Slutsatsdragning tables för övervakning och felsökning av modeller
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Viktigt!
Den här artikeln beskriver ämnen som gäller för slutsatsdragning tables för anpassade modeller. För externa modeller eller etablerade dataflödesarbetsbelastningar använder du AI Gateway-aktiverad slutsatsdragning tables.
I den här artikeln beskrivs slutsatsdragning tables för övervakning av hanterade modeller. Följande diagram visar ett typiskt arbetsflöde med slutsatsdragning tables. Slutsatsdragningen table registrerar automatiskt inkommande begäranden och utgående svar för en modell som betjänar slutpunkten och loggar dem som en Unity-Catalog Delta-table. Du kan använda data i den här table för att övervaka, felsöka och förbättra ML-modeller.
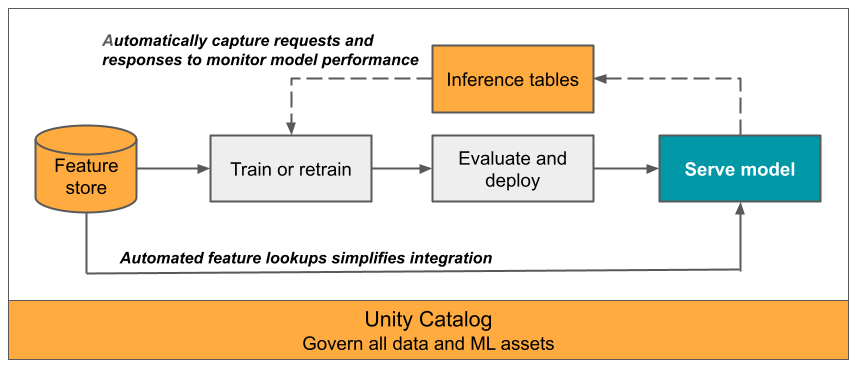
Vad är slutsatsdragning tables?
Övervakning av prestanda för modeller i produktionsarbetsflöden är en viktig aspekt av livscykeln för AI- och ML-modellen. Slutsatsdragning tables förenklar övervakning och diagnostik för modeller genom att kontinuerligt logga indata och svar från begäranden (förutsägelser) från Mosaic AI Model Serving-slutpunkter och spara dem i en Delta-table i Unity Catalog. Du kan sedan använda alla funktioner i Databricks-plattformen, till exempel Databricks SQL-frågor, notebooks och Lakehouse Monitoring för att övervaka, optimize och felsöka dina modeller.
Du kan aktivera slutsatsdragning tables på en befintlig eller nyskapad modell som betjänar slutpunkten, och begäranden till slutpunkten loggas sedan automatiskt till en table i UC.
Några vanliga program för slutsatsdragning tables är följande:
- Övervaka data och modellkvalitet. Du kan kontinuerligt övervaka modellens prestanda och dataavvikelse med hjälp av Lakehouse Monitoring. Lakehouse Monitoring genererar automatiskt instrumentpaneler för data- och modellkvalitet som du kan dela med intressenter. Dessutom kan du aktivera aviseringar för att veta när du behöver träna om din modell baserat på förändringar i inkommande data eller minskningar av modellprestanda.
- Felsöka produktionsproblem. Härledning Tables loggdata som HTTP-statuskoder, modellens exekveringstider och JSON-kod för begäran och svar. Du kan använda dessa prestandadata i felsökningssyfte. Du kan också använda historiska data i Slutsatsdragning Tables för att jämföra modellprestanda på historiska begäranden.
- Skapa en träningskorus. Genom att kombinera Inference Tables med marknadens sanningsetiketter kan du skapa en träningskorpus som du kan använda för att återträna eller finjustera och förbättra din modell. Med Databricks-jobb kan du set upp en kontinuerlig feedbackloop och automatisera omträningen.
Krav
- Din arbetsyta måste ha Unity Catalog aktiverat.
- Både skaparen av slutpunkten och modifieraren måste ha behörigheten Kan hantera på slutpunkten. Se Åtkomstkontrollistor.
- Både skaparen av slutpunkten och modifieraren måste ha följande behörigheter i Unity Catalog:
-
USE CATALOGbehörigheter för den angivna catalog. -
USE SCHEMAbehörigheter för den angivna schema. -
CREATE TABLEbehörigheter i schema.
-
Aktivera och inaktivera slutsatsdragning tables
Det här avsnittet visar hur du aktiverar eller inaktiverar slutsatsdragning tables med hjälp av Databricks-användargränssnittet. Du kan också använda API:et. Se Aktivera slutsatsdragning tables på modell som betjänar slutpunkter med hjälp av API- för instruktioner.
Ägaren till slutsatsdragningen tables är den användare som skapade slutpunkten. Alla åtkomstkontrollistor (ACL:er) på table följer Unity-standardbehörigheterna för Catalog och kan ändras av ägaren av table.
Varning
Slutsatsdragningen table kan skadas om du gör något av följande:
- Ändra tableschema.
- Ändra namnet på table.
- Ta bort table.
- Förlora dina behörigheter till Unity-Catalog,catalog eller schema.
I det här fallet visar ändpunktens status auto_capture_config ett tillstånd FAILED för nyttolasten table. Om detta händer måste du skapa en ny slutpunkt för att fortsätta använda slutsatsdragning tables.
Använd följande steg för att aktivera slutsatsdragning tables när slutpunkten skapas:
Klicka på Servering i Databricks Mosaic AI-användargränssnittet.
Klicka på Skapa serverdelsslutpunkt.
Select Aktivera slutsatsdragning tables.
I de nedrullningsbara menyerna select önskad catalog och schemawhere du vill att table ska finnas.
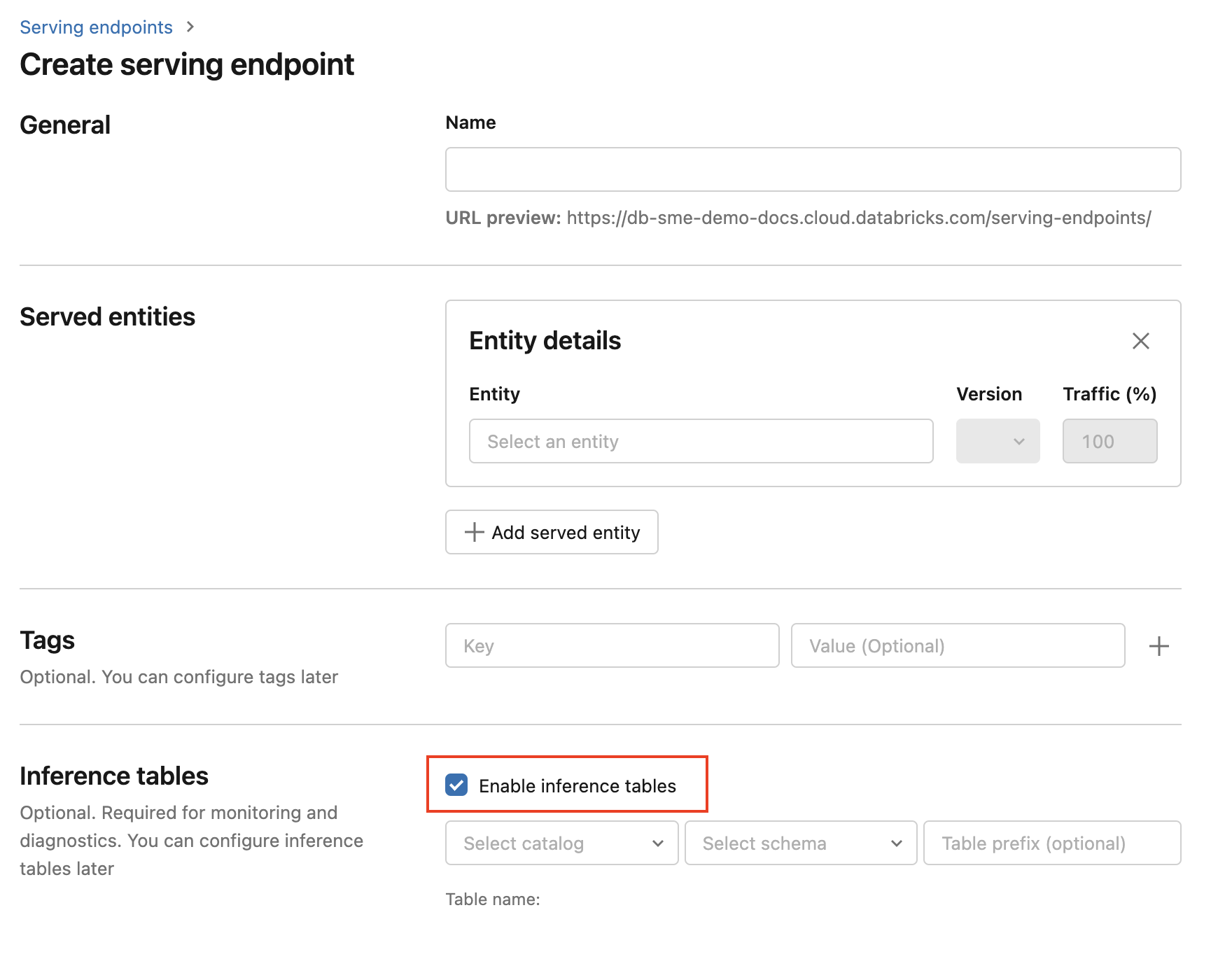
Standardnamnet för table är
<catalog>.<schema>.<endpoint-name>_payload. Om du vill kan du ange ett anpassat table prefix.Klicka på Skapa serverdelsslutpunkt.
Du kan också aktivera slutsatsdragning tables på en befintlig slutpunkt. Så här redigerar du en befintlig slutpunktskonfiguration:
- Gå till slutpunktssidan.
- Klicka på Redigera konfiguration.
- Följ de föregående anvisningarna och börja med steg 3.
- Klicka på Update tjänsteslutpunktnär du är klar.
Följ de här anvisningarna för att inaktivera slutsatsdragning tables:
- Gå till slutpunktssidan.
- Klicka på Redigera konfiguration.
- Klicka på Aktivera slutsatsdragning table för att remove bockmarkeringen.
- När du är nöjd med slutpunktsspecifikationerna klickar du på Update.
Arbetsflöde: Övervaka modellprestanda med hjälp av slutsatsdragning tables
Följ dessa steg för att övervaka modellprestanda med hjälp av slutsatsdragning tables:
- Aktivera inferens tables på din slutpunkt, antingen vid skapande av slutpunkt eller vid senare uppdatering.
- Schemalägg ett arbetsflöde för att bearbeta JSON-nyttolaster i slutsatsdragningen table genom att packa upp dem enligt slutpunktens schema.
- (Valfritt) Join uppackade begäranden och svar med verkliga etiketter så att mått på modellkvalitet kan beräknas.
- Skapa en övervakning av de resulterande måtten för Delta-table och refresh.
Startanteckningsböckerna implementerar det här arbetsflödet.
Startanteckningsbok för övervakning av en slutsatsdragning table
Följande notebook-fil implementerar stegen ovan för att avkoda förfrågningar från Lakehouse Monitoring inlärning table. Notebook-filen kan köras på begäran eller enligt ett återkommande schema med Databricks-jobb.
Slutsatsdragning table Startanteckningsbok för Lakehouse Monitoring
Startanteckningsbok för övervakning av textkvalitet från slutpunkter som betjänar LLM:er
Följande notebook packar upp begäranden från en slutsats table, beräknar en set av mått för textutvärdering (till exempel läsbarhet och toxicitet) och aktiverar övervakning över dessa mått. Notebook-filen kan köras på begäran eller enligt ett återkommande schema med Databricks-jobb.
LLM-slutledning table Lakehouse Monitoring startanteckningsbok
Fråga efter och analysera resultat i slutsatsdragningen table
När dina betjänade modeller är klara loggas alla begäranden som görs till dina modeller automatiskt till slutsatsdragningen table, tillsammans med svaren. Du kan visa table i användargränssnittet, fråga table från DBSQL eller en notebook-fil eller fråga table med hjälp av REST-API:et.
Om du vill visa table i användargränssnittet: På slutpunktssidan klickar du på namnet på slutsatsdragningen table för att öppna table i Catalog Explorer.

Om du vill köra frågor mot table från DBSQL eller en Databricks-notebook-fil: Du kan köra kod som liknar följande för att fråga slutsatsdragningen table.
SELECT * FROM <catalog>.<schema>.<payload_table>
Om du har aktiverat slutsatsdragning tables med hjälp av användargränssnittet är payload_table det table namn som du tilldelade när du skapade slutpunkten. Om du har aktiverat slutsatsdragning tables med hjälp av API:et rapporteras payload_table i avsnittet state i auto_capture_config-svaret. Ett exempel finns i Enable inference tables on model serving endpoints using the API.
Prestandaanteckning
När du har anropat slutpunkten kan du se att anropet loggas till din slutsatsdragning table inom en timme efter att du har skickat en bedömningsbegäran. Dessutom garanterar Azure Databricks att loggleveransen sker minst en gång, så det är möjligt, även om det är osannolikt, att dubblettloggar skickas.
Unity Catalog slutsatsdragning tableschema
Varje begäran och svar som loggas till en slutsats table skrivs till en Delta-table med följande schema:
Kommentar
Om du anropar slutpunkten med en batch med indata loggas hela batchen som en rad.
| Column namn | beskrivning | Typ |
|---|---|---|
databricks_request_id |
En Azure Databricks-genererad begäran identifier kopplad till alla modelltjänstbegäranden. | STRÄNG |
client_request_id |
En valfri klientgenererad begäran identifier som kan anges i den modell som betjänar begärandetexten. Mer information finns i Ange client_request_id . |
STRÄNG |
date |
UTC-datumet då modellserverns begäran togs emot. | DATUM |
timestamp_ms |
Tidsstämpeln i epok millisekunder på när modellen som betjänar begäran togs emot. | LÅNG |
status_code |
HTTP-statuskoden som returnerades från modellen. | INT |
sampling_fraction |
Samplingsfraktionen som användes i händelse av att begäran var nedsamplad. Det här värdet är mellan 0 och 1, where 1 representerar att 100% inkommande begäranden inkluderades. | DOUBLE |
execution_time_ms |
Körningstiden i millisekunder som modellen utförde slutsatsdragning för. Detta inkluderar inte överliggande nätverksfördröjningar och representerar bara den tid det tog för modellen att generate förutsägelser. | LÅNG |
request |
JSON-brödtexten för den råa begäran som skickades till den modell som betjänar slutpunkten. | STRÄNG |
response |
JSON-brödtexten för råsvaret som returnerades av modellen som betjänar slutpunkten. | STRÄNG |
request_metadata |
En karta över metadata som är relaterade till den modell som betjänar slutpunkten som är associerad med begäran. Den här kartan innehåller slutpunktsnamnet, modellnamnet och modellversionen som används för slutpunkten. | KARTSTRÄNG<, STRÄNG> |
Specificera client_request_id
Fältet client_request_id är ett valfritt värde som användaren kan ange i den modell som betjänar begärandetexten. Detta gör att användaren kan ange sina egna identifier för en begäran som visas i den slutliga slutsatsen table under client_request_id och kan användas för att koppla ihop användarens begäran med andra tables som använder client_request_id, som anslutning av grundsanningsetikett. Om du vill ange en client_request_idtar du med den som en nyckel på den översta nivån i nyttolasten för begäran. Om inget client_request_id anges visas värdet som null på raden som motsvarar begäran.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
client_request_id kan senare användas för att utföra kopplingar baserade på referensetiketter, förutsatt att det finns andra tables som har etiketter associerade med client_request_id.
Begränsningar
- Kundhanterade nycklar stöds inte.
- För slutpunkter som är värdar för grundmodellerstöds slutsatsdragning tables endast på etablerat dataflöde arbetsbelastningar.
- Azure Firewall kan leda till att det inte går att skapa Unity Catalog Delta-table, så stöds inte som standard. Kontakta ditt Databricks-kontoteam för att aktivera det.
- När slutsatsdragning tables aktiveras är limit för den totala maximala samtidigheten för alla betjänade modeller i en enda slutpunkt 128. Kontakta ditt Azure Databricks-kontoteam för att begära en ökning av detta limit.
- Om en slutsatsdragning table innehåller mer än 500 000 filer loggas inga ytterligare data. Om du vill undvika att överskrida den här limitkör du OPTIMIZE eller set upp kvarhållningen på table genom att ta bort äldre data. Om du vill kontrollera antalet filer i tablekör du
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>. - Loggleverans för slutsatsdragning tables görs just nu på bästa möjliga sätt, men du kan förvänta dig att loggarna är tillgängliga inom 1 timme efter en begäran. Kontakta ditt Databricks-kontoteam för mer information.
Allmänna begränsningar för modell som betjänar slutpunkter finns i Begränsningar och regioner för modellservering.