Krav: Samla in krav
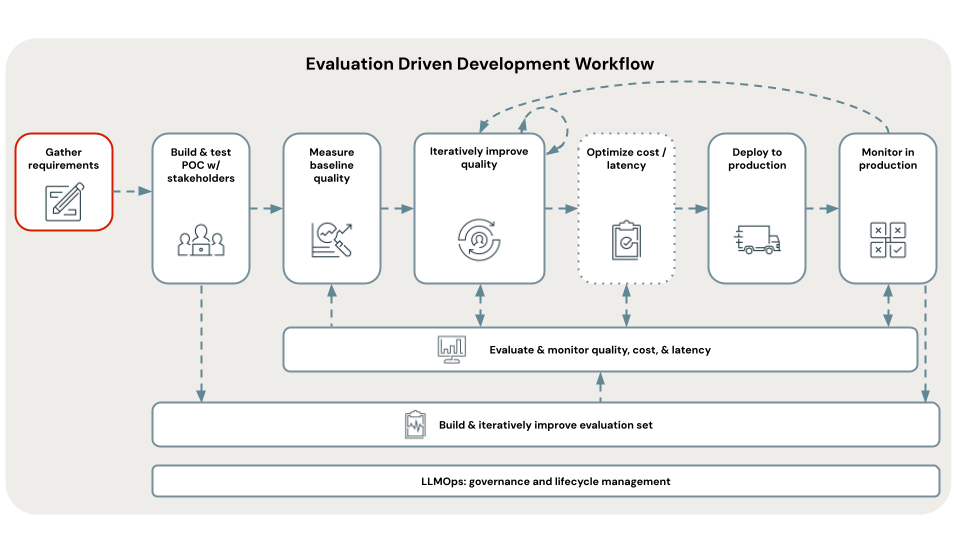
Att definiera tydliga och omfattande krav för användningsfall är ett viktigt första steg för att utveckla ett lyckat RAG-program. Dessa krav har två huvudsakliga syften. För det första hjälper de till att avgöra om RAG är den lämpligaste metoden för det angivna användningsfallet. Om RAG verkligen passar bra vägleder dessa krav lösningsdesign, implementering och utvärderingsbeslut. Investeringstid i början av ett projekt för att samla in detaljerade krav kan förhindra betydande utmaningar och bakslag senare i utvecklingsprocessen och säkerställa att den resulterande lösningen uppfyller slutanvändarnas och intressenternas behov. Väldefinierade krav utgör grunden för de efterföljande stegen i utvecklingslivscykeln som vi går igenom.
Se GitHub-lagringsplatsen för exempelkoden i det här avsnittet. Du kan också använda lagringsplatskoden som en mall för att skapa dina egna AI-program.
Passar användningsfallet bra för RAG?
Det första du behöver fastställa är om RAG ens är rätt metod för ditt användningsfall. Med tanke på hypen kring RAG är det frestande att se det som en möjlig lösning på alla problem. Det finns dock nyanser om när RAG är lämpligt kontra inte.
RAG passar bra när:
- Resonemang över hämtad information (både ostrukturerad och strukturerad) som inte helt passar in i LLM:s kontextfönster
- Syntetisera information från flera källor (till exempel generera en sammanfattning av viktiga punkter från olika artiklar i ett ämne)
- Dynamisk hämtning baserat på en användarfråga är nödvändig (till exempel med en användarfråga kan du avgöra vilken datakälla som ska hämtas från)
- Användningsfallet kräver att nytt innehåll genereras baserat på hämtad information (till exempel besvara frågor, ge förklaringar och ge rekommendationer)
RAG kanske inte passar bäst när:
- Uppgiften kräver inte frågespecifik hämtning. Till exempel generera sammanfattningar av samtalsavskrift; även om enskilda avskrifter tillhandahålls som kontext i LLM-prompten förblir den hämtade informationen densamma för varje sammanfattning.
- Hela uppsättningen med information som ska hämtas får plats i LLM:s kontextfönster
- Extremt svar med låg svarstid krävs (till exempel när svar krävs i millisekunder)
- Enkla regelbaserade eller mallbaserade svar räcker (till exempel en chattrobot för kundsupport som ger fördefinierade svar baserat på nyckelord)
Krav för att identifiera
När du har fastställt att RAG passar bra för ditt användningsfall bör du överväga följande frågor för att samla in konkreta krav. Kraven prioriteras enligt följande:
🟢 P0: Måste definiera det här kravet innan du startar din POC.
🟡 P1: Måste definiera innan du går till produktion, men kan iterativt förfina under POC.
⚪ P2: Nice att ha krav.
Detta är inte en fullständig lista över frågor. Det bör dock ge en solid grund för att samla in de viktigaste kraven för din RAG-lösning.
Användarupplevelse
Definiera hur användarna ska interagera med RAG-systemet och vilken typ av svar som förväntas
🟢 [P0] Hur ser en typisk begäran till RAG-kedjan ut? Be intressenterna om exempel på potentiella användarfrågor.
🟢 [P0] Vilken typ av svar förväntar sig användarna (korta svar, förklaringar med långa formulär, en kombination eller något annat)?
🟡 [P1] Hur interagerar användarna med systemet? Via ett chattgränssnitt, ett sökfält eller någon annan modalitet?
🟡 [P1] hatt ton eller stil bör genereras svar ta? (formellt, konversationstekniska, tekniska?)
🟡 [P1] Hur ska programmet hantera tvetydiga, ofullständiga eller irrelevanta frågor? Bör någon form av feedback eller vägledning ges i sådana fall?
⚪ [P2] Finns det specifika formaterings- eller presentationskrav för de genererade utdata? Ska utdata inkludera metadata utöver kedjans svar?
Data
Fastställ typen, källan och kvaliteten på de data som ska användas i RAG-lösningen.
🟢 [P0] Vilka är de tillgängliga källorna att använda?
För varje datakälla:
- 🟢 [P0] Är data strukturerade eller ostrukturerade?
- 🟢 [P0] Vad är källformatet för hämtningsdata (t.ex. PDF-filer, dokumentation med bilder/tabeller, strukturerade API-svar)?
- 🟢 [P0] Var finns dessa data?
- 🟢 [P0] Hur mycket data är tillgängligt?
- 🟡 [P1] Hur ofta uppdateras data? Hur ska dessa uppdateringar hanteras?
- 🟡 [P1] Finns det några kända datakvalitetsproblem eller inkonsekvenser för varje datakälla?
Överväg att skapa en inventeringstabell för att konsolidera den här informationen, till exempel:
| Data source | Källa | Filtyper | Storlek | Uppdateringsfrekvens |
|---|---|---|---|---|
| Datakälla 1 | Unity Catalog-volymen | JSON | 10 GB | Varje dag |
| Datakälla 2 | Offentligt API | XML | NA (API) | Realtid |
| Datakälla 3 | SharePoint | PDF, .docx | 500 MB | Månadsvis |
Prestandabegränsningar
Samla in prestanda- och resurskrav för RAG-programmet.
🟡 [P1] Vilken är den maximala godtagbara svarstiden för att generera svaren?
🟡 [P1] Vilken är den maximala godkända tiden för den första token?
🟡 [P1] Är högre total svarstid acceptabel om utdata strömmas?
🟡 [P1] Finns det några kostnadsbegränsningar för beräkningsresurser som är tillgängliga för slutsatsdragning?
🟡 [P1] Vilka är de förväntade användningsmönstren och den högsta belastningen?
🟡 [P1] Hur många samtidiga användare eller begäranden ska systemet kunna hantera? Databricks hanterar inbyggt sådana skalbarhetskrav genom möjligheten att skala automatiskt med modellservering.
Utvärdering
Fastställa hur RAG-lösningen ska utvärderas och förbättras över tid.
🟢 [P0] Vilket affärsmål/KPI vill du påverka? Vad är baslinjevärdet och vad är målet?
🟢 [P0] Vilka användare eller intressenter kommer att ge inledande och löpande feedback?
🟢 [P0] Vilka mått ska användas för att utvärdera kvaliteten på genererade svar? Mosaic AI Agent Evaluation innehåller en rekommenderad uppsättning mått att använda.
🟡 [P1] Vilka frågor måste RAG-appen vara bra på för att gå till produktion?
🟡 [P1] Finns det ett [utvärderingsset]? Är det möjligt att få en utvärderingsuppsättning med användarfrågor, tillsammans med grundsanningssvar och (valfritt) rätt stöddokument som ska hämtas?
🟡 [P1] Hur kommer användarfeedback att samlas in och införlivas i systemet?
Säkerhet
Identifiera eventuella säkerhets- och sekretessöverväganden.
🟢 [P0] Finns det känsliga/konfidentiella data som måste hanteras med försiktighet?
🟡 [P1] Måste åtkomstkontroller implementeras i lösningen (till exempel kan en viss användare bara hämta från en begränsad uppsättning dokument)?
Distribution
Förstå hur RAG-lösningen kommer att integreras, distribueras och underhållas.
🟡 Hur ska RAG-lösningen integreras med befintliga system och arbetsflöden?
🟡 Hur ska modellen distribueras, skalas och versionshanteras? Den här handledningen beskriver hur hela livscykeln kan hanteras på Databricks med hjälp av MLflow, Unity Catalog, Agent SDK och Modelltjänster.
Exempel
Tänk till exempel på hur dessa frågor gäller för det här exempelprogrammet för RAG som används av ett Kundsupportteam för Databricks:
| Ytdiagram | Att tänka på | Krav |
|---|---|---|
| Användarupplevelse | – Interaktionsmodalitet. – Vanliga exempel på användarfrågor. – Förväntat svarsformat och format. – Hantera tvetydiga eller irrelevanta frågor. |
– Chattgränssnitt integrerat med Slack. – Exempelfrågor: "Hur gör jag för att minska starttiden för kluster?" "Vilken typ av supportplan har jag?" – Tydliga, tekniska svar med kodfragment och länkar till relevant dokumentation där det är lämpligt. – Ge sammanhangsberoende förslag och eskalera till supporttekniker när det behövs. |
| Data | – Antal och typ av datakällor. – Dataformat och plats. – Datastorlek och uppdateringsfrekvens. – Datakvalitet och konsekvens. |
– Tre datakällor. – Företagsdokumentation (HTML, PDF). – Lösta supportärenden (JSON). - Inlägg i gemenskapsforumet (Deltatabell). – Data som lagras i Unity Catalog och uppdateras varje vecka. – Total datastorlek: 5 GB. – Konsekvent datastruktur och kvalitet som underhålls av dedikerade dokument och supportteam. |
| Prestanda | - Maximal acceptabel svarstid. – Kostnadsbegränsningar. – Förväntad användning och samtidighet. |
– Krav på maximal svarstid. – Kostnadsbegränsningar. – Förväntad högsta belastning. |
| Utvärdering | – Tillgänglighet för utvärderingsdatauppsättning. – Kvalitetsmått. – Insamling av användarfeedback. |
- Ämnesexperter från varje produktområde hjälper till att granska utdata och justera felaktiga svar för att skapa utvärderingsdatauppsättningen. - KPI:er för företag. – Ökning av supportbegärandeupplösningsfrekvensen. – Minska användartiden per supportbegäran. – Kvalitetsmått. - LLM-bedömd svar korrekthet och relevans. - LLM bedömer hämtningsprecision. – Användarinvändaruppröstning eller nedröstning. – Feedbackinsamling. - Slack kommer att instrumenteras för att ge tummen upp / ner. |
| Säkerhet | – Hantering av känsliga data. – Åtkomstkontrollkrav. |
– Inga känsliga kunddata ska finnas i hämtningskällan. – Användarautentisering via Databricks Community SSO. |
| Distribution | – Integrering med befintliga system. – Distribution och versionshantering. |
– Integrering med supportärendesystem. – Kedja distribuerad som en Databricks Model Serving-slutpunkt. |
Gå vidare
Kom igång med steg 1. Klona kodlagringsplatsen och skapa beräkning.