Skapa volymer i Azure Stack HCI- och Windows Server-kluster
Gäller för: Azure Stack HCI, versionerna 22H2 och 21H2; Windows Server 2022, Windows Server 2019, Windows Server 2016
Viktigt!
Azure Stack HCI är nu en del av Azure Local. Namnbytet av produktdokumentation pågår. Äldre versioner av Azure Stack HCI, till exempel 22H2, fortsätter dock att referera till Azure Stack HCI och återspeglar inte namnändringen. Läs mer.
Den här artikeln beskriver hur du skapar volymer i ett kluster med hjälp av Windows Admin Center och Windows PowerShell, hur du arbetar med filer på volymerna och hur du aktiverar deduplicering och komprimering, integritetskontrollsummor eller BitLocker-kryptering på volymer. Information om hur du skapar volymer och konfigurerar replikering för stretchkluster finns i Skapa stretchvolymer.
Dricks
Om du inte redan har gjort det kan du kolla in Planera volymer först.
När du skapar volymer i ett kluster med en nod måste du använda PowerShell. Se Skapa volymer med PowerShell.
Skapa en dubbelriktad eller trevägsspeglingsvolym
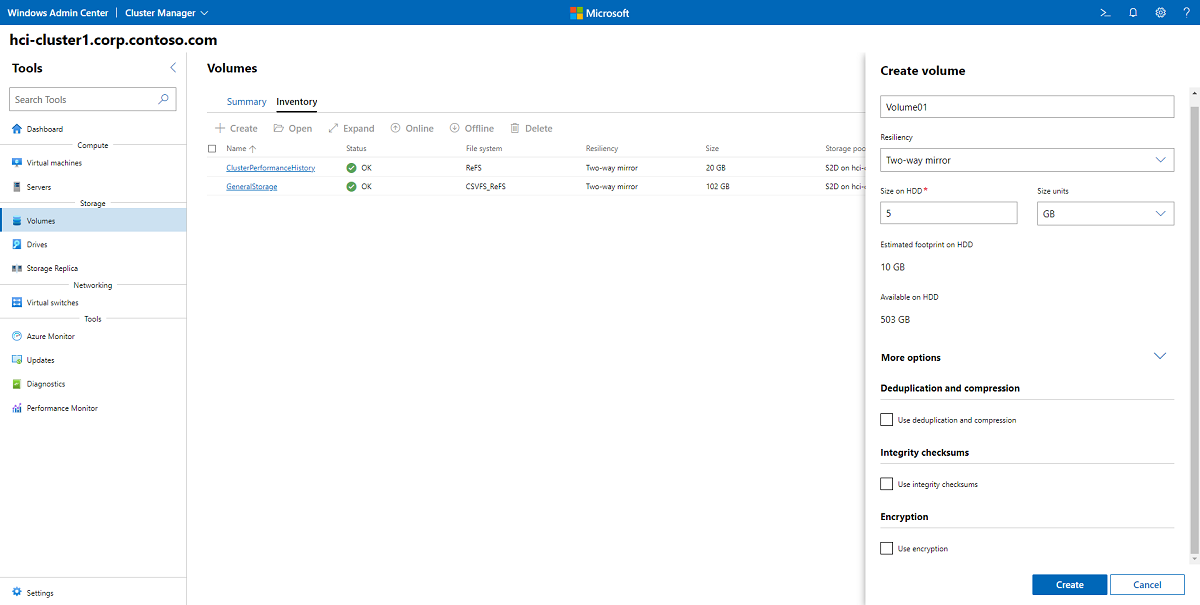
Så här skapar du en dubbelriktad eller trevägsspeglingsvolym med Hjälp av Windows Admin Center:
I Administrationscenter för Windows ansluter du till ett kluster och väljer sedan Volymer i fönstret Verktyg .
På sidan Volymer väljer du fliken Inventering och väljer sedan Skapa.
I fönstret Skapa volym anger du ett namn för volymen.
I Återhämtning väljer du Tvåvägsspegling eller Trevägsspegling beroende på antalet servrar i klustret.
I Storlek på HDD anger du volymens storlek. Till exempel 5 TB (terabyte).
Under Fler alternativ kan du använda kryssrutorna för att aktivera deduplicering och komprimering, integritetskontrollsummor eller BitLocker-kryptering.
Välj Skapa.

Beroende på storleken kan det ta några minuter att skapa volymen. Meddelanden i det övre högra hörnet meddelar dig när volymen skapas. Den nya volymen visas sedan i inventeringslistan.
Skapa en speglingsaccelererad paritetsvolym
Speglingsaccelererad paritet (MAP) minskar volymens fotavtryck på hårddisken. En trevägsspeglingsvolym skulle till exempel innebära att du behöver 30 terabyte som fotavtryck för varje 10 terabyte. Om du vill minska kostnaderna för fotavtryck skapar du en volym med speglingsaccelererad paritet. Detta minskar fotavtrycket från 30 terabyte till bara 22 terabyte, även med endast 4 servrar, genom att spegla de mest aktiva 20 procenten av data och använda paritet, vilket är mer utrymmeseffektivt, för att lagra resten. Du kan justera det här förhållandet mellan paritet och spegling för att göra prestanda kontra kapacitetsavvägning som är rätt för din arbetsbelastning. Till exempel ger 90 procent paritet och 10 procent spegling mindre prestanda men effektiviserar fotavtrycket ytterligare.
Kommentar
Speglingsaccelererade paritetsvolymer kräver ReFS (Resilient File System).
Så här skapar du en volym med speglingsaccelererad paritet i Administrationscenter för Windows:
- I Administrationscenter för Windows ansluter du till ett kluster och väljer sedan Volymer i fönstret Verktyg .
- På sidan Volymer väljer du fliken Inventering och väljer sedan Skapa.
- I fönstret Skapa volym anger du ett namn för volymen.
- I Återhämtning väljer du Speglingsaccelererad paritet.
- I Paritetsprocent väljer du procentandelen paritet.
- Under Fler alternativ kan du använda kryssrutorna för att aktivera deduplicering och komprimering, integritetskontrollsummor eller BitLocker-kryptering.
- Välj Skapa.
Öppna volymen och lägg till filer
Så här öppnar du en volym och lägger till filer på volymen i Administrationscenter för Windows:
I Administrationscenter för Windows ansluter du till ett kluster och väljer sedan Volymer i fönstret Verktyg .
På sidan Volymer väljer du fliken Inventering .
I listan med volymer väljer du namnet på den volym som du vill öppna.
På sidan volyminformation kan du se sökvägen till volymen.
Längst upp på sidan väljer du Öppna. Då startas verktyget Filer i Administrationscenter för Windows.
Navigera till volymens sökväg. Här kan du bläddra bland filerna i volymen.
Välj Ladda upp och välj sedan en fil som ska laddas upp.
Använd bakåtknappen i webbläsaren för att gå tillbaka till fönstret Verktyg i Administrationscenter för Windows.
Aktivera deduplicering och komprimering
Deduplicering och komprimering hanteras per volym. Deduplicering och komprimering använder en efterbearbetningsmodell, vilket innebär att du inte ser några besparingar förrän den körs. När det gör det fungerar det över alla filer, även de som fanns där från tidigare.
Mer information finns i Aktivera volymkryptering, deduplicering och komprimering
Skapa volymer med Windows PowerShell
Starta först Windows PowerShell från Start-menyn i Windows. Vi rekommenderar att du använder cmdleten New-Volume för att skapa volymer för Azure Stack HCI. Det ger den snabbaste och enklaste upplevelsen. Den här enkla cmdleten skapar automatiskt den virtuella disken, partitioner och formaterar den, skapar volymen med matchande namn och lägger till den i klusterdelade volymer – allt i ett enkelt steg.
Cmdleten New-Volume har fyra parametrar som du alltid behöver ange:
FriendlyName: Valfri sträng, till exempel "Volume1"
FileSystem: Antingen CSVFS_ReFS (rekommenderas för alla volymer, krävs för speglingsaccelererade paritetsvolymer) eller CSVFS_NTFS
StoragePoolFriendlyName: Namnet på din lagringspool, till exempel "S2D på ClusterName"
Storlek: Volymens storlek, till exempel "10 TB"
Kommentar
Windows, inklusive PowerShell, räknar med binära tal (base-2), medan enheter ofta etiketteras med decimaltal (base-10). Detta förklarar varför en "en terabyte"-enhet, definierad som 1 000 000 000 000 byte, visas i Windows som ungefär "909 GB". Detta är förväntat. När du skapar volymer med New-Volume bör du ange parametern Storlek i binära tal (base-2). Om du till exempel anger "909 GB" eller "0,909495 TB" skapas en volym på cirka 1 000 000 000 000 byte.
Exempel: Med 1 till 3 servrar
Om distributionen bara har en eller två servrar kommer Lagringsutrymmen Direct automatiskt att använda tvåvägsspegling för återhämtning. Om distributionen bara har tre servrar använder den automatiskt trevägsspegling.
New-Volume -FriendlyName "Volume1" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 1TB
Exempel: Med 4+ servrar
Om du har fyra eller fler servrar kan du använda den valfria parametern ResiliencySettingName för att välja din återhämtningstyp.
- ResiliencySettingName: Antingen Spegling eller Paritet.
I följande exempel använder "Volume2" trevägsspegling och "Volume3" använder dubbel paritet (kallas ofta "raderingskodning").
New-Volume -FriendlyName "Volume2" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 1TB -ResiliencySettingName Mirror
New-Volume -FriendlyName "Volume3" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 1TB -ResiliencySettingName Parity
Använda lagringsnivåer
I distributioner med tre typer av enheter kan en volym sträcka sig över nivåerna SSD och HDD för att delvis finnas på var och en. På samma sätt kan en volym i distributioner med fyra eller flera servrar blanda spegling och dubbel paritet för att delvis finnas på var och en.
För att hjälpa dig att skapa sådana volymer tillhandahåller Azure Stack HCI standardnivåmallar som kallas MirrorOn MediaType och NestedMirrorOnMediaType (för prestanda) och ParityOnMediaType och NestedParityOnMediaType (för kapacitet), där MediaType är HDD eller SSD. Mallarna representerar lagringsnivåer baserat på medietyper och kapslar in definitioner för trevägsspegling på de snabbare kapacitetsenheterna (om tillämpligt) och dubbel paritet på långsammare kapacitetsenheter (om tillämpligt).
Kommentar
Lagringsbusslagercache (SBL) stöds inte i konfiguration av en enskild server. Alla konfigurationer av enkel lagringstyp (till exempel all-NVMe eller all-SSD) är den enda lagringstyp som stöds för en enskild server.
Kommentar
På Lagringsutrymmen Direct-kluster som körs på tidigare versioner av Windows Server 2016 kallades standardnivåmallarna bara prestanda och kapacitet.
Du kan se lagringsnivåer genom att köra cmdleten Get-StorageTier på valfri server i klustret.
Get-StorageTier | Select FriendlyName, ResiliencySettingName, PhysicalDiskRedundancy
Om du till exempel har ett kluster med två noder med endast HDD kan dina utdata se ut ungefär så här:
FriendlyName ResiliencySettingName PhysicalDiskRedundancy
------------ --------------------- ----------------------
NestedParityOnHDD Parity 1
Capacity Mirror 1
NestedMirrorOnHDD Mirror 3
MirrorOnHDD Mirror 1
Om du vill skapa nivåindelade volymer refererar du till dessa nivåmallar med hjälp av parametrarna StorageTierFriendlyNames och StorageTierSizes för cmdleten New-Volume . Följande cmdlet skapar till exempel en volym som blandar trevägsspegling och dubbel paritet i 30:70 proportioner.
New-Volume -FriendlyName "Volume1" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -StorageTierFriendlyNames MirrorOnHDD, Capacity -StorageTierSizes 300GB, 700GB
Upprepa efter behov för att skapa mer än en volym.
Sammanfattningstabell för lagringsnivå
Följande tabeller sammanfattar de lagringsnivåer som är/kan skapas i Azure Stack HCI och Windows Server.
NumberOfNodes: 1
| FriendlyName | MediaType | ResiliencySettingName | NumberOfDataCopies | PhysicalDiskRedundancy | NumberOfGroups | FaultDomainAwareness | ColumnIsolation | Kommentar |
|---|---|---|---|---|---|---|---|---|
| MirrorOnHDD | HDD | Spegling | 2 | 1 | 1 | PhysicalDisk | PhysicalDisk | automatiskt skapad |
| MirrorOnSSD | SSD | Spegling | 2 | 1 | 1 | PhysicalDisk | PhysicalDisk | automatiskt skapad |
| MirrorOnSCM | SCM | Spegling | 2 | 1 | 1 | PhysicalDisk | PhysicalDisk | automatiskt skapad |
| ParityOnHDD | HDD | Paritet | 1 | 1 | 1 | PhysicalDisk | PhysicalDisk | automatiskt skapad |
| ParityOnSSD | SSD | Paritet | 1 | 1 | 1 | PhysicalDisk | PhysicalDisk | automatiskt skapad |
| ParityOnSCM | SCM | Paritet | 1 | 1 | 1 | PhysicalDisk | PhysicalDisk | automatiskt skapad |
NumberOfNodes: 2
| FriendlyName | MediaType | ResiliencySettingName | NumberOfDataCopies | PhysicalDiskRedundancy | NumberOfGroups | FaultDomainAwareness | ColumnIsolation | Kommentar |
|---|---|---|---|---|---|---|---|---|
| MirrorOnHDD | HDD | Spegling | 2 | 1 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
| MirrorOnSSD | SSD | Spegling | 2 | 1 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
| MirrorOnSCM | SCM | Spegling | 2 | 1 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
| NestedMirrorOnHDD | HDD | Spegling | 4 | 3 | 1 | StorageScaleUnit | PhysicalDisk | manuell |
| NestedMirrorOnSSD | SSD | Spegling | 4 | 3 | 1 | StorageScaleUnit | PhysicalDisk | manuell |
| NestedMirrorOnSCM | SCM | Spegling | 4 | 3 | 1 | StorageScaleUnit | PhysicalDisk | manuell |
| NestedParityOnHDD | HDD | Paritet | 2 | 1 | 1 | StorageScaleUnit | PhysicalDisk | manuell |
| NestedParityOnSSD | SSD | Paritet | 2 | 1 | 1 | StorageScaleUnit | PhysicalDisk | manuell |
| NestedParityOnSCM | SCM | Paritet | 2 | 1 | 1 | StorageScaleUnit | PhysicalDisk | manuell |
NumberOfNodes: 3
| FriendlyName | MediaType | ResiliencySettingName | NumberOfDataCopies | PhysicalDiskRedundancy | NumberOfGroups | FaultDomainAwareness | ColumnIsolation | Kommentar |
|---|---|---|---|---|---|---|---|---|
| MirrorOnHDD | HDD | Spegling | 3 | 2 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
| MirrorOnSSD | SSD | Spegling | 3 | 2 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
| MirrorOnSCM | SCM | Spegling | 3 | 2 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
NumberOfNodes: 4+
| FriendlyName | MediaType | ResiliencySettingName | NumberOfDataCopies | PhysicalDiskRedundancy | NumberOfGroups | FaultDomainAwareness | ColumnIsolation | Kommentar |
|---|---|---|---|---|---|---|---|---|
| MirrorOnHDD | HDD | Spegling | 3 | 2 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
| MirrorOnSSD | SSD | Spegling | 3 | 2 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
| MirrorOnSCM | SCM | Spegling | 3 | 2 | 1 | StorageScaleUnit | PhysicalDisk | automatiskt skapad |
| ParityOnHDD | HDD | Paritet | 1 | 2 | Automatiskt | StorageScaleUnit | StorageScaleUnit | automatiskt skapad |
| ParityOnSSD | SSD | Paritet | 1 | 2 | Automatiskt | StorageScaleUnit | StorageScaleUnit | automatiskt skapad |
| ParityOnSCM | SCM | Paritet | 1 | 2 | Automatiskt | StorageScaleUnit | StorageScaleUnit | automatiskt skapad |
Kapslade återhämtningsvolymer
Kapslad återhämtning gäller endast för tvåserverkluster som kör Azure Stack HCI eller Windows Server 2022 eller Windows Server 2019. Du kan inte använda kapslad återhämtning om klustret har tre eller fler servrar, eller om klustret kör Windows Server 2016. Kapslad återhämtning gör det möjligt för ett tvåserverkluster att klara flera maskinvarufel samtidigt utan att lagringstillgängligheten går förlorad, vilket gör att användare, appar och virtuella datorer kan fortsätta att köras utan avbrott. Mer information finns i Kapslad återhämtning för Lagringsutrymmen direct- och planvolymer: välja återhämtningstyp.
Du kan använda välbekanta lagrings-cmdletar i PowerShell för att skapa volymer med kapslad återhämtning enligt beskrivningen i följande avsnitt.
Steg 1: Skapa mallar på lagringsnivå (endast Windows Server 2019)
Windows Server 2019 kräver att du skapar nya mallar på lagringsnivå med hjälp av cmdleten New-StorageTier innan du skapar volymer. Du behöver bara göra detta en gång, och sedan kan varje ny volym du skapar referera till dessa mallar.
Kommentar
Om du kör Windows Server 2022, Azure Stack HCI 21H2 eller Azure Stack HCI 20H2 kan du hoppa över det här steget.
Ange vilka -MediaType kapacitetsenheter du vill och, om du vill, valfritt -FriendlyName . Ändra inte andra parametrar.
Om dina kapacitetsenheter till exempel är hårddiskar (HDD) startar du PowerShell som administratör och kör följande cmdletar.
Så här skapar du en NestedMirror-nivå:
New-StorageTier -StoragePoolFriendlyName S2D* -FriendlyName NestedMirrorOnHDD -ResiliencySettingName Mirror -MediaType HDD -NumberOfDataCopies 4
Så här skapar du en NestedParity-nivå:
New-StorageTier -StoragePoolFriendlyName S2D* -FriendlyName NestedParityOnHDD -ResiliencySettingName Parity -MediaType HDD -NumberOfDataCopies 2 -PhysicalDiskRedundancy 1 -NumberOfGroups 1 -FaultDomainAwareness StorageScaleUnit -ColumnIsolation PhysicalDisk
Om dina kapacitetsenheter är SSD (Solid State Drives) anger du -MediaType till SSD i stället och ändrar -FriendlyName till *OnSSD. Ändra inte andra parametrar.
Dricks
Kontrollera att Get-StorageTier nivåerna har skapats.
Steg 2: Skapa kapslade volymer
Skapa nya volymer med hjälp av cmdleten New-Volume .
Kapslad dubbelriktad spegling
Om du vill använda kapslad dubbelriktad spegling refererar du till nivåmallen
NestedMirroroch anger storleken. Till exempel:New-Volume -StoragePoolFriendlyName S2D* -FriendlyName Volume01 -StorageTierFriendlyNames NestedMirrorOnHDD -StorageTierSizes 500GBOm dina kapacitetsenheter är SSD (Solid State Drives) ändrar du
-StorageTierFriendlyNamestill*OnSSD.Kapslad speglingsaccelererad paritet
Om du vill använda kapslad speglingsaccelererad paritet refererar du till både
NestedMirrormallarna ochNestedParitynivåmallarna och anger två storlekar, en för varje del av volymen (spegling först, paritet sekund). Om du till exempel vill skapa en volym på 500 GB som är 20 % kapslad dubbelriktad spegling och 80 % kapslad paritet kör du:New-Volume -StoragePoolFriendlyName S2D* -FriendlyName Volume02 -StorageTierFriendlyNames NestedMirrorOnHDD, NestedParityOnHDD -StorageTierSizes 100GB, 400GBOm dina kapacitetsenheter är SSD (Solid State Drives) ändrar du
-StorageTierFriendlyNamestill*OnSSD.
Steg 3: Fortsätt i Administrationscenter för Windows
Volymer som använder kapslad återhämtning visas i Windows Administrationscenter med tydlig etikettering, som i följande skärmbild. När de har skapats kan du hantera och övervaka dem med Hjälp av Windows Admin Center precis som andra volymer i Lagringsutrymmen Direct.

Valfritt: Utöka till cacheenheter
Med sina standardinställningar skyddar kapslad återhämtning mot förlust av flera kapacitetsenheter samtidigt, eller en server och en kapacitetsenhet samtidigt. Om du vill utöka det här skyddet till cacheenheter finns det ett annat att tänka på: eftersom cacheenheter ofta tillhandahåller läs- och skrivcachelagring för flera kapacitetsenheter, är det enda sättet att se till att du kan tolerera förlust av en cacheenhet när den andra servern är nere att inte cachelagra skrivningar, men det påverkar prestanda.
För att åtgärda det här scenariot erbjuder Lagringsutrymmen Direct alternativet att automatiskt inaktivera skrivcachelagring när en server i ett kluster med två servrar är nere och sedan återaktivera skrivcachelagring när servern är säkerhetskopierad. Om du vill tillåta rutinmässiga omstarter utan prestandapåverkan inaktiveras inte skrivcachelagring förrän servern har varit nere i 30 minuter. När skrivcachelagring har inaktiverats skrivs innehållet i skrivcachen till kapacitetsenheter. Därefter kan servern tolerera en misslyckad cacheenhet på onlineservern, men läsningar från cacheminnet kan fördröjas eller misslyckas om en cacheenhet misslyckas.
Kommentar
För ett fysiskt system med alla cacheminnen (en enda medietyp) behöver du inte överväga automatisk inaktivering av skrivcachelagring när en server i ett kluster med två servrar är nere. Du behöver bara tänka på detta med SBL-cachen (Storage Bus Layer), som endast krävs om du använder hårddiskar.
(Valfritt) Om du vill inaktivera skrivcachelagring automatiskt när en server i ett kluster med två servrar är nere startar du PowerShell som administratör och kör:
Get-StorageSubSystem Cluster* | Set-StorageHealthSetting -Name "System.Storage.NestedResiliency.DisableWriteCacheOnNodeDown.Enabled" -Value "True"
När värdet är True är cachebeteendet:
| Situation | Cachebeteende | Kan tolerera förlust av cacheenhet? |
|---|---|---|
| Båda servrarna är upp | Cachelagrar läsningar och skrivningar, fullständig prestanda | Ja |
| Servern är nere, de första 30 minuterna | Cachelagrar läsningar och skrivningar, fullständig prestanda | Nej (tillfälligt) |
| Efter de första 30 minuterna | Endast cacheläsningar, prestanda påverkas | Ja (när cachen har skrivits till kapacitetsenheter) |
Nästa steg
Relaterade ämnen och andra lagringshanteringsuppgifter finns också: