RStudio på Azure Databricks
Du kan använda RStudio, en populär integrerad utvecklingsmiljö (IDE) för R, för att ansluta till Azure Databricks-beräkningsresurser i Azure Databricks-arbetsytor. Använd RStudio Desktop för att ansluta till ett Azure Databricks-kluster eller ett SQL-lager från din lokala utvecklingsdator. Du kan också använda webbläsaren för att logga in på din Azure Databricks-arbetsyta och sedan ansluta till ett Azure Databricks-kluster som har RStudio Server installerat på den arbetsytan.
Ansluta med RStudio Desktop
Använd RStudio Desktop för att ansluta till ett fjärranslutet Azure Databricks-kluster eller SQL-lager från din lokala utvecklingsdator. Om du vill ansluta i det här scenariot använder du en ODBC-anslutning och anropar ODBC-paketfunktioner för R, som beskrivs i det här avsnittet.
Kommentar
Du kan inte använda paket som SparkR eller sparklyr i det här RStudio Desktop-scenariot, såvida du inte också använder Databricks Connect. Som ett alternativ till att använda RStudio Desktop kan du använda webbläsaren för att logga in på din Azure Databricks-arbetsyta och sedan ansluta till ett Azure Databricks-kluster som har RStudio Server installerat på den arbetsytan.
Så här konfigurerar du RStudio Desktop på din lokala utvecklingsdator:
- Ladda ned och installera R 3.3.0 eller senare.
- Ladda ned och installera RStudio Desktop.
- Starta RStudio Desktop.
(Valfritt) Så här skapar du ett RStudio-projekt:
- Starta RStudio Desktop.
- Klicka på > för fil.
- Välj Ny katalog > Nytt projekt.
- Välj en ny katalog för projektet och klicka sedan på Skapa projekt.
Så här skapar du ett R-skript:
- När projektet är öppet klickar du på >.>
- Klicka på Spara > som fil.
- Namnge filen och klicka sedan på Spara.
Så här ansluter du till det fjärranslutna Azure Databricks-klustret eller SQL-lagret via ODBC för R:
Hämta Server-värdnamnet, Portoch HTTP-sökvägen värden för ditt fjärranslutna kluster eller SQL-lager. För ett kluster finns dessa värden på fliken JDBC/ODBC i Avancerade alternativ. För ett SQL-lager finns dessa värden på fliken Anslutningsinformation.
Hämta en Azure Databricks-personlig åtkomsttoken.
Kommentar
När du autentiserar med automatiserade verktyg, system, skript och appar rekommenderar Databricks att du använder personliga åtkomsttoken som tillhör tjänstens huvudnamn i stället för arbetsyteanvändare. Information om hur du skapar token för tjänstens huvudnamn finns i Hantera token för tjänstens huvudnamn.
Installera och konfigurera Databricks ODBC-drivrutinen för Windows, macOS eller Linux baserat på den lokala datorns operativsystem.
Konfigurera ett ODBC-namn (DSN) till ditt fjärrkluster eller SQL-lager för Windows, macOSeller Linux, baserat på den lokala datorns operativsystem.
Från RStudio-konsolen (Visa > Flytta fokus till konsol) installerar du odbc- och DBI-paketen från CRAN:
require(devtools) install_version( package = "odbc", repos = "http://cran.us.r-project.org" ) install_version( package = "DBI", repos = "http://cran.us.r-project.org" )I R-skriptet (Visa > Flytta fokus till källa) läser du in de installerade
odbcpaketen ochDBI:library(odbc) library(DBI)Anropa ODBC-versionen av dbConnect-funktionen
conn = dbConnect( drv = odbc(), dsn = "Databricks" )Anropa en åtgärd via ODBC DSN, till exempel en
SELECT-instruktion via funktionen dbGetQuery iDBI-paketet, som anger namnet på anslutningsvariabeln och självaSELECT-instruktionen, till exempel från en tabell med namnetdiamondsi ett schema (databas) med namnetdefault:print(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
Det fullständiga R-skriptet är följande:
library(odbc)
library(DBI)
conn = dbConnect(
drv = odbc(),
dsn = "Databricks"
)
print(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
Om du vill köra skriptet klickar du på Källa i källvyn. Resultatet för föregående R-skript är följande:
_c0 carat cut color clarity depth table price x y z
1 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
Ansluta till en Databricks-värdbaserad RStudio Server
Viktigt!
Databricks-värdbaserade RStudio Server är inaktuell och är endast tillgängligt på Databricks Runtime version 15.4 och senare. Mer information finns i Utfasning av värdbaserad RStudio Server.
Använd webbläsaren för att logga in på din Azure Databricks-arbetsyta och anslut sedan till en Azure Databricks-beräkning som har RStudio Server installerat på den arbetsytan.
Mer information finns i Ansluta till en Databricks-värdbaserad RStudio-server
RStudio-integreringsarkitektur
När du använder RStudio Server på Azure Databricks körs RStudio Server Daemon på drivrutinsnoden i ett Azure Databricks-kluster. Webbgränssnittet för RStudio är proxied via Azure Databricks-webbappen, vilket innebär att du inte behöver göra några ändringar i klusternätverkskonfigurationen. Det här diagrammet visar arkitekturen för RStudio-integreringskomponenten.
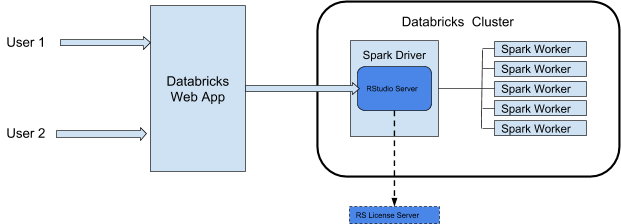
Varning
Azure Databricks proxyservrar RStudio-webbtjänsten från port 8787 på klustrets Spark-drivrutin. Den här webbproxyn är endast avsedd för användning med RStudio. Om du startar andra webbtjänster på port 8787 kan du utsätta användarna för potentiella säkerhetsexploateringar. Varken Databricks eller Microsoft ansvarar för eventuella problem som uppstår vid installation av programvara som inte stöds i ett kluster.
Krav
Klustret måste vara ett kluster för alla syften.
Du måste ha behörigheten KAN KOPPLA TILL för klustret. Klusteradministratören kan ge dig den här behörigheten. Se Beräkningsbehörigheter.
Klustret får inte ha tabellåtkomstkontroll, automatisk avslutningeller genomströmning av autentiseringsuppgifter aktiverat.
Klustret får inte använda läget Deladåtkomst.
Klustret får inte ha Spark-konfigurationen
spark.databricks.pyspark.enableProcessIsolationinställd påtrue.Du måste ha en flytande Pro-licens för RStudio Server för att kunna använda Pro-utgåvan.
Kommentar
Även om klustret kan använda ett åtkomstläge som stöder Unity Catalog, kan du inte använda RStudio Server från klustret för att komma åt data i Unity Catalog.
Kom igång: RStudio Server OS Edition
RStudio Server Open Source Edition är förinstallerat på Azure Databricks-kluster som använder Databricks Runtime for Machine Learning (Databricks Runtime ML).
Gör följande för att öppna RStudio Server OS Edition i ett kluster:
Öppna informationssidan för klustret.
Starta klustret och klicka sedan på fliken Appar :
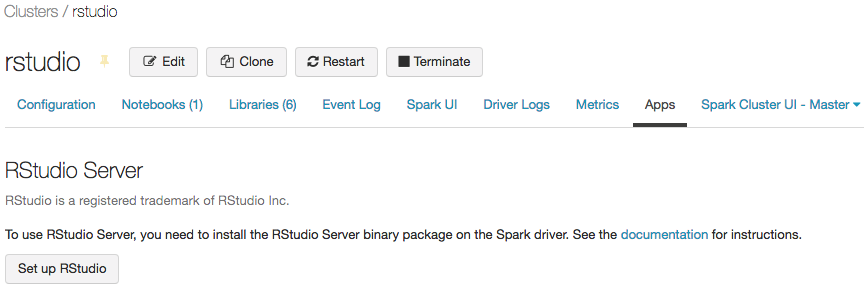
På fliken Appar klickar du på knappen Konfigurera RStudio. Detta genererar ett engångslösenord åt dig. Klicka på visa-länken för att visa den och kopiera lösenordet.
Klicka på länken Öppna RStudio för att öppna användargränssnittet på en ny flik. Ange ditt användarnamn och lösenord i inloggningsformuläret och logga in.
Från RStudio-användargränssnittet kan du importera
SparkR-paketet och konfigurera enSparkRsession för att starta Spark-jobb i klustret.library(SparkR) sparkR.session() # Query the first two rows of a table named "diamonds" in a # schema (database) named "default" and display the query result. df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2") showDF(df)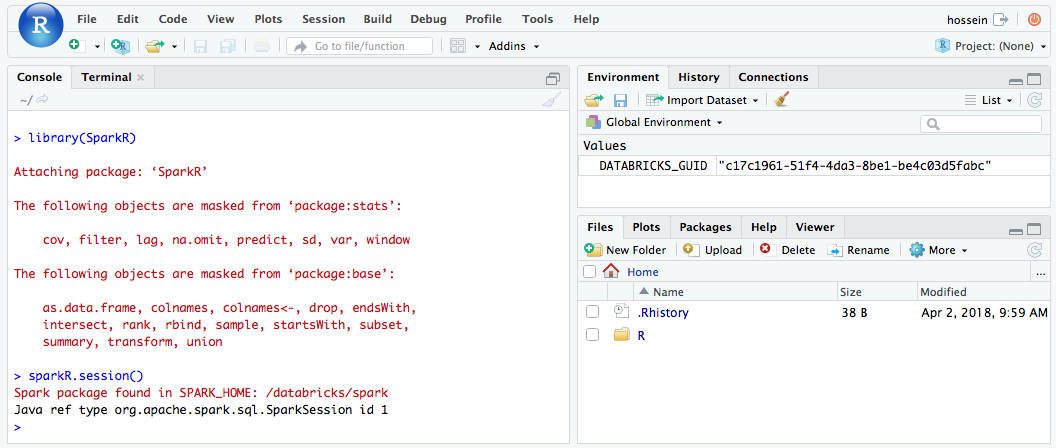
Du kan också koppla sparklyr--paketet och konfigurera en Spark-anslutning.
library(sparklyr) sc <- spark_connect(method = "databricks") # Query a table named "diamonds" and display the first two rows. df <- spark_read_table(sc = sc, name = "diamonds") print(x = df, n = 2)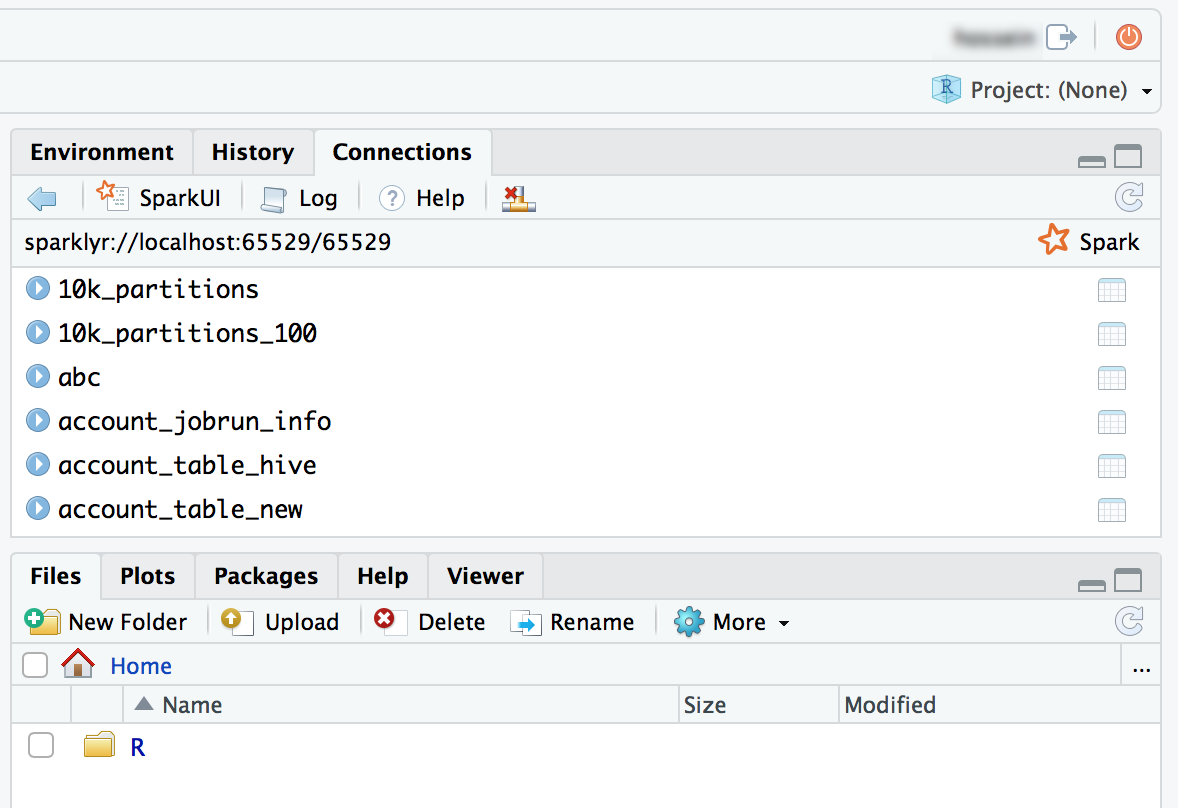
Kom igång: RStudio Workbench
Det här avsnittet visar hur du konfigurerar och börjar använda RStudio Workbench (tidigare RStudio Server Pro) i ett Azure Databricks-kluster. Beroende på din licens kan RStudio Workbench innehålla RStudio Server Pro.
Konfigurera RStudio-licensserver
Om du vill använda RStudio Workbench i Azure Databricks måste du konvertera pro-licensen till en flytande licens. Kontakta om du vill ha help@rstudio.comhjälp. När licensen konverteras måste du konfigurera en licensserver för RStudio Workbench.
Så här konfigurerar du en licensserver:
- Starta en liten instans i molnleverantörens nätverk. licensserverns daemon är mycket enkel.
- Ladda ned och installera motsvarande version av RStudio-licensservern på din instans och starta tjänsten. Detaljerade anvisningar finns i administrationsguiden för RStudio Workbench.
- Kontrollera att licensserverporten är öppen för Azure Databricks-instanser.
Installera RStudio Workbench
Om du vill konfigurera RStudio Workbench i ett Azure Databricks-kluster måste du skapa ett init-skript för att installera det binära RStudio Workbench-paketet och konfigurera det så att det använder licensservern för licenslån.
Kommentar
Om du planerar att installera RStudio Workbench på en Databricks Runtime-version som redan innehåller RStudio Server Open Source Edition-paketet måste du först avinstallera paketet för att installationen ska lyckas.
Följande är ett exempel .sh fil som du kan lagra som ett init-skript på en plats, till exempel i din hemkatalog som en arbetsytefil, i en Unity Catalog-volym eller i objektlagring. Mer information finns i Klusteromfattande init-skript. Skriptet utför även ytterligare autentiseringskonfigurationer som effektiviserar integreringen med Azure Databricks.
Varning
Init-skript med klusteromfattning i DBFS är livslängdens slut. Lagring av init-skript i DBFS finns på vissa arbetsytor för att stödja äldre arbetsbelastningar och rekommenderas inte. Alla init-skript som lagras i DBFS ska migreras. Migreringsinstruktioner finns i Migrera init-skript från DBFS.
#!/bin/bash
set -euxo pipefail
if [[ $DB_IS_DRIVER = "TRUE" ]]; then
sudo apt-get update
sudo dpkg --purge rstudio-server # in case open source version is installed.
sudo apt-get install -y gdebi-core alien
## Installing RStudio Workbench
cd /tmp
# You can find new releases at https://rstudio.com/products/rstudio/download-commercial/debian-ubuntu/.
wget https://download2.rstudio.org/server/bionic/amd64/rstudio-workbench-2022.02.1-461.pro1-amd64.deb -O rstudio-workbench.deb
sudo gdebi -n rstudio-workbench.deb
## Configuring authentication
sudo echo 'auth-proxy=1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-user-header-rewrite=^(.*)$ $1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-sign-in-url=<domain>/login.html' >> /etc/rstudio/rserver.conf
sudo echo 'admin-enabled=1' >> /etc/rstudio/rserver.conf
sudo echo 'export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin' >> /etc/rstudio/rsession-profile
# Enabling floating license
sudo echo 'server-license-type=remote' >> /etc/rstudio/rserver.conf
# Session configurations
sudo echo 'session-rprofile-on-resume-default=1' >> /etc/rstudio/rsession.conf
sudo echo 'allow-terminal-websockets=0' >> /etc/rstudio/rsession.conf
sudo rstudio-server license-manager license-server <license-server-url>
sudo rstudio-server restart || true
fi
- Ersätt
<domain>med din Azure Databricks-URL och<license-server-url>med URL:en för din flytande licensserver. - Lagra den här
.shfilen som ett init-skript på en plats, till exempel i din hemkatalog som en arbetsytefil, i en Unity Catalog-volym eller i objektlagring. Mer information finns i Klusteromfattande init-skript. - Innan du startar ett kluster lägger du till den här
.shfilen som ett init-skript från den associerade platsen. Anvisningar finns i Klusteromfattande init-skript. - Starta klustret.
Använda RStudio Server Pro
Öppna informationssidan för klustret.
Starta klustret och klicka på fliken Appar :
På fliken Appar klickar du på knappen Konfigurera RStudio.
Du behöver inte engångslösenordet. Klicka på länken Öppna RStudio-användargränssnitt så öppnas en autentiserad RStudio Pro-session åt dig.
Från RStudio-användargränssnittet kan du koppla
SparkR-paketet och konfigurera enSparkRsession för att starta Spark-jobb i klustret.library(SparkR) sparkR.session() # Query the first two rows of a table named "diamonds" in a # schema (database) named "default" and display the query result. df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2") showDF(df)
Du kan också koppla sparklyr--paketet och konfigurera en Spark-anslutning.
library(sparklyr) sc <- spark_connect(method = "databricks") # Query a table named "diamonds" and display the first two rows. df <- spark_read_table(sc = sc, name = "diamonds") print(x = df, n = 2)
Vanliga frågor och svar om RStudio Server
Vad är skillnaden mellan RStudio Server Open Source Edition och RStudio Workbench?
RStudio Workbench har stöd för en mängd olika företagsfunktioner som inte är tillgängliga i Open Source Edition. Du kan se funktionsjämförelsen på RStudios webbplats.
Dessutom distribueras RStudio Server Open Source Edition under GNU Affero General Public License (AGPL), medan Pro-versionen levereras med en kommersiell licens för organisationer som inte kan använda AGPL-programvara.
Slutligen kommer RStudio Workbench med professionellt och företagsstöd från RStudio, PBC, medan RStudio Server Open Source Edition inte har något stöd.
Kan jag använda min RStudio Workbench/RStudio Server Pro-licens på Azure Databricks?
Ja, om du redan har en Pro- eller Enterprise-licens för RStudio Server kan du använda den licensen på Azure Databricks. Se Kom igång: RStudio Workbench för att lära dig hur du konfigurerar RStudio Workbench på Azure Databricks.
Var körs RStudio Server? Behöver jag hantera ytterligare tjänster/servrar?
Som du ser i diagrammet i RStudio-integreringsarkitekturen körs RStudio Server-daemonen på drivrutinsnoden (huvudnoden) i ditt Azure Databricks-kluster. Med RStudio Server Open Source Edition behöver du inte köra några ytterligare servrar/tjänster. För RStudio Workbench måste du dock hantera en separat instans som kör RStudio License Server.
Kan jag använda RStudio Server på ett standardkluster?
Kommentar
Den här artikeln beskriver användargränssnittet för äldre kluster. Information om det nya klustrets användargränssnitt (i förhandsversion), inklusive terminologiändringar för klusteråtkomstlägen, finns i Referens för beräkningskonfiguration. En jämförelse av de nya och äldre klustertyperna finns i Kluster användargränssnittsändringar och klusteråtkomstlägen.
Ja, det kan du.
Kan jag använda RStudio Server i ett kluster med automatisk avslutning?
Nej, du kan inte använda RStudio när automatisk avslutning är aktiverat. Automatisk avslutning kan rensa osparade användarskript och data i en RStudio-session. För att skydda användarna mot det här scenariot med oavsiktlig dataförlust inaktiveras RStudio som standard i sådana kluster.
För kunder som behöver rensa klusterresurser när de inte används rekommenderar Databricks att du använder kluster-API:er för att rensa RStudio-kluster baserat på ett schema.
Hur ska jag spara mitt arbete på RStudio?
Vi rekommenderar starkt att du bevarar ditt arbete med hjälp av ett versionskontrollsystem från RStudio. RStudio har bra stöd för olika versionskontrollsystem och gör att du kan checka in och hantera dina projekt. Om du inte bevarar koden via någon av följande metoder riskerar du att förlora ditt arbete om en arbetsyteadministratör startar om eller avslutar klustret.
En metod är att spara dina filer (kod eller data) på vad är DBFS?. Om du till exempel sparar en fil under /dbfs/ filerna tas den inte bort när klustret avslutas eller startas om.
En annan metod är att spara R-anteckningsboken i det lokala filsystemet genom att exportera den som Rmarkdownoch sedan importera filen till RStudio-instansen. I bloggen Dela R Notebooks med RMarkdown beskrivs stegen mer detaljerat.
Hur gör jag för att starta en SparkR session?
SparkR finns i Databricks Runtime, men du måste läsa in den i RStudio. Kör följande kod i RStudio för att initiera en SparkR session.
library(SparkR)
sparkR.session()
Om det uppstår ett fel när paketet importeras SparkR kör .libPaths() du och kontrollerar att /home/ubuntu/databricks/spark/R/lib det ingår i resultatet.
Om den inte ingår kontrollerar du innehållet /usr/lib/R/etc/Rprofile.sitei . Visa /home/ubuntu/databricks/spark/R/lib/SparkR på drivrutinen för att kontrollera att SparkR-paketet är installerat.
Hur gör jag för att starta en sparklyr session?
Paketet sparklyr måste vara installerat på klustret. Använd någon av följande metoder för att installera sparklyr paketet:
- Som ett Azure Databricks-bibliotek
-
install.packages()kommando` - Användargränssnitt för RStudio-pakethantering
library(sparklyr)
sc <- spark_connect(method = “databricks”)
Hur integreras RStudio med Azure Databricks R-notebook-filer?
Du kan flytta ditt arbete mellan notebook-filer och RStudio via versionskontroll.
Vad är arbetskatalogen?
När du startar ett projekt i RStudio väljer du en arbetskatalog. Som standard är det här hemkatalogen på drivrutinscontainern (master) där RStudio Server körs. Du kan ändra den här katalogen om du vill.
Kan jag starta Shiny Apps från RStudio som körs på Azure Databricks?
Ja, du kan utveckla och visa Shiny-program i RStudio Server på Databricks.
Jag kan inte använda terminal eller git i RStudio på Azure Databricks. Hur kan jag åtgärda det?
Kontrollera att du har inaktiverat websockets. I RStudio Server Open Source Edition kan du göra detta från användargränssnittet.
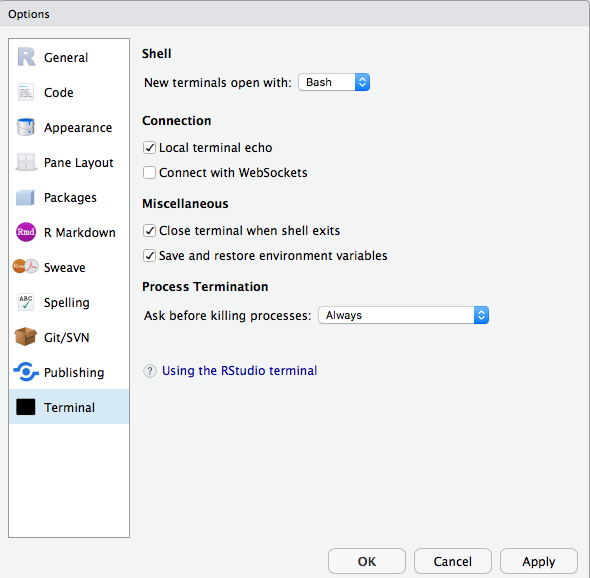
I RStudio Server Pro kan du lägga till allow-terminal-websockets=0 i /etc/rstudio/rsession.conf för att inaktivera websockets för alla användare.
Fliken Appar visas inte under klusterinformation.
Den här funktionen är inte tillgänglig för alla kunder. Du måste vara med i Premium-planen.