Vad är anpassad neural röst?
Anpassad neural röst (CNV) är en text till tal-funktion som gör att du kan skapa en unik, anpassad, syntetisk röst för dina program. Med anpassad neural röst kan du skapa en mycket naturlig röst för ditt varumärke eller dina karaktärer genom att tillhandahålla mänskliga talexempel som träningsdata.
Viktigt!
Anpassad neural röståtkomst är begränsad baserat på kriterier för berättigande och användning. Begär åtkomst i intagsformuläret.
Åtkomst till Anpassad neural röst (CNV) Lite är tillgänglig för vem som helst att demo och utvärdera CNV innan de investerar i professionella inspelningar för att skapa en röst av högre kvalitet.
I rutan kan text till tal användas med fördefinierade neurala röster för varje språk som stöds. De fördefinierade neurala rösterna fungerar bra i de flesta text-till-tal-scenarier om en unik röst inte krävs.
Anpassad neural röst baseras på neural text till tal-teknik och den flerspråkiga universella modellen med flera talare. Du kan skapa syntetiska röster som är rika på talstilar eller anpassningsbara korsspråk. Den realistiska och naturliga ljudrösten för anpassad neural röst kan representera varumärken, personifiera datorer och tillåta användare att interagera med program konversationsmässigt. Se språk som stöds för anpassad neural röst.
Hur fungerar det?
Om du vill skapa en anpassad neural röst använder du Speech Studio för att ladda upp det inspelade ljudet och motsvarande skript, träna modellen och distribuera rösten till en anpassad slutpunkt.
Dricks
Prova Anpassad neural röst (CNV) Lite för att demo och utvärdera CNV innan du investerar i professionella inspelningar för att skapa en röst av högre kvalitet.
Att skapa en bra anpassad neural röst kräver noggrann kvalitetskontroll i varje steg, från röstdesign och förberedelse av data till distribution av röstmodellen till systemet.
Innan du kommer igång i Speech Studio bör du tänka på följande:
- Utforma en persona av rösten som representerar ditt varumärke med hjälp av ett personligt kort dokument. Det här dokumentet definierar element som röstens funktioner och tecknet bakom rösten. Detta hjälper till att vägleda processen med att skapa en anpassad neural röstmodell, inklusive att definiera skripten, välja din rösttalang, träning och röstjustering.
- Välj inspelningsskriptet för att representera användarscenarierna för din röst. Du kan till exempel använda fraserna från robotkonversationer som inspelningsskript om du skapar en kundtjänstrobot. Inkludera olika meningstyper i dina skript, inklusive instruktioner, frågor och utrop.
Här är en översikt över stegen för att skapa en anpassad neural röst i Speech Studio:
- Skapa ett projekt som innehåller dina data, röstmodeller, tester och slutpunkter. Varje projekt är specifikt för ett land/en region och ett språk. Om du ska skapa flera röster rekommenderar vi att du skapar ett projekt för varje röst.
- Sätt upp rösttalanger. Innan du kan träna en neural röst måste du skicka in en inspelning av rösttalangens medgivande. Rösttalangens uttalande är en inspelning av rösttalangen som läser ett uttalande om att de samtycker till användningen av sina taldata för att träna en anpassad röstmodell.
- Förbered träningsdata i rätt format. Det är en bra idé att fånga ljudinspelningar i en professionell kvalitet inspelning studio för att uppnå en hög signal-till-brus förhållande. Kvaliteten på röstmodellen beror mycket på dina träningsdata. Konsekvent volym, talfrekvens, tonhöjd och konsekvens i uttrycksfulla talsätt krävs.
- Träna din röstmodell. Välj minst 300 yttranden för att skapa en anpassad neural röst. En serie datakvalitetskontroller utförs automatiskt när du laddar upp dem. Om du vill skapa röstmodeller av hög kvalitet bör du åtgärda eventuella fel och skicka igen.
- Testa din röst. Förbered testskript för din röstmodell som täcker de olika användningsfallen för dina appar. Det är en bra idé att använda skript inom och utanför träningsdatauppsättningen, så att du kan testa kvaliteten mer allmänt för olika innehåll.
- Distribuera och använda din röstmodell i dina appar.
Du kan justera, justera och använda din anpassade röst, på samma sätt som du skulle använda en fördefinierad neural röst. Konvertera text till tal i realtid eller generera ljudinnehåll offline med textinmatning. Du använder REST-API:et, Speech SDK eller Speech Studio.
Dricks
Kolla in kodexemplen på Speech SDK-lagringsplatsen på GitHub för att se hur du använder anpassad neural röst i ditt program.
Stilen och egenskaperna hos den tränade röstmodellen beror på stilen och kvaliteten på inspelningarna från rösttalangen som används för träning. Du kan dock göra flera justeringar med hjälp av SSML (Speech Synthesis Markup Language) när du gör API-anropen till din röstmodell för att generera syntetiskt tal. SSML är det påläggsspråk som används för att kommunicera med text till tal-tjänsten för att konvertera text till ljud. De justeringar du kan göra inkluderar ändring av tonhöjd, hastighet, intonation och uttalskorrigering. Om röstmodellen har skapats med flera formatmallar kan du också använda SSML för att växla formatmallarna.
Komponentsekvens
Anpassad neural röst består av tre huvudkomponenter: textanalysatorn, den neurala akustiska modellen och den neurala vocodern. För att generera naturligt syntetiskt tal från text matas text först in i textanalysatorn, vilket ger utdata i form av fonetiksekvens. Ett fonme är en grundläggande ljudenhet som skiljer ett ord från ett annat på ett visst språk. En sekvens med fonem definierar uttalen av orden som anges i texten.
Därefter går fonsekvensen in i den neurala akustiska modellen för att förutsäga akustiska funktioner som definierar talsignaler. Akustiska funktioner inkluderar timbre, talande stil, hastighet, intonationer och stressmönster. Slutligen konverterar den neurala vocoderen de akustiska funktionerna till hörbara vågor, så att syntetiskt tal genereras.
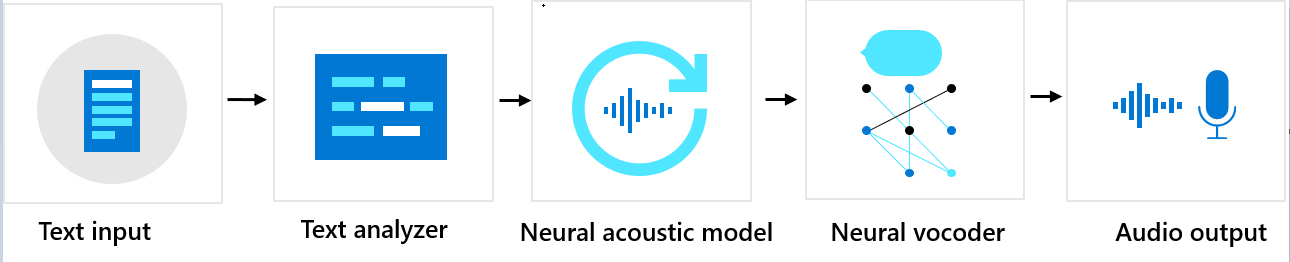
Neural text till talröstmodeller tränas med hjälp av djupa neurala nätverk baserat på inspelningsexempel av mänskliga röster. Mer information finns i det här Microsoft-blogginlägget. Mer information om hur en neural vocoder tränas finns i det här Microsoft-blogginlägget.
Ansvarsfull AI
Ett AI-system innehåller inte bara tekniken, utan även de personer som använder den, de personer som påverkas av den och miljön där den distribueras. Läs transparensanteckningarna om du vill veta mer om ansvarsfull AI-användning och distribution i dina system.
- Transparensanteckning och användningsfall för anpassad neural röst
- Egenskaper och begränsningar för att använda anpassad neural röst
- Begränsad åtkomst till anpassad neural röst
- Riktlinjer för ansvarsfull distribution av syntetisk röstteknik
- Avslöjande för rösttalanger
- Riktlinjer för informationsdesign
- Designmönster för avslöjande
- Uppförandekod för text-till-tal-integreringar
- Data, sekretess och säkerhet för anpassad neural röst