En arkitektur för stordata är utformad för att hantera datainmatning, bearbetning och analys av data som är för omfattande eller för komplicerad för traditionella databassystem. Tröskeln där organisationer går in i stordatasfären varierar beroende på kapaciteten hos användarna och deras verktyg. För vissa kan det innebära hundratals gigabyte med data, medan det för andra innebär hundratals terabyte. I takt med att verktygen för att arbeta med stordatamängder utvecklas, så ökar även innebörden av stordata. Den här termen avser alltmer det värde du kan extrahera från dina datamängder genom avancerade analyser, och inte bara storleken på data, även om de i dessa fall ofta är ganska stora.
Under åren har datalandskapet förändrats. Det du kan göra, eller förväntas göra, med data har förändrats. Kostnaden för lagring har sjunkit betydligt, medan de olika sätten att samla in data fortsätter att öka. Vissa data kommer i snabb takt, och måste hela tiden samlas in och observeras. Andra data kommer långsammare, men i mycket stora segment, ofta i form av årtionden av historiska data. Du kanske står inför ett problem med avancerad analys, eller ett som kräver maskininlärning. Det här är utmaningar som arkitekturer för stordata försöker lösa.
Stordatalösningar kännetecknas av en eller flera av följande typer av arbetsbelastningar:
- Satsvis bearbetning av vilande stordatakällor.
- Realtidsbearbetning av stordata i rörelse.
- Interaktiv utforskning av stordata.
- Förutsägelseanalys och Machine Learning.
Överväg arkitekturer för stordata när du behöver:
- Lagra och bearbeta data i volymer som är för stora för en traditionell databas.
- transformera ostrukturerade data för analys och rapportering
- samla in, bearbeta och analysera obundna dataströmmar i realtid eller med låg latens.
Komponenter i en arkitektur för stordata
I följande diagram visas de logiska komponenterna i en arkitektur för stordata. Enskilda lösningar kanske inte innehåller alla objekt i det här diagrammet.
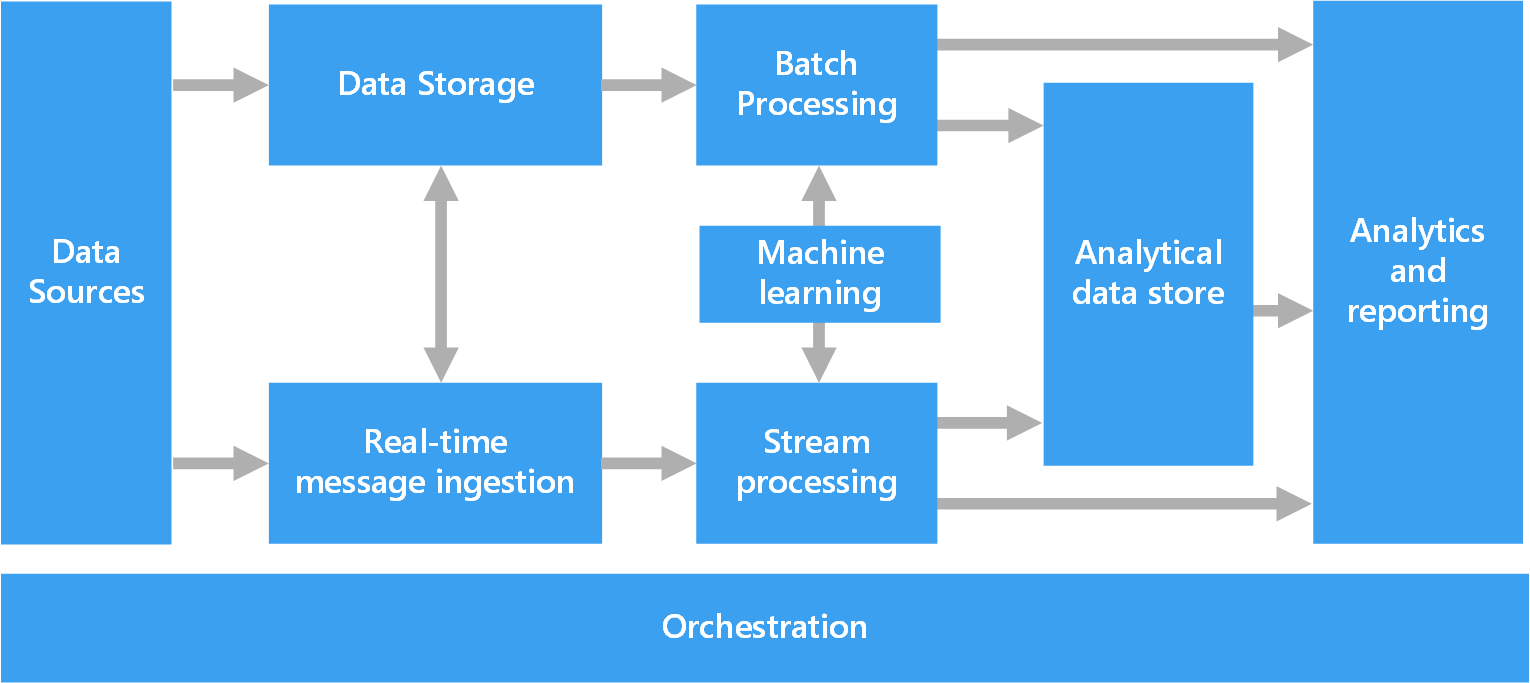
De flesta arkitekturer för stordata innehåller några av eller samtliga av följande komponenter:
Datakällor. Alla stordatalösningar utgår från en eller flera datakällor. Exempel:
- Programdatalager, till exempel relationsdatabaser.
- Statiska filer som skapas av program, till exempel loggfiler för webbservrar.
- Datakällor för realtidsdata, till exempel IoT-enheter.
Datalagring. Data för satsvisa bearbetningsåtgärder lagras vanligtvis i ett distribuerat filarkiv som kan innehålla stora volymer av stora filer i olika format. Den här typen av lager kallas ofta för en Data Lake. Exempel på alternativ för att implementera en sådan lagringslösning är Azure Data Lake Store eller blob-containrar i Azure Storage.
Batchbearbetning. Eftersom datamängderna är så stora måste en stordatalösning ofta bearbeta datafilerna genom att använda långvariga batchjobb för att filtrera, samla och förbereda data på andra sätt för analys. Sådana jobb består ofta i att läsa källfiler, bearbeta dem och skriva utdata till nya filer. Det är också möjligt att köra U-SQL i Azure Data Lake Analytics med hjälp av Hive-, Pig- eller anpassade Map/Reduce-jobb i ett HDInsight Hadoop-kluster, eller att använda Java-, Scala- eller Python-program i ett HDInsight Spark-kluster.
Inmatning av realtidsmeddelanden. Om lösningen omfattar realtidskällor måste arkitekturen innehålla en metod för att fånga in och lagra realtidsmeddelanden för bearbetning av dataströmmen. Det kan vara ett enkelt datalager, där inkommande meddelanden hamnar i en mapp för bearbetning. Många lösningar kräver dock ett inmatningsarkiv för meddelanden för att kunna fungera som meddelandebuffert, men också för att stödja skalbar bearbetning, tillförlitlig leverans och annan semantik för meddelandeköer. Den här delen av en strömningsarkitektur kallas ofta strömbuffring. Några exempel på alternativ är Azure Event Hubs, Azure IoT Hub och Kafka.
Bearbetning av dataströmmen. När du fångar in realtidsmeddelanden måste lösningen bearbeta dem genom att filtrera, samla och förbereda data på andra sätt för analys. Den bearbetade dataströmmen skrivs sedan till en utdatamottagare. Azure Stream Analytics erbjuder en tjänst för hanterad bearbetning av dataströmmen baserad på kontinuerlig körning av SQL-frågor som körs på obegränsade strömmar. Du kan också använda öppen källkod Apache-strömningstekniker som Spark Streaming i ett HDInsight-kluster.
Maskininlärning. Genom att läsa förberedda data för analys (från batch- eller dataströmbearbetning) kan maskininlärningsalgoritmer användas för att skapa modeller som kan förutsäga utfall eller klassificera data. Dessa modeller kan tränas på stora datamängder och de resulterande modellerna kan användas för att analysera nya data och göra förutsägelser. Detta kan göras med hjälp av Azure Machine Learning
Analysdatalager. Många stordatalösningar förbereder data för analys och hanterar sedan bearbetade data i ett strukturerat format som kan ta emot frågor från analysverktyg. Analysdatalagret som används för att hantera dessa frågor kan vara ett relationellt informationslager i Kimball-format, som används i de flesta traditionella Business Intelligence-lösningar (BI). Data kan även presenteras med en NoSQL-teknik för låg latens som HBase, eller en interaktiv Hive-databas som skapar en abstraktion av metadata via datafiler i det distribuerade dataarkivet. Azure Synapse Analytics är en hanterad tjänst för storskalig, molnbaserade datalagring. HDInsight stöder interaktiv Hive, HBase och Spark SQL, som även kan användas för att hantera data för analys.
Analys och rapportering. Målet för de flesta stordatalösningar är att ge insikter om data genom analys och rapportering. Vill du erbjuda användarna möjligheten att analysera data kan arkitekturen innefatta ett lager för datamodellering, till exempel en flerdimensionell OLAP-kub eller tabelldatamodellen i Azure Analysis Services. Den kan också stödja Business Intelligence som självservice med hjälp av de modellerings- och visualiseringstekniker som ingår i Microsoft Power BI eller Microsoft Excel. Analys och rapportering kan också ske i form av interaktiv datagranskning som utförs av datavetare eller dataanalytiker. För dessa scenarier stöder många Azure-tjänster analytiska notebook-filer, till exempel Jupyter, så att dessa användare kan använda sina befintliga kunskaper med Python eller Microsoft R. För storskalig datautforskning kan du använda Microsoft R Server, antingen fristående eller med Spark.
Orkestrering. De flesta stordatalösningar består av upprepade åtgärder för databearbetning inkapslade i arbetsflöden som omvandlar källdata, flyttar data mellan flera källor och mottagare, läser in bearbetade data till ett analysdatalager eller skickar resultaten direkt till en rapport eller instrumentpanel. Du kan använda en samordningsteknik som Azure Data Factory eller Apache Oozie och Sqoop för att automatisera dessa arbetsflöden.
Lambda-arkitektur
När du arbetar med mycket stora datamängder kan det ta lång tid att köra den typ av frågor som klienter behöver. De här frågorna kan inte utföras i realtid och kräver ofta algoritmer, till exempel MapReduce, som körs parallellt i hela datamängden. Resultaten lagras sedan separat från rådata och används för frågor.
En nackdel med den här metoden är att den introducerar svarstid – om bearbetningen tar några timmar kan en fråga returnera resultat som är flera timmar gamla. Helst vill du få vissa resultat i realtid (kanske med viss förlust av precision) och kombinera de resultaten med resultaten från batchanalysen.
Lambda-arkitekturen, som först togs fram av Nathan Marz, hanterar det här problemet genom att skapa två sökvägar för dataflöde. Alla data som kommer in i systemet går via de här två sökvägarna:
Ett batchlager (kall sökväg) lagrar alla inkommande data i obearbetat format och utför batchbearbetning av data. Resultatet av bearbetningen lagras som en batchvy.
Ett hastighetslager (het sökväg) analyserar data i realtid. Det här lagret är utformat för kort svarstid, på bekostnad av precision.
Batchlagret skickar till ett betjäningslager som indexerar batchvyn för effektiva frågor. Hastighetslagret uppdaterar betjäningslagret med inkrementella uppdateringar baserat på senaste data.
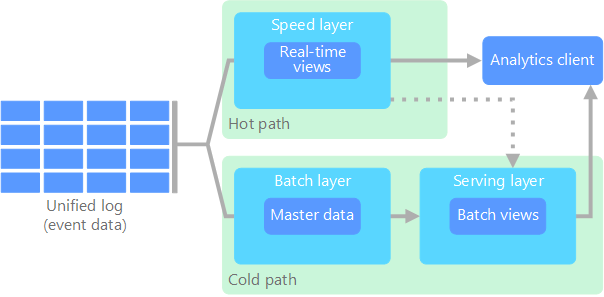
Data som flödar till den heta sökvägen begränsas av svarstidskrav som tillämpas av hastighetslagret, så att de kan bearbetas så snart som möjligt. Det kräver ofta en kompromiss med viss nivå av precision till förmån för data som är klara så snart som möjligt. Tänk dig till exempel ett IoT-scenario där ett stort antal temperatursensorer skickar telemetridata. Hastighetslagret kan användas för att bearbeta en glidande tidsperiod för inkommande data.
Data som flödar till den kalla sökvägen omfattas å andra sidan inte av samma krav på kort svarstid. Det möjliggör beräkning med hög precision i stora datamängder, vilket kan vara mycket tidsintensivt.
Slutligen konvergerar den heta och kalla sökvägen i klientprogrammet för analys. Om klienten behöver visa aktuella men potentiellt mindre exakta data i realtid, hämtas resultatet från den heta sökvägen. Annars väljs resultat från den kalla sökvägen för att visa mindre aktuella men mer exakta data. Med andra ord innehåller den heta sökvägen data under en relativt kort tidsperiod, och därefter kan resultaten uppdateras med mer exakta data från den kalla sökvägen.
Rådata som lagras på batchlagret kan inte ändras. Inkommande data läggs alltid till i befintliga data, och tidigare data skrivs aldrig över. Ändringar av värdet för ett visst datum lagras som en ny tidsstämplad händelsepost. Det möjliggör omberäkning när som helst i historiken för insamlade data. Möjligheten att omberäkna batchvyn utifrån ursprungliga rådata är viktig, eftersom det gör att nya vyer kan skapas när systemet utvecklas.
Kappa-arkitektur
En nackdel med lambda-arkitekturen är dess komplexitet. Bearbetningslogik visas på två olika platser – de kalla och heta sökvägarna – med olika ramverk. Det leder till duplicerad beräkningslogik och komplexiteten med att hantera arkitekturen för båda sökvägarna.
Kappa-arkitekturen togs fram av Jay Kreps som ett alternativ till lambda-arkitekturen. Den har samma grundläggande mål som lambda-arkitekturen, men med en viktig skillnad: Alla data flödar via en enskild sökväg, med hjälp av ett system för strömbearbetning.
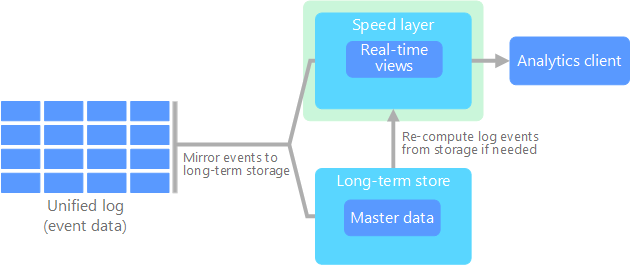
Det finns vissa likheter med lambda-arkitekturens batchlager, i och med att händelsedata inte kan ändras och allt samlas in, i stället för en delmängd. Data matas in som en ström av händelser till en distribuerad och feltolerant enhetlig logg. De här händelserna är ordnade, och det aktuella tillståndet för en händelse ändras bara av att en ny händelse läggs till. På ungefär samma sätt som en lambda-arkitekturs hastighetslager utförs all händelsebearbetning i indataströmmen och sparas som en realtidsvy.
Om du behöver omberäkna hela datamängden (motsvarande det som batchlagret gör i lambda) spelar du upp strömmen igen, vanligtvis med parallellitet för att slutföra beräkningen snabbt.
Sakernas Internet (IoT)
Ur en praktisk synvinkel representerar Sakernas Internet (IoT) alla enheter som är anslutna till Internet. Det omfattar din dator, mobiltelefon, smartklocka, smarta termostat, smarta kylskåp, anslutna bil, implantat för hjärtövervakning och allt annat som ansluter till Internet och skickar eller tar emot data. Antalet anslutna enheter ökar varje dag, och det gör även mängden data som samlas in från dem. Dessa data samlas ofta in i begränsade miljöer, ibland med lång svarstid. I andra fall skickas data från miljöer med kort svarstid av tusentals eller miljontals enheter, vilket kräver möjlighet att snabbt mata in data och bearbeta därefter. Därför krävs noggrann planering för att hantera de här begränsningarna och unika kraven.
Händelsedrivna arkitekturer är centrala för IoT-lösningar. I följande diagram visas en möjlig logisk arkitektur för IoT. Diagrammet betonar komponenterna för direktuppspelning av händelser i arkitekturen.
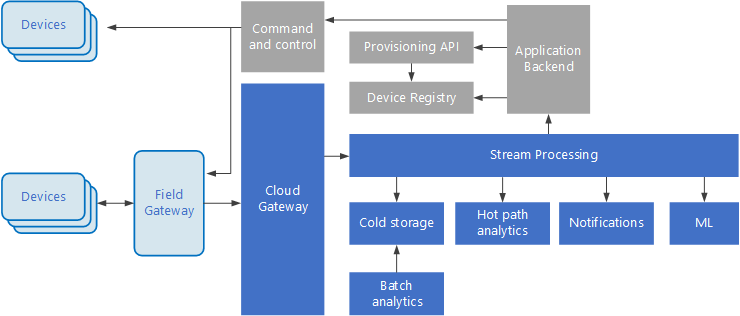
Molngatewayen matar in enhetshändelser vid molngränsen med hjälp av ett tillförlitligt meddelandesystem med kort svarstid.
Enheter kan skicka händelser direkt till molngatewayen eller via en fältgateway. En fältgateway är en särskild enhet eller programvara, vanligtvis samordnad med enheterna, som tar emot händelser och vidarebefordrar dem till molngatewayen. Fältgatewayen kan också förbearbeta råa enhetshändelser och utföra funktioner, till exempel filtrering, aggregering eller omvandling av protokollet.
Efter inmatningen går händelserna igenom en eller flera strömprocessorer som kan dirigera data (till exempel för lagring) eller utföra analyser och annan bearbetning.
Här följer några vanliga bearbetningstyper. (Listan är inte komplett.)
Skriva händelsedata till kall lagring för arkivering eller batchanalyser.
Het sökvägsanalys kan analysera händelseströmmen i (nära) realtid, för att identifiera avvikelser, identifiera mönster över rullande tidsfönster eller utlösa aviseringar när ett specifikt villkor uppträder i dataströmmen.
Hantering av särskilda typer av icke-telemetrimeddelanden från enheter, till exempel meddelanden och larm.
Maskininlärning.
I rutorna som är skuggade grått visas komponenterna i ett IoT-system som inte är direkt relaterade till händelseströmning, utan inkluderas här för fullständighetens skull.
Enhetsregistret är en databas med etablerade enheter, inklusive enhets-ID:n och vanligtvis enhetsmetadata, till exempel plats.
Etablerings-API är ett gemensamt externt gränssnitt för etablering och registrering av nya enheter.
I vissa IoT-lösningar kan kommando- och styrningsmeddelanden skickas till enheter.
Nästa steg
Se följande relevanta Azure-tjänster: