Serverlös beräkning för notebook-filer
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion. Information om berättigande och aktivering finns i Aktivera serverlös beräkning.
Den här artikeln beskriver hur du använder serverlös beräkning för notebook-filer. Information om hur du använder serverlös beräkning för arbetsflöden finns i Köra ditt Azure Databricks-jobb med serverlös beräkning för arbetsflöden.
Prisinformation finns i Databricks-priser.
Krav
Arbetsytan måste vara aktiverad för Unity Catalog.
Din arbetsyta måste finnas i en region som stöds. Se Azure Databricks-regioner.
Ditt konto måste vara aktiverat för serverlös beräkning. Se Aktivera serverlös beräkning.
Koppla en notebook-fil till serverlös beräkning
Om din arbetsyta är aktiverad för serverlös interaktiv beräkning har alla användare på arbetsytan åtkomst till serverlös beräkning för notebook-filer. Inga ytterligare behörigheter krävs.
Om du vill ansluta till den serverlösa beräkningen klickar du på den nedrullningsbara menyn Anslut i anteckningsboken och väljer Serverlös. För nya notebook-filer är den anslutna beräkningen automatiskt serverlös vid kodkörning om ingen annan resurs har valts.
Installera notebook-beroenden
Du kan installera Python-beroenden för serverlösa notebook-filer med hjälp av panelen På miljösidan , som ger en enda plats där du kan redigera, visa och exportera bibliotekskraven för en notebook-fil. Dessa beroenden kan läggas till med hjälp av en basmiljö eller individuellt.
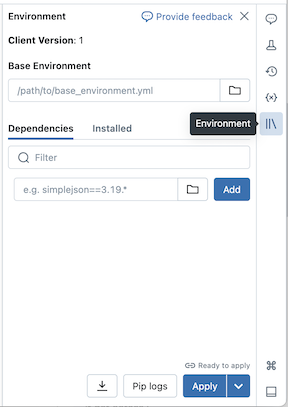
Konfigurera en basmiljö
En basmiljö är en YAML-fil som lagras som en arbetsytefil eller på en Unity Catalog-volym som anger ytterligare miljöberoenden. Basmiljöer kan delas mellan notebook-filer. Så här konfigurerar du en basmiljö:
Skapa en YAML-fil som definierar inställningar för en virtuell Python-miljö. I följande exempel definierar YAML, som baseras på miljöspecifikationen för MLflow-projekt, en basmiljö med några biblioteksberoenden:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - cowsay==6.1Ladda upp YAML-filen som en arbetsytefil eller till en Unity Catalog-volym. Se Importera en fil eller Ladda upp filer till en Unity Catalog-volym.
Till höger om anteckningsboken
 klickar du på knappen för att expandera panelen Miljö . Den här knappen visas bara när en notebook-fil är ansluten till serverlös beräkning.
klickar du på knappen för att expandera panelen Miljö . Den här knappen visas bara när en notebook-fil är ansluten till serverlös beräkning.I fältet Basmiljö anger du sökvägen till den uppladdade YAML-filen eller navigerar till den och väljer den.
Klicka på Använd. Detta installerar beroendena i den virtuella notebook-miljön och startar om Python-processen.
Användare kan åsidosätta de beroenden som anges i basmiljön genom att installera beroenden individuellt.
Lägga till beroenden individuellt
Du kan också installera beroenden på en notebook-fil som är ansluten till serverlös beräkning med hjälp av fliken Beroenden i panelen Miljö :
- Till höger om anteckningsboken klickar du på knappen för att expandera panelen Miljö . Den här knappen visas bara när en notebook-fil är ansluten till serverlös beräkning.
- I avsnittet Beroenden klickar du på Lägg till beroende och anger sökvägen till biblioteksberoendet i fältet . Du kan ange ett beroende i valfritt format som är giltigt i en requirements.txt fil.
- Klicka på Använd. Detta installerar beroendena i den virtuella notebook-miljön och startar om Python-processen.
Kommentar
Ett jobb med serverlös beräkning installerar miljöspecifikationen för notebook-filen innan du kör notebook-koden. Det innebär att du inte behöver lägga till beroenden när du schemalägger notebook-filer som jobb. Se Konfigurera notebook-miljöer och beroenden.
Visa installerade beroenden och pip-loggar
Om du vill visa installerade beroenden klickar du på Installerad på panelen Miljöer för en notebook-fil. Pip-installationsloggar för notebook-miljön är också tillgängliga genom att klicka på Pip-loggar längst ned i panelen.
Återställa miljön
Om notebook-filen är ansluten till serverlös beräkning cachelagrar Databricks automatiskt innehållet i notebook-filens virtuella miljö. Det innebär att du vanligtvis inte behöver installera om Python-beroenden som anges i panelen Miljö när du öppnar en befintlig notebook-fil, även om den har kopplats från på grund av inaktivitet.
Cachelagring av virtuell Python-miljö gäller även för jobb. Det innebär att efterföljande körningar av jobb går snabbare eftersom nödvändiga beroenden redan är tillgängliga.
Kommentar
Om du ändrar implementeringen av ett anpassat Python-paket som används i ett jobb på serverlös måste du också uppdatera versionsnumret för jobb för att hämta den senaste implementeringen.
Om du vill rensa miljöcachen och utföra en ny installation av de beroenden som anges i panelen Miljö i en notebook-fil som är kopplad till serverlös beräkning klickar du på pilen bredvid Tillämpa och klickar sedan på Återställ miljö.
Kommentar
Återställ den virtuella miljön om du installerar paket som bryter eller ändrar kärnanteckningsboken eller Apache Spark-miljön. Att koppla från notebook-filen från serverlös beräkning och koppla om den rensar inte nödvändigtvis hela miljöcachen.
Visa frågeinsikter
Serverlös beräkning för notebook-filer och arbetsflöden använder frågeinsikter för att utvärdera Spark-körningsprestanda. När du har kört en cell i en notebook-fil kan du visa insikter relaterade till SQL- och Python-frågor genom att klicka på länken Se prestanda .
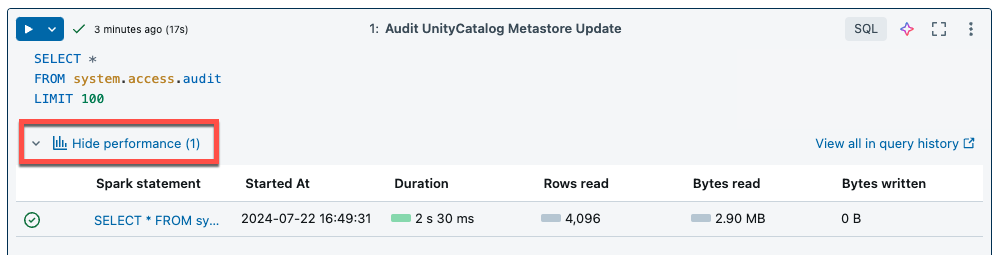
Du kan klicka på någon av Spark-uttrycken för att visa frågemåtten. Därifrån kan du klicka på Se frågeprofil för att se en visualisering av frågekörningen. Mer information om frågeprofiler finns i Frågeprofil.
Kommentar
Information om hur du visar prestandainsikter för jobbkörningar finns i Visa frågeinsikter för jobbkörning.
Frågehistorik
Alla frågor som körs på serverlös beräkning registreras också på arbetsytans frågehistoriksida. Information om frågehistorik finns i Frågehistorik.
Frågeinsiktsbegränsningar
- Frågeprofilen är endast tillgänglig när frågekörningen har avslutats.
- Mått uppdateras live även om frågeprofilen inte visas under körningen.
- Endast följande frågestatusar omfattas: RUNNING, CANCELED, FAILED, FINISHED.
- Det går inte att avbryta frågor som körs från frågehistoriksidan. De kan avbrytas i notebook-filer eller jobb.
- Utförliga mått är inte tillgängliga.
- Nedladdningen av frågeprofilen är inte tillgänglig.
- Åtkomst till Spark-användargränssnittet är inte tillgänglig.
- Instruktionstexten innehåller bara den sista raden som kördes. Det kan dock finnas flera rader före den här raden som kördes som en del av samma instruktion.
Begränsningar
En lista över begränsningar finns i Begränsningar för serverlös beräkning.