Mappa felsökningsläge för dataflöde
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Översikt
Med Azure Data Factory och Synapse Analytics som mappar dataflödets felsökningsläge kan du interaktivt titta på dataformstransformningen medan du skapar och felsöker dina dataflöden. Felsökningssessionen kan användas både i Dataflöde designsessioner och vid körning av pipelinefelsökning av dataflöden. Om du vill aktivera felsökningsläget använder du knappen Dataflöde Felsökning i det övre fältet på arbetsytan för dataflöde eller pipelinearbetsytan när du har dataflödesaktiviteter.
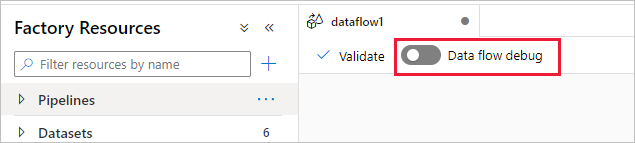

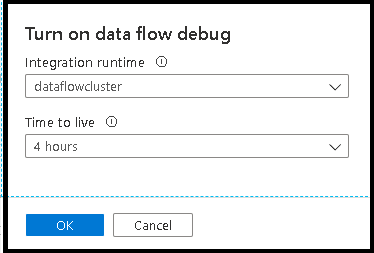
När du aktiverar skjutreglaget uppmanas du att välja vilken integreringskörningskonfiguration du vill använda. Om AutoResolveIntegrationRuntime väljs, kommer ett kluster med åtta kärnor av allmän beräkning med en standardtid på 60 minuter att leva att knoppas upp. Om du vill tillåta ett mer inaktivt team innan sessionen överskrider tidsgränsen kan du välja en högre TTL-inställning. Mer information om dataflödesintegreringskörningar finns i Integration Runtime-prestanda.
När felsökningsläget är aktiverat skapar du ditt dataflöde interaktivt med ett aktivt Spark-kluster. Sessionen stängs när du inaktiverar felsökningen. Du bör vara medveten om de timavgifter som datafabriken debiterar under den tid som felsökningssessionen är aktiverad.
I de flesta fall är det en bra idé att skapa dina Dataflöde i felsökningsläge så att du kan verifiera din affärslogik och visa dina datatransformeringar innan du publicerar ditt arbete. Använd knappen "Felsök" på pipelinepanelen för att testa dataflödet i en pipeline.
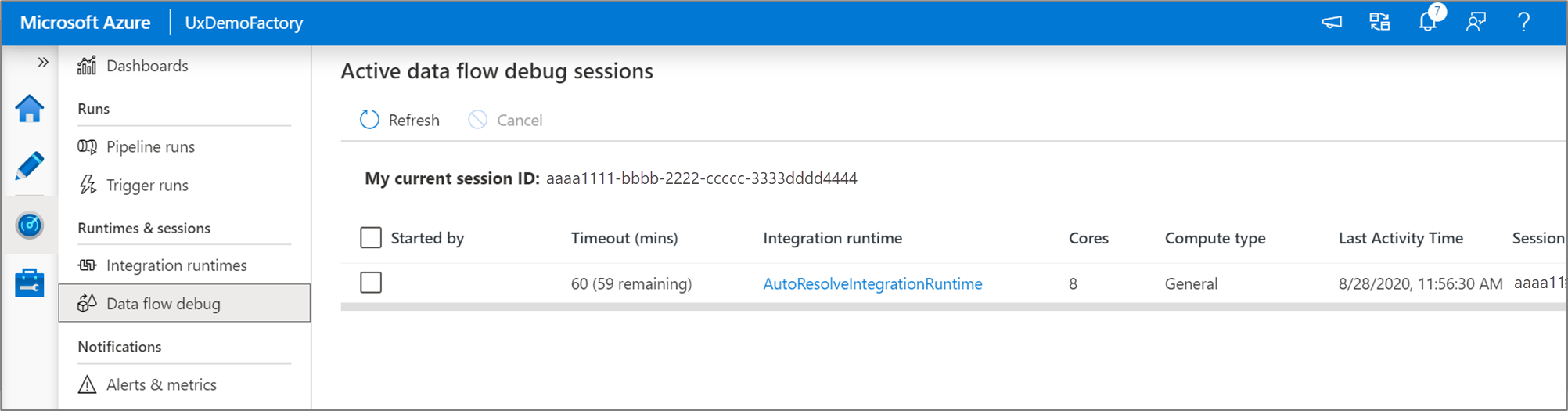
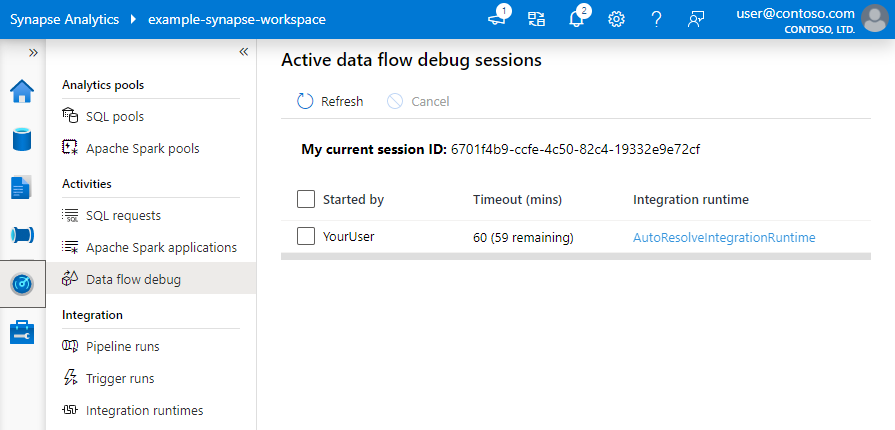
Kommentar
Varje felsökningssession som en användare startar från webbläsarens användargränssnitt är en ny session med ett eget Spark-kluster. Du kan använda övervakningsvyn för felsökningssessioner som visas i föregående bilder för att visa och hantera felsökningssessioner. Du debiteras för varje timme som varje felsökningssession körs, inklusive TTL-tid.
Det här videoklippet handlar om tips, tricks och bra metoder för felsökningsläge för dataflöden.
Klusterstatus
Klusterstatusindikatorn överst på designytan blir grön när klustret är redo för felsökning. Om klustret redan är varmt visas den gröna indikatorn nästan omedelbart. Om klustret inte redan kördes när du gick in i felsökningsläget utför Spark-klustret en kall start. Indikatorn snurrar tills miljön är redo för interaktiv felsökning.
När du är klar med felsökningen inaktiverar du felsökningsknappen så att Spark-klustret kan avslutas och du inte längre debiteras för felsökningsaktivitet.
Felsökningsinställningar
När du aktiverar felsökningsläget kan du redigera hur ett dataflöde förhandsgranskar data. Felsökningsinställningar kan redigeras genom att klicka på "Felsökningsinställningar" i verktygsfältet Dataflöde arbetsytor. Du kan välja den radgräns eller filkälla som ska användas för var och en av dina källtransformeringar här. Radgränserna i den här inställningen gäller endast för den aktuella felsökningssessionen. Du kan också välja den mellanlagringslänkade tjänst som ska användas för en Azure Synapse Analytics-källa.
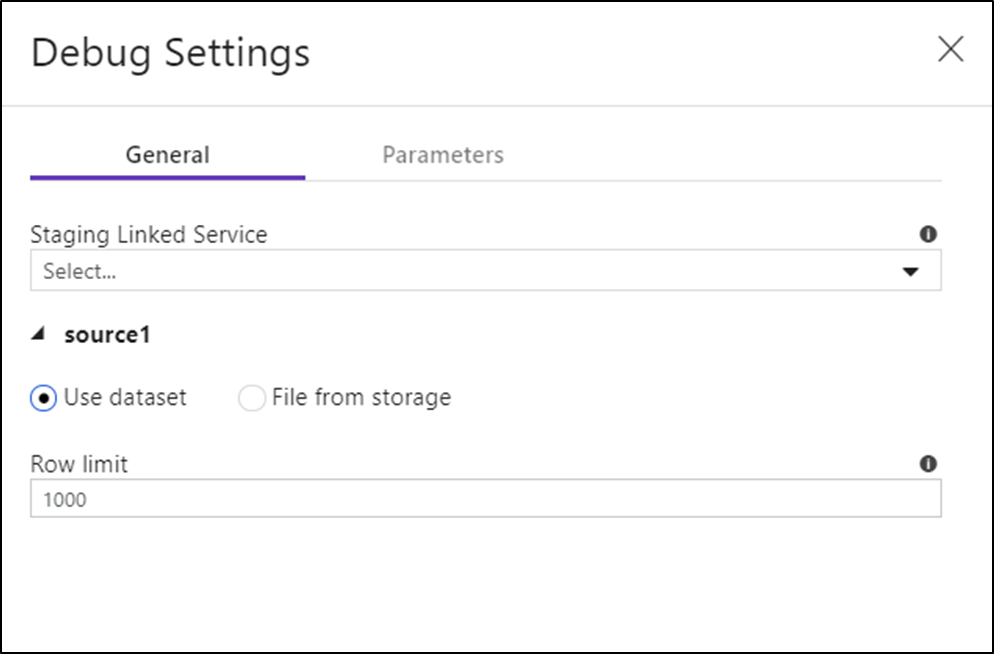
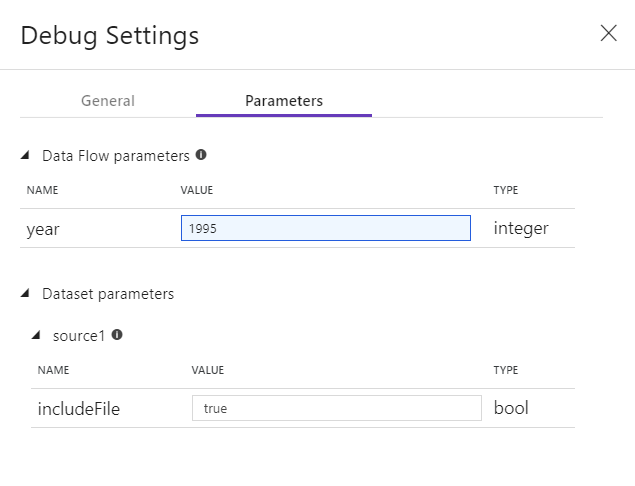
Om du har parametrar i din Dataflöde eller någon av dess refererade datauppsättningar kan du ange vilka värden som ska användas under felsökningen genom att välja fliken Parametrar.
Använd samplingsinställningarna här för att peka på exempelfiler eller exempeltabeller med data så att du inte behöver ändra dina källdatauppsättningar. Genom att använda en exempelfil eller tabell här kan du behålla samma logik- och egenskapsinställningar i dataflödet när du testar mot en delmängd data.
Standard-IR som används för felsökningsläge i dataflöden är en liten 4-kärnig enskild arbetsnod med en 4-kärnig enskild drivrutinsnod. Detta fungerar bra med mindre dataexempel när du testar dataflödeslogik. Om du expanderar radgränserna i felsökningsinställningarna under dataförhandsgranskningen eller anger ett högre antal samplade rader i källan under pipelinefelsökningen kanske du vill överväga att ange en större beräkningsmiljö i en ny Azure Integration Runtime. Sedan kan du starta om felsökningssessionen med hjälp av den större beräkningsmiljön.
Förhandsgranskning av data
När felsökningen är aktiverad lyser fliken Dataförhandsgranskning på den nedre panelen. Utan felsökningsläge på visar Dataflöde endast aktuella metadata in och ut från var och en av dina transformeringar på fliken Inspektera. Dataförhandsgranskningen frågar bara efter antalet rader som du har angett som din gräns i felsökningsinställningarna. Välj Uppdatera för att uppdatera förhandsgranskningen av data baserat på dina aktuella transformeringar. Om dina källdata har ändrats väljer du Uppdatera > referens från källan.
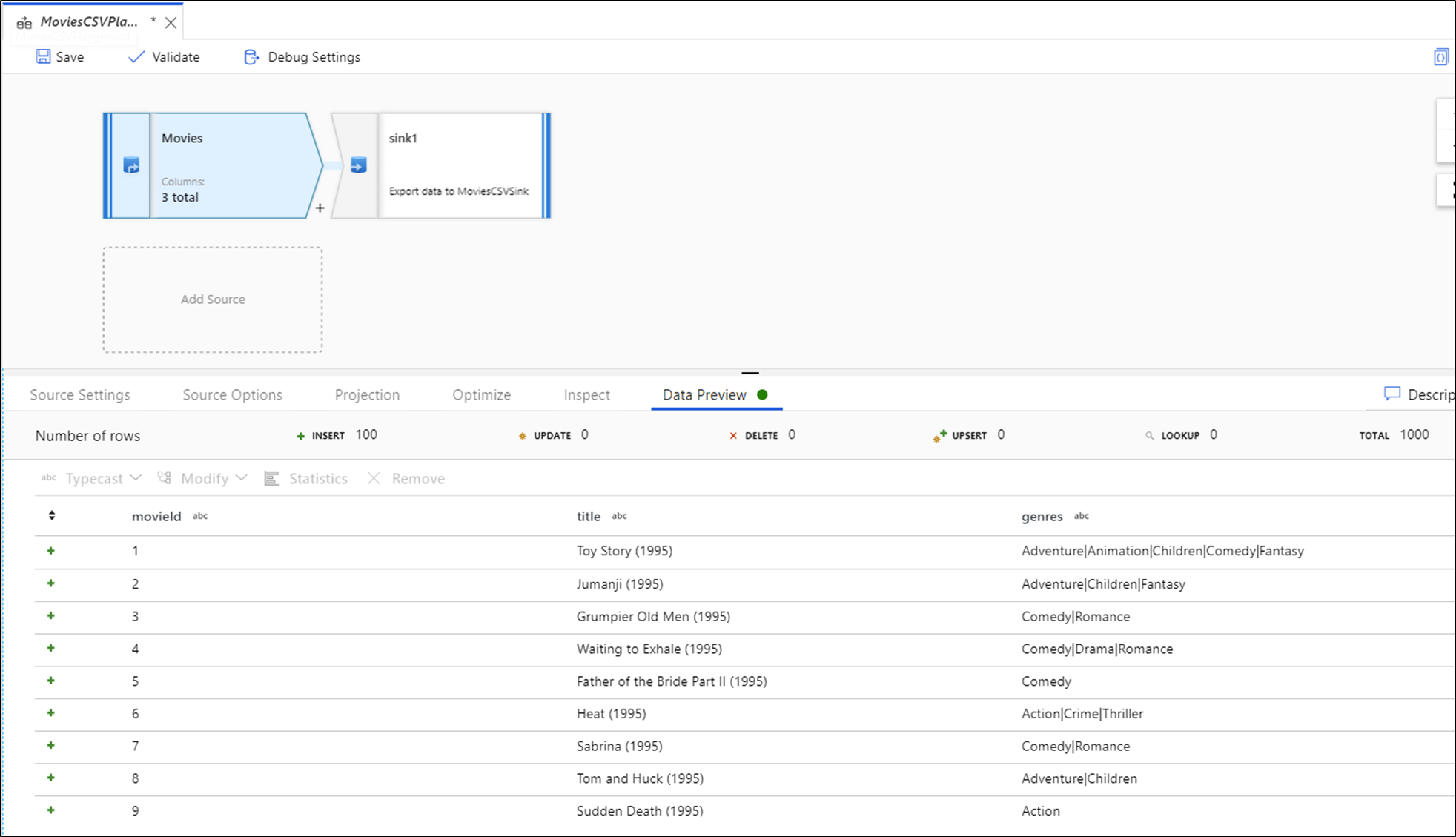
Du kan sortera kolumner i dataförhandsgranskning och ordna om kolumner med dra och släpp. Dessutom finns det en exportknapp överst i panelen för dataförhandsgranskning som du kan använda för att exportera förhandsgranskningsdata till en CSV-fil för datautforskning offline. Du kan använda den här funktionen för att exportera upp till 1 000 rader med förhandsgranskningsdata.
Kommentar
Filkällor begränsar bara de rader som du ser, inte de rader som läss. För mycket stora datamängder rekommenderar vi att du tar en liten del av filen och använder den för testningen. Du kan välja en tillfällig fil i Felsökningsinställningar för varje källa som är en fildatauppsättningstyp.
När du kör i felsökningsläge i Dataflöde skrivs inte dina data till transformering av mottagare. En felsökningssession är avsedd att fungera som ett test för dina transformeringar. Mottagare krävs inte under felsökningen och ignoreras i dataflödet. Om du vill testa att skriva data i mottagaren kör du Dataflöde från en pipeline och använder felsökningskörningen från en pipeline.
Dataförhandsvisning är en ögonblicksbild av dina transformerade data med hjälp av radgränser och datasampling från dataramar i Spark-minnet. Därför används eller testas inte mottagardrivrutinerna i det här scenariot.
Kommentar
Dataförhandsvisning visar tid enligt webbläsarens nationella inställningar.
Testa kopplingsvillkor
När enhetstestning av kopplingar, finns eller uppslagstransformeringar kontrollerar du att du använder en liten uppsättning kända data för testet. Du kan använda alternativet Felsökningsinställningar som beskrevs tidigare för att ange en tillfällig fil som ska användas för testningen. Detta behövs eftersom du inte kan förutsäga vilka rader och vilka nycklar som ska läsas in i flödet för testning när du begränsar eller samplar rader från en stor datamängd. Resultatet är icke-terministiskt, vilket innebär att dina kopplingsvillkor kan misslyckas.
Snabbåtgärder
När du ser dataförhandsgranskningen kan du generera en snabb transformering till typecast, ta bort eller göra en ändring i en kolumn. Välj kolumnrubriken och välj sedan ett av alternativen i verktygsfältet för dataförhandsgranskning.
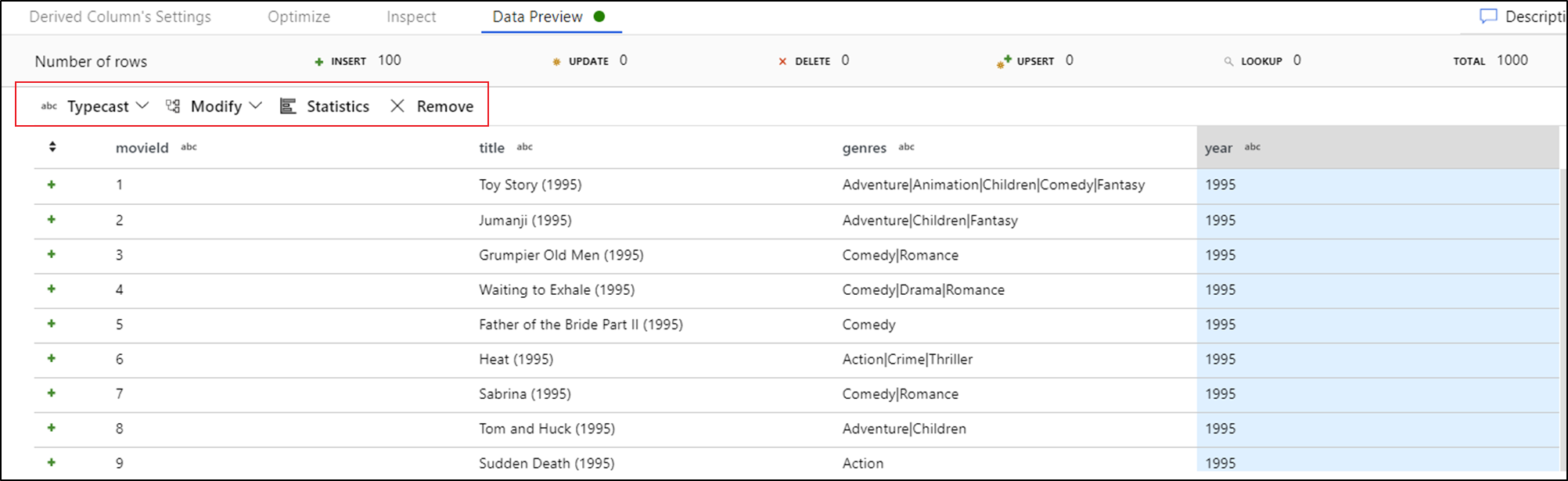
När du har valt en ändring uppdateras dataförhandsgranskningen omedelbart. Välj Bekräfta i det övre högra hörnet för att generera en ny transformering.
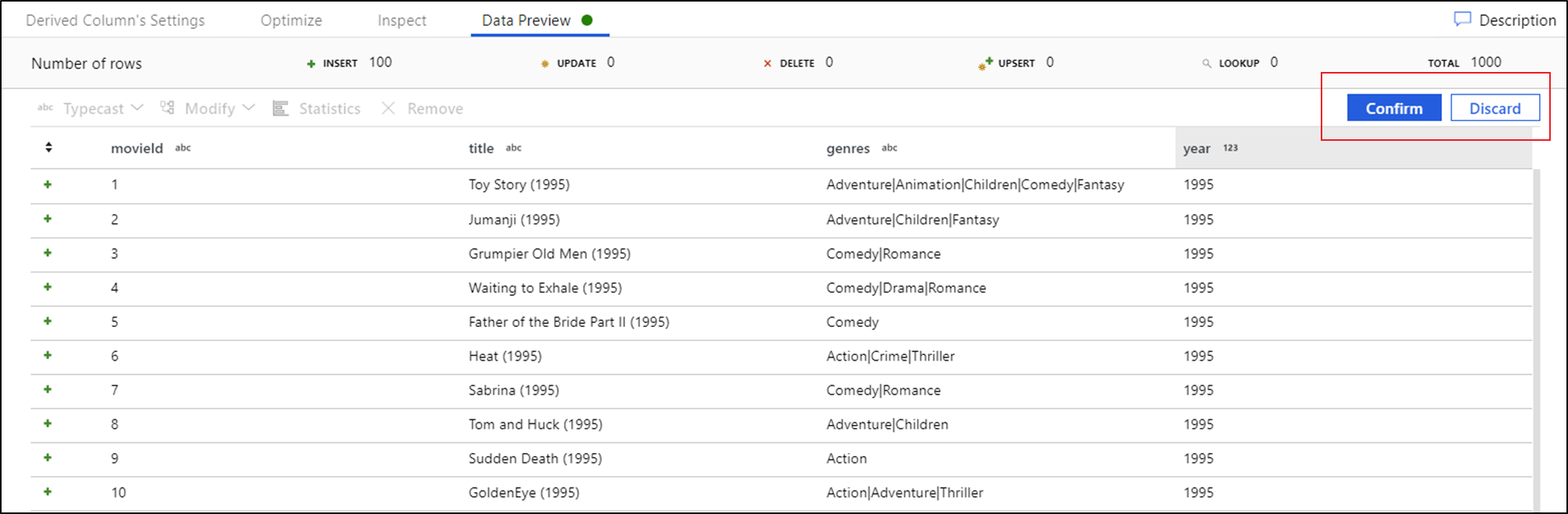
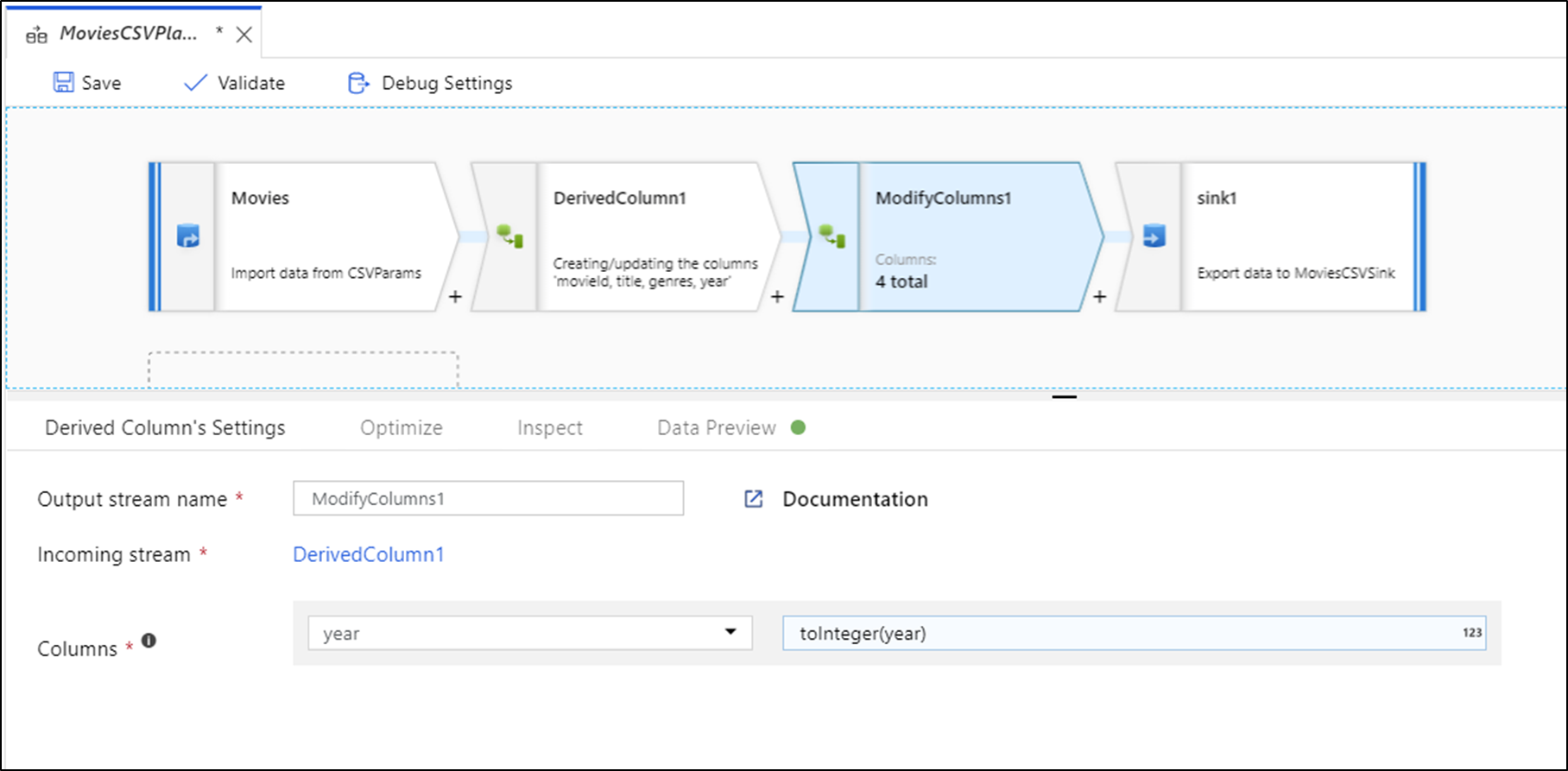
Typecast och Modify genererar en transformering av härledda kolumner och Ta bort genererar en Select-transformering.
Kommentar
Om du redigerar Dataflöde måste du hämta dataförhandsgranskningen igen innan du lägger till en snabb transformering.
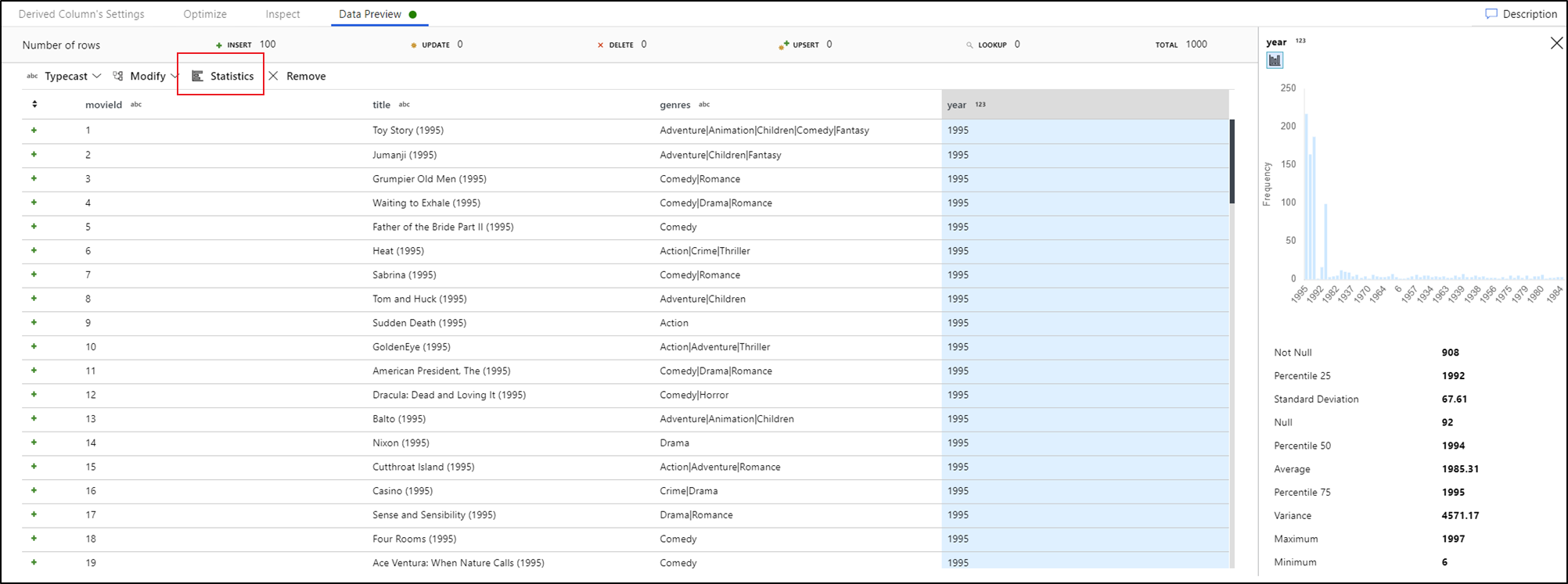
Dataprofilering
Om du väljer en kolumn på fliken Förhandsgranskning av data och klickar på Statistik i verktygsfältet för dataförhandsgranskning visas ett diagram längst till höger i datarutnätet med detaljerad statistik om varje fält. Tjänsten gör en bestämningsbas på datasampling av vilken typ av diagram som ska visas. Fält med hög kardinalitet är som standard NULL-/NOT NULL-diagram medan kategoriska och numeriska data med låg kardinalitet visar stapeldiagram som visar datavärdesfrekvens. Du ser också max/längd på strängfält, min/max-värden i numeriska fält, standardutveckling, percentiler, antal och medelvärde.
Relaterat innehåll
- När du är klar med att skapa och felsöka dataflödet kör du det från en pipeline.
- När du testar din pipeline med ett dataflöde använder du körningsalternativet För felsökning av pipeline .