Självstudie: Identifiera och analysera avvikelser med hjälp av KQL-maskininlärningsfunktioner i Azure Monitor
Kusto-frågespråk (KQL) innehåller maskininlärningsoperatorer, funktioner och plugin-program för tidsserieanalys, avvikelseidentifiering, prognostisering och rotorsaksanalys. Använd dessa KQL-funktioner för att utföra avancerad dataanalys i Azure Monitor utan att behöva exportera data till externa maskininlärningsverktyg.
I den här självstudien lär du dig att:
- Skapa en tidsserie
- Identifiera avvikelser i en tidsserie
- Justera inställningarna för avvikelseidentifiering för att förfina resultaten
- Analysera rotorsaken till avvikelser
Kommentar
Den här självstudien innehåller länkar till en Log Analytics-demomiljö där du kan köra KQL-frågeexemplen. Data i demomiljön är dynamiska, så frågeresultaten är inte desamma som frågeresultaten som visas i den här artikeln. Du kan dock implementera samma KQL-frågor och huvudnamn i din egen miljö och alla Azure Monitor-verktyg som använder KQL.
Förutsättningar
- Ett Azure-konto med en aktiv prenumeration. Skapa ett konto utan kostnad.
- En arbetsyta med loggdata.
Behörigheter som krävs
Du måste ha Microsoft.OperationalInsights/workspaces/query/*/read behörighet till de Log Analytics-arbetsytor som du frågar efter, till exempel den inbyggda rollen Log Analytics Reader.
Skapa en tidsserie
Använd KQL-operatorn make-series för att skapa en tidsserie.
Nu ska vi skapa en tidsserie baserat på loggar i tabellen Användning, som innehåller information om hur mycket data varje tabell i en arbetsyta matar in varje timme, inklusive fakturerbara och icke-fakturerbara data.
Den här frågan använder make-series för att kartlägga den totala mängden fakturerbara data som matas in av varje tabell på arbetsytan varje dag under de senaste 21 dagarna:
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
I det resulterande diagrammet kan du tydligt se några avvikelser , till exempel i datatyperna AzureDiagnostics och SecurityEvent :
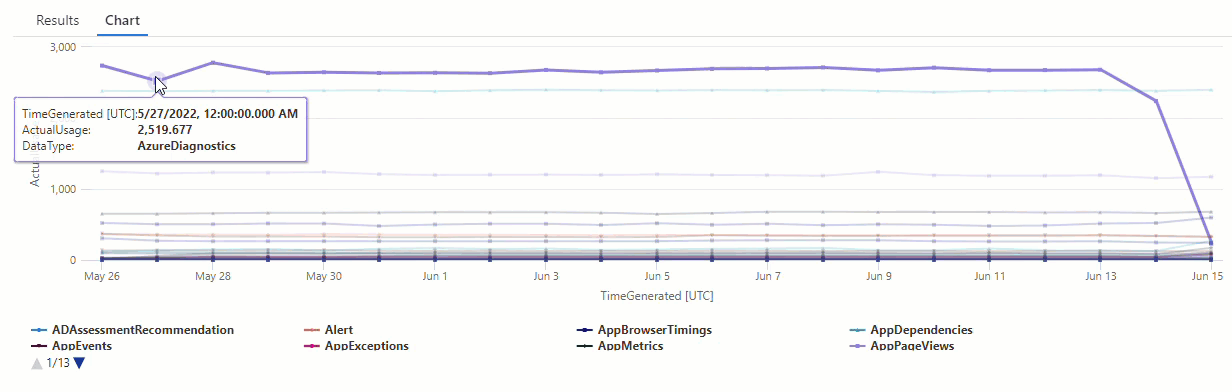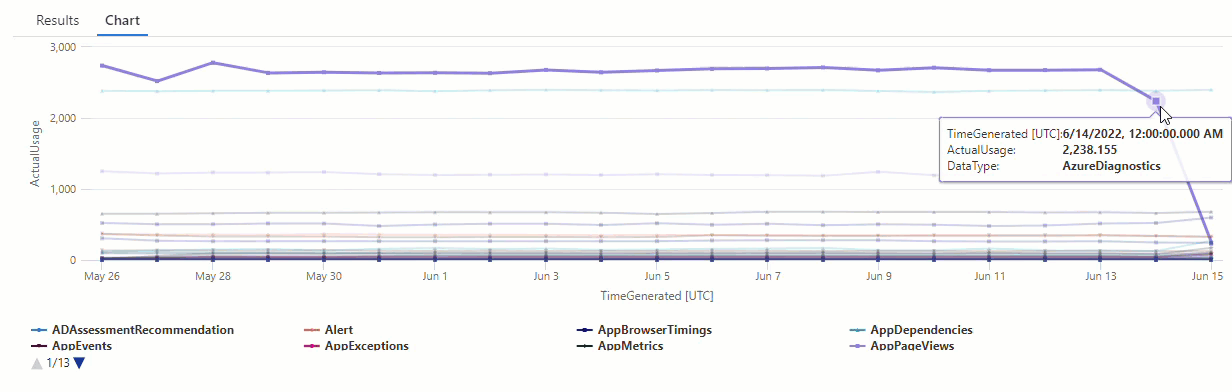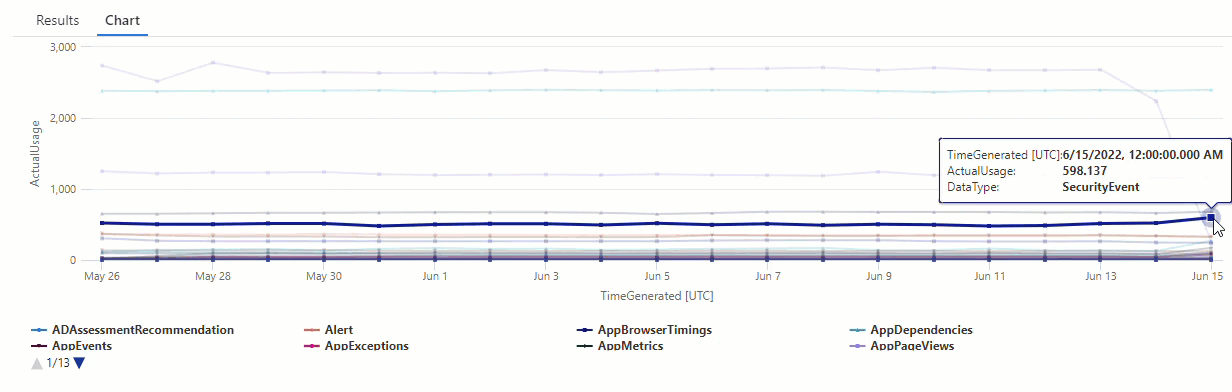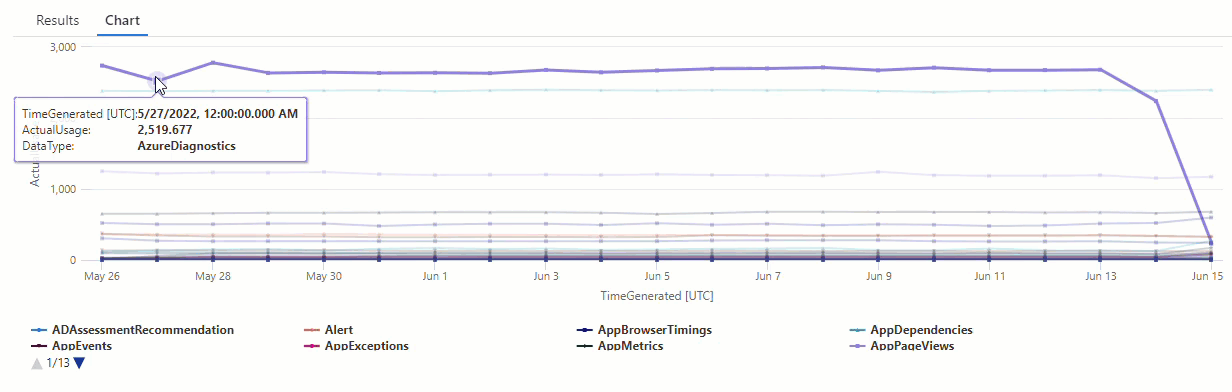
Nu ska vi använda en KQL-funktion för att lista alla avvikelser i en tidsserie.
Kommentar
Mer information om make-series syntax och användning finns i operatorn make-series.
Hitta avvikelser i en tidsserie
Funktionen series_decompose_anomalies() tar en serie värden som indata och extraherar avvikelser.
Nu ska vi ge resultatuppsättningen för vår tidsseriefråga som indata till series_decompose_anomalies() funktionen:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Den här frågan returnerar alla användningsavvikelser för alla tabeller under de senaste tre veckorna:

Om du tittar på frågeresultatet kan du se att funktionen:
- Beräknar en förväntad daglig användning för varje tabell.
- Jämför den faktiska dagliga användningen med förväntad användning.
- Tilldelar en avvikelsepoäng till varje datapunkt, vilket anger omfattningen av avvikelsen för den faktiska användningen från förväntad användning.
- Identifierar positiva (
1) och negativa (-1) avvikelser i varje tabell.
Kommentar
Mer information om series_decompose_anomalies() syntax och användning finns i series_decompose_anomalies().
Justera inställningarna för avvikelseidentifiering för att förfina resultaten
Det är bra att granska de första frågeresultaten och göra justeringar i frågan om det behövs. Avvikande värden i indata kan påverka funktionens inlärning och du kan behöva justera funktionens inställningar för avvikelseidentifiering för att få mer exakta resultat.
Filtrera resultatet av series_decompose_anomalies() frågan efter avvikelser i AzureDiagnostics datatypen:

Resultaten visar två avvikelser den 14 juni och den 15 juni. Jämför dessa resultat med diagrammet från vår första make-series fråga, där du kan se andra avvikelser den 27 och 28 maj:

Skillnaden i resultat beror på att series_decompose_anomalies() funktionen poängsätter avvikelser i förhållande till det förväntade användningsvärdet, som funktionen beräknar baserat på det fullständiga värdeintervallet i indataserien.
Om du vill få mer förfinade resultat från funktionen exkluderar du användningen den 15 juni – vilket är en extremavvikelse jämfört med de andra värdena i serien – från funktionens inlärningsprocess.
Syntaxen för series_decompose_anomalies() funktionen är:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points anger antalet punkter i slutet av serien som ska undantas från inlärningsprocessen (regression).
Om du vill exkludera den sista datapunkten anger du Test_points till 1:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Filtrera resultatet för AzureDiagnostics datatypen:

Alla avvikelser i diagrammet från vår första make-series fråga visas nu i resultatuppsättningen.
Analysera rotorsaken till avvikelser
Genom att jämföra förväntade värden med avvikande värden kan du förstå orsaken till skillnaderna mellan de två uppsättningarna.
KQL-plugin-programmet diffpatterns() jämför två datauppsättningar med samma struktur och hittar mönster som kännetecknar skillnader mellan de två datauppsättningarna.
Den här frågan jämför AzureDiagnostics användningen den 15 juni, den extrema extremavvikelsen i vårt exempel, med tabellanvändningen andra dagar:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
Frågan identifierar varje post i tabellen som inträffar på AnomalyDate (15 juni) eller OtherDates. Plugin-programmet diffpatterns() delar sedan upp dessa datauppsättningar – med namnet A (OtherDates i vårt exempel) och B (AnomalyDate i vårt exempel) – och returnerar några mönster som bidrar till skillnaderna i de två uppsättningarna:

Om du tittar på frågeresultaten kan du se följande skillnader:
- Det finns 24 892 147 instanser av inmatning från CH1-GEARAMAAKS-resursen alla andra dagar i frågetidsintervallet och ingen datainmatning från den här resursen den 15 juni. Data från CH1-GEARAMAAKS-resursen står för 73,36 % av den totala inmatningen andra dagar i frågetidsintervallet och 0 % av den totala inmatningen den 15 juni.
- Det finns 2 168 448 instanser av inmatning från NSG-TESTSQLMI519 resursen alla andra dagar i frågetidsintervallet och 110 544 instanser av inmatning från den här resursen den 15 juni. Data från NSG-TESTSQLMI519-resursen står för 6,39 % av den totala inmatningen andra dagar i frågetidsintervallet och 25,61 % av inmatningen den 15 juni.
Observera att det i genomsnitt finns 108 422 instanser av inmatning från NSG-TESTSQLMI519 resursen under de 20 dagar som utgör den andra perioden (dividera 2 168 448 med 20). Därför skiljer sig inmatningen från NSG-TESTSQLMI519 resursen den 15 juni inte nämnvärt från inmatningen från den här resursen andra dagar. Men eftersom det inte finns någon inmatning från CH1-GEARAMAAKS den 15 juni utgör inmatningen från NSG-TESTSQLMI519 en betydligt större procentandel av den totala inmatningen på avvikelsedatumet jämfört med andra dagar.
Kolumnen PercentDiffAB visar den absoluta procentuella skillnaden mellan A och B (|PercentA – PercentB|), som är huvudmåttet på skillnaden mellan de två uppsättningarna. Som standard diffpatterns() returnerar plugin-programmet skillnaden på över 5 % mellan de två datauppsättningarna, men du kan justera det här tröskelvärdet. Om du till exempel bara vill returnera skillnader på 20 % eller mer mellan de två datauppsättningarna kan du ange | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) i frågan ovan. Frågan returnerar nu bara ett resultat:

Kommentar
Mer information om diffpatterns() syntax och användning finns i plugin-programmet för diffmönster.
Nästa steg
Läs mer om: