Skapa en ostrukturerad datapipeline för RAG
Den här artikeln beskriver hur du skapar en ostrukturerad datapipeline för gen AI-program. Ostrukturerade pipelines är särskilt användbara för Retrieval-Augmented Generation (RAG)-applikationer.
Lär dig hur du konverterar ostrukturerat innehåll som textfiler och PDF-filer till ett vektorindex som AI-agenter eller andra hämtningar kan köra frågor mot. Du lär dig också hur du experimenterar och finjusterar din pipeline för att optimera segmentering, indexering och parsning av data, så att du kan felsöka och experimentera med pipelinen för att uppnå bättre resultat.
Anteckningsbok för ostrukturerade dataflöden
Följande notebook-fil visar hur du implementerar informationen i den här artikeln för att skapa en ostrukturerad datapipeline.
Databricks ostrukturerad datapipeline
Viktiga komponenter i datapipelinen

Grunden för alla RAG-program med ostrukturerade data är datapipelinen. Den här pipelinen ansvarar för att kurera och förbereda ostrukturerade data i ett format som RAG-programmet kan använda effektivt. Även om den här datapipelinen kan bli komplex beroende på användningsfallet, är följande viktiga komponenter som du måste tänka på när du först skapar DITT RAG-program:
- Corpus sammansättning och inmatning: Välj rätt datakällor och innehåll baserat på det specifika användningsfallet.
-
Förbearbetning av data: Omvandla rådata till ett rent, konsekvent format som lämpar sig för inbäddning och hämtning.
- Parsning: Extrahera relevant information från rådata med lämpliga tekniker för parsning.
-
Enrichment: Berika data med ytterligare metadata och ta bort brus.
- extrahering av metadata: Extrahera användbara metadata för att implementera snabbare och effektivare datahämtning.
- Deduplicering: Analysera dokumenten för att identifiera och eliminera dubbletter eller nästan duplicerade dokument.
- Filtrering: Eliminera irrelevanta eller oönskade dokument från samlingen.
- Segmentering: Dela upp parsade data i mindre, hanterbara segment för effektiv hämtning.
- Embedding: Konvertera segmenterade textdata till en numerisk vektorrepresentation som fångar dess semantiska betydelse.
- Indexering och lagring: Skapa effektiva vektorindex för optimerad sökprestanda.
Corpus sammansättning och inmatning
DITT RAG-program kan inte hämta den information som krävs för att besvara en användarfråga utan rätt datakorus. Rätt data beror helt och hållet på programmets specifika krav och mål, vilket gör det viktigt att ägna tid åt att förstå nyanserna i tillgängliga data. Mer information finns i Generative AI-apputvecklares arbetsflöde.
När du till exempel skapar en kundsupportrobot kan du överväga att inkludera följande:
- Kunskapsbasdokument
- Vanliga frågor (FAQ)
- Produkthandböcker och specifikationer
- Felsökningsguider
Kontakta domänexperter och intressenter från början av alla projekt för att identifiera och kurera relevant innehåll som kan förbättra kvaliteten och täckningen för dina datakorus. De kan ge insikter om vilka typer av frågor som användarna sannolikt kommer att skicka och hjälpa till att prioritera den mest kritiska informationen som ska inkluderas.
Databricks rekommenderar att du matar in data på ett skalbart och inkrementellt sätt. Azure Databricks erbjuder olika metoder för datainmatning, inklusive fullständigt hanterade anslutningsappar för SaaS-program och API-integreringar. Som en bästa praxis bör rådata matas in och lagras i en måltabell. Den här metoden säkerställer databevarande, spårbarhet och granskning. Se Importera data till en Azure Databricks lakehouse.
Förbearbetning av data
När data har matats in är det viktigt att rensa och formatera rådata till ett konsekvent format som lämpar sig för inbäddning och hämtning.
Parsning
När du har identifierat lämpliga datakällor för ditt retriever-program extraherar nästa steg nödvändig information från rådata. Den här processen, som kallas parsning, innebär att de ostrukturerade data omvandlas till ett format som RAG-programmet effektivt kan använda.
De specifika parsningstekniker och verktyg som du använder beror på vilken typ av data du arbetar med. Till exempel:
- Textdokument (PDF-filer, Word-dokument): Off-the-shelf-bibliotek som ostrukturerade och PyPDF2 kan hantera olika filformat och ge alternativ för att anpassa parsningsprocessen.
- HTML-dokument: HTML-parsningsbibliotek som BeautifulSoup och lxml kan användas för att extrahera relevant innehåll från webbsidor. De här biblioteken kan hjälpa dig att navigera i HTML-strukturen, välja specifika element och extrahera önskad text eller attribut.
- Bilder och skannade dokument: OCR-tekniker (Optisk teckenigenkänning) krävs vanligtvis för att extrahera text från bilder. Populära OCR-bibliotek innehåller bibliotek med öppen källkod, till exempel Tesseract eller SaaS-versioner som Amazon Textract, Azure AI Vision OCRoch Google Cloud Vision API.
Metodtips för att parsa data
Parsning säkerställer att data är rena, strukturerade och redo för inbäddningsgenerering och vektorsökning. När du parsar dina data bör du överväga följande metodtips:
- Datarensning: Förbearbeta den extraherade texten för att ta bort irrelevant eller bullrig information, till exempel sidhuvuden, sidfötter eller specialtecken. Minska mängden onödig eller felaktig information som din RAG-kedja behöver bearbeta.
- Hantera fel och undantag: Implementera mekanismer för felhantering och loggning för att identifiera och lösa eventuella problem som uppstår under parsningsprocessen. Detta hjälper dig att snabbt identifiera och åtgärda problem. Detta pekar ofta på överordnade problem med kvaliteten på källdata.
- Anpassa parsningslogik: Beroende på dina datas struktur och format kan du behöva anpassa parsningslogik för att extrahera den mest relevanta informationen. Även om det kan kräva ytterligare arbete i förväg kan du investera tid för att göra detta om det behövs, eftersom det ofta förhindrar många problem med nedströmskvalitet.
- Utvärderar parsningskvalitet: Utvärdera regelbundet kvaliteten på de parsade data genom att manuellt granska ett urval av utdata. Detta kan hjälpa dig att identifiera eventuella problem eller förbättringsområden i parsningsprocessen.
Berikning
Berika data med ytterligare metadata och ta bort brus. Även om förädling är valfritt kan det avsevärt förbättra din ansökans övergripande prestanda.
extrahering av metadata
Om du genererar och extraherar metadata som samlar in viktig information om dokumentets innehåll, kontext och struktur kan det avsevärt förbättra rag-programmets hämtningskvalitet och prestanda. Metadata ger ytterligare signaler som förbättrar relevansen, möjliggör avancerad filtrering och stöder domänspecifika sökkrav.
Även om bibliotek som LangChain och LlamaIndex tillhandahåller inbyggda parsers som kan extrahera associerade standardmetadata automatiskt, är det ofta bra att komplettera detta med anpassade metadata som är skräddarsydda för ditt specifika användningsfall. Den här metoden säkerställer att kritisk domänspecifik information samlas in, vilket förbättrar nedströmshämtning och generering. Du kan också använda stora språkmodeller (LLM) för att automatisera metadataförbättringar.
Typer av metadata är:
- metadata på dokumentnivå: Filnamn, URL:er, redigeringsinformation, tidsstämplar för skapande och ändring, GPS-koordinater och versionshantering av dokument.
- Innehållsbaserade metadata: Extraherade nyckelord, sammanfattningar, ämnen, namngivna entiteter och domänspecifika taggar (produktnamn och kategorier som PII eller HIPAA).
- Strukturella metadata: avsnittsrubriker, innehållsförteckning, sidnummer och semantiska innehållsgränser (kapitel eller underavsnitt).
- Kontextuella metadata: Källsystem, inmatningsdatum, datakänslighetsnivå, originalspråk eller transnationella instruktioner.
Att lagra metadata tillsammans med segmenterade dokument eller motsvarande inbäddningar är viktigt för optimala prestanda. Det hjälper också till att begränsa den hämtade informationen och förbättra programmets noggrannhet och skalbarhet. Dessutom kan integrering av metadata i hybridsökningspipelines, vilket innebär att kombinera vektorlikhetssökning med nyckelordsbaserad filtrering, förbättra relevansen, särskilt i stora datamängder eller specifika sökvillkorsscenarier.
Deduplicering
Beroende på dina källor kan du få duplicerade dokument eller nära dubbletter. Om du till exempel hämtar från en eller flera delade enheter kan det finnas flera kopior av samma dokument på flera platser. Vissa av dessa kopior kan ha subtila ändringar. På samma sätt kan din kunskapsbas ha kopior av produktdokumentationen eller utkast till kopior av blogginlägg. Om dessa dubbletter finns kvar i din corpus kan du få mycket redundanta segment i ditt slutliga index som kan minska programmets prestanda.
Du kan eliminera vissa dubbletter med enbart metadata. Om ett objekt till exempel har samma rubrik och skapandedatum men flera poster från olika källor eller platser kan du filtrera dem baserat på metadata.
Detta kanske dock inte räcker. För att identifiera och eliminera dubbletter baserat på innehållet i dokumenten kan du använda en teknik som kallas lokalitetskänslig hashning. Mer specifikt fungerar en teknik som kallas MinHash bra här, och en Spark-implementering finns redan i Spark ML-. Det fungerar genom att skapa en hash för dokumentet baserat på de ord som det innehåller och kan sedan effektivt identifiera dubbletter eller nära dubbletter genom att ansluta till dessa hashar. På en mycket hög nivå är detta en process i fyra steg:
- Skapa en funktionsvektor för varje dokument. Om det behövs bör du överväga att använda tekniker som stoppa ordborttagning, härstamning och lemmatisering för att förbättra resultaten och sedan tokenisera till n-gram.
- Anpassa en MinHash-modell och använd MinHash för att hasha vektorerna för Jaccard-avstånd.
- Kör en likhetskombinering med hjälp av hashvärdena för att skapa en resultatuppsättning för varje dubblett eller ett nästan identiskt dokument.
- Filtrera bort dubbletter som du inte vill behålla.
Ett baslinjededupliceringssteg kan välja vilka dokument som ska behållas godtyckligt (till exempel det första i resultatet av varje dubblett eller ett slumpmässigt val bland dubbletterna). En potentiell förbättring skulle vara att välja den "bästa" versionen av dubbletten med hjälp av annan logik (till exempel senast uppdaterad, publiceringsstatus eller mest auktoritativ källa). Observera också att du kan behöva experimentera med funktionaliseringssteget och antalet hash-tabeller som används i MinHash-modellen för att förbättra matchande resultat.
Mer information finns i Spark-dokumentationen för locality-sensitive hashing.
filtrering
Vissa av de dokument som du matar in i din corpus kanske inte är användbara för din agent, antingen för att de är irrelevanta för dess syfte, för gamla eller otillförlitliga, eller för att de innehåller problematiskt innehåll som skadligt språk. Andra dokument kan dock innehålla känslig information som du inte vill exponera via din agent.
Överväg därför att inkludera ett steg i pipelinen för att filtrera bort dessa dokument med hjälp av metadata, till exempel att tillämpa en toxicitetsklassificerare på dokumentet för att skapa en förutsägelse som du kan använda som ett filter. Ett annat exempel skulle vara att tillämpa en algoritm för identifiering av personligt identifierbar information (PII) på dokumenten för att filtrera dokument.
Slutligen är alla dokumentkällor som du matar in i din agent potentiella attackvektorer för dåliga aktörer att starta dataförgiftningsattacker. Du kan också överväga att lägga till identifierings- och filtreringsmekanismer för att identifiera och eliminera dem.
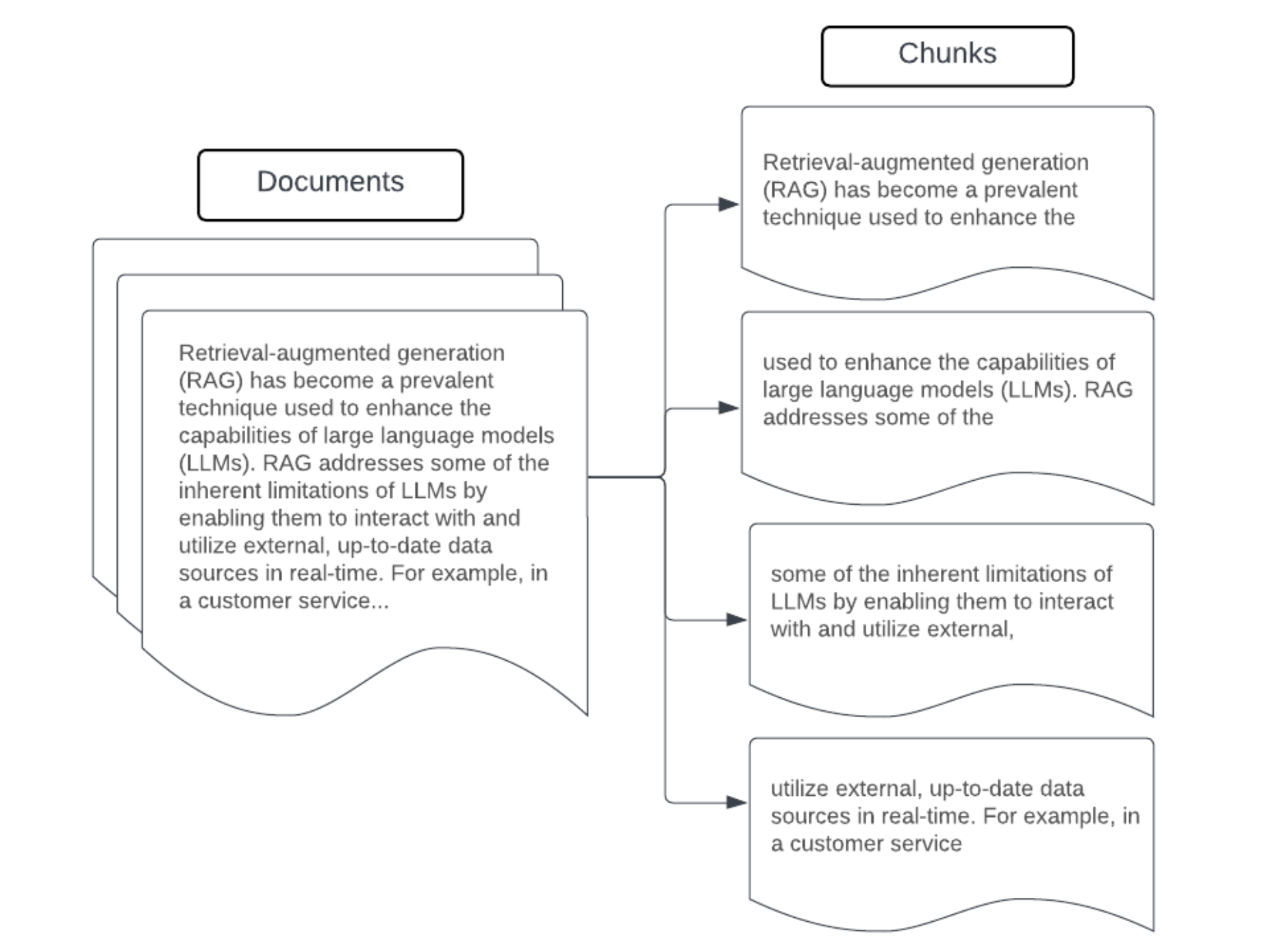
segmentering
När du har parsat rådata i ett mer strukturerat format, tagit bort dubbletter och filtrerat bort oönskad information är nästa steg att dela upp dem i mindre, hanterbara enheter som kallas segment. Genom att dela upp stora dokument i mindre, semantiskt koncentrerade segment ser du till att hämtade data passar i LLM:s kontext samtidigt som störande eller irrelevant information minimeras. De val som görs vid segmentering påverkar direkt de hämtade data som LLM tillhandahåller, vilket gör dem till ett av de första optimeringsskikten i ett RAG-program.
När du segmenterar dina data bör du tänka på följande faktorer:
- Segmenteringsstrategi: Den metod som du använder för att dela upp den ursprungliga texten i segment. Detta kan omfatta grundläggande tekniker som att dela upp efter meningar, stycken, specifika tecken/tokenantal och mer avancerade dokumentspecifika delningsstrategier.
- segmentstorlek: Mindre segment kan fokusera på specifik information men förlora viss omgivande kontextuell information. Större segment kan fånga mer kontext men kan innehålla irrelevant information eller vara beräkningsmässigt dyra.
- Överlappning mellan segment: För att säkerställa att viktig information inte går förlorad när data delas upp i segment bör du överväga att inkludera viss överlappning mellan angränsande segment. Överlappning kan säkerställa kontinuitet och kontextbevarande mellan segment och förbättra hämtningsresultaten.
- semantisk sammanhållning: När det är möjligt ska du sträva efter att skapa semantiskt sammanhängande segment som innehåller relaterad information men som kan stå oberoende av varandra som en meningsfull textenhet. Detta kan uppnås genom att överväga strukturen för de ursprungliga data, till exempel stycken, avsnitt eller ämnesgränser.
- Metadata:Relevanta metadata, till exempel källdokumentets namn, avsnittsrubrik eller produktnamn, kan förbättra hämtningen. Den här ytterligare informationen kan hjälpa dig att matcha hämtningsfrågor till segment.
Strategier för datasegmentering
Att hitta rätt segmenteringsmetod är både iterativt och kontextberoende. Det finns ingen metod som passar alla. Den optimala segmentstorleken och metoden beror på det specifika användningsfallet och typen av data som bearbetas. I stort sett kan segmenteringsstrategier ses som följande:
- Segmentering med fast storlek: Dela upp texten i segment av en förutbestämd storlek, till exempel ett fast antal tecken eller token (till exempel LangChain CharacterTextSplitter). Även om det är snabbt och enkelt att dela upp ett godtyckligt antal tecken/token, resulterar det vanligtvis inte i konsekventa semantiskt sammanhängande segment. Den här metoden fungerar sällan för program i produktionsklass.
- Styckebaserad segmentering: Använd de naturliga styckegränserna i texten för att definiera segment. Den här metoden kan hjälpa till att bevara segmentens semantiska enhetlighet, eftersom stycken ofta innehåller relaterad information (till exempel LangChain RecursiveCharacterTextSplitter).
- Formatspecifik segmentering: Format som Markdown eller HTML har en inbyggd struktur som kan definiera segmentgränser (till exempel markdown-rubriker). Verktyg som LangChains MarkdownHeaderTextSplitter eller HTML-sidhuvudavsnittsbaserade/ splitter kan användas för detta ändamål.
- semantisk segmentering: Tekniker som ämnesmodellering kan användas för att identifiera semantiskt sammanhängande avsnitt i texten. Dessa metoder analyserar innehållet eller strukturen i varje dokument för att fastställa de lämpligaste segmentgränserna baserat på ämnesförskjutningar. Även om det är mer involverat än grundläggande metoder kan semantisk segmentering hjälpa till att skapa segment som är mer anpassade till de naturliga semantiska divisionerna i texten (se LangChain SemanticChunker, till exempel).
Exempel: Segmentering i fasta storlekar
Exempel på segmentering med fast storlek med LangChains RecursiveCharacterTextSplitter med chunk_size=100 och chunk_overlap=20. ChunkViz är ett interaktivt sätt att visualisera hur olika delningsstorlekar och delningsöverlappningar med Langchains teckendelare påverkar de resulterande delarna.
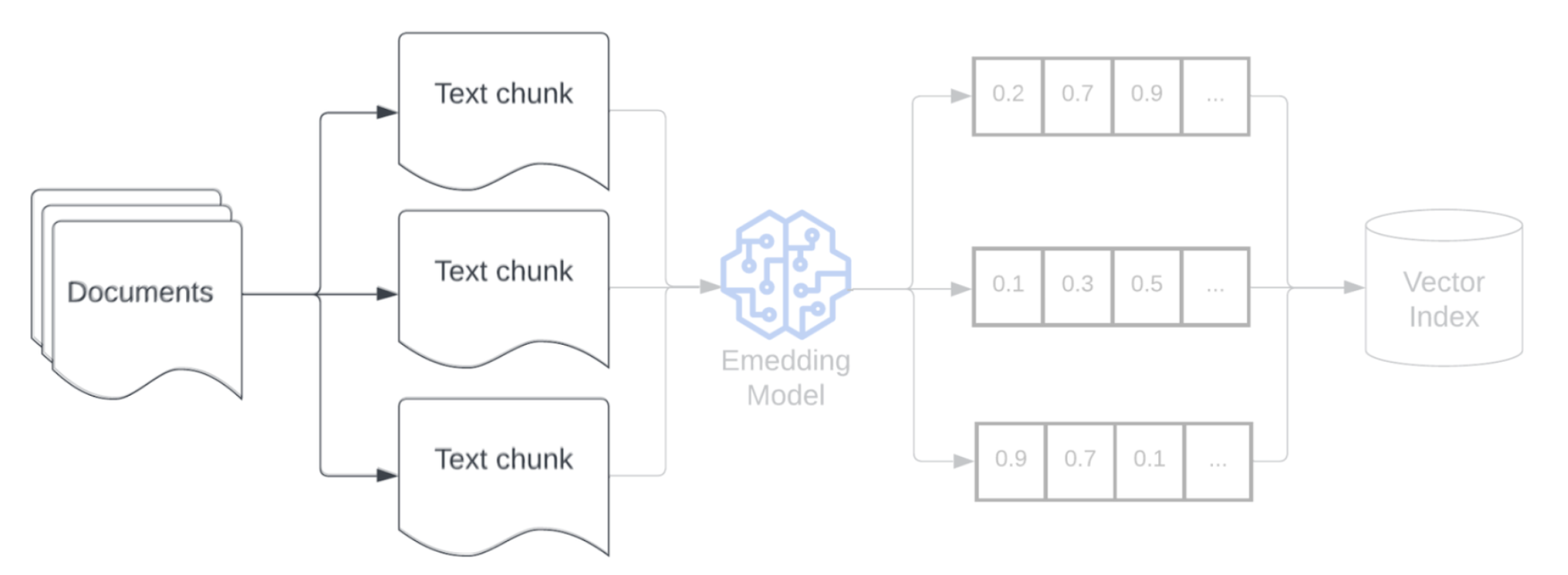
Inbäddning
När du har segmenterat dina data är nästa steg att konvertera textsegmenten till en vektorrepresentation med hjälp av en inbäddningsmodell. En inbäddningsmodell konverterar varje textsegment till en vektorrepresentation som fångar dess semantiska betydelse. Genom att representera segment som kompakta vektorer möjliggör inbäddningar snabb och korrekt hämtning av de mest relevanta segmenten baserat på deras semantiska likhet med en hämtningsfråga. Hämtningsfrågan transformeras vid frågetillfället med samma inbäddningsmodell som används för att bädda in segment i datapipelinen.
När du väljer en inbäddningsmodell bör du tänka på följande faktorer:
- Modellval: Varje inbäddningsmodell har nyanser, och de tillgängliga riktmärkena kanske inte samlar in de specifika egenskaperna för dina data. Det är viktigt att välja en modell som har tränats på liknande data. Det kan också vara bra att utforska alla tillgängliga inbäddningsmodeller som är utformade för specifika uppgifter. Prova olika färdiga inbäddningsmodeller, även de som är lägre rankade för vanliga resultatlistor som MTEB. Några exempel att tänka på:
- Max-token: Vet den maximala tokengränsen för din valda inbäddningsmodell. Om du skickar segment som överskrider den här gränsen trunkeras de, vilket kan leda till att viktig information går förlorad. Till exempel har bge-large-en-v1.5 en maximal tokengräns på 512.
- Modellstorlek: Större inbäddningsmodeller fungerar vanligtvis bättre men kräver mer beräkningsresurser. Baserat på ditt specifika användningsfall och tillgängliga resurser måste du balansera prestanda och effektivitet.
- Finjustering: Om DITT RAG-program hanterar domänspecifikt språk (till exempel interna företagsakronymer eller terminologi) bör du överväga att finjustera inbäddningsmodellen på domänspecifika data. Detta kan hjälpa modellen att bättre fånga nyanser och terminologi för din specifika domän och kan ofta leda till bättre hämtningsprestanda.
indexering och lagring
Nästa steg i pipelinen är att skapa index för inbäddningarna och metadata som genererades i föregående steg. I det här steget ingår att organisera högdimensionella vektorbäddningar i effektiva datastrukturer som möjliggör snabba och korrekta likhetssökningar.
Mosaic AI Vector Search använder de senaste indexeringsteknikerna när du distribuerar en slutpunkt för vektorsökning och index för att säkerställa snabba och effektiva sökningar för dina vektorsökningsfrågor. Du behöver inte bekymra dig om att testa och välja de bästa indexeringsteknikerna.
När indexet har skapats och distribuerats är det redo att lagras i ett system som stöder skalbara frågor med låg svarstid. För rag-pipelines för produktion med stora datamängder använder du en vektordatabas eller en skalbar söktjänst för att säkerställa låg svarstid och högt dataflöde. Lagra ytterligare metadata tillsammans med inbäddningar för att möjliggöra effektiv filtrering under hämtningen.