Snabbstart: Identifiera och konvertera tal till text
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
I den här snabbstarten provar du tal till text i realtid i Azure AI Foundry.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt.
- Vissa funktioner för Azure AI-tjänster är kostnadsfria att prova i Azure AI Foundry-portalen. För åtkomst till alla funktioner som beskrivs i den här artikeln måste du ansluta AI-tjänster i Azure AI Foundry.
Prova tal till text i realtid
Gå till ditt Azure AI Foundry-projekt. Om du behöver skapa ett projekt kan du läsa Skapa ett Azure AI Foundry-projekt.
Välj Lekplatser i den vänstra rutan och välj sedan en lekplats att använda. I det här exemplet väljer du Prova lekplatsen Tal.
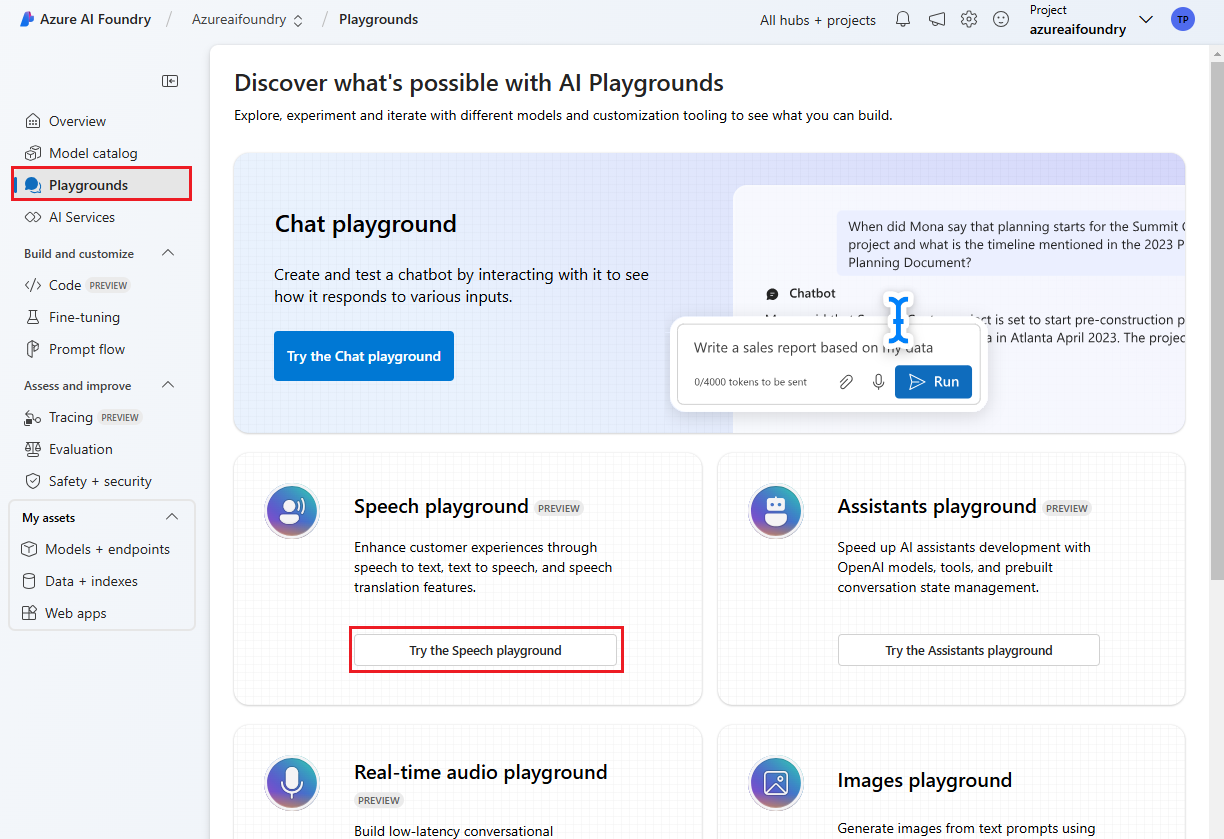
Du kan också välja en annan anslutning som ska användas på lekplatsen. På Speech Playground kan du ansluta till Azure AI Services-resurser med flera tjänster eller Speech Service-resurser.

Välj Transkription i realtid.
Välj Visa avancerade alternativ för att konfigurera alternativ för tal till text, till exempel:
- Språkidentifiering: Används för att identifiera språk som talas i ljud jämfört med en lista över språk som stöds. Mer information om språkidentifieringsalternativ som start och kontinuerlig igenkänning finns i Språkidentifiering.
- Talardiarisering: Används för att identifiera och separera högtalare i ljud. Diarization skiljer mellan de olika talare som deltar i konversationen. Taltjänsten tillhandahåller information om vilken talare som talade en viss del av transkriberat tal. Mer information om talardiarisering finns i snabbstarten för tal till text i realtid med talardiarisering .
- Anpassad slutpunkt: Använd en distribuerad modell från anpassat tal för att förbättra igenkänningsprecisionen. Om du vill använda Microsofts baslinjemodell lämnar du den här inställningen till Ingen. Mer information om anpassat tal finns i Anpassat tal.
- Utdataformat: Välj mellan enkla och detaljerade utdataformat. Enkla utdata innehåller visningsformat och tidsstämplar. Detaljerade utdata innehåller fler format (till exempel visning, lexikala, ITN och maskerade ITN), tidsstämplar och N-bästa listor.
- Fraslista: Förbättra transkriptionsprecisionen genom att ange en lista över kända fraser, till exempel namn på personer eller specifika platser. Använd kommatecken eller semikolon för att separera varje värde i fraslistan. Mer information om fraslistor finns i Fraslistor.
Välj en ljudfil som ska laddas upp eller spela in ljud i realtid. I det här exemplet använder
Call1_separated_16k_health_insurance.wavvi filen som är tillgänglig på Speech SDK-lagringsplatsen på GitHub. Du kan ladda ned filen eller använda din egen ljudfil.
Du kan visa transkriptionen i realtid längst ned på sidan.
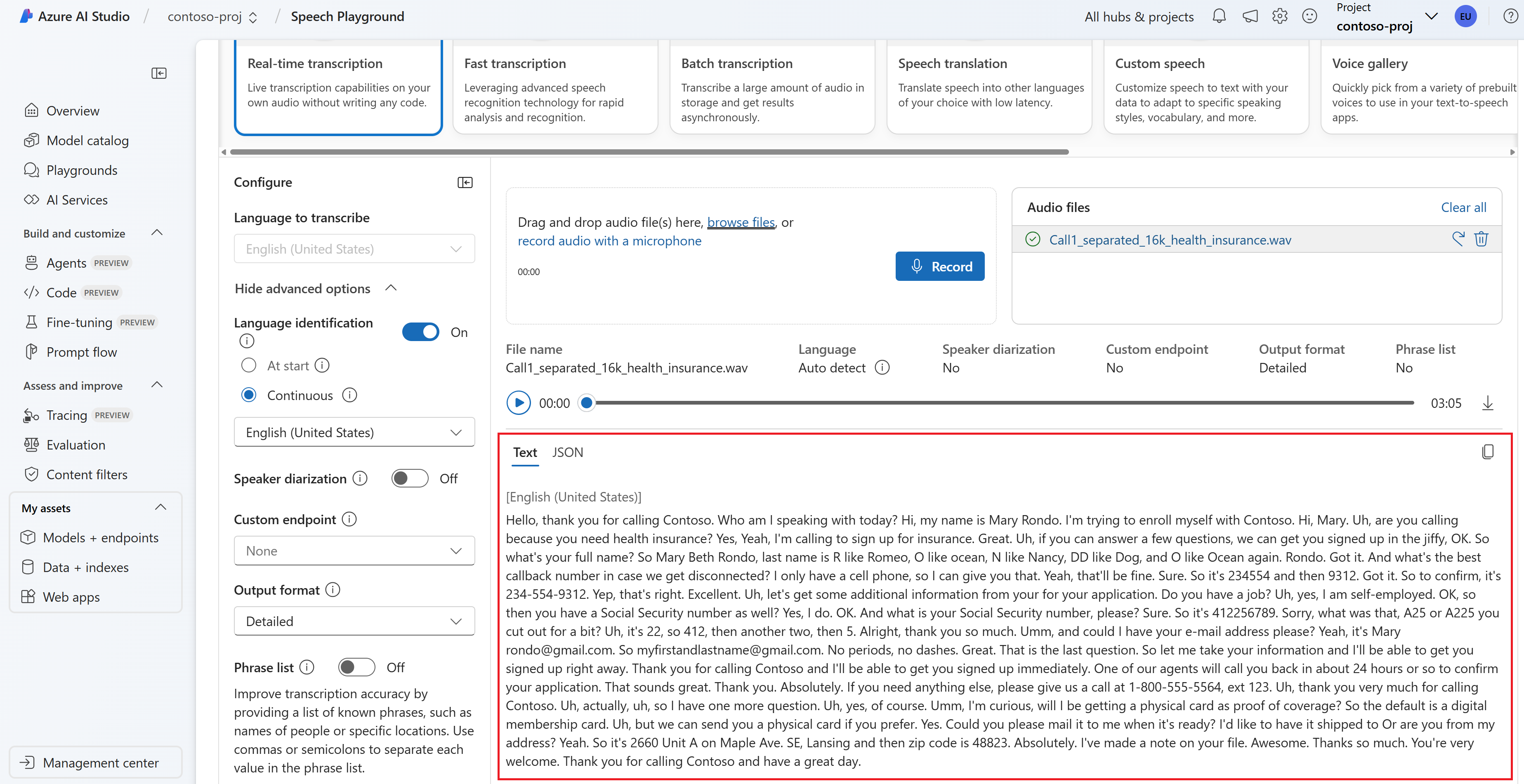
Du kan välja fliken JSON för att se JSON-utdata från transkriptionen. Egenskaperna inkluderar
Offset,Duration,RecognitionStatus,Display,Lexical,ITNoch mycket mer.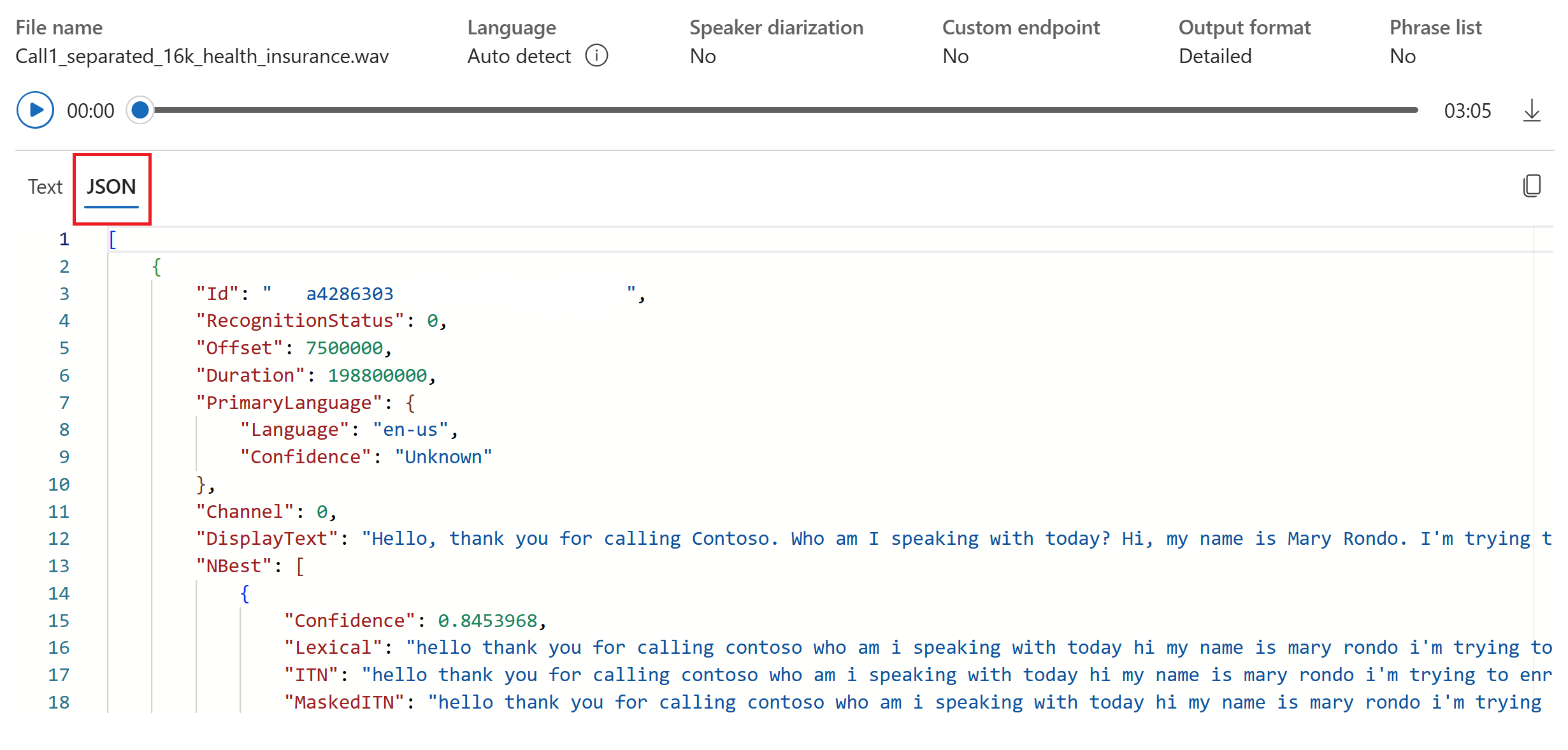





Referensdokumentation Paket (NuGet) | Ytterligare exempel på GitHub |
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Konfigurera miljön
Speech SDK är tillgängligt som ett NuGet-paket och implementerar .NET Standard 2.0. Du installerar Speech SDK senare i den här guiden. Andra krav finns i Installera Speech SDK.
Ange miljövariabler
Du måste autentisera ditt program för att få åtkomst till Azure AI-tjänster. Den här artikeln visar hur du använder miljövariabler för att lagra dina autentiseringsuppgifter. Du kan sedan komma åt miljövariablerna från koden för att autentisera ditt program. För produktion använder du ett säkrare sätt att lagra och komma åt dina autentiseringsuppgifter.
Viktigt!
Vi rekommenderar Microsoft Entra-ID-autentisering med hanterade identiteter för Azure-resurser för att undvika att lagra autentiseringsuppgifter med dina program som körs i molnet.
Om du använder en API-nyckel lagrar du den på ett säkert sätt någon annanstans, till exempel i Azure Key Vault. Inkludera inte API-nyckeln direkt i koden och publicera den aldrig offentligt.
Mer information om säkerhet för AI-tjänster finns i Autentisera begäranden till Azure AI-tjänster.
Om du vill ange miljövariablerna för din Speech-resursnyckel och -region öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
SPEECH_KEYmiljövariabeln ersätter du din nyckel med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätter du din region med en av regionerna för resursen.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Kommentar
Om du bara behöver komma åt miljövariablerna i den aktuella konsolen kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som behöver läsa miljövariablerna, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigerare startar du om Visual Studio innan du kör exemplet.
Identifiera tal från en mikrofon
Dricks
Prova Azure AI Speech Toolkit för att enkelt skapa och köra exempel på Visual Studio Code.
Följ de här stegen för att skapa ett konsolprogram och installera Speech SDK.
Öppna ett kommandotolksfönster i mappen där du vill ha det nya projektet. Kör det här kommandot för att skapa ett konsolprogram med .NET CLI.
dotnet new consoleDet här kommandot skapar Program.cs-filen i projektkatalogen.
Installera Speech SDK i ditt nya projekt med .NET CLI.
dotnet add package Microsoft.CognitiveServices.SpeechErsätt innehållet i Program.cs med följande kod:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Om du vill ändra taligenkänningsspråket ersätter du
en-USmed ett annat språk som stöds. Använd till exempeles-ESför spanska (Spanien). Om du inte anger något språk ären-USstandardvärdet . Mer information om hur du identifierar ett av flera språk som kan talas finns i Språkidentifiering.Kör det nya konsolprogrammet för att starta taligenkänning från en mikrofon:
dotnet runViktigt!
Se till att du anger
SPEECH_KEYmiljövariablerna ochSPEECH_REGION. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.Tala i mikrofonen när du uppmanas att göra det. Det du talar bör visas som text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Kommentarer
Här följer några andra överväganden:
I det här exemplet används åtgärden
RecognizeOnceAsyncför att transkribera yttranden på upp till 30 sekunder eller tills tystnad har identifierats. Information om kontinuerlig igenkänning för längre ljud, inklusive flerspråkiga konversationer, finns i Så här känner du igen tal.Om du vill känna igen tal från en ljudfil använder du
FromWavFileInputi stället förFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");För komprimerade ljudfiler som MP4 installerar du GStreamer och använder
PullAudioInputStreamellerPushAudioInputStream. Mer information finns i Använda komprimerat indataljud.
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.
Referensdokumentation Paket (NuGet) | Ytterligare exempel på GitHub |
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Konfigurera miljön
Speech SDK är tillgängligt som ett NuGet-paket och implementerar .NET Standard 2.0. Du installerar Speech SDK senare i den här guiden. Andra krav finns i Installera Speech SDK.
Ange miljövariabler
Du måste autentisera ditt program för att få åtkomst till Azure AI-tjänster. Den här artikeln visar hur du använder miljövariabler för att lagra dina autentiseringsuppgifter. Du kan sedan komma åt miljövariablerna från koden för att autentisera ditt program. För produktion använder du ett säkrare sätt att lagra och komma åt dina autentiseringsuppgifter.
Viktigt!
Vi rekommenderar Microsoft Entra-ID-autentisering med hanterade identiteter för Azure-resurser för att undvika att lagra autentiseringsuppgifter med dina program som körs i molnet.
Om du använder en API-nyckel lagrar du den på ett säkert sätt någon annanstans, till exempel i Azure Key Vault. Inkludera inte API-nyckeln direkt i koden och publicera den aldrig offentligt.
Mer information om säkerhet för AI-tjänster finns i Autentisera begäranden till Azure AI-tjänster.
Om du vill ange miljövariablerna för din Speech-resursnyckel och -region öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
SPEECH_KEYmiljövariabeln ersätter du din nyckel med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätter du din region med en av regionerna för resursen.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Kommentar
Om du bara behöver komma åt miljövariablerna i den aktuella konsolen kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som behöver läsa miljövariablerna, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigerare startar du om Visual Studio innan du kör exemplet.
Identifiera tal från en mikrofon
Dricks
Prova Azure AI Speech Toolkit för att enkelt skapa och köra exempel på Visual Studio Code.
Följ de här stegen för att skapa ett konsolprogram och installera Speech SDK.
Skapa ett nytt C++-konsolprojekt i Visual Studio Community med namnet
SpeechRecognition.Välj Verktyg>Nuget Package Manager Package Manager>Console. Kör följande kommando i Package Manager-konsolen:
Install-Package Microsoft.CognitiveServices.SpeechErsätt innehållet i
SpeechRecognition.cppmed följande kod:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Om du vill ändra taligenkänningsspråket ersätter du
en-USmed ett annat språk som stöds. Använd till exempeles-ESför spanska (Spanien). Om du inte anger något språk ären-USstandardvärdet . Mer information om hur du identifierar ett av flera språk som kan talas finns i Språkidentifiering.Skapa och kör det nya konsolprogrammet för att starta taligenkänning från en mikrofon.
Viktigt!
Se till att du anger
SPEECH_KEYmiljövariablerna ochSPEECH_REGION. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.Tala i mikrofonen när du uppmanas att göra det. Det du talar bör visas som text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Kommentarer
Här följer några andra överväganden:
I det här exemplet används åtgärden
RecognizeOnceAsyncför att transkribera yttranden på upp till 30 sekunder eller tills tystnad har identifierats. Information om kontinuerlig igenkänning för längre ljud, inklusive flerspråkiga konversationer, finns i Så här känner du igen tal.Om du vill känna igen tal från en ljudfil använder du
FromWavFileInputi stället förFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");För komprimerade ljudfiler som MP4 installerar du GStreamer och använder
PullAudioInputStreamellerPushAudioInputStream. Mer information finns i Använda komprimerat indataljud.
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.
Referensdokumentation Paket (Go) | Ytterligare exempel på GitHub |
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Konfigurera miljön
Installera Speech SDK för Go. Krav och instruktioner finns i Installera Speech SDK.
Ange miljövariabler
Du måste autentisera ditt program för att få åtkomst till Azure AI-tjänster. Den här artikeln visar hur du använder miljövariabler för att lagra dina autentiseringsuppgifter. Du kan sedan komma åt miljövariablerna från koden för att autentisera ditt program. För produktion använder du ett säkrare sätt att lagra och komma åt dina autentiseringsuppgifter.
Viktigt!
Vi rekommenderar Microsoft Entra-ID-autentisering med hanterade identiteter för Azure-resurser för att undvika att lagra autentiseringsuppgifter med dina program som körs i molnet.
Om du använder en API-nyckel lagrar du den på ett säkert sätt någon annanstans, till exempel i Azure Key Vault. Inkludera inte API-nyckeln direkt i koden och publicera den aldrig offentligt.
Mer information om säkerhet för AI-tjänster finns i Autentisera begäranden till Azure AI-tjänster.
Om du vill ange miljövariablerna för din Speech-resursnyckel och -region öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
SPEECH_KEYmiljövariabeln ersätter du din nyckel med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätter du din region med en av regionerna för resursen.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Kommentar
Om du bara behöver komma åt miljövariablerna i den aktuella konsolen kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som behöver läsa miljövariablerna, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigerare startar du om Visual Studio innan du kör exemplet.
Identifiera tal från en mikrofon
Följ de här stegen för att skapa en GO-modul.
Öppna ett kommandotolksfönster i mappen där du vill ha det nya projektet. Skapa en ny fil med namnet speech-recognition.go.
Kopiera följande kod till speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Kör följande kommandon för att skapa en go.mod-fil som länkar till komponenter som finns på GitHub:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goViktigt!
Se till att du anger
SPEECH_KEYmiljövariablerna ochSPEECH_REGION. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.Skapa och kör koden:
go build go run speech-recognition
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.
Referensdokumentation | Ytterligare exempel på GitHub
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Konfigurera miljön
Installera Speech SDK för att konfigurera din miljö. Exemplet i den här snabbstarten fungerar med Java Runtime.
Installera Apache Maven. Kör
mvn -vsedan för att bekräfta att installationen har slutförts.Skapa en ny
pom.xmlfil i roten av projektet och kopiera följande kod till den:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Installera Speech SDK och beroenden.
mvn clean dependency:copy-dependencies
Ange miljövariabler
Du måste autentisera ditt program för att få åtkomst till Azure AI-tjänster. Den här artikeln visar hur du använder miljövariabler för att lagra dina autentiseringsuppgifter. Du kan sedan komma åt miljövariablerna från koden för att autentisera ditt program. För produktion använder du ett säkrare sätt att lagra och komma åt dina autentiseringsuppgifter.
Viktigt!
Vi rekommenderar Microsoft Entra-ID-autentisering med hanterade identiteter för Azure-resurser för att undvika att lagra autentiseringsuppgifter med dina program som körs i molnet.
Om du använder en API-nyckel lagrar du den på ett säkert sätt någon annanstans, till exempel i Azure Key Vault. Inkludera inte API-nyckeln direkt i koden och publicera den aldrig offentligt.
Mer information om säkerhet för AI-tjänster finns i Autentisera begäranden till Azure AI-tjänster.
Om du vill ange miljövariablerna för din Speech-resursnyckel och -region öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
SPEECH_KEYmiljövariabeln ersätter du din nyckel med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätter du din region med en av regionerna för resursen.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Kommentar
Om du bara behöver komma åt miljövariablerna i den aktuella konsolen kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som behöver läsa miljövariablerna, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigerare startar du om Visual Studio innan du kör exemplet.
Identifiera tal från en mikrofon
Följ de här stegen för att skapa ett konsolprogram för taligenkänning.
Skapa en ny fil med namnet SpeechRecognition.java i samma projektrotkatalog.
Kopiera följande kod till SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Om du vill ändra taligenkänningsspråket ersätter du
en-USmed ett annat språk som stöds. Använd till exempeles-ESför spanska (Spanien). Om du inte anger något språk ären-USstandardvärdet . Mer information om hur du identifierar ett av flera språk som kan talas finns i Språkidentifiering.Kör det nya konsolprogrammet för att starta taligenkänning från en mikrofon:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionViktigt!
Se till att du anger
SPEECH_KEYmiljövariablerna ochSPEECH_REGION. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.Tala i mikrofonen när du uppmanas att göra det. Det du talar bör visas som text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Kommentarer
Här följer några andra överväganden:
I det här exemplet används åtgärden
RecognizeOnceAsyncför att transkribera yttranden på upp till 30 sekunder eller tills tystnad har identifierats. Information om kontinuerlig igenkänning för längre ljud, inklusive flerspråkiga konversationer, finns i Så här känner du igen tal.Om du vill känna igen tal från en ljudfil använder du
fromWavFileInputi stället förfromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");För komprimerade ljudfiler som MP4 installerar du GStreamer och använder
PullAudioInputStreamellerPushAudioInputStream. Mer information finns i Använda komprimerat indataljud.
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.
Referensdokumentation Paket (npm) | Ytterligare exempel på GitHub-bibliotekets källkod | |
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Du behöver också en .wav ljudfil på den lokala datorn. Du kan använda din egen .wav fil (upp till 30 sekunder) eller ladda ned https://crbn.us/whatstheweatherlike.wav exempelfilen.
Konfigurera miljön
Installera Speech SDK för JavaScript för att konfigurera din miljö. Kör det här kommandot: npm install microsoft-cognitiveservices-speech-sdk. Anvisningar för guidad installation finns i Installera Speech SDK.
Ange miljövariabler
Du måste autentisera ditt program för att få åtkomst till Azure AI-tjänster. Den här artikeln visar hur du använder miljövariabler för att lagra dina autentiseringsuppgifter. Du kan sedan komma åt miljövariablerna från koden för att autentisera ditt program. För produktion använder du ett säkrare sätt att lagra och komma åt dina autentiseringsuppgifter.
Viktigt!
Vi rekommenderar Microsoft Entra-ID-autentisering med hanterade identiteter för Azure-resurser för att undvika att lagra autentiseringsuppgifter med dina program som körs i molnet.
Om du använder en API-nyckel lagrar du den på ett säkert sätt någon annanstans, till exempel i Azure Key Vault. Inkludera inte API-nyckeln direkt i koden och publicera den aldrig offentligt.
Mer information om säkerhet för AI-tjänster finns i Autentisera begäranden till Azure AI-tjänster.
Om du vill ange miljövariablerna för din Speech-resursnyckel och -region öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
SPEECH_KEYmiljövariabeln ersätter du din nyckel med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätter du din region med en av regionerna för resursen.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Kommentar
Om du bara behöver komma åt miljövariablerna i den aktuella konsolen kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som behöver läsa miljövariablerna, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigerare startar du om Visual Studio innan du kör exemplet.
Identifiera tal från en fil
Dricks
Prova Azure AI Speech Toolkit för att enkelt skapa och köra exempel på Visual Studio Code.
Följ de här stegen för att skapa ett Node.js-konsolprogram för taligenkänning.
Öppna ett kommandotolksfönster där du vill ha det nya projektet och skapa en ny fil med namnet SpeechRecognition.js.
Installera Speech SDK för JavaScript:
npm install microsoft-cognitiveservices-speech-sdkKopiera följande kod till SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();I SpeechRecognition.js ersätter du YourAudioFile.wav med din egen .wav fil. Det här exemplet identifierar bara tal från en .wav fil. Information om andra ljudformat finns i Använda komprimerat indataljud. Det här exemplet stöder upp till 30 sekunders ljud.
Om du vill ändra taligenkänningsspråket ersätter du
en-USmed ett annat språk som stöds. Använd till exempeles-ESför spanska (Spanien). Om du inte anger något språk ären-USstandardvärdet . Mer information om hur du identifierar ett av flera språk som kan talas finns i Språkidentifiering.Kör det nya konsolprogrammet för att starta taligenkänning från en fil:
node.exe SpeechRecognition.jsViktigt!
Se till att du anger
SPEECH_KEYmiljövariablerna ochSPEECH_REGION. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.Talet från ljudfilen ska matas ut som text:
RECOGNIZED: Text=I'm excited to try speech to text.
Kommentarer
I det här exemplet används åtgärden recognizeOnceAsync för att transkribera yttranden på upp till 30 sekunder eller tills tystnad har identifierats. Information om kontinuerlig igenkänning för längre ljud, inklusive flerspråkiga konversationer, finns i Så här känner du igen tal.
Kommentar
Det går inte att känna igen tal från en mikrofon i Node.js. Det stöds endast i en webbläsarbaserad JavaScript-miljö. Mer information finns i React-exemplet och implementeringen av tal till text från en mikrofon på GitHub.
React-exemplet visar designmönster för utbyte och hantering av autentiseringstoken. Den visar också inspelning av ljud från en mikrofon eller fil för tal till textkonverteringar.
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.
Referensdokumentation Paket (PyPi) | Ytterligare exempel på GitHub |
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Konfigurera miljön
Speech SDK för Python är tillgänglig som en PyPI-modul (Python Package Index). Speech SDK för Python är kompatibelt med Windows, Linux och macOS.
- För Windows installerar du Microsoft Visual C++ Redistributable för Visual Studio 2015, 2017, 2019 och 2022 för din plattform. Att installera det här paketet för första gången kan kräva en omstart.
- I Linux måste du använda x64-målarkitekturen.
Installera en version av Python från 3.7 eller senare. Andra krav finns i Installera Speech SDK.
Ange miljövariabler
Du måste autentisera ditt program för att få åtkomst till Azure AI-tjänster. Den här artikeln visar hur du använder miljövariabler för att lagra dina autentiseringsuppgifter. Du kan sedan komma åt miljövariablerna från koden för att autentisera ditt program. För produktion använder du ett säkrare sätt att lagra och komma åt dina autentiseringsuppgifter.
Viktigt!
Vi rekommenderar Microsoft Entra-ID-autentisering med hanterade identiteter för Azure-resurser för att undvika att lagra autentiseringsuppgifter med dina program som körs i molnet.
Om du använder en API-nyckel lagrar du den på ett säkert sätt någon annanstans, till exempel i Azure Key Vault. Inkludera inte API-nyckeln direkt i koden och publicera den aldrig offentligt.
Mer information om säkerhet för AI-tjänster finns i Autentisera begäranden till Azure AI-tjänster.
Om du vill ange miljövariablerna för din Speech-resursnyckel och -region öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
SPEECH_KEYmiljövariabeln ersätter du din nyckel med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätter du din region med en av regionerna för resursen.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Kommentar
Om du bara behöver komma åt miljövariablerna i den aktuella konsolen kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som behöver läsa miljövariablerna, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigerare startar du om Visual Studio innan du kör exemplet.
Identifiera tal från en mikrofon
Dricks
Prova Azure AI Speech Toolkit för att enkelt skapa och köra exempel på Visual Studio Code.
Följ de här stegen för att skapa ett konsolprogram.
Öppna ett kommandotolksfönster i mappen där du vill ha det nya projektet. Skapa en ny fil med namnet speech_recognition.py.
Kör det här kommandot för att installera Speech SDK:
pip install azure-cognitiveservices-speechKopiera följande kod till speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Om du vill ändra taligenkänningsspråket ersätter du
en-USmed ett annat språk som stöds. Använd till exempeles-ESför spanska (Spanien). Om du inte anger något språk ären-USstandardvärdet . Mer information om hur du identifierar ett av flera språk som kan talas finns i språkidentifiering.Kör det nya konsolprogrammet för att starta taligenkänning från en mikrofon:
python speech_recognition.pyViktigt!
Se till att du anger
SPEECH_KEYmiljövariablerna ochSPEECH_REGION. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.Tala i mikrofonen när du uppmanas att göra det. Det du talar bör visas som text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Kommentarer
Här följer några andra överväganden:
I det här exemplet används åtgärden
recognize_once_asyncför att transkribera yttranden på upp till 30 sekunder eller tills tystnad har identifierats. Information om kontinuerlig igenkänning för längre ljud, inklusive flerspråkiga konversationer, finns i Så här känner du igen tal.Om du vill känna igen tal från en ljudfil använder du
filenamei stället föruse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")För komprimerade ljudfiler som MP4 installerar du GStreamer och använder
PullAudioInputStreamellerPushAudioInputStream. Mer information finns i Använda komprimerat indataljud.
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.
Paket för referensdokumentation (nedladdning) | Ytterligare exempel på GitHub |
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Konfigurera miljön
Speech SDK för Swift distribueras som ett ramverkspaket. Ramverket stöder både Objective-C och Swift på både iOS och macOS.
Speech SDK kan användas i Xcode-projekt som en CocoaPod eller laddas ned direkt och länkas manuellt. Den här guiden använder en CocoaPod. Installera CocoaPod-beroendehanteraren enligt beskrivningen i installationsanvisningarna.
Ange miljövariabler
Du måste autentisera ditt program för att få åtkomst till Azure AI-tjänster. Den här artikeln visar hur du använder miljövariabler för att lagra dina autentiseringsuppgifter. Du kan sedan komma åt miljövariablerna från koden för att autentisera ditt program. För produktion använder du ett säkrare sätt att lagra och komma åt dina autentiseringsuppgifter.
Viktigt!
Vi rekommenderar Microsoft Entra-ID-autentisering med hanterade identiteter för Azure-resurser för att undvika att lagra autentiseringsuppgifter med dina program som körs i molnet.
Om du använder en API-nyckel lagrar du den på ett säkert sätt någon annanstans, till exempel i Azure Key Vault. Inkludera inte API-nyckeln direkt i koden och publicera den aldrig offentligt.
Mer information om säkerhet för AI-tjänster finns i Autentisera begäranden till Azure AI-tjänster.
Om du vill ange miljövariablerna för din Speech-resursnyckel och -region öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
SPEECH_KEYmiljövariabeln ersätter du din nyckel med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätter du din region med en av regionerna för resursen.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Kommentar
Om du bara behöver komma åt miljövariablerna i den aktuella konsolen kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som behöver läsa miljövariablerna, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigerare startar du om Visual Studio innan du kör exemplet.
Identifiera tal från en mikrofon
Följ de här stegen för att identifiera tal i ett macOS-program.
Klona lagringsplatsen Azure-Samples/cognitive-services-speech-sdk för att hämta taligenkänningen från en mikrofon i Swift i macOS-exempelprojektet . Lagringsplatsen har också iOS-exempel.
Gå till katalogen för den nedladdade exempelappen (
helloworld) i en terminal.Kör kommandot
pod install. Det här kommandot genererar enhelloworld.xcworkspaceXcode-arbetsyta som innehåller både exempelappen och Speech SDK som ett beroende.helloworld.xcworkspaceÖppna arbetsytan i Xcode.Öppna filen Med namnet AppDelegate.swift och leta upp
applicationDidFinishLaunchingmetoderna ochrecognizeFromMicsom visas här.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }I AppDelegate.m använder du de miljövariabler som du tidigare angav för din Speech-resursnyckel och -region.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Om du vill ändra taligenkänningsspråket ersätter du
en-USmed ett annat språk som stöds. Använd till exempeles-ESför spanska (Spanien). Om du inte anger något språk ären-USstandardvärdet . Mer information om hur du identifierar ett av flera språk som kan talas finns i Språkidentifiering.Om du vill göra felsökningsutdata synliga väljer du Visa>felsökningsområde>Aktivera konsol.
Skapa och kör exempelkoden genom att välja Produktkörning> på menyn eller välja knappen Spela upp.
Viktigt!
Se till att du anger
SPEECH_KEYmiljövariablerna ochSPEECH_REGION. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.
När du har valt knappen i appen och sagt några ord bör du se texten som du talade på den nedre delen av skärmen. När du kör appen för första gången uppmanas du att ge appen åtkomst till datorns mikrofon.
Kommentarer
I det här exemplet används åtgärden recognizeOnce för att transkribera yttranden på upp till 30 sekunder eller tills tystnad har identifierats. Information om kontinuerlig igenkänning för längre ljud, inklusive flerspråkiga konversationer, finns i Så här känner du igen tal.
Objective-C
Speech SDK för Objective-C delar klientbibliotek och referensdokumentation med Speech SDK för Swift. Exempel på Objective-C-kod finns i identifiera tal från en mikrofon i Objective-C på macOS-exempelprojektet i GitHub.
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.
Tal till text REST API-referens Tal till text REST API för kort ljudreferens | Ytterligare exempel på GitHub |
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Du behöver också en .wav ljudfil på den lokala datorn. Du kan använda din egen .wav fil i upp till 60 sekunder eller ladda ned https://crbn.us/whatstheweatherlike.wav exempelfilen.
Ange miljövariabler
Du måste autentisera ditt program för att få åtkomst till Azure AI-tjänster. Den här artikeln visar hur du använder miljövariabler för att lagra dina autentiseringsuppgifter. Du kan sedan komma åt miljövariablerna från koden för att autentisera ditt program. För produktion använder du ett säkrare sätt att lagra och komma åt dina autentiseringsuppgifter.
Viktigt!
Vi rekommenderar Microsoft Entra-ID-autentisering med hanterade identiteter för Azure-resurser för att undvika att lagra autentiseringsuppgifter med dina program som körs i molnet.
Om du använder en API-nyckel lagrar du den på ett säkert sätt någon annanstans, till exempel i Azure Key Vault. Inkludera inte API-nyckeln direkt i koden och publicera den aldrig offentligt.
Mer information om säkerhet för AI-tjänster finns i Autentisera begäranden till Azure AI-tjänster.
Om du vill ange miljövariablerna för din Speech-resursnyckel och -region öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
SPEECH_KEYmiljövariabeln ersätter du din nyckel med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätter du din region med en av regionerna för resursen.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Kommentar
Om du bara behöver komma åt miljövariablerna i den aktuella konsolen kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som behöver läsa miljövariablerna, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigerare startar du om Visual Studio innan du kör exemplet.
Identifiera tal från en fil
Öppna ett konsolfönster och kör följande cURL-kommando. Ersätt YourAudioFile.wav med sökvägen och namnet på ljudfilen.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Viktigt!
Se till att du anger SPEECH_KEY miljövariablerna och SPEECH_REGION. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.
Du bör få ett svar som liknar det som visas här.
DisplayText Bör vara den text som kändes igen från ljudfilen. Kommandot identifierar upp till 60 sekunders ljud och konverterar det till text.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Mer information finns i REST API för tal till text för kort ljud.
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.
I den här snabbstarten skapar och kör du ett program för att identifiera och transkribera tal till text i realtid.
Om du i stället vill transkribera ljudfiler asynkront läser du Vad är batch-transkription. Om du inte är säker på vilken tal till text-lösning som passar dig kan du läsa Vad är tal till text?
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- Skapa en Speech-resurs i Azure Portal.
- Hämta resursnyckeln och regionen Speech. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar.
Konfigurera miljön
Följ de här stegen och se snabbstarten för Speech CLI för andra krav för din plattform.
Kör följande .NET CLI-kommando för att installera Speech CLI:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIKör följande kommandon för att konfigurera din Speech-resursnyckel och -region. Ersätt
SUBSCRIPTION-KEYmed din Speech-resursnyckel och ersättREGIONmed din Speech-resursregion.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Identifiera tal från en mikrofon
Kör följande kommando för att starta taligenkänning från en mikrofon:
spx recognize --microphone --source en-USTala in i mikrofonen och du ser transkription av dina ord i text i realtid. Speech CLI stoppas efter en tyst period, 30 sekunder eller när du väljer Ctrl+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Kommentarer
Här följer några andra överväganden:
Om du vill känna igen tal från en ljudfil använder du
--filei stället för--microphone. För komprimerade ljudfiler som MP4 installerar du GStreamer och använder--format. Mer information finns i Använda komprimerat indataljud.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyOm du vill förbättra igenkänningsprecisionen för specifika ord eller yttranden använder du en fraslista. Du inkluderar en fraslista i rad eller med en textfil tillsammans med
recognizekommandot :spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtOm du vill ändra taligenkänningsspråket ersätter du
en-USmed ett annat språk som stöds. Använd till exempeles-ESför spanska (Spanien). Om du inte anger något språk ären-USstandardvärdet .spx recognize --microphone --source es-ESFör kontinuerlig igenkänning av ljud längre än 30 sekunder lägger du till
--continuous:spx recognize --microphone --source es-ES --continuousKör det här kommandot för information om fler alternativ för taligenkänning, till exempel filindata och utdata:
spx help recognize
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort den Speech-resurs som du skapade.