Transformera data i Delta Lake med hjälp av mappning av dataflöden
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Om du inte har använt Azure Data Factory tidigare kan du läsa Introduktion till Azure Data Factory.
I den här självstudien använder du dataflödesarbetsytan för att skapa dataflöden som gör att du kan analysera och transformera data i Azure Data Lake Storage (ADLS) Gen2 och lagra dem i Delta Lake.
Förutsättningar
- Azure-prenumeration. Om du inte har en Azure-prenumeration kan du skapa ett kostnadsfritt Azure-konto innan du börjar.
- Azure Storage-konto. Du använder ADLS-lagring som käll - och mottagardatalager . Om du inte har ett lagringskonto finns det anvisningar om hur du skapar ett i Skapa ett Azure Storage-konto.
Filen som vi transformerar i den här självstudien är MoviesDB.csv, som du hittar här. Om du vill hämta filen från GitHub kopierar du innehållet till valfri textredigerare för att spara lokalt som en .csv fil. Information om hur du laddar upp filen till ditt lagringskonto finns i Ladda upp blobar med Azure Portal. Exemplen refererar till en container med namnet "sample-data".
Skapa en datafabrik
I det här steget skapar du en datafabrik och öppnar Data Factory UX för att skapa en pipeline i datafabriken.
Öppna Microsoft Edge eller Google Chrome. Data Factory-användargränssnittet stöds för närvarande endast i Microsoft Edge- och Google Chrome-webbläsare.
Välj Skapa en resursintegreringsdatafabrik>>på den vänstra menyn
På sidan Ny datafabrik under Namn anger du ADFTutorialDataFactory
Välj den Azure-prenumeration som du vill skapa den nya datafabriken i.
Gör något av följande för Resursgrupp:
a. Välj Använd befintlig och välj en befintlig resursgrupp i listrutan.
b. Välj Skapa ny och ange namnet på en resursgrupp.
Mer information om resursgrupper finns i Använda resursgrupper för att hantera Azure-resurser.
Under Version väljer du V2.
Under Plats väljer du en plats för datafabriken. Endast platser som stöds visas i listrutan. Datalager (till exempel Azure Storage och SQL Database) och beräkningar (till exempel Azure HDInsight) som används av datafabriken kan finnas i andra regioner.
Välj Skapa.
När skapandet är klart visas meddelandet i Meddelandecenter. Välj Gå till resurs för att gå till sidan Datafabrik.
Klicka på Författare och övervakare för att starta användargränssnittet för datafabriken på en separat flik.
Skapa en pipeline med en dataflödesaktivitet
I det här steget skapar du en pipeline som innehåller en dataflödesaktivitet.
På startsidan väljer du Orkestrera.
På fliken Allmänt för pipelinen anger du DeltaLake som Namn på pipelinen.
I fönstret Aktiviteter expanderar du dragspelet Flytta och transformera . Dra och släpp aktiviteten Dataflöde från fönstret till pipelinearbetsytan.
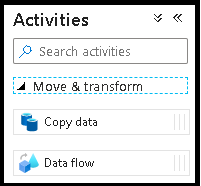
I popup-fönstret Lägg till Dataflöde väljer du Skapa ny Dataflöde och namnger sedan dataflödet DeltaLake. Välj Slutför när du är klar.
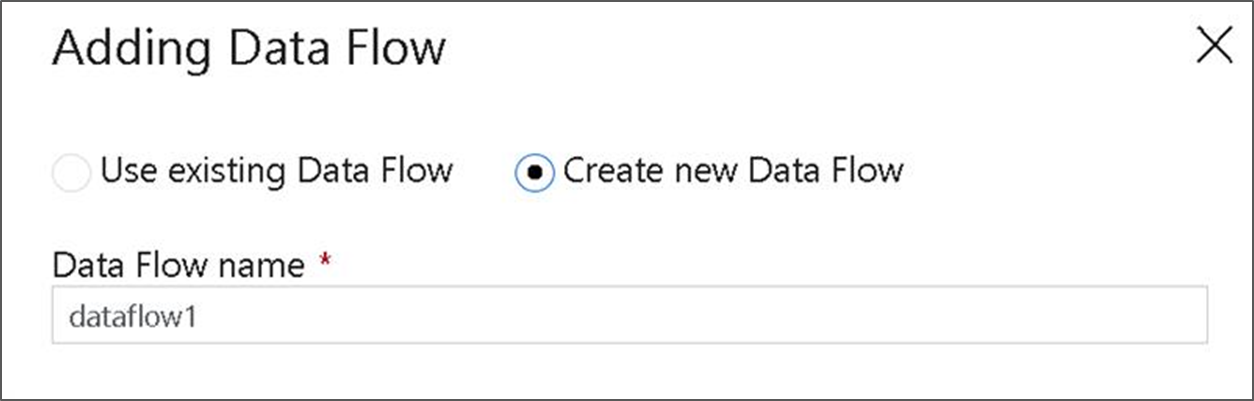
I det övre fältet på pipelinearbetsytan skjuter du Dataflöde felsökningsreglaget på. Felsökningsläget möjliggör interaktiv testning av omvandlingslogik mot ett Live Spark-kluster. Dataflöde kluster tar 5–7 minuter att värma upp och användarna rekommenderas att aktivera felsökning först om de planerar att utföra Dataflöde utveckling. Mer information finns i Felsökningsläge.

Skapa transformeringslogik på dataflödesarbetsytan
Du genererar två dataflöden i den här självstudien. Det första dataflödet är en enkel källa att sänka för att generera en ny Delta Lake från CSV-filen för filmer. Slutligen skapar du den flödesdesign som följer för att uppdatera data i Delta Lake.

Självstudiemål
- Använd datauppsättningskällan MoviesCSV från förutsättningarna och skapa en ny Delta Lake från den.
- Skapa logiken till uppdaterade betyg för 1988-filmer till "1".
- Ta bort alla filmer från 1950.
- Infoga nya filmer för 2021 genom att duplicera filmerna från 1960.
Börja från en tom dataflödesarbetsyta
Välj källtransformeringen överst i fönstret för dataflödesredigeraren och välj sedan + Ny bredvid egenskapen Datauppsättning i fönstret Källinställningar :
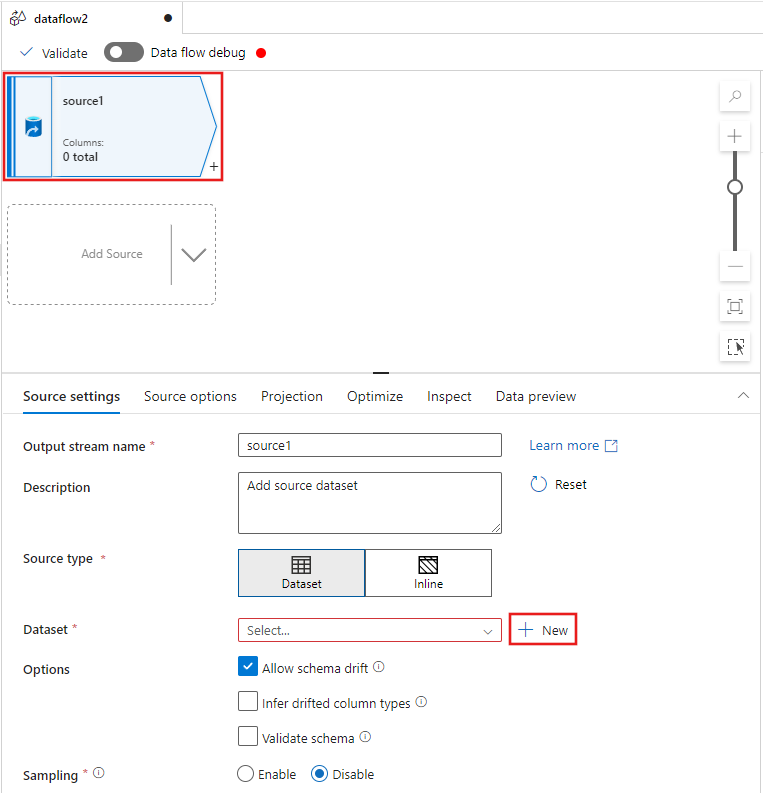
Välj Azure Data Lake Storage Gen2 från fönstret Ny datauppsättning som visas och välj sedan Fortsätt.
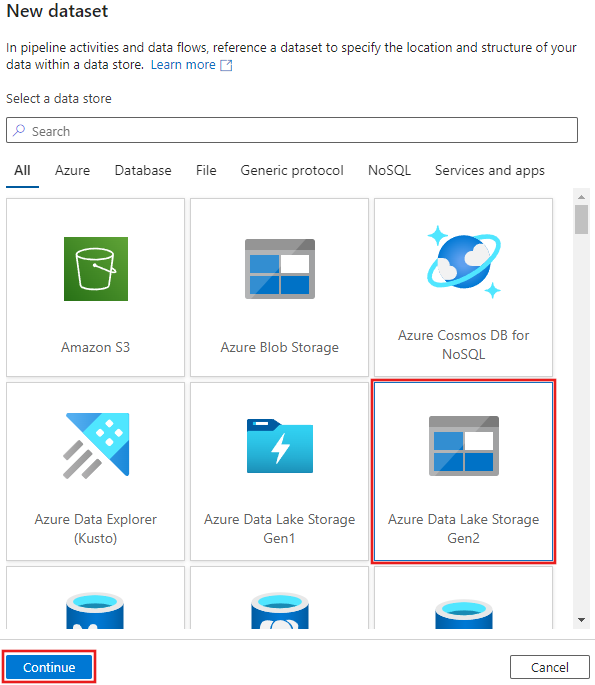
Välj AvgränsadText som datamängdstyp och välj Fortsätt igen.

Ge datauppsättningen namnet "MoviesCSV" och välj + Ny under Länkad tjänst för att skapa en ny länkad tjänst till filen.
Ange information om ditt lagringskonto som skapades tidigare i avsnittet Krav och bläddra och välj den MoviesCSV-fil som du laddade upp där.
När du har lagt till den länkade tjänsten markerar du kryssrutan Första raden som rubrik och väljer sedan OK för att lägga till källan.
Gå till fliken Projektion i fönstret för dataflödesinställningar och välj sedan Identifiera datatyper.
Välj + nu efter källan i dataflödesredigerarens fönster och rulla nedåt för att välja Mottagare under avsnittet Mål , och lägg till en ny mottagare i dataflödet.
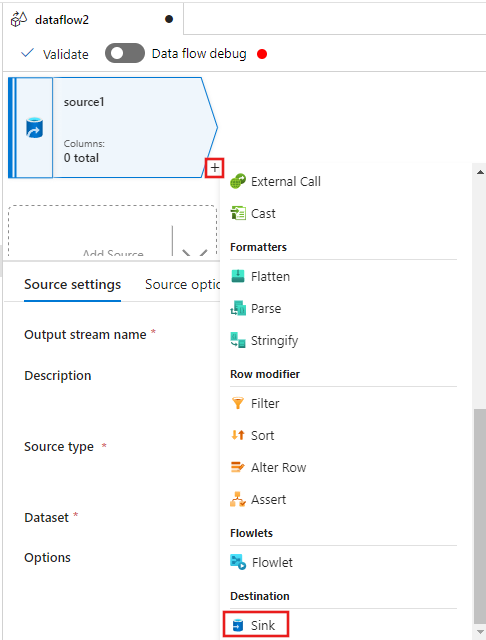
På fliken Mottagare för de mottagarinställningar som visas efter att mottagaren har lagts till väljer du Infoga för mottagartypen och sedan Delta för datauppsättningstypen Infoga. Välj sedan Azure Data Lake Storage Gen2 för den länkade tjänsten.
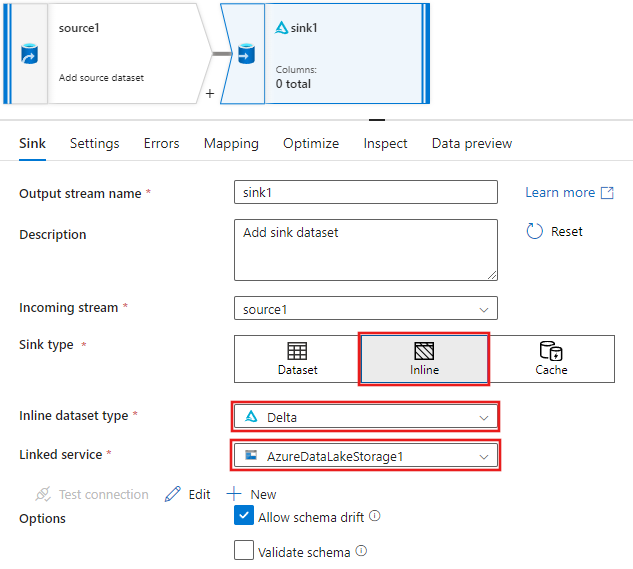
Välj ett mappnamn i lagringscontainern där du vill att tjänsten ska skapa Delta Lake.
Navigera slutligen tillbaka till pipelinedesignern och välj Felsök för att köra pipelinen i felsökningsläge med bara den här dataflödesaktiviteten på arbetsytan. Detta genererar din nya Delta Lake i Azure Data Lake Storage Gen2.
På menyn Fabriksresurser till vänster på skärmen väljer du + nu att lägga till en ny resurs och väljer sedan Dataflöde.
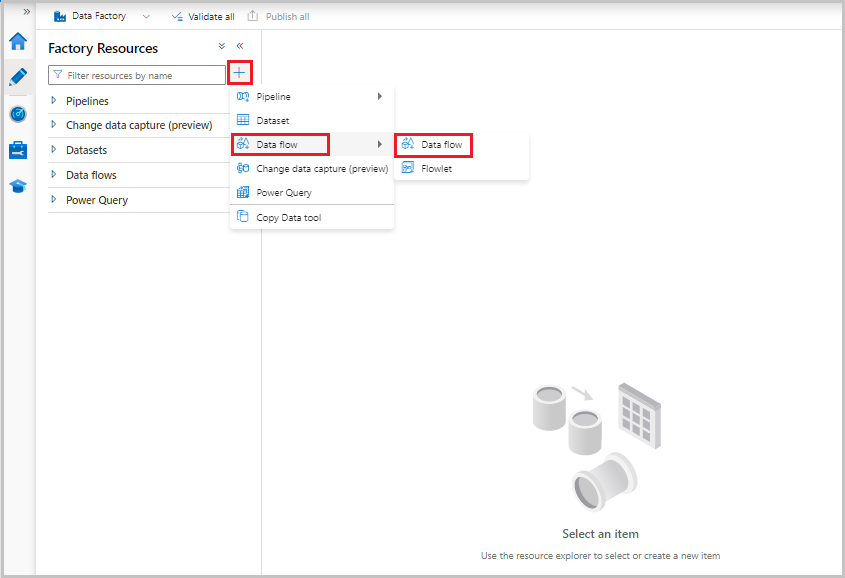
Som tidigare väljer du Filen MoviesCSV igen som källa och väljer sedan Identifiera datatyper igen på fliken Projektion .
Den här gången, när du har skapat källan, väljer du + fönstret i dataflödesredigeraren och lägger till en filtertransformering i källan.
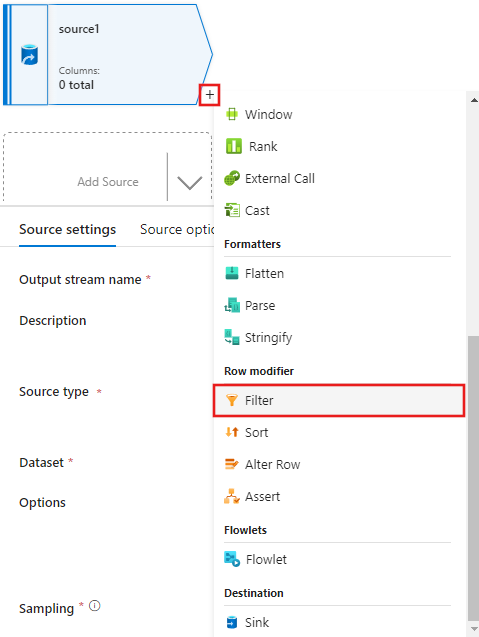
Lägg till ett filter på villkor i fönstret Filterinställningar som endast tillåter filmrader som matchar 1950, 1960 och 1988.
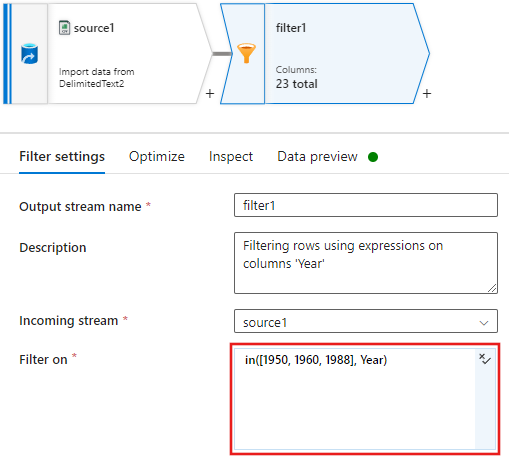
Lägg nu till en transformering av härledda kolumner för att uppdatera klassificeringar för varje film från 1988 till "1".
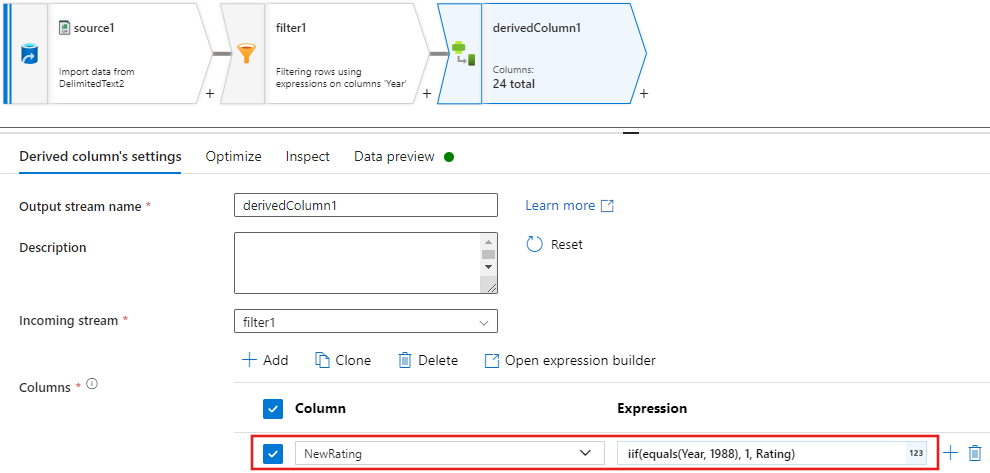
Update, insert, delete, and upsertprinciper skapas i ändringsradtransformen. Lägg till en ändringsradtransformering efter din härledda kolumn.Dina alter row-principer bör se ut så här.

Nu när du har angett rätt princip för varje ändringsradtyp kontrollerar du att rätt uppdateringsregler har angetts för mottagartransformeringen
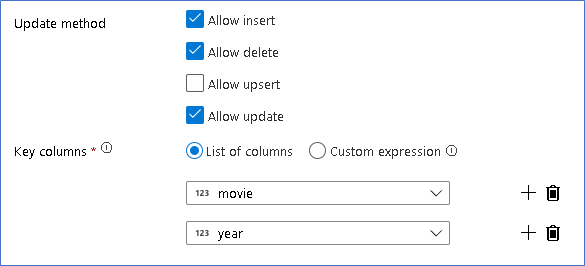
Här använder vi Delta Lake-mottagaren till din Azure Data Lake Storage Gen2-datasjö och tillåter infogningar, uppdateringar och borttagningar.
Observera att nyckelkolumnerna är en sammansatt nyckel som består av primärnyckelkolumnen film och årskolumnen. Det beror på att vi skapade falska filmer från 2021 genom att duplicera raderna från 1960. Detta undviker kollisioner när du letar upp de befintliga raderna genom att tillhandahålla unikhet.
Ladda ned slutfört exempel
Här är en exempellösning för Delta-pipelinen med ett dataflöde för att uppdatera/ta bort rader i sjön.
Relaterat innehåll
Läs mer om språket för dataflödesuttryck.