Metodtips för att skriva till filer till datasjö med dataflöden
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Om du inte har använt Azure Data Factory tidigare kan du läsa Introduktion till Azure Data Factory.
I den här självstudien får du lära dig metodtips som kan användas när du skriver filer till ADLS Gen2 eller Azure Blob Storage med hjälp av dataflöden. Du behöver åtkomst till ett Azure Blob Storage-konto eller Azure Data Lake Store Gen2-konto för att läsa en parquet-fil och sedan lagra resultatet i mappar.
Förutsättningar
- Azure-prenumeration. Om du inte har en Azure-prenumeration kan du skapa ett kostnadsfritt Azure-konto innan du börjar.
- Azure Storage-konto. Du använder ADLS-lagring som käll - och mottagardatalager . Om du inte har ett lagringskonto finns det anvisningar om hur du skapar ett i Skapa ett Azure Storage-konto.
Stegen i den här självstudien förutsätter att du har
Skapa en datafabrik
I det här steget skapar du en datafabrik och öppnar Data Factory UX för att skapa en pipeline i datafabriken.
Öppna Microsoft Edge eller Google Chrome. Data Factory-användargränssnittet stöds för närvarande endast i Microsoft Edge- och Google Chrome-webbläsare.
Välj Skapa en resursintegreringsdatafabrik>>på den vänstra menyn
På sidan Ny datafabrik under Namn anger du ADFTutorialDataFactory
Välj den Azure-prenumeration som du vill skapa den nya datafabriken i.
Gör något av följande för Resursgrupp:
a. Välj Använd befintlig och välj en befintlig resursgrupp i listrutan.
b. Välj Skapa ny och ange namnet på en resursgrupp. Mer information om resursgrupper finns i Använda resursgrupper för att hantera dina Azure-resurser.
Under Version väljer du V2.
Under Plats väljer du en plats för datafabriken. Endast platser som stöds visas i listrutan. Datalager (till exempel Azure Storage och SQL Database) och beräkningar (till exempel Azure HDInsight) som används av datafabriken kan finnas i andra regioner.
Välj Skapa.
När skapandet är klart visas meddelandet i Meddelandecenter. Välj Gå till resurs för att gå till sidan Datafabrik.
Klicka på Författare och övervakare för att starta användargränssnittet för datafabriken på en separat flik.
Skapa en pipeline med en dataflödesaktivitet
I det här steget skapar du en pipeline som innehåller en dataflödesaktivitet.
På startsidan för Azure Data Factory väljer du Orchestrate.
På fliken Allmänt för pipelinen anger du DeltaLake som Namn på pipelinen.
Dra på skjutreglaget Dataflöde felsökning i det övre fabriksfältet. Felsökningsläget möjliggör interaktiv testning av omvandlingslogik mot ett Live Spark-kluster. Dataflöde kluster tar 5–7 minuter att värma upp och användarna rekommenderas att aktivera felsökning först om de planerar att utföra Dataflöde utveckling. Mer information finns i Felsökningsläge.

I fönstret Aktiviteter expanderar du dragspelet Flytta och transformera . Dra och släpp aktiviteten Dataflöde från fönstret till pipelinearbetsytan.
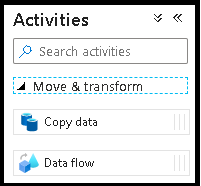
I popup-fönstret Lägg till Dataflöde väljer du Skapa ny Dataflöde och namnger sedan dataflödet DeltaLake. Klicka på Slutför när du är klar.
Skapa transformeringslogik på dataflödesarbetsytan
Du tar alla källdata (i den här självstudien använder vi en Parquet-filkälla) och använder en mottagartransformering för att landa data i Parquet-format med hjälp av de mest effektiva mekanismerna för data lake ETL.

Självstudiemål
- Välj någon av dina källdatauppsättningar i ett nytt dataflöde 1. Använda dataflöden för att effektivt partitionera din mottagardatauppsättning
- Landa partitionerade data i ADLS Gen2-lakemappar
Börja från en tom dataflödesarbetsyta
Först ska vi konfigurera dataflödesmiljön för var och en av de mekanismer som beskrivs nedan för landningsdata i ADLS Gen2
- Klicka på källtransformeringen.
- Klicka på den nya knappen bredvid datauppsättningen i den nedre panelen.
- Välj en datauppsättning eller skapa en ny. I den här demonstrationen använder vi en Parquet-datauppsättning med namnet Användardata.
- Lägg till en transformering av härledda kolumner. Vi använder detta som ett sätt att ange önskade mappnamn dynamiskt.
- Lägg till en transformering av mottagare.
Hierarkisk mapputdata
Det är mycket vanligt att använda unika värden i dina data för att skapa mapphierarkier för att partitionera dina data i sjön. Det här är ett mycket optimalt sätt att organisera och bearbeta data i sjön och i Spark (beräkningsmotorn bakom dataflöden). Det kommer dock att finnas en liten prestandakostnad för att organisera dina utdata på det här sättet. Förvänta dig en liten minskning av den totala pipelineprestandan med hjälp av den här mekanismen i mottagaren.
- Gå tillbaka till dataflödesdesignern och redigera dataflödet som skapas ovan. Klicka på mottagartransformeringen.
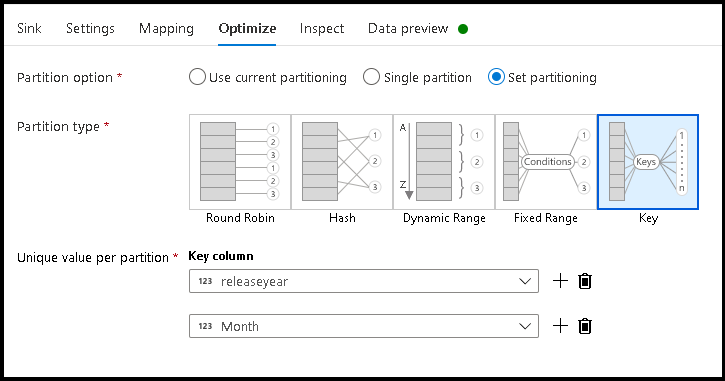
- Klicka på Optimera > uppsättningspartitioneringsnyckel >
- Välj de kolumner som du vill använda för att ange den hierarkiska mappstrukturen.
- Observera att exemplet nedan använder år och månad som kolumner för mappnamngivning. Resultatet blir mappar i formuläret
releaseyear=1990/month=8. - När du kommer åt datapartitionerna i en dataflödeskälla pekar du bara på mappen på den översta nivån ovan
releaseyearoch använder ett jokerteckenmönster för varje efterföljande mapp, t.ex.**/**/*.parquet - Om du vill ändra datavärdena, eller även om du behöver generera syntetiska värden för mappnamn, använder du transformeringen Härledd kolumn för att skapa de värden som du vill använda i mappnamnen.
Namnmapp som datavärden
En något bättre prestanda för mottagarteknik för sjödata med hjälp av ADLS Gen2 som inte erbjuder samma fördel som nyckel-/värdepartitionering är Name folder as column data. Medan nyckelpartitioneringsformatet för hierarkisk struktur gör att du kan bearbeta datasektorer enklare, är den här tekniken en utplattad mappstruktur som kan skriva data snabbare.
- Gå tillbaka till dataflödesdesignern och redigera dataflödet som skapas ovan. Klicka på mottagartransformeringen.
- Klicka på Optimera > uppsättningspartitionering > Använd aktuell partitionering.
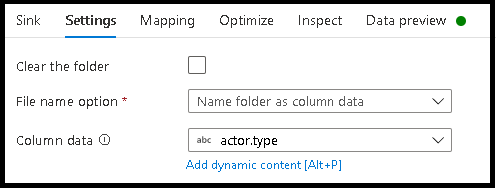
- Klicka på Inställningar > Namnmapp som kolumndata.
- Välj den kolumn som du vill använda för att generera mappnamn.
- Om du vill ändra datavärdena, eller även om du behöver generera syntetiska värden för mappnamn, använder du transformeringen Härledd kolumn för att skapa de värden som du vill använda i mappnamnen.
Namnfil som datavärden
De tekniker som anges i självstudierna ovan är bra användningsfall för att skapa mappkategorier i din datasjö. Standardschemat för namngivning av filer som används av dessa tekniker är att använda Spark-körjobb-ID:t. Ibland kanske du vill ange namnet på utdatafilen i en dataflödestextmottagare. Den här tekniken rekommenderas endast för användning med små filer. Processen att sammanfoga partitionsfiler i en enda utdatafil är en tidskrävande process.
- Gå tillbaka till dataflödesdesignern och redigera dataflödet som skapas ovan. Klicka på mottagartransformeringen.
- Klicka på Optimera > uppsättningspartitionering > Enskild partition. Det är det här kravet på en enskild partition som skapar en flaskhals i körningsprocessen när filer sammanfogas. Det här alternativet rekommenderas endast för små filer.
- Klicka på Inställningar > Namnfil som kolumndata.
- Välj den kolumn som du vill använda för att generera filnamn.
- Om du vill ändra datavärdena, eller även om du behöver generera syntetiska värden för filnamn, använder du transformeringen Härledd kolumn för att skapa de värden som du vill använda i dina filnamn.
Relaterat innehåll
Läs mer om dataflödesmottagare.