Shiny på Azure Databricks
Shiny är ett R-paket som finns på CRAN och används för att skapa interaktiva R-program och instrumentpaneler. Du kan använda Shiny i RStudio Server som finns i Azure Databricks-kluster. Du kan också utveckla, vara värd för och dela Shiny-program direkt från en Azure Databricks-notebook-fil.
Om du vill komma igång med Shiny kan du läsa de glänsande självstudierna. Du kan köra de här självstudierna i Azure Databricks-notebook-filer.
Den här artikeln beskriver hur du kör Shiny-program på Azure Databricks och använder Apache Spark i Shiny-program.
Glänsande inuti R-anteckningsböcker
Kom igång med shiny inuti R notebook-filer
Shiny-paketet ingår i Databricks Runtime. Du kan interaktivt utveckla och testa Shiny-program i Azure Databricks R-notebook-filer på samma sätt som värdbaserade RStudio.
Följ dessa steg för att komma igång:
Skapa en R-anteckningsbok.
Importera Shiny-paketet och kör exempelappen
01_hellopå följande sätt:library(shiny) runExample("01_hello")När appen är klar innehåller utdata url:en för Shiny-appen som en klickbar länk som öppnar en ny flik. Information om hur du delar den här appen med andra användare finns i Dela glänsande app-URL.

Kommentar
- Loggmeddelanden visas i kommandoresultatet, ungefär som standardloggmeddelandet (
Listening on http://0.0.0.0:5150) som visas i exemplet. - Om du vill stoppa Shiny-programmet klickar du på Avbryt.
- Shiny-programmet använder notebook R-processen. Om du kopplar från anteckningsboken från klustret, eller om du avbryter cellen som kör programmet, avslutas Shiny-programmet. Du kan inte köra andra celler medan Shiny-programmet körs.
Köra Shiny-appar från Databricks Git-mappar
Du kan köra Shiny-appar som är incheckade i Databricks Git-mappar.
Kör programmet.
library(shiny) runApp("006-tabsets")
Köra Shiny-appar från filer
Om din Shiny-programkod ingår i ett projekt som hanteras av versionskontrollen kan du köra den i notebook-filen.
Kommentar
Du måste använda den absoluta sökvägen eller ange arbetskatalogen med setwd().
Kolla in koden från en lagringsplats med hjälp av kod som liknar:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Om du vill köra programmet anger du kod som liknar följande i en annan cell:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Dela glänsande app-URL
Url:en för shiny-appen som genereras när du startar en app kan delas med andra användare. Alla Azure Databricks-användare med CAN ATTACH TO-behörighet i klustret kan visa och interagera med appen så länge både appen och klustret körs.
Om klustret som appen körs på avslutas är appen inte längre tillgänglig. Du kan inaktivera automatisk avslutning i klusterinställningarna.
Om du bifogar och kör notebook-filen som är värd för Shiny-appen i ett annat kluster ändras shiny-URL:en. Om du startar om appen i samma kluster kan Shiny också välja en annan slumpmässig port. För att säkerställa en stabil URL kan du ange shiny.port alternativet, eller när du startar om appen i samma kluster kan du ange port argumentet.
Shiny på värdbaserad RStudio Server
Krav
Viktigt!
Med RStudio Server Pro måste du inaktivera proxierad autentisering.
Se till att auth-proxy=1 inte finns i /etc/rstudio/rserver.conf.
Kom igång med Shiny på värdbaserade RStudio Server
Öppna RStudio på Azure Databricks.
Importera Shiny-paketet i RStudio och kör exempelappen
01_hellopå följande sätt:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Ett nytt fönster visas med shiny-programmet.
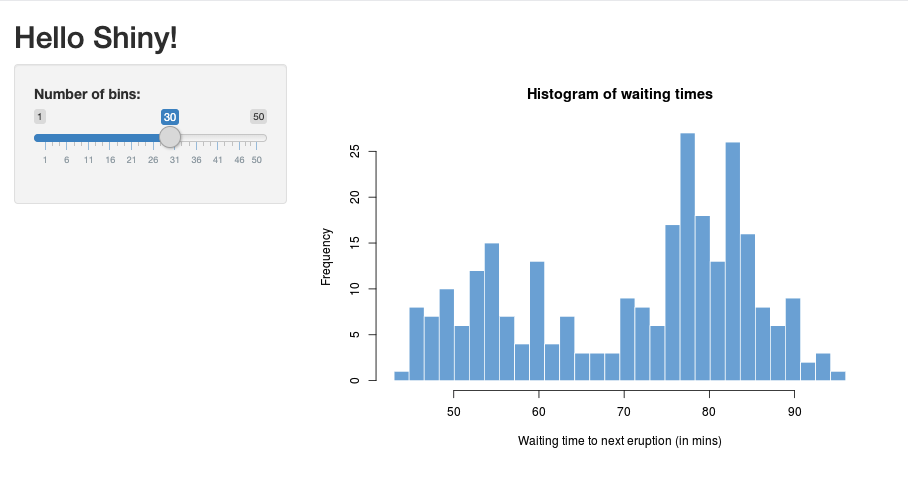
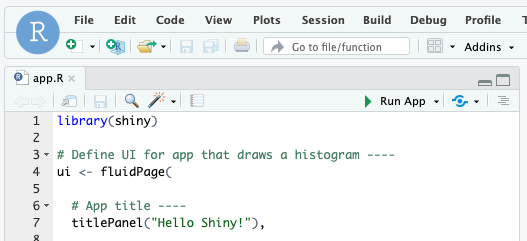
Köra en Shiny-app från ett R-skript
Om du vill köra en Shiny-app från ett R-skript öppnar du R-skriptet i RStudio-redigeraren och klickar på knappen Kör app längst upp till höger.
Använda Apache Spark i Shiny-appar
Du kan använda Apache Spark i Shiny-program med antingen SparkR eller sparklyr.
Använda SparkR med Shiny i en notebook-fil
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Använd sparklyr med Shiny i en notebook-fil
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
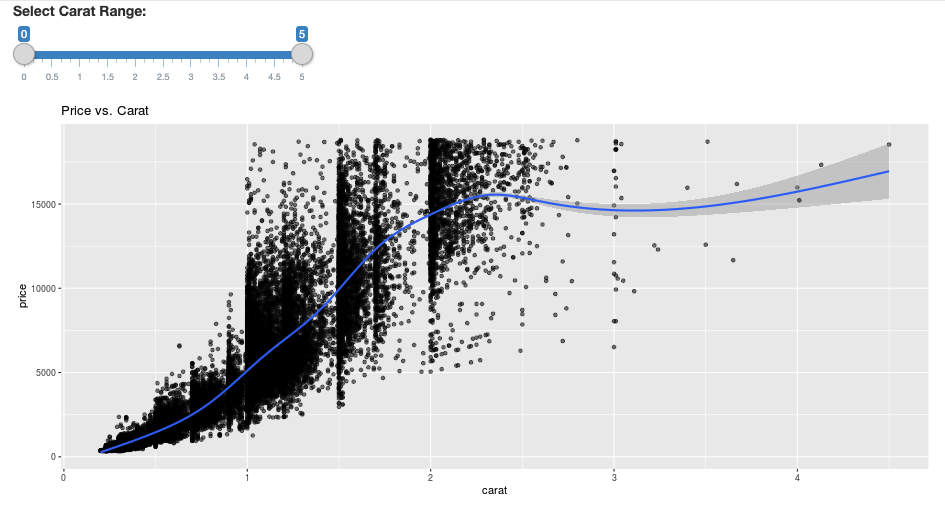
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Vanliga frågor och svar
- Varför är min Shiny-app nedtonad efter en tid?
- Varför försvinner mitt glänsande visningsfönster efter ett tag?
- Varför kommer långa Spark-jobb aldrig tillbaka?
- Hur undviker jag tidsgränsen?
- Min app kraschar direkt efter starten, men koden verkar vara korrekt. Vad är det som händer?
- Hur många anslutningar kan accepteras för en Shiny-applänk under utvecklingen?
- Kan jag använda en annan version av Shiny-paketet än den som installerades i Databricks Runtime?
- Hur kan jag utveckla ett Shiny-program som kan publiceras till en Shiny-server och få åtkomst till data i Azure Databricks?
- Kan jag utveckla ett Shiny-program i en Azure Databricks-notebook-fil?
- Hur kan jag spara shiny-program som jag utvecklade på värdbaserade RStudio Server?
Varför är min Shiny-app nedtonad efter en tid?
Om det inte finns någon interaktion med Shiny-appen stängs anslutningen till appen efter cirka 4 minuter.
Om du vill återansluta uppdaterar du shiny-appsidan. Instrumentpanelens tillstånd återställs.
Varför försvinner mitt glänsande visningsfönster efter ett tag?
Om shiny viewer-fönstret försvinner efter tomgång i flera minuter beror det på samma timeout som scenariot "gray out".
Varför kommer långa Spark-jobb aldrig tillbaka?
Detta beror också på tidsgränsen för inaktivitet. Alla Spark-jobb som körs längre än de tidigare nämnda tidsgränserna kan inte återge resultatet eftersom anslutningen stängs innan jobbet returneras.
Hur undviker jag tidsgränsen?
Det finns en lösning som föreslås i funktionsbegäran: Be klienten skicka keep alive-meddelande för att förhindra TCP-timeout på vissa lastbalanserare på Github. Lösningen skickar pulsslag för att hålla WebSocket-anslutningen vid liv när appen är inaktiv. Men om appen blockeras av en tidskrävande beräkning fungerar inte den här lösningen.
Shiny stöder inte tidskrävande uppgifter. Ett shiny-blogginlägg rekommenderar att du använder löften och framtider för att köra långa uppgifter asynkront och hålla appen avblockerad. Här är ett exempel som använder pulsslag för att hålla Shiny-appen vid liv och kör ett långvarigt Spark-jobb i en
futurekonstruktion.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)Det finns en hård gräns på 12 timmar sedan den första sidinläsningen varefter alla anslutningar, även om de är aktiva, avslutas. Du måste uppdatera Shiny-appen för att återansluta i dessa fall. Den underliggande WebSocket-anslutningen kan dock när som helst stängas av en mängd olika faktorer, inklusive nätverks-instabilitet eller datorns viloläge. Databricks rekommenderar att du skriver om Shiny-appar så att de inte kräver en långvarig anslutning och inte överlitar sig på sessionstillstånd.
Min app kraschar direkt efter starten, men koden verkar vara korrekt. Vad är det som händer?
Det finns en gräns på 50 MB för den totala mängden data som kan visas i en Shiny-app i Azure Databricks. Om programmets totala datastorlek överskrider den här gränsen kraschar den omedelbart efter start. För att undvika detta rekommenderar Databricks att du minskar datastorleken, till exempel genom att koppla ned de data som visas eller minska bildupplösningen.
Hur många anslutningar kan accepteras för en Shiny-applänk under utvecklingen?
Databricks rekommenderar upp till 20.
Kan jag använda en annan version av Shiny-paketet än den som installerades i Databricks Runtime?
Ja. Se Åtgärda versionen av R-paket.
Hur kan jag utveckla ett Shiny-program som kan publiceras till en Shiny-server och få åtkomst till data i Azure Databricks?
Även om du kan komma åt data naturligt med Hjälp av SparkR eller sparklyr under utveckling och testning på Azure Databricks, kan det inte direkt komma åt data och tabeller i Azure Databricks när ett Shiny-program har publicerats till en fristående värdtjänst.
Om du vill att programmet ska fungera utanför Azure Databricks måste du skriva om hur du kommer åt data. Det finns några alternativ:
- Använd JDBC/ODBC för att skicka frågor till ett Azure Databricks-kluster.
- Använd Databricks Connect.
- Direktåtkomst till data i objektlagring.
Databricks rekommenderar att du arbetar med ditt Azure Databricks-lösningsteam för att hitta den bästa metoden för din befintliga data- och analysarkitektur.
Kan jag utveckla ett Shiny-program i en Azure Databricks-notebook-fil?
Ja, du kan utveckla ett Shiny-program i en Azure Databricks-notebook-fil.
Hur kan jag spara shiny-program som jag utvecklade på värdbaserade RStudio Server?
Du kan antingen spara programkoden på DBFS eller kontrollera koden i versionskontrollen.