Den här artikeln beskriver designprocessen, principerna och teknikvalen för att använda Azure Synapse för att skapa en säker data lakehouse-lösning. Vi fokuserar på säkerhetsöverväganden och viktiga tekniska beslut.
Apache®, Apache Spark® och flamlogotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder. Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Arkitektur
Följande diagram visar arkitekturen för data lakehouse-lösningen. Den är utformad för att kontrollera interaktionerna mellan tjänsterna för att minska säkerhetshoten. Lösningarna varierar beroende på funktions- och säkerhetskrav.

Ladda ned en Visio-fil med den här arkitekturen.
Dataflöde
Dataflödet för lösningen visas i följande diagram:

- Data laddas upp från datakällan till datalandningszonen, antingen till Azure Blob Storage eller till en filresurs som tillhandahålls av Azure Files. Data laddas upp av ett batchuppladdningsprogram eller system. Strömmande data samlas in och lagras i Blob Storage med hjälp av avbildningsfunktionen i Azure Event Hubs. Det kan finnas flera datakällor. Flera olika fabriker kan till exempel ladda upp sina driftdata. Information om hur du skyddar åtkomsten till Blob Storage, filresurser och andra lagringsresurser finns i Säkerhetsrekommendationer för Blob Storage och Planering för en Azure Files-distribution.
- Datafilens ankomst utlöser Azure Data Factory för att bearbeta data och lagra dem i datasjön i kärndatazonen. Att ladda upp data till kärndatazonen i Azure Data Lake skyddar mot dataexfiltrering.
- Azure Data Lake lagrar rådata som hämtas från olika källor. Det skyddas av brandväggsregler och virtuella nätverk. Den blockerar alla anslutningsförsök som kommer från det offentliga Internet.
- Ankomsten av data i datasjön utlöser Azure Synapse-pipelinen, eller så kör en tidsutlösare ett databearbetningsjobb. Apache Spark i Azure Synapse aktiveras och kör ett Spark-jobb eller en notebook-fil. Det samordnar också dataprocessflödet i data lakehouse. Azure Synapse-pipelines konverterar data från zonen Brons till silverzonen och sedan till guldzonen.
- Ett Spark-jobb eller en notebook-fil kör databearbetningsjobbet. Datakuration eller ett maskininlärningsträningsjobb kan också köras i Spark. Strukturerade data i guldzonen lagras i Delta Lake-format .
- En serverlös SQL-pool skapar externa tabeller som använder data som lagras i Delta Lake. Den serverlösa SQL-poolen har en kraftfull och effektiv SQL-frågemotor och kan stödja traditionella SQL-användarkonton eller Microsoft Entra-användarkonton.
- Power BI ansluter till den serverlösa SQL-poolen för att visualisera data. Den skapar rapporter eller instrumentpaneler med hjälp av data i data lakehouse.
- Dataanalytiker eller forskare kan logga in på Azure Synapse Studio för att:
- Förbättra data ytterligare.
- Analysera för att få affärsinsikter.
- Träna maskininlärningsmodellen.
- Företagsprogram ansluter till en serverlös SQL-pool och använder data för att stödja andra affärsdriftskrav.
- Azure Pipelines kör CI/CD-processen som automatiskt skapar, testar och distribuerar lösningen. Den är utformad för att minimera mänsklig inblandning under distributionsprocessen.
Komponenter
Följande är de viktigaste komponenterna i den här data lakehouse-lösningen:
- Azure Synapse
- Azure Files
- Event Hubs
- Blob Storage
- Azure Data Lake Storage
- Azure DevOps
- Power BI
- Data Factory
- Azure Bastion
- Azure Monitor
- Microsoft Defender för molnet
- Azure Key Vault
Alternativ
- Om du behöver databearbetning i realtid kan du i stället för att lagra enskilda filer i datalandningszonen använda Apache Structured Streaming för att ta emot dataströmmen från Event Hubs och bearbeta den.
- Om data har en komplex struktur och kräver komplexa SQL-frågor bör du överväga att lagra dem i en dedikerad SQL-pool i stället för en serverlös SQL-pool.
- Om data innehåller många hierarkiska datastrukturer– till exempel en stor JSON-struktur – kanske du vill lagra dem i Azure Synapse Data Explorer.
Information om scenario
Azure Synapse Analytics är en mångsidig dataplattform som stöder lagring av företagsdata, dataanalys i realtid, pipelines, databearbetning i tidsserier, maskininlärning och datastyrning. För att stödja dessa funktioner integrerar den flera olika tekniker, till exempel:
- Informationslager i företagsklass
- Serverlös SQL-pool
- Apache Spark
- Pipelines
- Data Explorer
- Maskininlärningsfunktioner
- Microsoft Purview enhetlig datastyrning
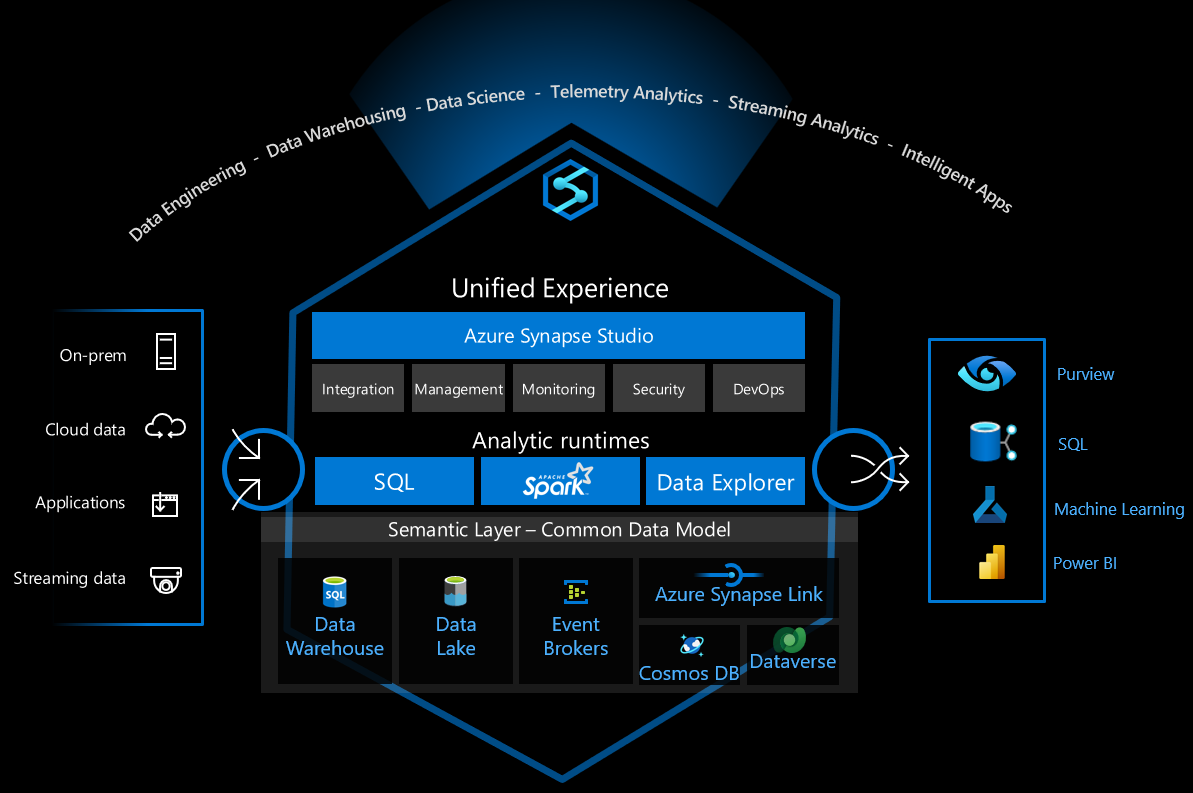
Dessa funktioner öppnar många möjligheter, men det finns många tekniska val att göra för att på ett säkert sätt konfigurera infrastrukturen för säker användning.
Den här artikeln beskriver designprocessen, principerna och teknikvalen för att använda Azure Synapse för att skapa en säker data lakehouse-lösning. Vi fokuserar på säkerhetsöverväganden och viktiga tekniska beslut. Lösningen använder följande Azure-tjänster:
- Azure Synapse
- Serverlösa SQL-pooler i Azure Synapse
- Apache Spark i Azure Synapse Analytics
- Azure Synapse-pipelines
- Azure Data Lake
- Azure DevOps.
Målet är att ge vägledning om att skapa en säker och kostnadseffektiv data lakehouse-plattform för företagsanvändning och att få teknikerna att fungera sömlöst och säkert tillsammans.
Potentiella användningsfall
Ett datasjöhus är en modern datahanteringsarkitektur som kombinerar funktionerna för kostnadseffektivitet, skala och flexibilitet i en datasjö med data- och transaktionshanteringsfunktionerna i ett informationslager. Ett datasjöhus kan hantera en stor mängd data och stödja business intelligence- och maskininlärningsscenarier. Den kan också bearbeta data från olika datastrukturer och datakällor. Mer information finns i Vad är Databricks Lakehouse?.
Några vanliga användningsfall för lösningen som beskrivs här är:
- Analys av IoT-telemetri (Internet of Things)
- Automatisering av smarta fabriker (för tillverkning)
- Spåra konsumentaktiviteter och beteende (för detaljhandel)
- Hantera säkerhetsincidenter och händelser
- Övervaka programloggar och programbeteende
- Bearbetning och affärsanalys av halvstrukturerade data
Design på hög nivå
Den här lösningen fokuserar på säkerhetsdesign och implementeringsmetoder i arkitekturen. Serverlös SQL-pool, Apache Spark i Azure Synapse, Azure Synapse-pipelines, Data Lake Storage och Power BI är de viktigaste tjänsterna som används för att implementera data lakehouse-mönstret.
Här är designarkitekturen för lösningar på hög nivå:

Välj säkerhetsfokus
Vi startade säkerhetsdesignen med hjälp av verktyget Hotmodellering. Verktyget hjälpte oss:
- Kommunicera med systemintressenter om potentiella risker.
- Definiera förtroendegränsen i systemet.
Baserat på hotmodelleringsresultaten har vi gjort följande säkerhetsområden till våra främsta prioriteringar:
- Identitets- och åtkomstkontroll
- Nätverksskydd
- DevOps-säkerhet
Vi har utformat säkerhetsfunktionerna och infrastrukturändringarna för att skydda systemet genom att minimera de viktiga säkerhetsrisker som identifierats med dessa främsta prioriteringar.
Mer information om vad som ska kontrolleras och beaktas finns i:
- Säkerhet i Microsoft Cloud Adoption Framework för Azure
- Åtkomstkontroll
- Tillgångsskydd
- Innovationsskydd
Nätverks- och tillgångsskyddsplan
En av de viktigaste säkerhetsprinciperna i Cloud Adoption Framework är den Nolltillit principen: när du utformar säkerhet för alla komponenter eller system minskar du risken för att angripare utökar sin åtkomst genom att anta att andra resurser i organisationen komprometteras.
Baserat på resultatet av hotmodellering antar lösningen distributionsrekommendationen för mikrosegmentering i nollförtroende och definierar flera säkerhetsgränser. Azure Virtual Network och Azure Synapse dataexfiltreringsskydd är de viktigaste teknikerna som används för att implementera säkerhetsgränsen för att skydda datatillgångar och kritiska komponenter.
Eftersom Azure Synapse består av flera olika tekniker måste vi:
Identifiera komponenterna i Synapse och relaterade tjänster som används i projektet.
Azure Synapse är en mångsidig dataplattform som kan hantera många olika databehandlingsbehov. Först måste vi bestämma vilka komponenter i Azure Synapse som används i projektet så att vi kan planera hur de ska skyddas. Vi måste också avgöra vilka andra tjänster som kommunicerar med dessa Azure Synapse-komponenter.
I data lakehouse-arkitekturen är de viktigaste komponenterna:
- Serverlös SQL i Azure Synapse
- Apache Spark i Azure Synapse
- Azure Synapse-pipelines
- Data Lake Storage
- Azure DevOps
Definiera de juridiska kommunikationsbeteendena mellan komponenterna.
Vi måste definiera de tillåtna kommunikationsbeteendena mellan komponenterna. Vill vi till exempel att Spark-motorn ska kommunicera direkt med den dedikerade SQL-instansen eller vill vi att den ska kommunicera via en proxy som Azure Synapse Dataintegration pipeline eller Data Lake Storage?
Baserat på principen Nolltillit blockerar vi kommunikation om det inte finns något affärsbehov för interaktionen. Vi blockerar till exempel en Spark-motor som finns i en okänd klientorganisation från att kommunicera direkt med Data Lake Storage.
Välj rätt säkerhetslösning för att framtvinga de definierade kommunikationsbeteendena.
I Azure kan flera säkerhetstekniker framtvinga de definierade beteendena för tjänstkommunikation. I Data Lake Storage kan du till exempel använda en LISTA över tillåtna IP-adresser för att styra åtkomsten till en datasjö, men du kan också välja vilka virtuella nätverk, Azure-tjänster och resursinstanser som tillåts. Varje skyddsmetod ger olika säkerhetsskydd. Välj baserat på affärsbehov och miljöbegränsningar. Konfigurationen som används i den här lösningen beskrivs i nästa avsnitt.
Implementera hotidentifiering och avancerat skydd för kritiska resurser.
För kritiska resurser är det bäst att implementera hotidentifiering och avancerat skydd. Tjänsterna hjälper till att identifiera hot och utlösa aviseringar, så att systemet kan meddela användarna om säkerhetsöverträdelser.
Överväg följande tekniker för att bättre skydda nätverk och tillgångar:
Distribuera perimeternätverk för att tillhandahålla säkerhetszoner för datapipelines
När en datapipelinearbetsbelastning kräver åtkomst till externa data och datalandningszonen är det bäst att implementera ett perimeternätverk och separera det med en pipeline för extrahering, transformering, inläsning (ETL).
Aktivera Defender för molnet för alla lagringskonton
Defender för molnet utlöser säkerhetsaviseringar när den identifierar ovanliga och potentiellt skadliga försök att komma åt eller utnyttja lagringskonton. Mer information finns i Konfigurera Microsoft Defender för lagring.
Låsa ett lagringskonto för att förhindra skadliga borttagnings- eller konfigurationsändringar
Mer information finns i Tillämpa ett Azure Resource Manager-lås på ett lagringskonto.
Arkitektur med nätverk och tillgångsskydd
I följande tabell beskrivs de definierade kommunikationsbeteenden och säkerhetstekniker som valts för den här lösningen. Alternativen baserades på de metoder som beskrivs i nätverks- och tillgångsskyddsplanen.
| Från (klient) | Till (tjänst) | Funktionssätt | Konfiguration | Kommentar | |
|---|---|---|---|---|---|
| Internet | Data Lake Storage | Neka alla | Brandväggsregel – Standard neka | Standard: "Neka" | Brandväggsregel – Standard neka |
| Azure Synapse Pipeline/Spark | Data Lake Storage | Tillåt (instans) | Virtuellt nätverk – Hanterad privat slutpunkt (Data Lake Storage) | ||
| Synapse SQL | Data Lake Storage | Tillåt (instans) | Brandväggsregel – Resursinstanser (Synapse SQL) | Synapse SQL måste få åtkomst till Data Lake Storage med hjälp av hanterade identiteter | |
| Azure Pipelines-agent | Data Lake Storage | Tillåt (instans) | Brandväggsregel – Valda virtuella nätverk Tjänstslutpunkt – Lagring |
För integreringstestning bypass: "AzureServices" (brandväggsregel) |
|
| Internet | Synapse-arbetsyta | Neka alla | Brandväggsregel | ||
| Azure Pipelines-agent | Synapse-arbetsyta | Tillåt (instans) | Virtuellt nätverk – privat slutpunkt | Kräver tre privata slutpunkter (Dev, serverlös SQL och dedikerad SQL) | |
| Synapse-hanterat virtuellt nätverk | Internet- eller obehörig Azure-klientorganisation | Neka alla | Virtuellt nätverk – Synapse-dataexfiltreringsskydd | ||
| Synapse-pipeline/Spark | Key Vault | Tillåt (instans) | Virtuellt nätverk – Hanterad privat slutpunkt (Key Vault) | Standard: "Neka" | |
| Azure Pipelines-agent | Key Vault | Tillåt (instans) | Brandväggsregel – Valda virtuella nätverk * Tjänstslutpunkt – Key Vault |
bypass: "AzureServices" (brandväggsregel) | |
| Azure Functions | Synapse serverlös SQL | Tillåt (instans) | Virtuellt nätverk – Privat slutpunkt (Synapse serverlös SQL) | ||
| Synapse-pipeline/Spark | Azure Monitor | Tillåt (instans) | Virtuellt nätverk – privat slutpunkt (Azure Monitor) |
I planen vill vi till exempel:
- Skapa en Azure Synapse-arbetsyta med ett hanterat virtuellt nätverk.
- Skydda utgående data från Azure Synapse-arbetsytor med hjälp av Azure Synapse-arbetsytor Dataexfiltreringsskydd.
- Hantera listan över godkända Microsoft Entra-klienter för Azure Synapse-arbetsytan.
- Konfigurera nätverksregler för att bevilja trafik till lagringskontot från valda virtuella nätverk, endast åtkomst och inaktivera åtkomst till offentligt nätverk.
- Använd hanterade privata slutpunkter för att ansluta det virtuella nätverket som hanteras av Azure Synapse till datasjön.
- Använd Resource Instance för att på ett säkert sätt ansluta Azure Synapse SQL till datasjön.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som du kan använda för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Säkerhet
Information om säkerhetspelare i det väldefinierade ramverket finns i Säkerhet.
Identitets- och åtkomstkontroll
Det finns flera komponenter i systemet. Var och en kräver en annan konfiguration för identitets- och åtkomsthantering (IAM). Dessa konfigurationer måste samarbeta för att ge en smidig användarupplevelse. Därför använder vi följande designvägledning när vi implementerar identitets- och åtkomstkontroll.
Välj en identitetslösning för olika åtkomstkontrolllager
- Det finns fyra olika identitetslösningar i systemet.
- SQL-konto (SQL Server)
- Tjänstens huvudnamn (Microsoft Entra-ID)
- Hanterad identitet (Microsoft Entra-ID)
- Användarkonto (Microsoft Entra-ID)
- Det finns fyra olika åtkomstkontrolllager i systemet.
- Programåtkomstlagret: välj identitetslösningen för AP-roller.
- Azure Synapse DB/Table-åtkomstskiktet: Välj identitetslösningen för roller i databaser.
- Azure Synapse får åtkomst till det externa resursskiktet: Välj identitetslösningen för att få åtkomst till externa resurser.
- Data Lake Storage-åtkomstlager: Välj identitetslösningen för att styra filåtkomsten i lagringen.

En viktig del av identitets- och åtkomstkontrollen är att välja rätt identitetslösning för varje åtkomstkontrollskikt. Principerna för säkerhetsdesign i Azure Well-Architected Framework föreslår att du använder interna kontroller och driver enkelheten. Därför använder den här lösningen slutanvändarens Microsoft Entra-användarkonto i program- och Azure Synapse DB-åtkomstskikten. Den använder de interna IAM-lösningarna från första part och ger detaljerad åtkomstkontroll. Azure Synapse-åtkomsten till det externa resursskiktet och Data Lake-åtkomstskiktet använder hanterad identitet i Azure Synapse för att förenkla auktoriseringsprocessen.
- Det finns fyra olika identitetslösningar i systemet.
Överväg åtkomst med minst privilegier
En Nolltillit vägledande princip tyder på att ge just-in-time och precis tillräckligt med åtkomst till kritiska resurser. Se Microsoft Entra Privileged Identity Management (PIM) för att förbättra säkerheten i framtiden.
Skydda länkad tjänst
Länkade tjänster definierar den anslutningsinformation som behövs för att en tjänst ska kunna ansluta till externa resurser. Det är viktigt att skydda konfigurationer av länkade tjänster.
- Skapa en länkad Azure Data Lake-tjänst med Private Link.
- Använd hanterad identitet som autentiseringsmetod i länkade tjänster.
- Använd Azure Key Vault för att skydda autentiseringsuppgifterna för åtkomst till den länkade tjänsten.

Utvärdering av säkerhetspoäng och hotidentifiering
För att förstå systemets säkerhetsstatus använder lösningen Microsoft Defender för molnet för att utvärdera infrastrukturens säkerhet och identifiera säkerhetsproblem. Microsoft Defender för molnet är ett verktyg för hantering av säkerhetsstatus och skydd mot hot. Det kan skydda arbetsbelastningar som körs i Azure, hybridplattformar och andra molnplattformar.

Du aktiverar automatiskt Defender för molnet kostnadsfria abonnemang för alla dina Azure-prenumerationer när du först besöker Defender för molnet sidor i Azure Portal. Vi rekommenderar starkt att du gör det möjligt för den att få utvärdering och förslag på molnsäkerhetsstatus. Microsoft Defender för molnet ger din säkerhetspoäng och viss vägledning för säkerhetshärdning för dina prenumerationer.
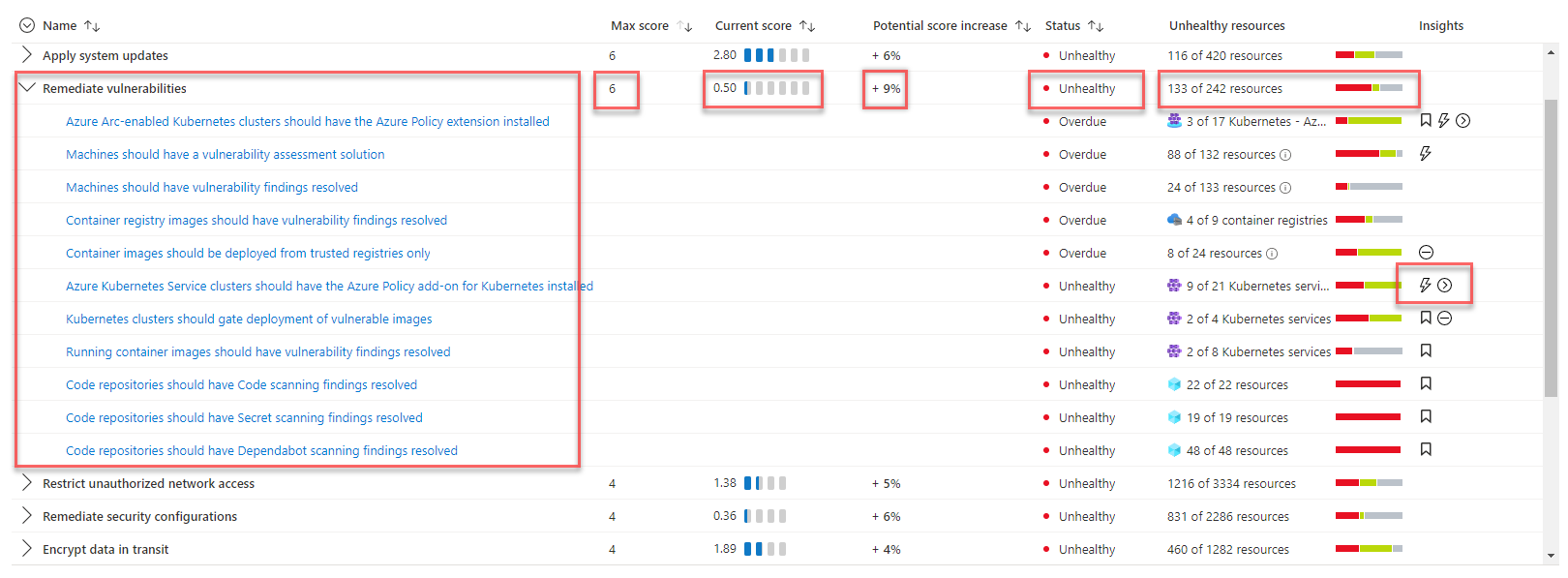
Om lösningen behöver avancerade funktioner för säkerhetshantering och hotidentifiering, till exempel identifiering och avisering av misstänkta aktiviteter, kan du aktivera skydd av molnarbetsbelastningar individuellt för olika resurser.
Kostnadsoptimering
Information om kostnadsoptimeringspelare för det välarkitekterade ramverket finns i Kostnadsoptimering.
En viktig fördel med data lakehouse-lösningen är dess kostnadseffektivitet och skalbara arkitektur. De flesta komponenter i lösningen använder förbrukningsbaserad fakturering och skalas automatiskt. I den här lösningen lagras alla data i Data Lake Storage. Du betalar bara för att lagra data om du inte kör några frågor eller bearbetar data.
Prissättningen för den här lösningen beror på användningen av följande viktiga resurser:
- Azure Synapse Serverless SQL: Använd förbrukningsbaserad fakturering, betala endast för det du använder.
- Apache Spark i Azure Synapse: Använd förbrukningsbaserad fakturering, betala endast för det du använder.
- Azure Synapse Pipelines: använd förbrukningsbaserad fakturering, betala endast för det du använder.
- Azure Data Lakes: Använd förbrukningsbaserad fakturering, betala endast för det du använder.
- Power BI: Kostnaden baseras på vilken licens du köper.
- Private Link: Använd förbrukningsbaserad fakturering, betala endast för det du använder.
Olika säkerhetsskyddslösningar har olika kostnadslägen. Du bör välja säkerhetslösningen baserat på dina affärsbehov och lösningskostnader.
Du kan använda Priskalkylatorn för Azure för att beräkna kostnaden för lösningen.
Driftsäkerhet
Information om grundpelare för driftseffektivitet i det välarkitekterade ramverket finns i Operational excellence (Driftskvalitet).
Använda en virtuell nätverksaktiverad pipelineagent med egen värd för CI/CD-tjänster
Standardagenten för Azure DevOps-pipeline stöder inte kommunikation med virtuella nätverk eftersom den använder ett mycket brett IP-adressintervall. Den här lösningen implementerar en lokalt installerad Azure DevOps-agent i det virtuella nätverket så att DevOps-processerna smidigt kan kommunicera med de andra tjänsterna i lösningen. Anslutningssträng och hemligheter för att köra CI/CD-tjänsterna lagras i ett oberoende Nyckelvalv. Under distributionsprocessen kommer den lokalt installerade agenten åt nyckelvalvet i kärndatazonen för att uppdatera resurskonfigurationer och hemligheter. Mer information finns i dokumentet Använd separata nyckelvalv . Den här lösningen använder också VM-skalningsuppsättningar för att säkerställa att DevOps-motorn automatiskt kan skalas upp och ned baserat på arbetsbelastningen.

Implementera säkerhetsgenomsökning och testning av säkerhetsrök i CI/CD-pipelinen
Ett statiskt analysverktyg för genomsökning av IaC-filer (infrastruktur som kod) kan hjälpa till att identifiera och förhindra felkonfigurationer som kan leda till säkerhets- eller efterlevnadsproblem. Säkerhetstestning av rök säkerställer att de viktiga systemsäkerhetsåtgärderna har aktiverats, vilket skyddar mot distributionsfel.
- Använd ett statiskt analysverktyg för att genomsöka IaC-mallar (infrastruktur som kod) för att identifiera och förhindra felkonfigurationer som kan leda till säkerhets- eller efterlevnadsproblem. Använd verktyg som Checkov eller Terrascan för att identifiera och förhindra säkerhetsrisker.
- Kontrollera att CD-pipelinen hanterar distributionsfel korrekt. Eventuella distributionsfel som rör säkerhetsfunktioner bör behandlas som ett kritiskt fel. Pipelinen ska försöka utföra den misslyckade åtgärden igen eller behålla distributionen.
- Verifiera säkerhetsåtgärderna i distributionspipelinen genom att köra säkerhetstestning av rök. Testning av säkerhetsrök, till exempel validering av konfigurationsstatus för distribuerade resurser eller testningsfall som undersöker kritiska säkerhetsscenarier, kan säkerställa att säkerhetsdesignen fungerar som förväntat.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Herman Wu | Senior programvarutekniker
Övriga medarbetare:
- Ian Chen | Huvudansvarig programvarutekniker
- Jose Contreras | Huvudprogramutveckling
- Roy Chan | Principal Software Engineer Manager
Nästa steg
- Dokumentation om Azure-produkter
- Andra artiklar
- Vad är Azure Synapse Analytics?
- Serverlös SQL-pool i Azure Synapse Analytics
- Apache Spark i Azure Synapse Analytics
- Pipelines och aktiviteter i Azure Data Factory och Azure Synapse Analytics
- Vad är Azure Synapse Data Explorer? (Förhandsversion)
- Maskininlärningsfunktioner i Azure Synapse Analytics
- Vad är Microsoft Purview?
- Azure Synapse Analytics och Azure Purview fungerar bättre tillsammans
- Introduktion till Azure Data Lake Storage Gen2
- Vad är Azure Data Factory?
- Bloggserie för aktuella datamönster: Data Lakehouse
- Vad är Microsoft Defender för molnet?
- Data Lakehouse, Data Warehouse och en modern dataplattformsarkitektur
- Metodtipsen för att organisera Azure Synapse-arbetsytor och lakehouse
- Förstå privata Azure Synapse-slutpunkter
- Azure Synapse Analytics – Nya insikter om datasäkerhet
- Azure-säkerhetsbaslinje för azure synapse-dedikerad SQL-pool (tidigare SQL DW)
- Cloud Network Security 101: Azure-tjänstslutpunkter jämfört med privata slutpunkter
- Konfigurera åtkomstkontroll för Azure Synapse-arbetsytan
- Ansluta till Azure Synapse Studio med Azure Private Link-hubbar
- Så här distribuerar du azure synapse-arbetsytefakter till ett hanterat VIRTUELLT NÄTVERK Azure Synapse-arbetsyta
- Kontinuerlig integrering och leverans för en Azure Synapse Analytics-arbetsyta
- Säkerhetspoäng i Microsoft Defender för molnet
- Metodtips för att använda Azure Key Vault
- Adatum Corporation-scenario för datahantering och analys i Azure