Vad är Speech Service?
Speech-tjänsten tillhandahåller funktioner för tal till text och text till tal med en Speech-resurs. Du kan transkribera tal till text med hög noggrannhet, producera naturligt klingande text till talröster, översätta talat ljud och använda talarigenkänning under konversationer.

Skapa egna röster, lägg till specifika ord i basordförrådet eller skapa egna modeller. Kör Speech var som helst – i molnet eller containrar i gränsmiljöer. Det är enkelt att talaktivera dina program, verktyg och enheter med Speech CLI, Speech SDK och REST API:er.
Tal är tillgängligt för många språk, regioner och prispunkter.
Tal-scenarier
Vanliga scenarier för tal är:
- Bildtext: Lär dig hur du synkroniserar bildtexter med ditt indataljud, tillämpar svordomsfilter, får partiella resultat, tillämpar anpassningar och identifierar talade språk för flerspråkiga scenarier.
- Skapande av ljudinnehåll: Du kan använda neurala röster för att göra interaktioner med chattrobotar och röstassistenter mer naturliga och engagerande, konvertera digitala texter som e-böcker till ljudböcker och förbättra navigeringssystemen i bilen.
- Call Center: Transkribera samtal i realtid eller bearbeta en grupp samtal, redigera personligt identifierande information och extrahera insikter som sentiment för att hjälpa till med ditt användningsfall för callcenter.
- Språkinlärning: Ge uttalsutvärderingsfeedback till språkinlärare, stöd för transkription i realtid för fjärrinlärningskonversationer och läs upp undervisningsmaterial med neurala röster.
- Röstassistenter: Skapa naturliga, mänskliga gränssnitt som konversationsgränssnitt för deras program och upplevelser. Funktionen röstassistent ger snabb och tillförlitlig interaktion mellan en enhet och en assistentimplementering.
Microsoft använder Speech för många scenarier, till exempel textning i Teams, diktering i Office 365 och Läs upp i Microsoft Edge-webbläsaren.
Talfunktioner
De här avsnitten sammanfattar Talfunktioner med länkar för mer information.
Tal till text
Använd tal till text för att transkribera ljud till text, antingen i realtid eller asynkront med batch-transkription.
Dricks
Du kan prova tal till text i realtid i Speech Studio utan att registrera dig eller skriva någon kod.
Konvertera ljud till text från en rad olika källor som mikrofoner, ljudfiler och bloblagring. Använd talardiarisering för att avgöra vem som sa vad och när. Få läsbara transkriptioner med automatisk formatering och interpunktion.
Basmodellen kanske inte räcker om ljudet innehåller omgivande brus eller innehåller många bransch- och domänspecifika jargonger. I dessa fall kan du skapa och träna anpassade talmodeller med akustiska data, språk och uttalsdata. Anpassade talmodeller är privata och kan ge en konkurrensfördel.
Tal till text i realtid
Med tal till text i realtid transkriberas ljudet eftersom tal känns igen från en mikrofon eller fil. Använd tal till text i realtid för program som behöver transkribera ljud i realtid, till exempel:
- Transkriptioner, bildtexter eller undertexter för livemöten
- Diarisering
- Uttalsbedömning
- Hjälp med kontaktcenteragenter
- Diktering
- Röstagenter
API för snabb transkription
API för snabb transkription används för att transkribera ljudfiler med resultat som returneras synkront och mycket snabbare än realtidsljud. Använd snabb transkription i scenarier där du behöver avskriften av en ljudinspelning så snabbt som möjligt med förutsägbar svarstid, till exempel:
- Snabb transkription av ljud eller video, undertexter och redigering.
- Videoöversättning
Information om hur du kommer igång med snabb transkription finns i använda API:et för snabb transkription.
Batch-transkription
Batch-transkription används för att transkribera en stor mängd ljud i lagringen. Du kan peka på ljudfiler med en SAS-URI (signatur för delad åtkomst) och asynkront ta emot transkriptionsresultat. Använd batch-transkription för program som behöver transkribera ljud i bulk, till exempel:
- Transkriptioner, bildtexter eller undertexter för förinspelat ljud
- Analys efter samtal i kontaktcenter
- Diarisering
Text till tal
Med text till tal kan du konvertera indatatext till människa som syntetiserat tal. Använd neurala röster, som är mänskliga som röster som drivs av djupa neurala nätverk. Använd Speech Synthesis Markup Language (SSML) för att finjustera tonhöjd, uttal, talfrekvens, volym med mera.
- Fördefinierad neural röst: Mycket naturliga out-of-the-box-röster. Kontrollera de fördefinierade neurala röstexemplen i röstgalleriet och fastställa rätt röst för dina affärsbehov.
- Anpassad neural röst: Förutom de fördefinierade neurala röster som kommer ut ur lådan kan du också skapa en anpassad neural röst som är igenkännlig och unik för ditt varumärke eller din produkt. Anpassade neurala röster är privata och kan erbjuda en konkurrensfördel. Kontrollera de anpassade neurala röstexemplen här.
Talöversättning
Talöversättning möjliggör flerspråkig översättning av tal i realtid till dina program, verktyg och enheter. Använd den här funktionen för tal till tal och tal till textöversättning.
Språkidentifiering
Språkidentifiering används för att identifiera språk som talas i ljud jämfört med en lista över språk som stöds. Använd språkidentifiering på egen hand, med tal till textigenkänning eller med talöversättning.
Talarigenkänning
Talarigenkänning ger algoritmer som verifierar och identifierar talare med sina unika röstegenskaper. Talarigenkänning används för att besvara frågan "Vem talar?".
Uttalsbedömning
Uttalsbedömning utvärderar tal uttal och ger talarna feedback om noggrannheten och flytet i talat ljud. Med uttalsutvärdering kan språkinlärarna öva, få omedelbar feedback och förbättra sitt uttal så att de kan känna sig trygga i att tala och göra presentationer.
Avsiktsigenkänning
Avsiktsigenkänning: Använd tal till text med förståelse för konversationsspråk för att härleda användaravsikter från transkriberat tal och agera på röstkommandon.
Leverans och närvaro
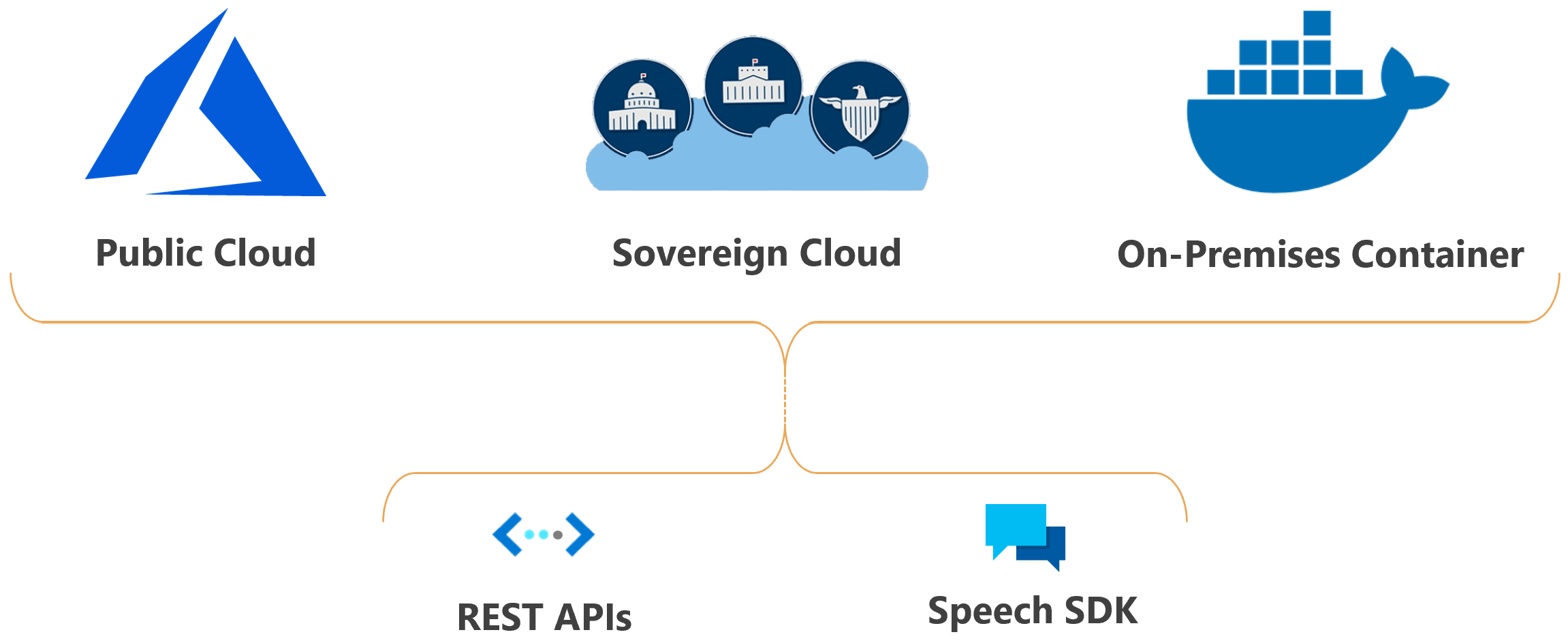
Du kan distribuera Azure AI Speech-funktioner i molnet eller lokalt.
Med containrar kan du föra tjänsten närmare dina data av kompatibilitets-, säkerhets- eller andra driftsskäl.
Distribution av taltjänsten i nationella moln är tillgänglig för vissa myndighetsentiteter och deras partner. Azure Government-molnet är till exempel tillgängligt för amerikanska myndigheter och deras partner. Microsoft Azure som drivs av 21Vianet-molnet är tillgängligt för organisationer med företagsnärvaro i Kina. Mer information finns i nationella moln.
Använda Speech i ditt program
Speech Studio är en uppsättning gränssnittsbaserade verktyg för att skapa och integrera funktioner från Azure AI Speech-tjänsten i dina program. Du skapar projekt i Speech Studio med hjälp av en metod utan kod och refererar sedan till dessa tillgångar i dina program med hjälp av Speech SDK, Speech CLI eller REST-API:erna.
Speech CLI är ett kommandoradsverktyg för att använda Speech Service utan att behöva skriva någon kod. De flesta funktioner i Speech SDK är tillgängliga i Speech CLI och vissa avancerade funktioner och anpassningar har förenklats.
Speech SDK exponerar många av de Speech-tjänstfunktioner som du kan använda för att utveckla talaktiverade program. Speech SDK är tillgängligt på många programmeringsspråk och på alla plattformar.
I vissa fall kan du inte eller bör inte använda Speech SDK. I sådana fall kan du använda REST-API:er för att komma åt Speech-tjänsten. Du kan till exempel använda REST-API:er för batch-transkription och rest-API:er för talarigenkänning.
Kom igång
Vi erbjuder snabbstarter på många populära programmeringsspråk. Varje snabbstart är utformad för att lära dig grundläggande designmönster och få dig att köra kod på mindre än 10 minuter. Se följande lista för snabbstarten för varje funktion:
Kodexempel
Exempelkod för Speech-tjänsten är tillgänglig på GitHub. De här exemplen beskriver vanliga scenarier som att läsa ljud från en fil eller ström, kontinuerlig och enkel bildigenkänning och arbeta med anpassade modeller. Använd dessa länkar för att visa SDK- och REST-exempel:
- Exempel på tal till text, text till tal och talöversättning (SDK)
- Batch-transkriptionsexempel (REST)
- Text till tal-exempel (REST)
- Röstassistentexempel (SDK)
Ansvarsfull AI
Ett AI-system innehåller inte bara tekniken, utan även de personer som använder den, de personer som påverkas av den och miljön där den distribueras. Läs transparensanteckningarna om du vill veta mer om ansvarsfull AI-användning och distribution i dina system.
Tal till text
- Antecknings- och användningsfall för transparens
- Egenskaper och begränsningar
- Integrering och ansvarsfull användning
- Data, sekretess och säkerhet
Uttalsbedömning
Anpassad neural röst
- Antecknings- och användningsfall för transparens
- Egenskaper och begränsningar
- Begränsad åtkomst
- Ansvarsfull distribution av syntetiskt tal
- Avslöjande av rösttalanger
- Offentliggörande av designriktlinjer
- Avslöjande av designmönster
- Uppförandekod
- Data, sekretess och säkerhet
Talarigenkänning
- Antecknings- och användningsfall för transparens
- Egenskaper och begränsningar
- Begränsad åtkomst
- Allmänna riktlinjer
- Data, sekretess och säkerhet