Detaljerad åtkomstkontroll för dedikerad beräkning (tidigare beräkning med en enskild användare)
Den här artikeln beskriver de datafiltreringsfunktioner som möjliggör finmaskig åtkomstkontroll för frågor som körs på dedikerad beräkning (all-purpose eller jobbberäkning som konfigurerats med Dedikerat åtkomstläge). Se Åtkomstlägen.
Den här datafiltreringen utförs i bakgrunden med hjälp av serverlös beräkning.
Varför kräver vissa frågor om dedikerad beräkning datafiltrering?
Med Unity Catalog kan du styra åtkomsten till tabelldata på kolumn- och radnivå (kallas även detaljerad åtkomstkontroll) med hjälp av följande funktioner:
När användare kör frågor mot vyer som exkluderar data från refererade tabeller eller frågetabeller som tillämpar filter och masker kan de använda någon av följande beräkningsresurser utan begränsningar:
- SQL-lager
- Standardberäkning (tidigare delad beräkning)
Men om du använder dedikerad beräkning för att köra sådana frågor måste beräkning och din arbetsyta uppfylla specifika krav:
Den dedikerade beräkningsresursen måste finnas på Databricks Runtime 15.4 LTS eller senare.
Arbetsytan måste vara aktiverad för serverlös beräkning för jobb, notebook-filer och Delta Live Tables.
Information om hur du bekräftar att din arbetsyta har stöd för serverlös beräkning finns i Funktioner med begränsad regional tillgänglighet.
Om din dedikerade beräkningsresurs och arbetsyta uppfyller dessa krav körs datafiltrering automatiskt när du kör frågor mot en vy eller tabell som använder detaljerad åtkomstkontroll.
Stöd för materialiserade vyer, strömmande tabeller och standardvyer
Förutom dynamiska vyer, radfilter och kolumnmasker möjliggör datafiltrering även frågor i följande vyer och tabeller som inte stöds för dedikerad beräkning som kör Databricks Runtime 15.3 och nedan:
Vid dedikerad beräkning som kör Databricks Runtime 15.3 och senare måste användaren som kör frågan i vyn ha SELECT på tabellerna och vyerna som refereras av vyn, vilket innebär att du inte kan använda vyer för att ge detaljerad åtkomstkontroll. På Databricks Runtime 15.4 med datafiltrering behöver den användare som frågar vyn inte åtkomst till de refererade tabellerna och vyerna.
Hur fungerar datafiltrering på dedikerad beräkning?
När en fråga får åtkomst till följande databasobjekt skickar den dedikerade beräkningsresursen frågan till serverlös beräkning för att utföra datafiltrering:
- Vyer som skapats över tabeller som användaren inte har
SELECTbehörighet på - Dynamiska vyer
- Tabeller med radfilter eller kolumnmasker definierade
- Materialiserade vyer och strömmande tabeller
I följande diagram har SELECT en användare på table_1, view_2och table_w_rls, som har radfilter tillämpade. Användaren har SELECT inte på table_2, vilket refereras av view_2.

Frågan på table_1 hanteras helt av den dedikerade beräkningsresursen eftersom ingen filtrering krävs. Frågorna på view_2 och table_w_rls kräver datafiltrering för att returnera de data som användaren har åtkomst till. Dessa frågor hanteras av funktionen för datafiltrering vid serverlös beräkning.
Vilka kostnader tillkommer?
Kunder debiteras för de serverlösa beräkningsresurser som används för att utföra datafiltreringsåtgärder. Prisinformation finns i Plattformsnivåer och tillägg.
Du kan hämta information från systemets faktureringsanvändningstabell för att se hur mycket du har debiterats. Följande fråga delar till exempel upp beräkningskostnader per användare:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Visa frågeprestanda när datafiltrering används
Spark-användargränssnittet för dedikerad beräkning visar mått som du kan använda för att förstå dina frågors prestanda. För varje fråga som du kör på beräkningsresursen visar fliken SQL/Dataframe frågegrafrepresentationen. Om en fråga var involverad i datafiltrering visar användargränssnittet en RemoteSparkConnectScan-operatornod längst ned i diagrammet. Noden visar mått som du kan använda för att undersöka frågeprestanda. Se Visa beräkningsinformation i Apache Spark-användargränssnittet.
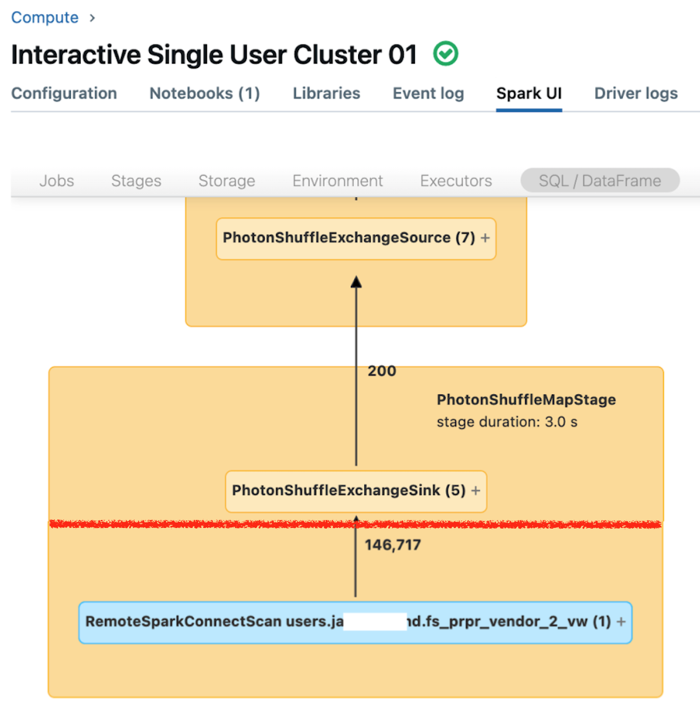
Expandera operatornoden RemoteSparkConnectScan för att se mått som hanterar sådana frågor som följande:
- Hur lång tid tog det att filtrera data? Visa "total fjärrkörningstid".
- Hur många rader kvar efter datafiltrering? Visa "rader utdata".
- Hur mycket data (i byte) returnerades efter datafiltrering? Visa "raders utdatastorlek".
- Hur många datafiler partitionerades och behövde inte läsas från lagringen? Visa "Filer som rensats" och "Storlek på filer som rensats".
- Hur många datafiler kunde inte beskäras och måste läsas från lagringen? Visa "Läs filer" och "Storlek på lästa filer".
- Hur många av filerna som måste läsas fanns redan i cacheminnet? Visa "Cache träffar storlek" och "Cache missar storlek.".
Begränsningar
Inget stöd för skriv- eller uppdateringstabellåtgärder för tabeller som har radfilter eller kolumnmasker tillämpade.
Mer specifikt stöds inte DML-åtgärder, till exempel
INSERT,DELETE,UPDATE,REFRESH TABLEochMERGE. Du kan bara läsa (SELECT) från dessa tabeller.Självkopplingar blockeras som standard när datafiltrering anropas, men du kan tillåta dem genom att ange
spark.databricks.remoteFiltering.blockSelfJoinsfalse vid beräkning som du kör dessa kommandon på.Innan du aktiverar självkopplingar på en dedikerad beräkningsresurs bör du vara medveten om att en självkopplingsfråga som hanteras av datafiltreringsfunktionen kan returnera olika ögonblicksbilder av samma fjärrtabell.
- Inget stöd för Docker-avbildningar.
- Om din arbetsyta distribuerades med en brandvägg före november 2024 måste du öppna portarna 8443 och 8444 för att aktivera detaljerad åtkomstkontroll vid dedikerad beräkning. Se Regler för nätverkssäkerhetsgrupp.