sparklyr
Azure Databricks stöder sparklyr i notebook-filer, jobb och RStudio Desktop. Den här artikeln beskriver hur du kan använda sparklyr och innehåller exempelskript som du kan köra. Mer information finns i R-gränssnittet till Apache Spark .
Krav
Azure Databricks distribuerar den senaste stabila versionen av sparklyr med varje Databricks Runtime-version. Du kan använda sparklyr i Azure Databricks R-notebook-filer eller i RStudio Server som finns på Azure Databricks genom att importera den installerade versionen av sparklyr.
I RStudio Desktop låter Databricks Connect dig ansluta sparklyr från din lokala dator till Azure Databricks-kluster och köra Apache Spark-kod. Se Använda sparklyr och RStudio Desktop med Databricks Connect.
Ansluta sparklyr till Azure Databricks-kluster
Om du vill upprätta en sparklyr-anslutning kan du använda "databricks" som anslutningsmetod i spark_connect().
Inga ytterligare parametrar för spark_connect() behövs, inte heller behöver man anropa spark_install() eftersom Spark redan är installerat på ett Azure Databricks-kluster.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
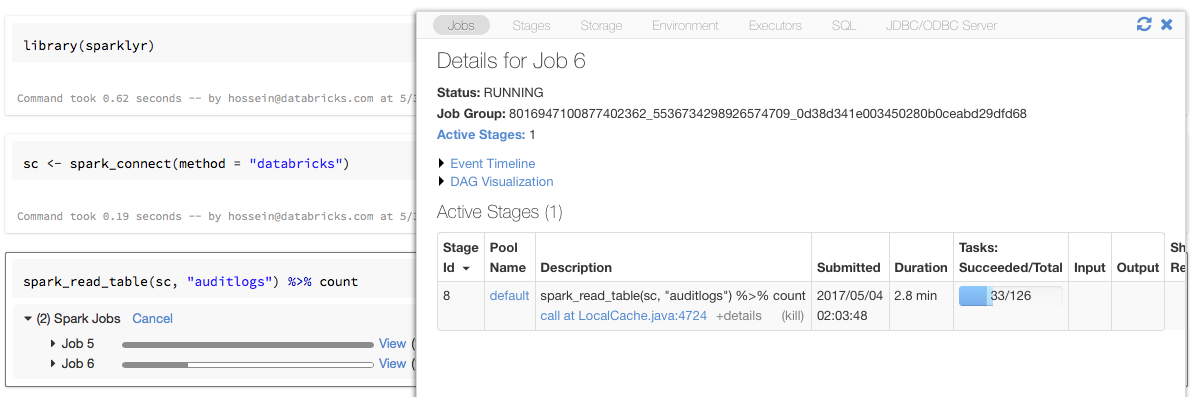
Förloppsstaplar och Spark-användargränssnitt med sparklyr
Om du tilldelar sparklyr-anslutningsobjektet till en variabel med namnet sc som i exemplet ovan visas Spark-förloppsstaplar i notebook-filen efter varje kommando som utlöser Spark-jobb.
Dessutom kan du klicka på länken bredvid förloppsindikatorn för att visa Spark-användargränssnittet som är associerat med det angivna Spark-jobbet.
Använda sparklyr
När du har installerat sparklyr och upprättat anslutningen fungerar alla andra sparklyr-API:er som normalt. Se exempelanteckningsboken för några exempel.
sparklyr används vanligtvis tillsammans med andra tidyverse-paket som dplyr. De flesta av dessa paket är förinstallerade på Databricks för din bekvämlighet. Du kan bara importera dem och börja använda API:et.
Använda sparklyr och SparkR tillsammans
SparkR och sparklyr kan användas tillsammans i en enda notebook-fil eller ett jobb. Du kan importera SparkR tillsammans med sparklyr och använda dess funktioner. I Azure Databricks-notebook-filer är SparkR-anslutningen förkonfigurerad.
Några av funktionerna i SparkR maskerar ett antal funktioner i dplyr:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Om du importerar SparkR efter att du har importerat dplyr kan du referera till funktionerna i dplyr med hjälp av de fullständigt kvalificerade namnen, dplyr::arrange()till exempel .
På samma sätt maskeras funktionerna i SparkR av dplyr om du importerar dplyr efter SparkR.
Du kan också selektivt koppla från ett av de två paketen medan du inte behöver det.
detach("package:dplyr")
Se även Jämföra SparkR och sparklyr.
Använda sparklyr i spark-submit-jobb
Du kan köra skript som använder sparklyr på Azure Databricks som spark-submit-jobb med mindre kodändringar. Vissa av instruktionerna ovan gäller inte för användning av sparklyr i spark-submit-jobb i Azure Databricks. I synnerhet måste du ange Spark-huvud-URL:en till spark_connect. Till exempel:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Funktioner som inte stöds
Azure Databricks stöder inte sparklyr-metoder som spark_web() och spark_log() som kräver en lokal webbläsare. Men eftersom Spark-användargränssnittet är inbyggt i Azure Databricks kan du enkelt inspektera Spark-jobb och -loggar.
Se Beräkningsdrivrutins- och arbetsloggar.
Exempel på notebook-fil: Sparklyr-demonstration
Sparklyr Notebook
Ytterligare exempel finns i Arbeta med DataFrames och tabeller i R.