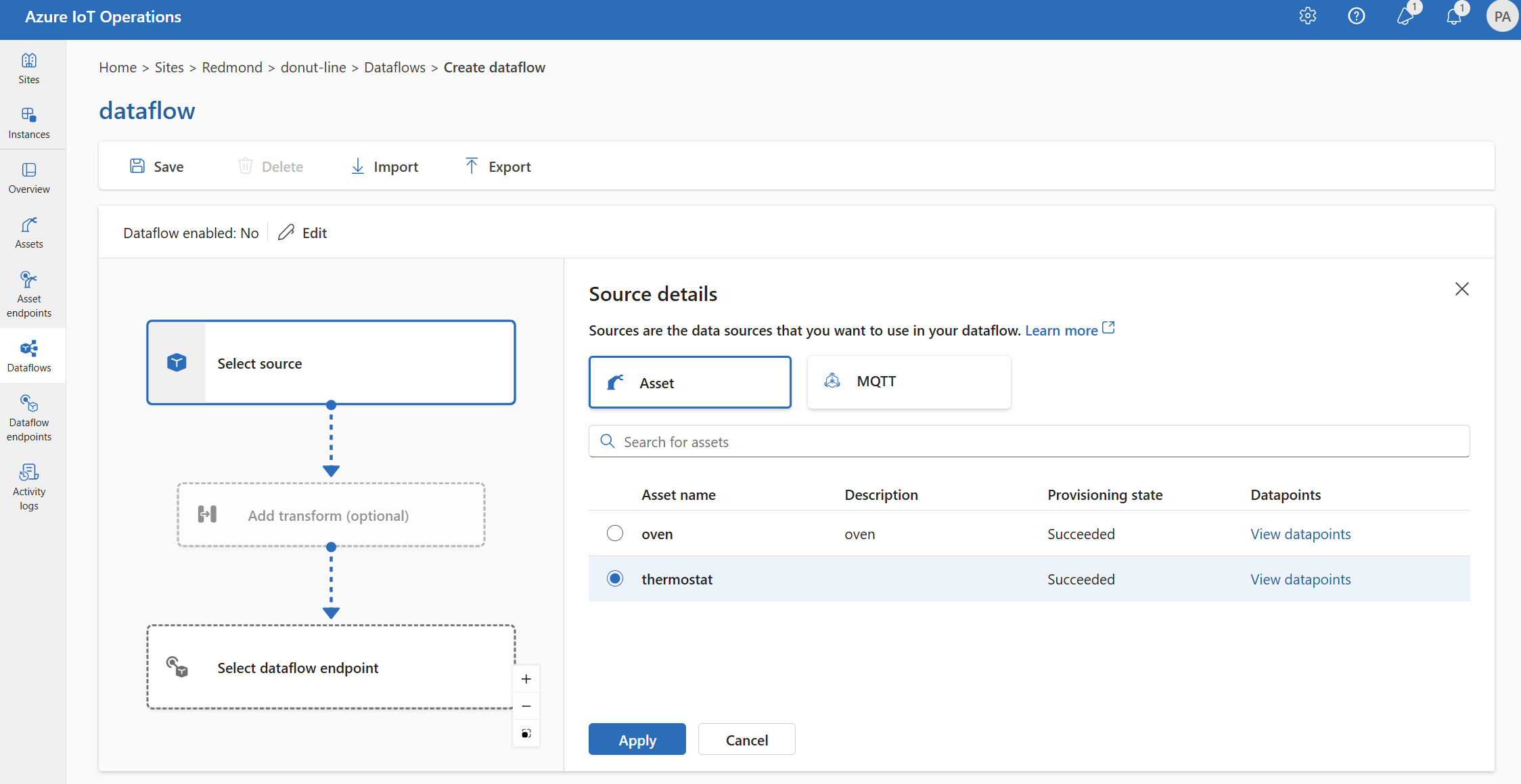
Välj Använd för att använda tillgången som källslutpunkt.
När du använder en tillgång som källa används tillgångsdefinitionen för att härleda schemat för dataflödet. Tillgångsdefinitionen innehåller schemat för tillgångens datapunkter. Mer information finns i Hantera tillgångskonfigurationer via fjärranslutning.
När den har konfigurerats når data från tillgången dataflödet via den lokala MQTT-koordinatorn. När du använder en tillgång som källa använder dataflödet därför den lokala standardslutpunkten för MQTT-koordinatorn som källa i verkligheten.
Alternativ 3: Använd anpassad MQTT- eller Kafka-dataflödesslutpunkt som källa
Om du har skapat en anpassad MQTT- eller Kafka-dataflödesslutpunkt (till exempel för användning med Event Grid eller Event Hubs) kan du använda den som källa för dataflödet. Kom ihåg att slutpunkter av lagringstyp, till exempel Data Lake eller Fabric OneLake, inte kan användas som källa.
Under Källinformation väljer du Meddelandekö.
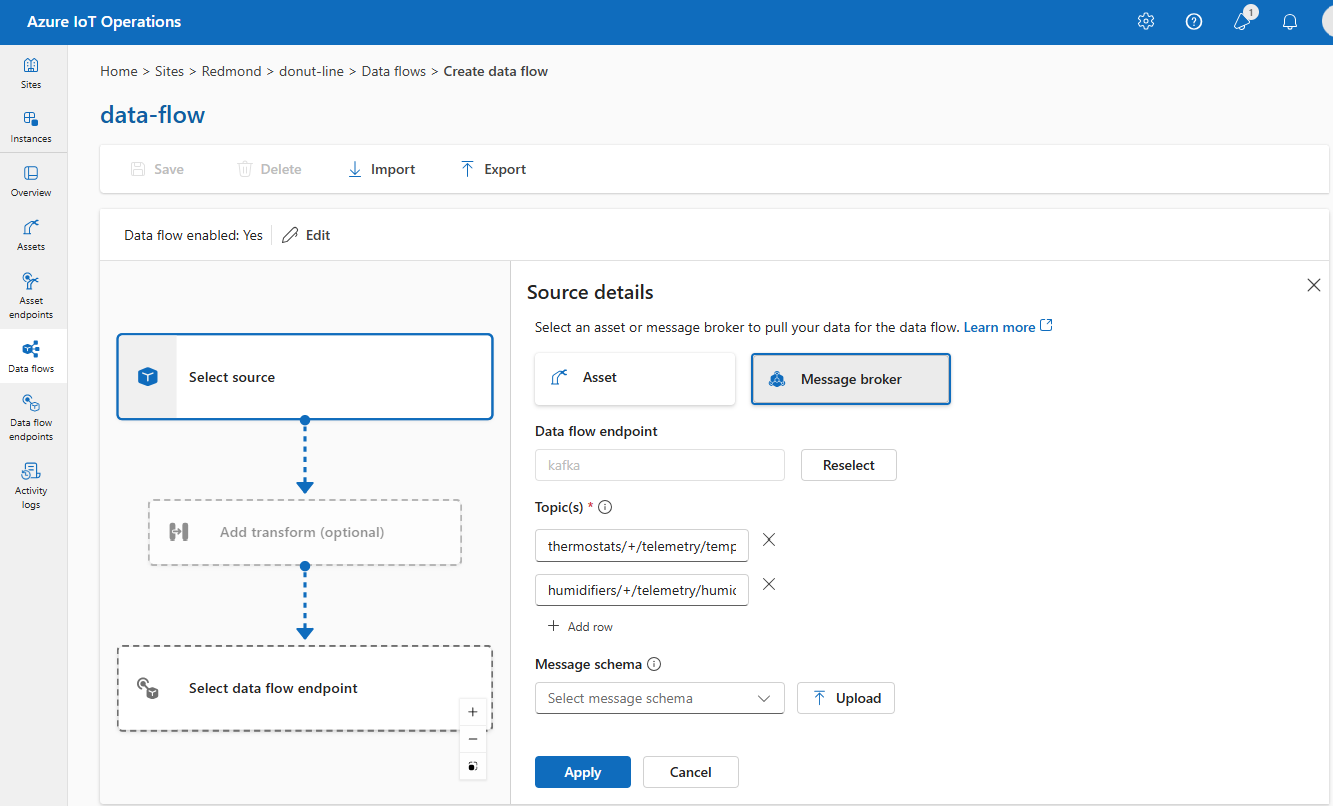
Ange följande inställningar för meddelandekökällan:
Inställning beskrivning Dataflödesslutpunkt Använd knappen Välj om för att välja en anpassad MQTT- eller Kafka-dataflödesslutpunkt. Mer information finns i Konfigurera MQTT-slutpunkter för dataflöde eller Konfigurera Azure Event Hubs- och Kafka-dataflödesslutpunkter. Område Ämnesfiltret som du vill prenumerera på för inkommande meddelanden. Se Avsnittet Konfigurera MQTT eller Kafka. Meddelandeschema Schemat som ska användas för att deserialisera inkommande meddelanden. Se Ange schema för att deserialisera data. Välj Använd.
Konfigurera datakällor (MQTT- eller Kafka-ämnen)
Du kan ange flera MQTT- eller Kafka-ämnen i en källa utan att behöva ändra dataflödesslutpunktskonfigurationen. Den här flexibiliteten innebär att samma slutpunkt kan återanvändas i flera dataflöden, även om ämnena varierar. Mer information finns i Återanvända dataflödesslutpunkter.
MQTT-ämnen
När källan är en MQTT-slutpunkt (Event Grid ingår) kan du använda MQTT-ämnesfiltret för att prenumerera på inkommande meddelanden. Ämnesfiltret kan innehålla jokertecken för att prenumerera på flera ämnen. Till exempel thermostats/+/telemetry/temperature/# prenumererar på alla temperaturtelemetrimeddelanden från termostater. Så här konfigurerar du MQTT-ämnesfilter:
I informationen om dataflödets driftupplevelse väljer du Meddelandekö och använder sedan fältet Ämne för att ange MQTT-ämnesfiltret att prenumerera på för inkommande meddelanden.
Kommentar
Endast ett ämnesfilter kan anges i driftmiljön. Om du vill använda flera ämnesfilter använder du Bicep eller Kubernetes.
Delade prenumerationer
Om du vill använda delade prenumerationer med meddelandekökällor kan du ange det delade prenumerationsavsnittet i form av $shared/<GROUP_NAME>/<TOPIC_FILTER>.
I operations experience dataflow Source details (Dataflödeskälla ) väljer du Meddelandekö och använder fältet Ämne för att ange den delade prenumerationsgruppen och ämnet.
Om instansantalet i dataflödesprofilen är större än en aktiveras den delade prenumerationen automatiskt för alla dataflöden som använder en meddelandekökälla. I det här fallet läggs prefixet $shared till och namnet på den delade prenumerationsgruppen genereras automatiskt. Om du till exempel har en dataflödesprofil med instansantalet 3 och ditt dataflöde använder en slutpunkt för meddelandekö som källa konfigurerad med ämnen topic1 och topic2konverteras de automatiskt till delade prenumerationer som $shared/<GENERATED_GROUP_NAME>/topic1 och $shared/<GENERATED_GROUP_NAME>/topic2.
Du kan uttryckligen skapa ett ämne med namnet $shared/mygroup/topic i konfigurationen. Det rekommenderas dock inte att lägga till ämnet $shared explicit eftersom prefixet $shared läggs till automatiskt när det behövs. Dataflöden kan göra optimeringar med gruppnamnet om det inte har angetts. Till exempel $share är inte inställt och dataflöden behöver bara köras över ämnesnamnet.
Viktigt!
Dataflöden som kräver delad prenumeration när antalet instanser är större än ett är viktigt när du använder Event Grid MQTT-koordinator som källa eftersom det inte stöder delade prenumerationer. Om du vill undvika meddelanden som saknas anger du antalet instanser av dataflödesprofilen till en när du använder Event Grid MQTT-asynkron meddelandekö som källa. Det är då dataflödet är prenumeranten och tar emot meddelanden från molnet.
Kafka-ämnen
När källan är en Kafka-slutpunkt (inklusive Event Hubs) anger du de enskilda Kafka-ämnena som ska prenumerera på inkommande meddelanden. Jokertecken stöds inte, så du måste ange varje ämne statiskt.
Kommentar
När du använder Event Hubs via Kafka-slutpunkten är varje enskild händelsehubb i namnområdet Kafka-ämnet. Om du till exempel har ett Event Hubs-namnområde med två händelsehubbar thermostats och humidifierskan du ange varje händelsehubb som ett Kafka-ämne.
Så här konfigurerar du Kafka-ämnena:
I informationen om dataflödets driftupplevelse väljer du Meddelandekö och använder sedan fältet Ämne för att ange kafka-ämnesfiltret som du vill prenumerera på för inkommande meddelanden.
Kommentar
Endast ett ämnesfilter kan anges i driftmiljön. Om du vill använda flera ämnesfilter använder du Bicep eller Kubernetes.
Ange källschema
När du använder MQTT eller Kafka som källa kan du ange ett schema för att visa listan över datapunkter i operations experience-portalen. Det finns för närvarande inte stöd för att använda ett schema för att deserialisera och verifiera inkommande meddelanden.
Om källan är en tillgång härleds schemat automatiskt från tillgångsdefinitionen.
Dricks
Om du vill generera schemat från en exempeldatafil använder du schemagenhjälpen.
Så här konfigurerar du schemat som används för att deserialisera inkommande meddelanden från en källa:
I information om dataflödets dataflöde väljer du Meddelandekö och använder fältet Meddelandeschema för att ange schemat. Du kan använda knappen Ladda upp för att ladda upp en schemafil först. Mer information finns i Förstå meddelandescheman.
Mer information finns i Förstå meddelandescheman.
Transformering
Transformeringsåtgärden är den plats där du kan transformera data från källan innan du skickar dem till målet. Transformeringar är valfria. Om du inte behöver göra ändringar i data ska du inte inkludera transformeringsåtgärden i dataflödeskonfigurationen. Flera transformeringar länkas samman i steg oavsett i vilken ordning de anges i konfigurationen. Stegens ordning är alltid:
- Berika: Lägg till ytterligare data till källdata med en datauppsättning och ett villkor som ska matchas.
- Filter: Filtrera data baserat på ett villkor.
- Mappa, beräkna, byt namn på eller lägg till en ny egenskap: Flytta data från ett fält till ett annat med en valfri konvertering.
Det här avsnittet är en introduktion till dataflödestransformering. Mer detaljerad information finns i Mappa data med hjälp av dataflöden, Konvertera data med hjälp av dataflödeskonverteringar och Berika data med hjälp av dataflöden.
I driftupplevelsen väljer du Dataflöde>Lägg till transformering (valfritt).
Berika: Lägga till referensdata
Om du vill utöka data lägger du först till referensdatauppsättningen i Azure IoT Operations State Store. Datauppsättningen används för att lägga till extra data i källdata baserat på ett villkor. Villkoret anges som ett fält i källdata som matchar ett fält i datamängden.
Du kan läsa in exempeldata i tillståndslagret med hjälp av state store CLI. Nyckelnamn i tillståndslagret motsvarar en datauppsättning i dataflödeskonfigurationen.
För närvarande stöds inte Enrich-fasen i driftupplevelsen.
Om datamängden har en post med fältet asset , ungefär som:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
Data från källan med deviceId fältmatchning thermostat1 har fälten location och manufacturer tillgängliga i filter- och kartfaser.
Mer information om villkorssyntax finns i Berika data med hjälp av dataflöden och Konvertera data med hjälp av dataflöden.
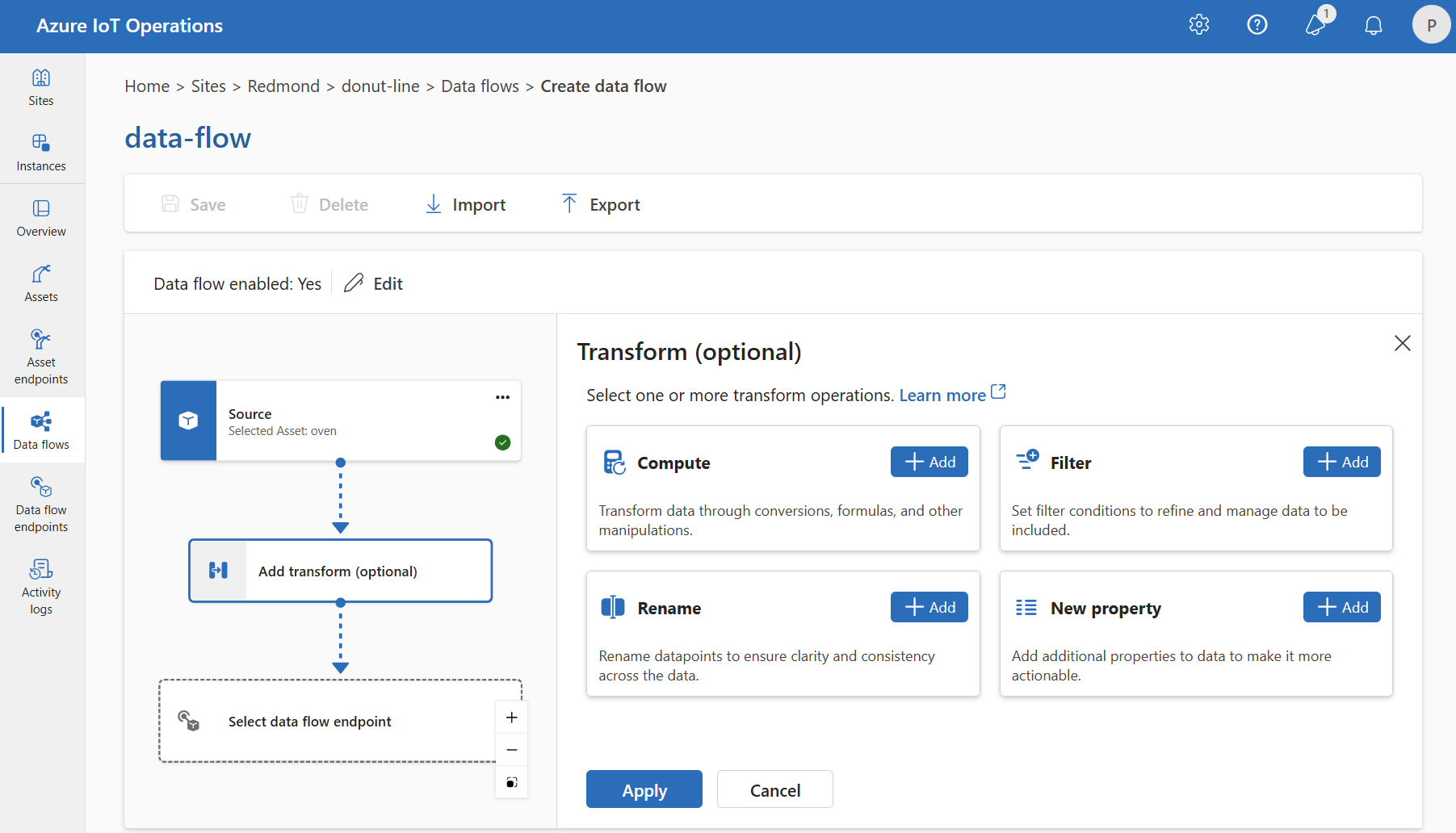
Filter: Filtrera data baserat på ett villkor
Om du vill filtrera data på ett villkor kan du använda filter fasen. Villkoret anges som ett fält i källdata som matchar ett värde.
Under Transformera (valfritt) väljer du Filtrera>lägg till.
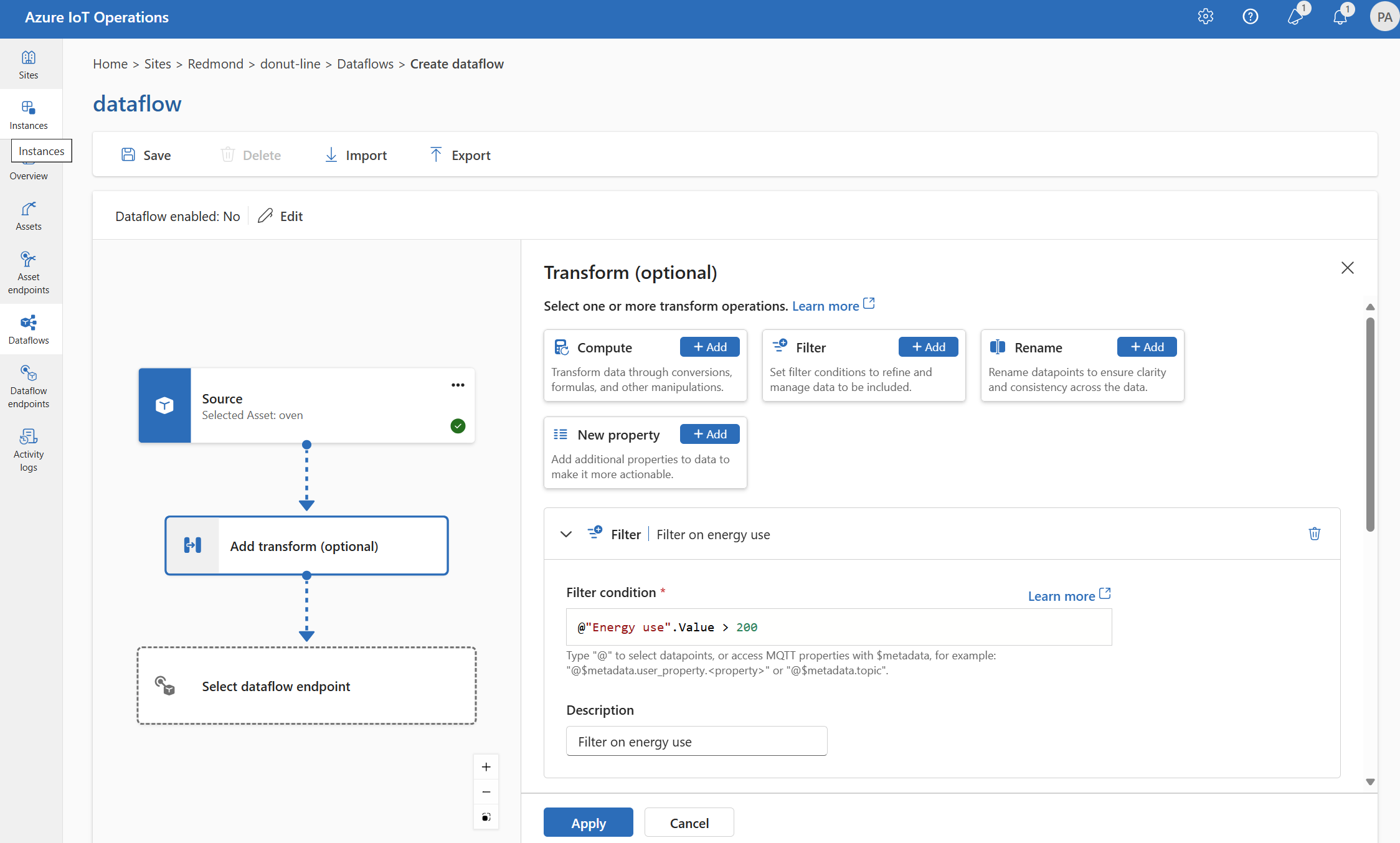
Ange de inställningar som krävs.
Inställning beskrivning Filtervillkor Villkoret för att filtrera data baserat på ett fält i källdata. beskrivning Ange en beskrivning för filtervillkoret. I fältet filtervillkor anger
@eller väljer du Ctrl + Blanksteg för att välja datapunkter i en listruta.Du kan ange MQTT-metadataegenskaper med formatet
@$metadata.user_properties.<property>eller@$metadata.topic. Du kan också ange $metadata rubriker med formatet@$metadata.<header>. Syntaxen$metadatabehövs bara för MQTT-egenskaper som ingår i meddelandehuvudet. Mer information finns i fältreferenser.Villkoret kan använda fälten i källdata. Du kan till exempel använda ett filtervillkor som
@temperature > 20att filtrera data som är mindre än eller lika med 20 baserat på temperaturfältet.Välj Använd.
Karta: Flytta data från ett fält till ett annat
Om du vill mappa data till ett annat fält med valfri konvertering kan du använda åtgärden map . Konverteringen anges som en formel som använder fälten i källdata.
I driftmiljön stöds mappning för närvarande med hjälp av transformeringar av beräkning, byt namn och ny egenskap .
Compute
Du kan använda beräkningstransformningen för att tillämpa en formel på källdata. Den här åtgärden används för att tillämpa en formel på källdata och lagra resultatfältet.
Under Transformera (valfritt) väljer du Beräkningstillägg>.
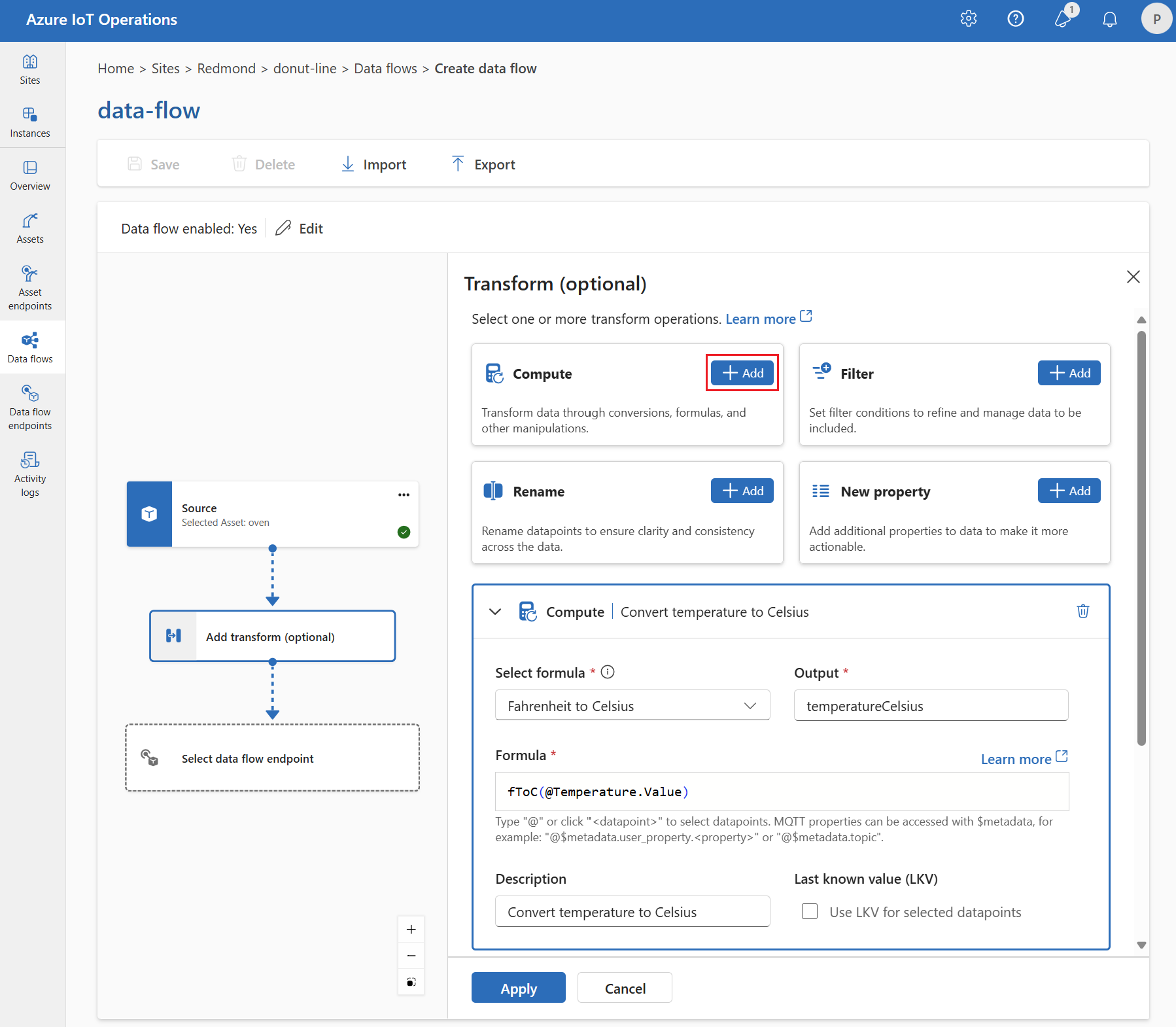
Ange de inställningar som krävs.
Inställning beskrivning Välj formel Välj en befintlig formel i listrutan eller välj Anpassad för att ange en formel manuellt. Output Ange utdatavisningsnamnet för resultatet. Formel Ange formeln som ska tillämpas på källdata. beskrivning Ange en beskrivning för omvandlingen. Senast kända värde Du kan också använda det senast kända värdet om det aktuella värdet inte är tillgängligt. Du kan ange eller redigera en formel i fältet Formel . Formeln kan använda fälten i källdata. Ange
@eller välj Ctrl + Blanksteg för att välja datapunkter i en listruta.Du kan ange MQTT-metadataegenskaper med formatet
@$metadata.user_properties.<property>eller@$metadata.topic. Du kan också ange $metadata rubriker med formatet@$metadata.<header>. Syntaxen$metadatabehövs bara för MQTT-egenskaper som ingår i meddelandehuvudet. Mer information finns i fältreferenser.Formeln kan använda fälten i källdata. Du kan till exempel använda
temperaturefältet i källdata för att konvertera temperaturen till Celsius och lagra den itemperatureCelsiusutdatafältet.Välj Använd.
Byt namn
Du kan byta namn på en datapunkt med transformering byt namn . Den här åtgärden används för att byta namn på en datapunkt i källdata till ett nytt namn. Det nya namnet kan användas i efterföljande steg i dataflödet.
Under Transformera (valfritt) väljer du Byt>namn på Lägg till.
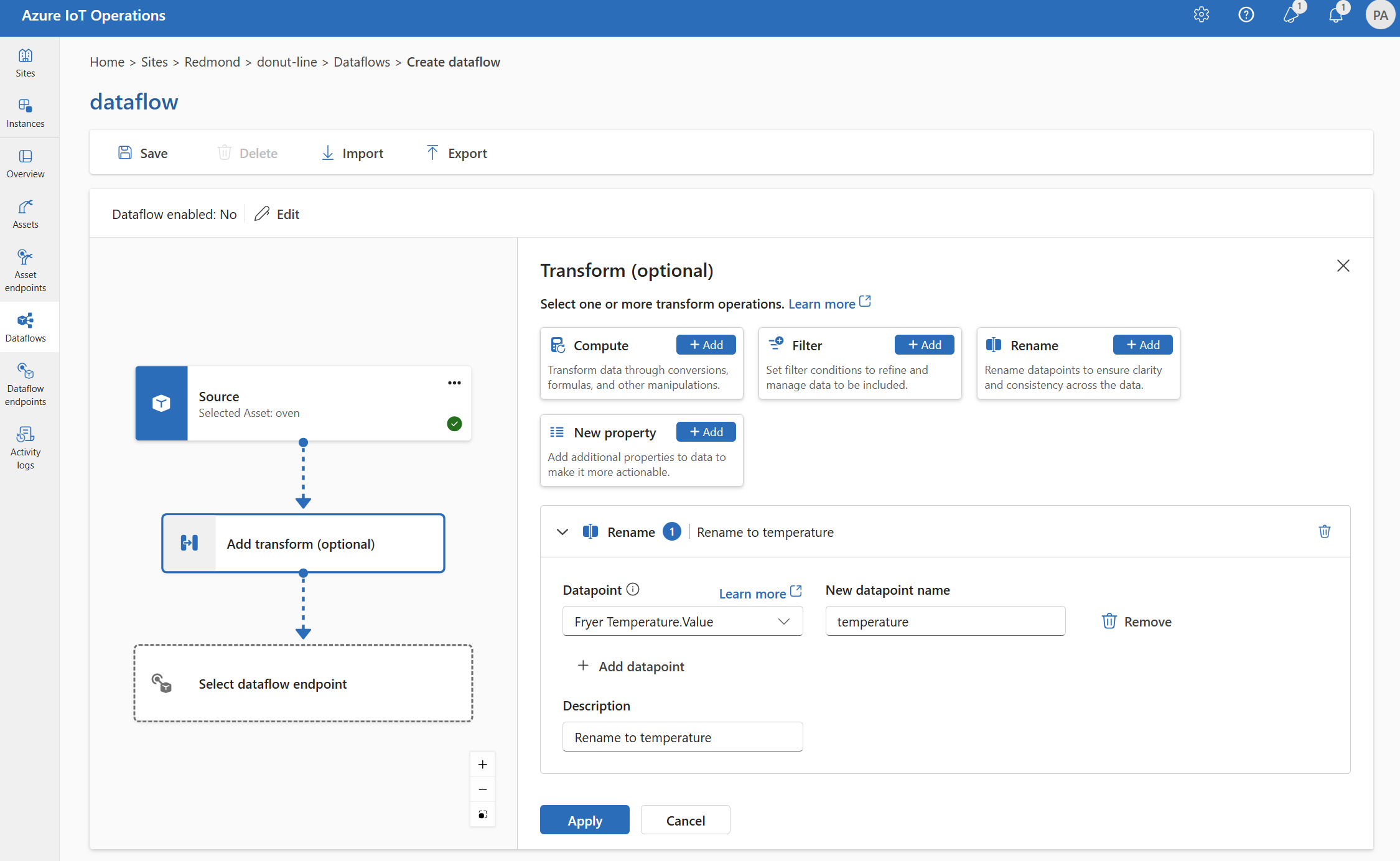
Ange de inställningar som krävs.
Inställning beskrivning Datapunkt Välj en datapunkt i listrutan eller ange ett $metadata sidhuvud. Nytt datapunktsnamn Ange det nya namnet för datapunkten. beskrivning Ange en beskrivning för omvandlingen. Ange
@eller välj Ctrl + Blanksteg för att välja datapunkter i en listruta.Du kan ange MQTT-metadataegenskaper med formatet
@$metadata.user_properties.<property>eller@$metadata.topic. Du kan också ange $metadata rubriker med formatet@$metadata.<header>. Syntaxen$metadatabehövs bara för MQTT-egenskaper som ingår i meddelandehuvudet. Mer information finns i fältreferenser.Välj Använd.
Ny egenskap
Du kan lägga till en ny egenskap i källdata med hjälp av transformering av ny egenskap . Den här åtgärden används för att lägga till en ny egenskap i källdata. Den nya egenskapen kan användas i efterföljande steg i dataflödet.
Under Transformera (valfritt) väljer du Ny egenskap>Lägg till.
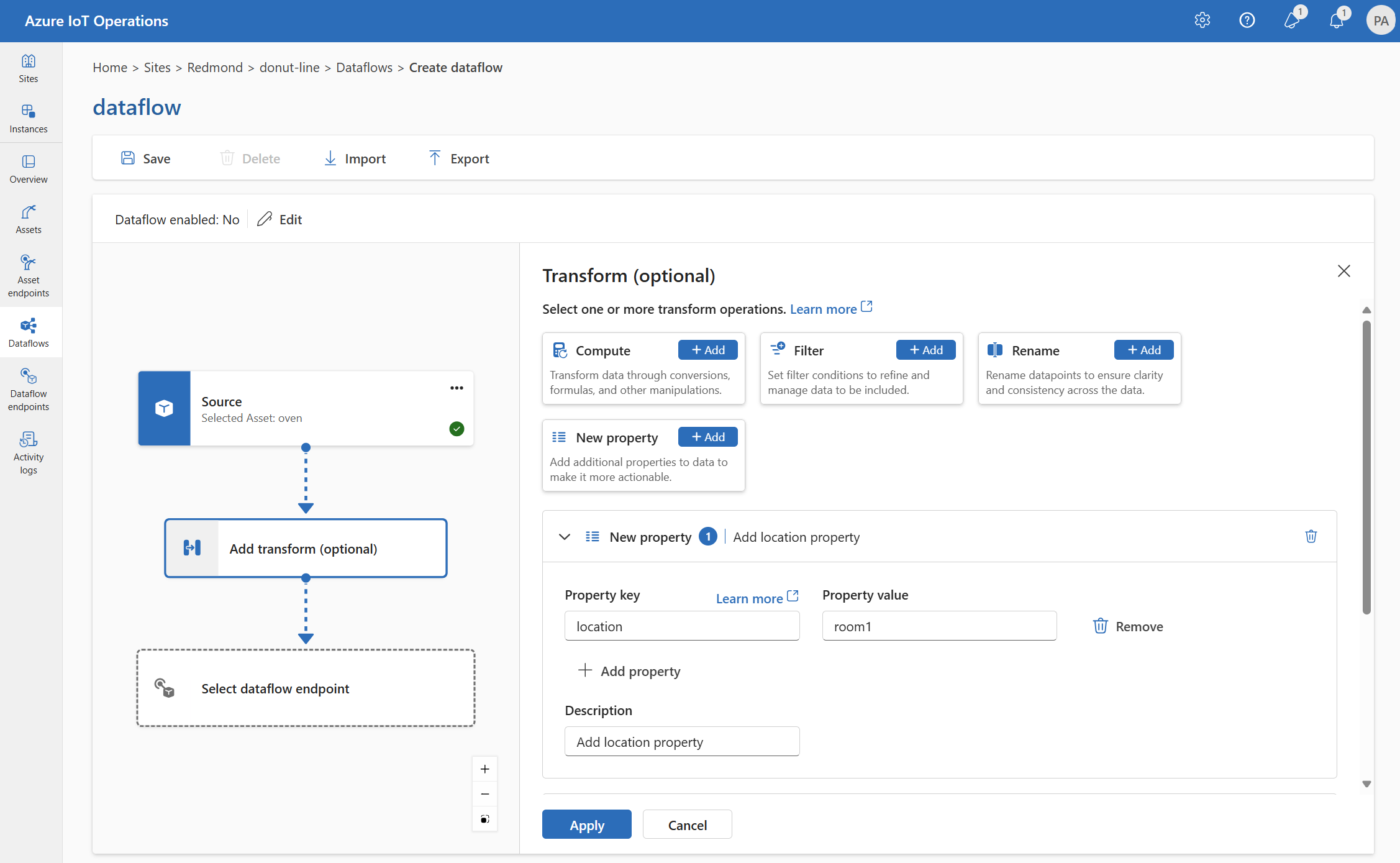
Ange de inställningar som krävs.
Inställning beskrivning Egenskapsnyckel Ange nyckeln för den nya egenskapen. Egenskapsvärde Ange värdet för den nya egenskapen. beskrivning Ange en beskrivning för den nya egenskapen. Välj Använd.
Mer information finns i Mappa data med hjälp av dataflöden och Konvertera data med hjälp av dataflöden.
Serialisera data enligt ett schema
Om du vill serialisera data innan du skickar dem till målet måste du ange ett schema- och serialiseringsformat. Annars serialiseras data i JSON med de typer som härleds. Lagringsslutpunkter som Microsoft Fabric eller Azure Data Lake kräver ett schema för att säkerställa datakonsekvens. Serialiseringsformat som stöds är Parquet och Delta.
Dricks
Om du vill generera schemat från en exempeldatafil använder du schemagenhjälpen.
För driftupplevelse anger du schema- och serialiseringsformatet i information om dataflödesslutpunkten. Slutpunkterna som stöder serialiseringsformat är Microsoft Fabric OneLake, Azure Data Lake Storage Gen 2, Azure Data Explorer och lokal lagring. Om du till exempel vill serialisera data i Delta-format måste du ladda upp ett schema till schemaregistret och referera till dem i konfigurationen av dataflödets målslutpunkt.
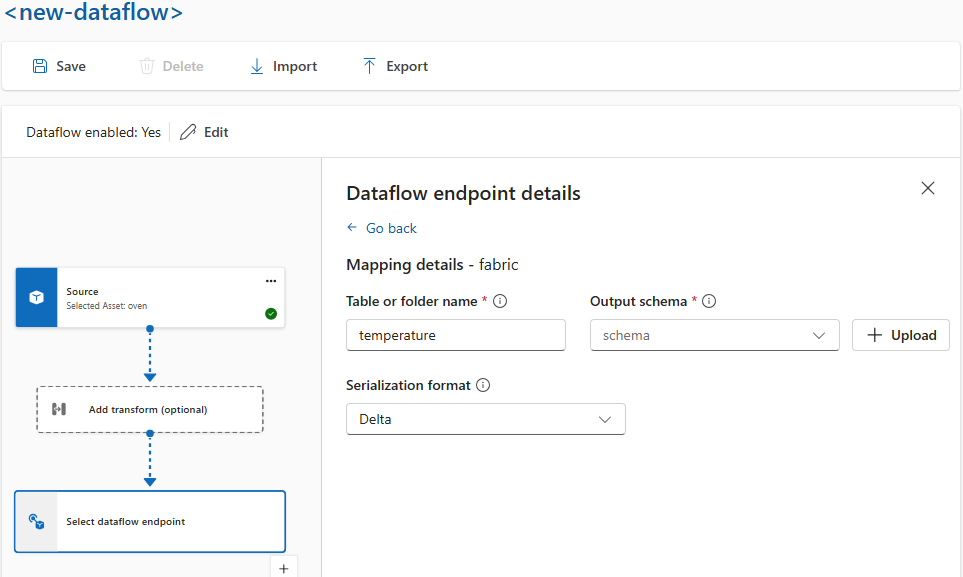
Mer information om schemaregistret finns i Förstå meddelandescheman.
Mål
Om du vill konfigurera ett mål för dataflödet anger du slutpunktsreferensen och datamålet. Du kan ange en lista över datamål för slutpunkten.
Om du vill skicka data till ett annat mål än den lokala MQTT-koordinatorn skapar du en dataflödesslutpunkt. Mer information finns i Konfigurera dataflödesslutpunkter. Om målet inte är den lokala MQTT-koordinatorn måste det användas som källa. Mer information finns i Dataflöden måste använda den lokala MQTT-koordinatorslutpunkten.
Viktigt!
Lagringsslutpunkter kräver ett schema för serialisering. Om du vill använda dataflöde med Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer eller Lokal lagring måste du ange en schemareferens.
Välj den dataflödesslutpunkt som ska användas som mål.
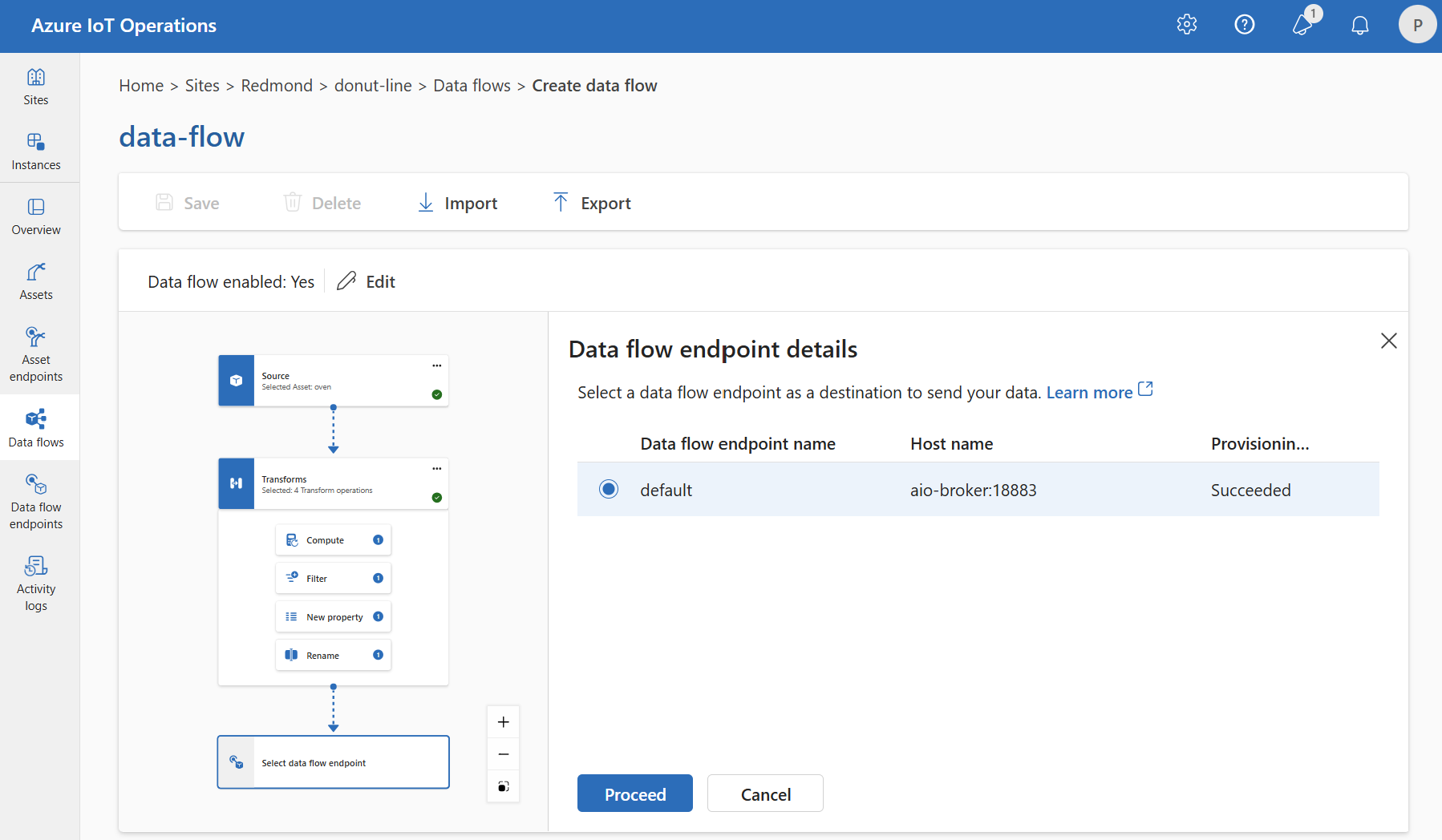
Lagringsslutpunkter kräver ett schema för serialisering. Om du väljer en Microsoft Fabric OneLake-, Azure Data Lake Storage-, Azure Data Explorer- eller Local Storage-målslutpunkt måste du ange en schemareferens. Om du till exempel vill serialisera data till en Microsoft Fabric-slutpunkt i Delta-format måste du ladda upp ett schema till schemaregistret och referera till dem i konfigurationen av dataflödets målslutpunkt.
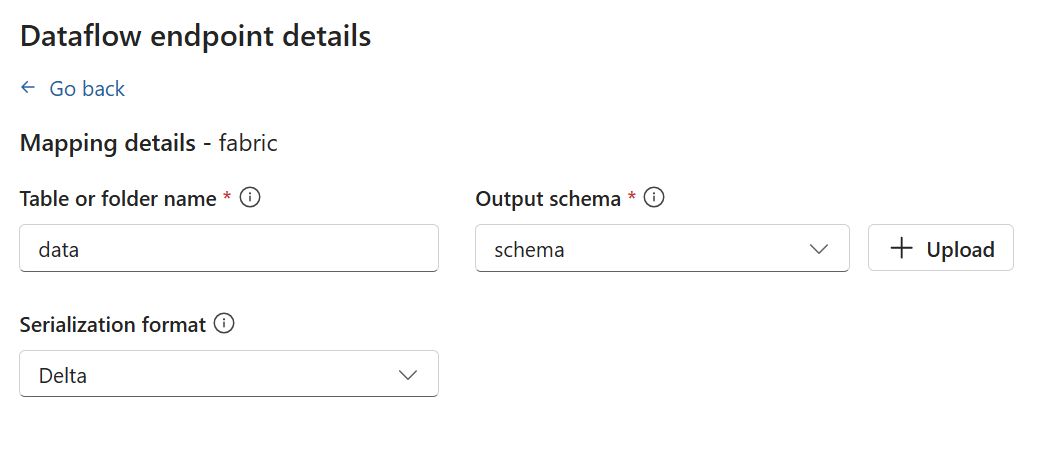
Välj Fortsätt för att konfigurera målet.
Ange de inställningar som krävs för målet, inklusive det ämne eller den tabell som data ska skickas till. Mer information finns i Konfigurera datamål (ämne, container eller tabell).
Konfigurera datamål (ämne, container eller tabell)
Precis som datakällor är datamål ett begrepp som används för att hålla dataflödesslutpunkterna återanvändbara över flera dataflöden. I princip representerar den underkatalogen i konfigurationen av dataflödesslutpunkten. Om dataflödesslutpunkten till exempel är en lagringsslutpunkt är datamålet tabellen i lagringskontot. Om dataflödesslutpunkten är en Kafka-slutpunkt är datamålet Kafka-ämnet.
| Slutpunktstyp | Betydelse för datamål | beskrivning |
|---|---|---|
| MQTT (eller Event Grid) | Område | MQTT-ämnet där data skickas. Endast statiska ämnen stöds, inga jokertecken. |
| Kafka (eller Event Hubs) | Område | Kafka-ämnet där data skickas. Endast statiska ämnen stöds, inga jokertecken. Om slutpunkten är ett Event Hubs-namnområde är datamålet den enskilda händelsehubben i namnområdet. |
| Azure Data Lake Storage | Container | Containern i lagringskontot. Inte tabellen. |
| Microsoft Fabric OneLake | Tabell eller mapp | Motsvarar den konfigurerade sökvägstypen för slutpunkten. |
| Öppna Azure-datautforskaren | Register | Tabellen i Azure Data Explorer-databasen. |
| Lokal lagring | Mapp | Mapp- eller katalognamnet i den lokala lagringsbeständiga volymmonteringen. När du använder Azure Container Storage som aktiveras av Azure Arc Cloud Ingest Edge-volymer måste detta matcha parametern spec.path för den delvolym som du skapade. |
Så här konfigurerar du datamålet:
När du använder driftupplevelsen tolkas datamålfältet automatiskt baserat på slutpunktstypen. Om dataflödesslutpunkten till exempel är en lagringsslutpunkt uppmanas du på sidan med målinformation att ange containernamnet. Om dataflödesslutpunkten är en MQTT-slutpunkt uppmanar målinformationssidan dig att ange ämnet och så vidare.

Exempel
Följande exempel är en dataflödeskonfiguration som använder MQTT-slutpunkten för källan och målet. Källan filtrerar data från MQTT-ämnet azure-iot-operations/data/thermostat. Omvandlingen konverterar temperaturen till Fahrenheit och filtrerar data där temperaturen multiplicerat med luftfuktigheten är mindre än 100000. Målet skickar data till MQTT-ämnet factory.

Mer information om dataflödeskonfigurationer finns i Azure REST API – Dataflöde och snabbstarten Bicep.
Kontrollera att ett dataflöde fungerar
Följ självstudie: Dubbelriktad MQTT-brygga till Azure Event Grid för att kontrollera att dataflödet fungerar.
Exportera dataflödeskonfiguration
Om du vill exportera dataflödeskonfigurationen kan du använda driftupplevelsen eller genom att exportera den anpassade dataflödesresursen.
Välj det dataflöde som du vill exportera och välj Exportera i verktygsfältet.
Korrekt dataflödeskonfiguration
Kontrollera följande för att säkerställa att dataflödet fungerar som förväntat:
- Standardslutpunkten för MQTT-dataflöde måste användas som källa eller mål.
- Dataflödesprofilen finns och refereras till i dataflödeskonfigurationen.
- Källan är antingen en MQTT-slutpunkt, Kafka-slutpunkt eller en tillgång. Slutpunkter av lagringstyp kan inte användas som källa.
- När du använder Event Grid som källa anges instansantalet för dataflödesprofilen till 1 eftersom Event Grid MQTT-asynkron meddelandekö inte stöder delade prenumerationer.
- När du använder Event Hubs som källa är varje händelsehubb i namnområdet ett separat Kafka-ämne och måste anges som datakälla.
- Transformering, om den används, konfigureras med rätt syntax, inklusive korrekt undflyende av specialtecken.
- När du använder slutpunkter av lagringstyp som mål anges ett schema.