Steg 1. Klona kodlagringsplatsen och skapa beräkning
Se GitHub-lagringsplatsen för exempelkoden i det här avsnittet. Du kan också använda lagringsplatskoden som en mall för att skapa dina egna AI-program.
Följ de här stegen för att läsa in exempelkoden till din Databricks-arbetsyta och konfigurera de globala inställningarna för programmet.
Krav
- En Azure Databricks-arbetsyta med serverlös beräkning och Unity Catalog aktiverad.
- En befintlig slutpunkt för Mosaic AI Vector Search eller behörigheter för att skapa en ny slutpunkt för vektorsökning (installationsanteckningsboken skapar en åt dig i det här fallet).
- Skrivåtkomst till ett befintligt Unity Catalog-schema där Delta-utdatatabellerna som innehåller de tolkade och segmenterade dokumenten och Vector Search-index lagras, eller behörigheter för att skapa en ny katalog och ett nytt schema (installationsanteckningsboken skapar en åt dig i det här fallet).
- Ett kluster med en användare som kör DBR 14.3 eller senare och som har åtkomst till Internet. Internetåtkomst krävs för att ladda ned nödvändiga Python- och systempaket. Använd inte ett kluster som kör Databricks Runtime för Machine Learning eftersom python-paket står i konflikt med Databricks Runtime ML.
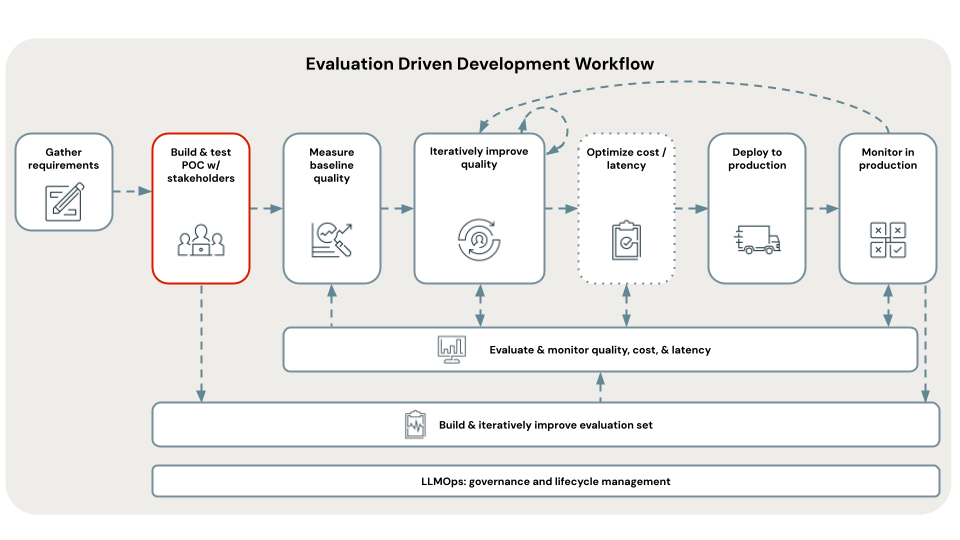
Flödesdiagram för självstudie
Diagrammet visar flödet av steg som används i den här självstudien.
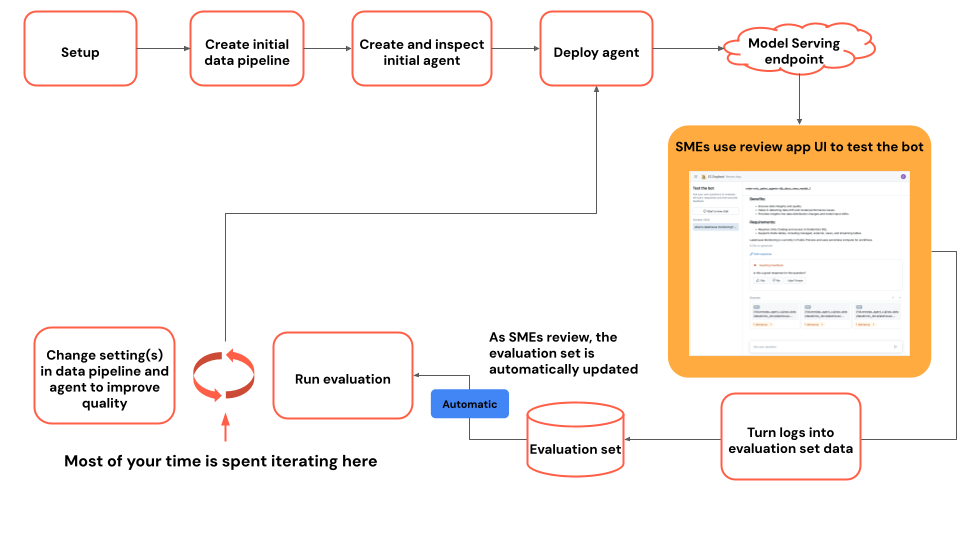
Instruktioner
Klona den här lagringsplatsen till din arbetsyta med hjälp av Git-mappar.
Öppna anteckningsboken rag_app_sample_code/00_global_config och justera inställningarna där.
# The name of the RAG application. This is used to name the chain's model in Unity Catalog and prepended to the output Delta tables and vector indexes RAG_APP_NAME = 'my_agent_app' # Unity Catalog catalog and schema where outputs tables and indexes are saved # If this catalog/schema does not exist, you need create catalog/schema permissions. UC_CATALOG = f'{user_name}_catalog' UC_SCHEMA = f'rag_{user_name}' ## Name of model in Unity Catalog where the POC chain is logged UC_MODEL_NAME = f"{UC_CATALOG}.{UC_SCHEMA}.{RAG_APP_NAME}" # Vector Search endpoint where index is loaded # If this does not exist, it will be created VECTOR_SEARCH_ENDPOINT = f'{user_name}_vector_search' # Source location for documents # You need to create this location and add files SOURCE_PATH = f"/Volumes/{UC_CATALOG}/{UC_SCHEMA}/source_docs"Öppna och kör den 01_validate_config_and_create_resources notebook-filen.
Gå vidare
Fortsätt med Distribuera POC.