Guide för att mappa dataflödens prestanda och justering
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflödesmappning i Azure Data Factory och Synapse-pipelines ger ett kodfritt gränssnitt för att utforma och köra datatransformationer i stor skala. Om du inte är bekant med dataflödesmappning kan du gå till Översikt över dataflödesmappning. Den här artikeln beskriver olika sätt att justera och optimera dina dataflöden så att de uppfyller dina prestandamått.
Titta på följande video för att se några exempel på tidsinställningar för att transformera data med dataflöden.
Övervaka dataflödesprestanda
När du har verifierat omvandlingslogik med felsökningsläget kör du dataflödet från slutpunkt till slutpunkt som en aktivitet i en pipeline. Dataflöden operationaliseras i en pipeline med hjälp av körningen av dataflödesaktiviteten. Dataflödesaktiviteten har en unik övervakningsupplevelse jämfört med andra aktiviteter som visar en detaljerad körningsplan och en prestandaprofil för omvandlingslogik. Om du vill visa detaljerad övervakningsinformation för ett dataflöde väljer du glasögonikonen i aktivitetskörningens utdata för en pipeline. Mer information finns i Övervaka mappning av dataflöden.

När du övervakar dataflödesprestanda finns det fyra möjliga flaskhalsar att hålla utkik efter:
- Starttid för kluster
- Läsa från en källa
- Omvandlingstid
- Skriva till en mottagare
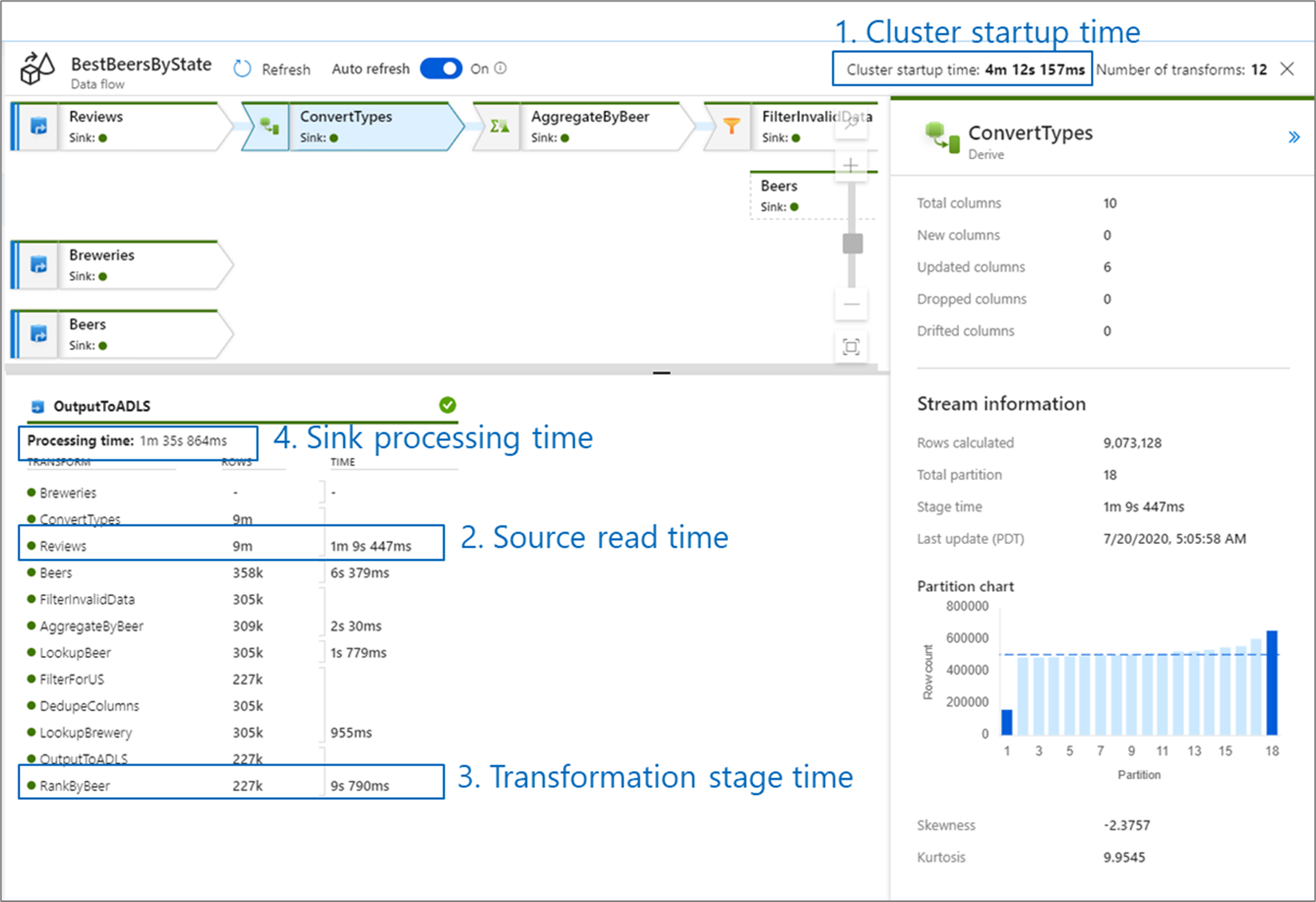
Starttiden för kluster är den tid det tar att starta ett Apache Spark-kluster. Det här värdet finns i det övre högra hörnet på övervakningsskärmen. Dataflöden körs på en just-in-time-modell där varje jobb använder ett isolerat kluster. Den här starttiden tar vanligtvis 3–5 minuter. För sekventiella jobb kan starttiden minskas genom att aktivera ett time to live-värde. Mer information finns i avsnittet Time to live (Tid att leva ) i Integration Runtime-prestanda.
Dataflöden använder en Spark-optimerare som ordnar om och kör din affärslogik i "faser" för att utföra så snabbt som möjligt. För varje mottagare som dataflödet skriver till visar övervakningsutdata varaktigheten för varje transformeringssteg, tillsammans med den tid det tar att skriva data till mottagaren. Den tid som är störst är troligen flaskhalsen i ditt dataflöde. Om transformeringssteget som tar den största innehåller en källa kanske du vill titta på hur du kan optimera lästiden ytterligare. Om en transformering tar lång tid kan du behöva partitionera om eller öka storleken på integrationskörningen. Om handfatbearbetningstiden är stor kan du behöva skala upp databasen eller kontrollera att du inte matar ut till en enda fil.
När du har identifierat flaskhalsen i dataflödet använder du strategierna för optimering nedan för att förbättra prestandan.
Testa dataflödeslogik
När du utformar och testar dataflöden från användargränssnittet kan du med felsökningsläget interaktivt testa mot ett Live Spark-kluster, vilket gör att du kan förhandsgranska data och köra dina dataflöden utan att vänta på att ett kluster ska värmas upp. Mer information finns i Felsökningsläge.
Fliken Optimera
Fliken Optimera innehåller inställningar för att konfigurera partitioneringsschemat för Spark-klustret. Den här fliken finns i varje transformering av dataflödet och anger om du vill partitionera om data när omvandlingen har slutförts. Genom att justera partitioneringen får du kontroll över fördelningen av dina data mellan beräkningsnoder och optimering av datalokalitet som kan ha både positiva och negativa effekter på dina övergripande dataflödesprestanda.
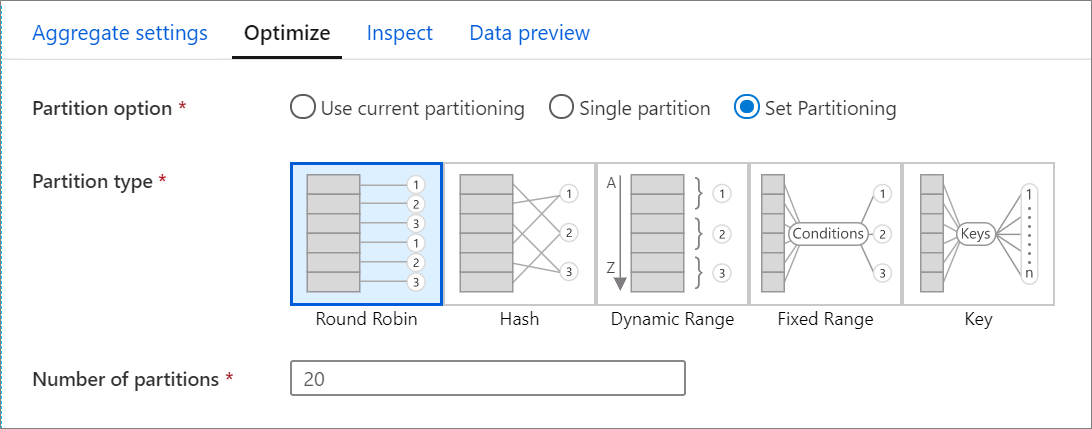
Använd aktuell partitionering som standard, vilket instruerar tjänsten att behålla den aktuella utdatapartitioneringen av omvandlingen. Eftersom ompartitionering av data tar tid rekommenderar vi att du använder aktuell partitionering i de flesta scenarier. Scenarier där du kanske vill partitionera om dina data inkluderar efter aggregeringar och kopplingar som avsevärt förvränger dina data eller när du använder källpartitionering i en SQL-databas.
Om du vill ändra partitioneringen för en transformering väljer du fliken Optimera och väljer alternativknappen Ange partitionering . Du får en rad alternativ för partitionering. Den bästa metoden för partitionering skiljer sig beroende på dina datavolymer, kandidatnycklar, null-värden och kardinalitet.
Viktigt!
En partition kombinerar alla distribuerade data till en enda partition. Det här är en mycket långsam åtgärd som också påverkar alla nedströmstransformeringar och skrivningar avsevärt. Det här alternativet rekommenderas inte om det inte finns en uttrycklig affärsorsak att använda det.
Följande partitioneringsalternativ är tillgängliga i varje transformering:
Resursallokering
Resursallokering distribuerar data lika mellan partitioner. Använd resursallokering när du inte har bra nyckelkandidater för att implementera en solid, smart partitioneringsstrategi. Du kan ange antalet fysiska partitioner.
Hash
Tjänsten genererar en hash med kolumner för att skapa enhetliga partitioner så att rader med liknande värden hamnar i samma partition. När du använder hash-alternativet testar du för eventuell partitionssnedvridning. Du kan ange antalet fysiska partitioner.
Dynamiskt intervall
Det dynamiska intervallet använder dynamiska Spark-intervall baserat på de kolumner eller uttryck som du anger. Du kan ange antalet fysiska partitioner.
Fast intervall
Skapa ett uttryck som ger ett fast intervall för värden i dina partitionerade datakolumner. För att undvika partitionsförskjutning bör du ha en god förståelse för dina data innan du använder det här alternativet. De värden som du anger för uttrycket används som en del av en partitionsfunktion. Du kan ange antalet fysiska partitioner.
Nyckel
Om du har en god förståelse för kardinaliteten för dina data kan nyckelpartitionering vara en bra strategi. Nyckelpartitionering skapar partitioner för varje unikt värde i kolumnen. Du kan inte ange antalet partitioner eftersom talet baseras på unika värden i data.
Dricks
Om du ställer in partitioneringsschemat manuellt omfördelar du data och kan kompensera fördelarna med Spark-optimeraren. Bästa praxis är att inte ange partitioneringen manuellt om du inte behöver det.
Loggningsnivå
Om du inte kräver varje pipelinekörning av dina dataflödesaktiviteter för att fullständigt logga alla utförliga telemetriloggar kan du ange loggningsnivån till "Basic" eller "None". När du kör dina dataflöden i "utförligt" läge (standard) begär du att tjänsten loggar aktivitet fullt ut på varje enskild partitionsnivå under dataomvandlingen. Detta kan vara en dyr åtgärd, så att bara aktivera utförliga när du felsöker kan förbättra ditt övergripande dataflöde och pipelineprestanda. "Basic"-läget loggar endast transformeringsvaraktigheterna medan "Ingen" endast ger en sammanfattning av varaktigheterna.

Relaterat innehåll
Se andra Dataflöde artiklar om prestanda: