Databricks Runtime för maskininlärning
Den här artikeln beskriver Databricks Runtime for Machine Learning och ger vägledning för hur du skapar ett kluster som använder det.
Vad är Databricks Runtime för Machine Learning?
Databricks Runtime for Machine Learning (Databricks Runtime ML) automatiserar skapandet av ett kluster med inbyggd maskininlärning och djupinlärningsinfrastruktur, inklusive de vanligaste ML- och DL-biblioteken.
Bibliotek som ingår i Databricks Runtime ML
Databricks Runtime ML innehåller en mängd populära ML-bibliotek. Biblioteken uppdateras med varje version så att de innehåller nya funktioner och korrigeringar.
Databricks har angett en delmängd av de bibliotek som stöds som bibliotek på den översta nivån. För dessa bibliotek ger Databricks snabbare uppdateringstakt och uppdaterar till de senaste paketversionerna med varje körningsversion (med undantag för beroendekonflikter). Databricks tillhandahåller även avancerad support, testning och inbäddade optimeringar för bibliotek på den översta nivån. Ledande bibliotek läggs till eller tas bort endast med större versioner.
- En fullständig lista över förstklassiga och andra tillhandahållna bibliotek finns i utgivningsanteckningar för Databricks Runtime ML.
- Information om hur ofta bibliotek uppdateras och när bibliotek är inaktuella finns i Databricks Runtime ML-underhållsprincip.
Du kan installera fler bibliotek för att skapa en anpassad miljö för din anteckningsbok eller kluster.
- Skapa ett klusterbibliotek för att göra ett bibliotek tillgängligt för alla notebook-filer som körs i ett kluster. Du kan också använda ett init-skript för att installera bibliotek i kluster när de skapas.
- För att installera ett bibliotek som endast är tillgängligt för en specifik notebook-session använder du Python-bibliotek avsedda för notebookar.
Konfigurera beräkningsresurser för Databricks Runtime ML
Processen för att skapa beräkning baserat på Databricks Runtime ML beror på om din arbetsyta är aktiverad för Dedikerad gruppkluster Offentlig förhandsversion eller inte. Arbetsytor som är aktiverade för förhandsversionen har ett nytt förenklat beräkningsgränssnitt.
Skapa ett kluster med Databricks Runtime ML
När du skapar ett kluster väljer du en Databricks Runtime ML-version från listrutan Databricks-körningsversion. Både CPU- och GPU-drivna ML-körtider är tillgängliga.
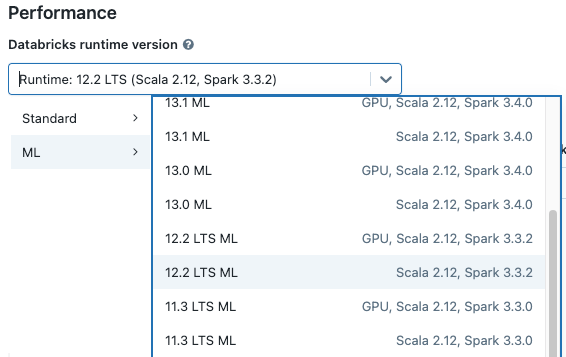
Om du väljer ett kluster från rullgardinsmenyn i anteckningsboken, visas Databricks Runtime versionen till höger om klusternamnet.
Om du väljer en GPU-aktiverad ML-körning uppmanas du att välja en kompatibel drivrutinstyp och Worker-typ. Inkompatibla instanstyper är nedtonade i den nedrullningsbara menyn. GPU-aktiverade instanstyper visas under etiketten GPU-accelererad . Information om hur du skapar Azure Databricks GPU-kluster finns i GPU-aktiverad beräkning. Databricks Runtime ML har drivrutiner för GPU-maskinvara och NVIDIA-bibliotek som CUDA.
Skapa ett nytt kluster med det nya förenklade beräkningsgränssnittet
Använd stegen i det här avsnittet endast om arbetsytan är aktiverad för förhandsversionen av dedikerade gruppkluster.
Om du vill använda maskininlärningsversionen av Databricks Runtime markerar du kryssrutan Machine learning.
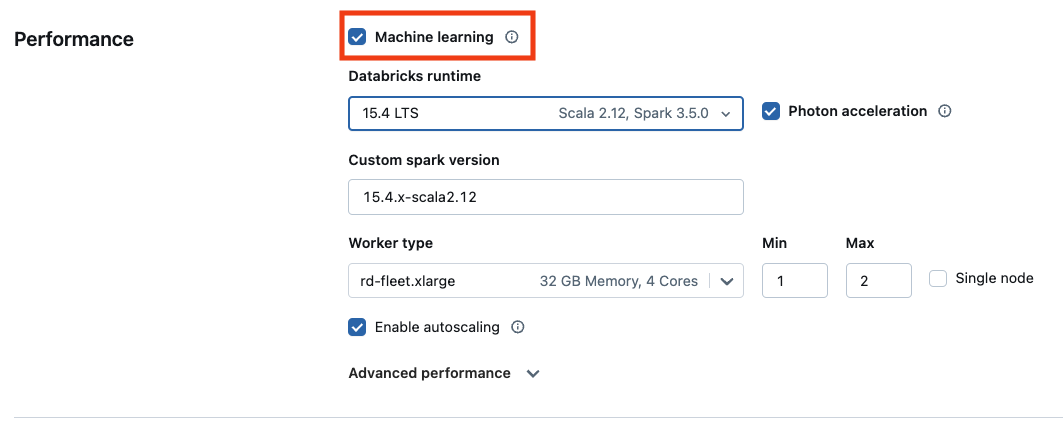
För GPU-baserad beräkning väljer du en GPU-aktiverad instanstyp. En fullständig lista över GPU-typer som stöds finns i instanstyper som stöds.
Photon och Databricks Runtime ML
När du skapar ett CPU-kluster som kör Databricks Runtime 15.2 ML eller senare kan du välja att aktivera Photon. Photon förbättrar prestanda för program som använder Spark SQL, Spark DataFrames, funktionsteknik, GraphFrames och xgboost4j. Det förväntas inte förbättra prestanda för program som använder Spark RDDs, Pandas UDF:er och icke-JVM-språk som Python. Python-paket som XGBoost, PyTorch och TensorFlow ser därför ingen förbättring med Photon.
Spark RDD-API:er och Spark MLlib har begränsad kompatibilitet med Photon. När du bearbetar stora datamängder med Spark RDD eller Spark MLlib kan det uppstå problem med Spark-minnet. Se Problem med Spark-minne.
Åtkomstläge för Databricks Runtime ML-kluster
För att få åtkomst till data i Unity Catalog i ett kluster som kör Databricks Runtime ML måste åtkomstläget vara inställt på Dedikerad (tidigare åtkomstläge för en enskild användare).
När en beräkningsresurs har dedikerad åtkomst kan resursen tilldelas till en enskild användare eller en grupp. När användaren tilldelas till en grupp (ett gruppkluster) minskar användarens behörigheter automatiskt till gruppens behörigheter, vilket gör att användaren på ett säkert sätt kan dela resursen med andra medlemmar i gruppen.
När du använder dedikerat åtkomstläge är följande funktioner endast tillgängliga på Databricks Runtime 15.4 LTS ML och senare: