Självstudie: Analysera data i Azure Monitor-loggar med hjälp av en notebook-fil
Notebook-filer är integrerade miljöer där du kan skapa och dela dokument med livekod, ekvationer, visualiseringar och text. Genom att integrera en notebook-fil med en Log Analytics-arbetsyta kan du skapa en process i flera steg som kör kod i varje steg baserat på resultatet från föregående steg. Du kan använda sådana effektiva processer för att skapa maskininlärningspipelines, avancerade analysverktyg, felsökningsguider (TSG:er) för supportbehov med mera.
När du integrerar en notebook-fil med en Log Analytics-arbetsyta kan du också:
- Kör KQL-frågor och anpassad kod på valfritt språk.
- Introducera nya analys- och visualiseringsfunktioner, till exempel nya maskininlärningsmodeller, anpassade tidslinjer och processträd.
- Integrera datauppsättningar utanför Azure Monitor-loggar, till exempel en lokal datauppsättning.
- Dra nytta av ökade tjänstgränser med hjälp av fråge-API-gränserna jämfört med Azure Portal.
I den här självstudien lär du dig att:
- Integrera en notebook-fil med Log Analytics-arbetsytan med hjälp av Azure Monitor Query-klientbiblioteket och Azure Identity-klientbiblioteket
- Utforska och visualisera data från din Log Analytics-arbetsyta i en notebook-fil
- Mata in data från notebook-filen i en anpassad tabell på Log Analytics-arbetsytan (valfritt)
Ett exempel på hur du skapar en maskininlärningspipeline för att analysera data i Azure Monitor-loggar med hjälp av en notebook-fil finns i den här exempelanteckningsboken: Identifiera avvikelser i Azure Monitor-loggar med hjälp av maskininlärningstekniker.
Dricks
Om du vill kringgå API-relaterade begränsningar delar du upp större frågor i flera mindre frågor.
Förutsättningar
Du behöver följande för den här självstudien:
En Azure Machine Learning-arbetsyta med en CPU-beräkningsinstans med:
- En notebook-fil.
- En kernel inställd på Python 3.8 eller senare.
Följande roller och behörigheter:
I Azure Monitor-loggar: Rollen Logs Analytics-deltagare för att läsa data från och skicka data till din Logs Analytics-arbetsyta. Mer information finns i Hantera åtkomst till Log Analytics-arbetsytor.
I Azure Machine Learning:
- En ägar- eller deltagarroll på resursgruppsnivå för att skapa en ny Azure Machine Learning-arbetsyta om det behövs.
- En deltagarroll på Azure Machine Learning-arbetsytan där du kör din notebook-fil.
Mer information finns i Hantera åtkomst till en Azure Machine Learning-arbetsyta.
Verktyg och anteckningsböcker
I den här självstudien använder du följande verktyg:
| Verktyg | beskrivning |
|---|---|
| Azure Monitor Query-klientbibliotek | Gör att du kan köra skrivskyddade frågor på data i Azure Monitor-loggar. |
| Azure Identity-klientbibliotek | Gör att Azure SDK-klienter kan autentisera med Microsoft Entra-ID. |
| Azure Monitor-klientbibliotek för inmatning | Gör att du kan skicka anpassade loggar till Azure Monitor med hjälp av API:et för logginmatning. Krävs för att mata in analyserade data i en anpassad tabell på din Log Analytics-arbetsyta (valfritt) |
| Datainsamlingsregel, datainsamlingsslutpunkt och ett registrerat program | Krävs för att mata in analyserade data i en anpassad tabell på din Log Analytics-arbetsyta (valfritt) |
Andra frågebibliotek som du kan använda är:
- Med Kqlmagic-biblioteket kan du köra KQL-frågor direkt i en notebook-fil på samma sätt som du kör KQL-frågor från Log Analytics-verktyget.
- MSTICPY-biblioteket innehåller mallade frågor som anropar inbyggda KQL-tidsserier och maskininlärningsfunktioner och tillhandahåller avancerade visualiseringsverktyg och analyser av data på Log Analytics-arbetsytan.
Andra Microsoft Notebook-funktioner för avancerad analys är:
- Azure Synapse Analytics-notebook-filer
- Microsoft Fabric-anteckningsböcker
- Notebook-filer för Visual Studio Code
1. Integrera din Log Analytics-arbetsyta med din notebook-fil
Konfigurera din notebook-fil för att fråga din Log Analytics-arbetsyta:
Installera klientbiblioteken för Azure Monitor Query, Azure Identity och Azure Monitor Ingestion tillsammans med Pandas-dataanalysbiblioteket, plottvisualiseringsbiblioteket:
import sys !{sys.executable} -m pip install --upgrade azure-monitor-query azure-identity azure-monitor-ingestion !{sys.executable} -m pip install --upgrade pandas plotlyAnge variabeln
LOGS_WORKSPACE_IDnedan till ID för din Log Analytics-arbetsyta. Variabeln är för närvarande inställd på att använda Azure Monitor Demo-arbetsytan, som du kan använda för att demonstrera notebook-filen.LOGS_WORKSPACE_ID = "DEMO_WORKSPACE"Konfigurera
LogsQueryClientför att autentisera och fråga Azure Monitor-loggar.Den här koden konfigureras
LogsQueryClientför att autentisera med :DefaultAzureCredentialfrom azure.core.credentials import AzureKeyCredential from azure.core.pipeline.policies import AzureKeyCredentialPolicy from azure.identity import DefaultAzureCredential from azure.monitor.query import LogsQueryClient if LOGS_WORKSPACE_ID == "DEMO_WORKSPACE": credential = AzureKeyCredential("DEMO_KEY") authentication_policy = AzureKeyCredentialPolicy(name="X-Api-Key", credential=credential) else: credential = DefaultAzureCredential() authentication_policy = None logs_query_client = LogsQueryClient(credential, authentication_policy=authentication_policy)LogsQueryClientstöder vanligtvis endast autentisering med autentiseringsuppgifter för Microsoft Entra-token. Vi kan dock skicka en anpassad autentiseringsprincip för att aktivera användning av API-nycklar. På så sätt kan klienten köra frågor mot demoarbetsytan. Tillgängligheten och åtkomsten till den här demoarbetsytan kan komma att ändras, så vi rekommenderar att du använder din egen Log Analytics-arbetsyta.Definiera en hjälpfunktion med namnet
query_logs_workspace, för att köra en viss fråga på Log Analytics-arbetsytan och returnera resultatet som en Pandas DataFrame.import pandas as pd import plotly.express as px from azure.monitor.query import LogsQueryStatus from azure.core.exceptions import HttpResponseError def query_logs_workspace(query): try: response = logs_query_client.query_workspace(LOGS_WORKSPACE_ID, query, timespan=None) if response.status == LogsQueryStatus.PARTIAL: error = response.partial_error data = response.partial_data print(error.message) elif response.status == LogsQueryStatus.SUCCESS: data = response.tables for table in data: my_data = pd.DataFrame(data=table.rows, columns=table.columns) except HttpResponseError as err: print("something fatal happened") print (err) return my_data
2. Utforska och visualisera data från Log Analytics-arbetsytan i anteckningsboken
Nu ska vi titta på vissa data på arbetsytan genom att köra en fråga från notebook-filen:
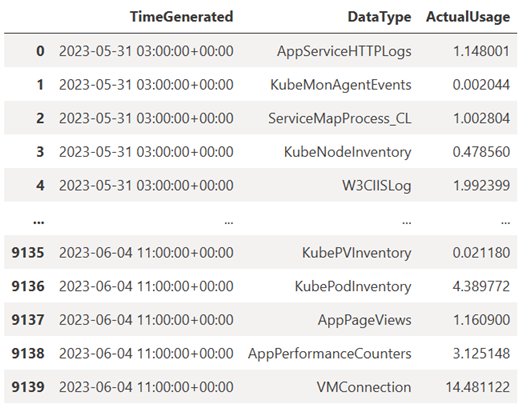
Den här frågan kontrollerar hur mycket data (i Megabyte) som du har matat in i var och en av tabellerna (datatyperna) på Din Log Analytics-arbetsyta varje timme under den senaste veckan:
TABLE = "Usage" QUERY = f""" let starttime = 7d; // Start date for the time series, counting back from the current date let endtime = 0d; // today {TABLE} | project TimeGenerated, DataType, Quantity | where TimeGenerated between (ago(starttime)..ago(endtime)) | summarize ActualUsage=sum(Quantity) by TimeGenerated=bin(TimeGenerated, 1h), DataType """ df = query_logs_workspace(QUERY) display(df)Den resulterande DataFrame visar timinmatningen i var och en av tabellerna på Log Analytics-arbetsytan:
Nu ska vi visa data som ett diagram som visar användning per timme för olika datatyper över tid, baserat på Pandas DataFrame:
df = df.sort_values(by="TimeGenerated") graph = px.line(df, x='TimeGenerated', y="ActualUsage", color='DataType', title="Usage in the last week - All data types") graph.show()Det resulterande diagrammet ser ut så här:
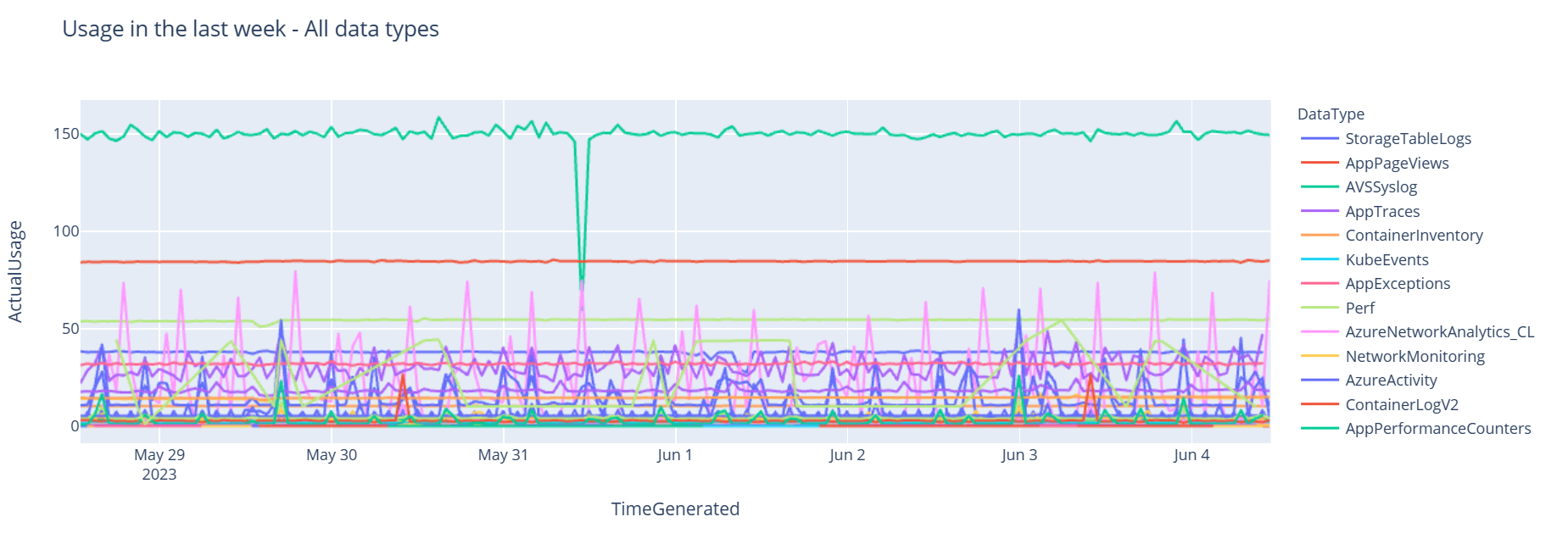
Du har frågat och visualiserat loggdata från Log Analytics-arbetsytan i notebook-filen.

3. Analysera data
Som ett enkelt exempel tar vi de första fem raderna:
analyzed_df = df.head(5)
Ett exempel på hur du implementerar maskininlärningstekniker för att analysera data i Azure Monitor-loggar finns i den här exempelanteckningsboken: Identifiera avvikelser i Azure Monitor-loggar med hjälp av maskininlärningstekniker.
4. Mata in analyserade data i en anpassad tabell på din Log Analytics-arbetsyta (valfritt)
Skicka dina analysresultat till en anpassad tabell i Log Analytics-arbetsytan för att utlösa aviseringar eller för att göra dem tillgängliga för ytterligare analys.
För att skicka data till Log Analytics-arbetsytan behöver du en anpassad tabell, slutpunkt för datainsamling, datainsamlingsregel och ett registrerat Microsoft Entra-program med behörighet att använda datainsamlingsregeln, enligt beskrivningen i Självstudie: Skicka data till Azure Monitor-loggar med API för inmatning av loggar (Azure Portal).
När du skapar din anpassade tabell:
Ladda upp den här exempelfilen för att definiera tabellschemat:
[ { "TimeGenerated": "2023-03-19T19:56:43.7447391Z", "ActualUsage": 40.1, "DataType": "AzureDiagnostics" } ]
Definiera de konstanter som du behöver för API:et för logginmatning:
os.environ['AZURE_TENANT_ID'] = "<Tenant ID>"; #ID of the tenant where the data collection endpoint resides os.environ['AZURE_CLIENT_ID'] = "<Application ID>"; #Application ID to which you granted permissions to your data collection rule os.environ['AZURE_CLIENT_SECRET'] = "<Client secret>"; #Secret created for the application os.environ['LOGS_DCR_STREAM_NAME'] = "<Custom stream name>" ##Name of the custom stream from the data collection rule os.environ['LOGS_DCR_RULE_ID'] = "<Data collection rule immutableId>" # immutableId of your data collection rule os.environ['DATA_COLLECTION_ENDPOINT'] = "<Logs ingestion URL of your endpoint>" # URL that looks like this: https://xxxx.ingest.monitor.azure.comMata in data i den anpassade tabellen på Log Analytics-arbetsytan:
from azure.core.exceptions import HttpResponseError from azure.identity import ClientSecretCredential from azure.monitor.ingestion import LogsIngestionClient import json credential = ClientSecretCredential( tenant_id=AZURE_TENANT_ID, client_id=AZURE_CLIENT_ID, client_secret=AZURE_CLIENT_SECRET ) client = LogsIngestionClient(endpoint=DATA_COLLECTION_ENDPOINT, credential=credential, logging_enable=True) body = json.loads(analyzed_df.to_json(orient='records', date_format='iso')) try: response = client.upload(rule_id=LOGS_DCR_RULE_ID, stream_name=LOGS_DCR_STREAM_NAME, logs=body) print("Upload request accepted") except HttpResponseError as e: print(f"Upload failed: {e}")Kommentar
När du skapar en tabell på Log Analytics-arbetsytan kan det ta upp till 15 minuter innan inmatade data visas i tabellen.
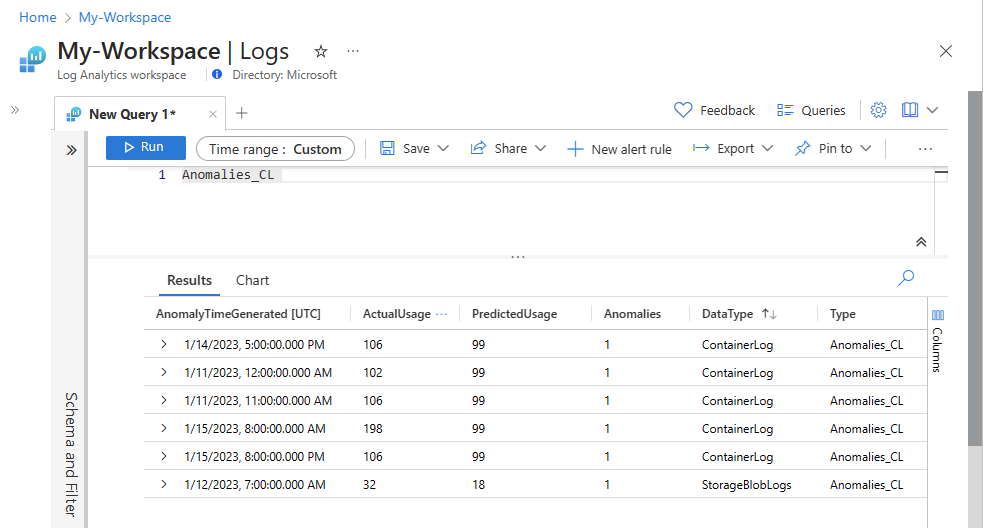
Kontrollera att data nu visas i den anpassade tabellen.

Nästa steg
Läs mer om hur du: