Использование преобразования данных DICOM в решениях для данных здравоохранения
Возможность преобразования данных DICOM в решениях для данных здравоохранения позволяет принимать, хранить и анализировать данные цифровой визуализации и коммуникаций в медицине (DICOM) из различных источников. Дополнительные сведения об этой возможности, а также о том, как ее развернуть и настроить, см. в разделе:
- Обзор преобразования данных DICOM
- Преобразование метаданных DICOM сопоставление
- Развертывание и настройка преобразования данных DICOM
Преобразование данных DICOM является дополнительной возможностью в решениях для данных здравоохранения в Microsoft Fabric.
Предварительные условия
Перед запуском конвейера преобразования данных DICOM убедитесь, что выполнены предварительные требования, процесс развертывания и действия по настройке, описанные в разделе Развертывание и настройка преобразования данных DICOM.
Параметры приема данных
В этой статье представлено пошаговое руководство по использованию возможности преобразования данных DICOM для приема, преобразования и унификации изображений DICOM набор данных. Данная возможность поддерживает следующие два варианта приема:
Вариант 1: Сквозной прием файлов DICOM. Файлы DICOM, в собственном (DCM) или сжатом (ZIP) форматах, загружаются в хранилище озера данных. Этот параметр называется параметром Прием.
Вариант 2: Интеграция со службой DICOM. Прием облегчается за счет встроенной интеграции со службой DICOM в службы Azure для работы с медицинскими данными. В этом случае файлы DCM сначала передаются из службы DICOM служб Azure для работы с медицинскими данными в Azure Data Lake Storage 2-го поколения. Затем конвейер следует шаблону приема данных Bring Your Own Storage (BYOS) . Эта опция называется Службы Azure для работы с медицинскими данными (AHDS).
Чтобы понять детали преобразования сопоставление, см. Преобразование метаданных DICOM сопоставление в решениях для обработки медицинских данных.
Вариант 1: сквозной прием файлов DICOM
В этом варианте мы принимаем и преобразуем данные изображений из файлов DICOM в хранилища медицинских данных, используя предварительно созданный конвейер данных. Сквозное преобразование состоит из следующих последовательных шагов:
- Прием файлов DICOM в OneLake
- Систематизация файлов DICOM в OneLake
- Извлечение метаданных DICOM в бронзовый хранилище озера данных
- Преобразование метаданных DICOM в формат FHIR (ресурсы быстрого взаимодействия в сфере здравоохранения)
- Прием данных в разностную таблицу ImagingStudy в бронзовом хранилище озера данных
- Сведение и преобразование данных в разностную таблицу ImagingStudy в серебряном хранилище озера данных
- Преобразование и прием данных в таблицу Image_Occurrence в золотом хранилище озера данных (необязательно)
Совет
Этот вариант приема использует образец 340ImagingStudies набор данных, содержащий сжатые ZIP-файлы. Кроме того, вы можете загрузить файлы DICOM непосредственно в их исходном формате DCM, поместив их в папку Ingest . В ZIP-файлах файлы DCM могут быть структурированы в несколько вложенных подпапок. Ограничений по количеству файлов DCM или количеству, глубине и вложенности подпапок в загруженных ZIP-файлах нет. Информацию об ограничениях на размер файла см. в разделе Размер файла для загрузки.
шаг 1: Загрузка файлов DICOM в OneLake
Папка Прием в бронзовом хранилище озера данных представляет собой папку для сброса (очередь). Вы можете перетащить файлы DICOM в эту папку. Затем файлы перемещаются в упорядоченную структуру папок в бронзовом хранилище озера данных.
Перейдите в папку
Ingest\Imaging\DICOM\DICOM-HDSв бронзе хранилище и озеро данных.Выберите ... (многоточие) >Загрузить>Папка для загрузки.
Выберите и загрузите 340ImagingStudies изображение набор данных из папки SampleData в
SampleData\Imaging\DICOM\DICOM-HDS. В качестве альтернативы вы также можете использовать OneLake file explorer или Azure Storage Explorer для загрузки образца набор данных.
шаг 2: Запуск конвейера обработки данных изображений
После перемещения файлов DCM/ZIP в папку Ingest в бронзовом хранилище и озеро данных вы можете запустить конвейер обработки данных изображений для организации и обработки данных в серебряном хранилище и озеро данных.
В вашей среде решений для обработки данных в сфере здравоохранения откройте конвейер данных healthcare#_msft_imaging_with_clinical_foundation_ingestion .
Нажмите кнопку Запустить , чтобы начать обработку данных визуализации от бронзы до серебра хранилище и озеро данных.
Этот конвейер данных последовательно запускает пять блокнотов: три из них развернуты в рамках возможностей основ данных здравоохранения, а два — в рамках возможностей преобразования данных DICOM. Чтобы узнать больше об этих блокнотах, см. раздел Преобразование данных DICOM: Артефакты.

шаг 3: Запустите блокнот преобразования серебра в золото
Заметка
Это преобразование шаг является необязательным. Используйте его только в том случае, если вам необходимо дополнительно преобразовать данные DICOM в формат общей модели данных (CDM) Observational Medical Outcomes Partnership (OMOP). В противном случае этот шаг можно пропустить.
Прежде чем запустить это преобразование, разверните и настройте OMOP возможности преобразований в решениях для обработки данных в здравоохранении.
После запуска конвейера визуализации ваши данные визуализации преобразуются в серебряный хранилище и озеро данных. Серебряный хранилище и озеро данных служит начальной точкой, где данные из различных модальностей начинают структурироваться. Для дальнейшего преобразования ваших данных в OMOP исследовательский стандарт для использования в возможности обнаружения и построения когорт (предварительная версия) запустите блокнот преобразования серебра в золото.
В вашей среде решений для обработки данных в сфере здравоохранения откройте блокнот healthcare#_msft_omop_silver_gold_transformation .
В этом блокноте используются API-интерфейсы решений для обработки медицинских данных OMOP для преобразования ресурсов из серебряного хранилище и озеро данных в OMOP таблицы дельта CDM в золотом хранилище и озеро данных. По умолчанию вносить какие-либо изменения в конфигурацию записной книжки не требуется.
Выберите Выполнить все, чтобы выполнить записную книжку.
В блокноте реализован OMOP подход отслеживания для отслеживания и обработки новых или обновленных записей в дельта-таблице ImagingStudy в серебряном хранилище и озеро данных. Он преобразует данные из дельта-таблиц FHIR в серебряном хранилище и озеро данных (включая таблицу ImagingStudy ) в соответствующие OMOP таблицы дельты в золотом хранилище и озеро данных (включая таблицу Image_Occurrence ). Более подробную информацию об этом преобразовании см. в разделе Преобразование сопоставление для таблицы дельта серебра в золото.
Подробную OMOP информацию о сопоставление см. в разделе FHIR to OMOP сопоставление.
шаг 4: Проверка данных
В реальных сценариях прием данных осуществляется из источников с разным уровнем качества. Механизм проверки, подробно описанный в разделе Проверка данных, намеренно запускает проверки некоторых предоставленных данных образцов изображений. Файлы, не соответствующие стандартам DICOM, перемещаются в папку Failed и не обрабатываются. Однако сбой одного файла не приводит к нарушению работы всего конвейера, как показывают данные выборки изображений. Конвейер и связанные с ним блокноты работают успешно, но папка Failed в Imaging\DICOM\DICOM-HDS\YYYY\MM\DD содержит несоответствующий файл. Все остальные допустимые файлы обрабатываются успешно, что приводит к общему успешному статусу конвейера. Мы намеренно включаем этот недействительный файл в данные образца изображения, чтобы проиллюстрировать, как конвейер обработки изображений обрабатывает недействительные файлы, и помочь вам выявить проблемы набор данных.

Чтобы убедиться, что конвейер успешно извлек все метаданные из необработанных файлов DICOM, откройте bronze хранилище и озеро данных, переключитесь на аналитику SQL конечная точка и выберите Новый запрос SQL.

Если конвейер отработал правильно, вы должны увидеть 7739 успешно обработанных экземпляров DICOM в таблице ImagingDicom . Для проверки выполните следующий запрос SQL. При успешной обработке вы должны увидеть 7739 на панели Результаты . Это число представляет собой общее количество экземпляров DICOM в выборке данных, включающей данные, полученные с помощью различных методов, таких как компьютерная томография (КТ) и магнитно-резонансная томография (МРТ).
select count(*) from ImagingDicom

Чтобы убедиться, что трубопровод успешно снабдил водой домики у озера, откройте серебряный хранилище и озеро данных, переключитесь на аналитику SQL конечная точка и выберите Новый запрос SQL. Для корректного запуска конвейера необходимо увидеть 339 успешно обработанных ресурсов ImagingStudy . Для проверки выполните следующий запрос SQL. Первоначально мы начинаем с 340 ресурсов ImagingStudy , но во время обработки возникает ошибка.
select count(*) from ImagingStudy

Вариант 2: Интеграция со службой DICOM
Внимание!
Используйте этот параметр преобразования только в том случае, если вы используете службу Azure Health Data Services DICOM и развернули API DICOM.
Этот подход к преобразованию расширяет модель Bring Your Own Storage (BYOS) с помощью службы DICOM служб медицинских данных Azure. Служба DICOM представляет собой подмножество API DICOMweb , которые позволяют хранить, просматривать, искать и удалять объекты DICOM. Он интегрируется с учетной записью Azure Data Lake Storage Gen2, связанной с вашим рабочим пространством Fabric, благодаря чему конвейер преобразования может напрямую получать доступ к вашим данным DICOM.
В качестве альтернативы вы можете пропустить использование API DICOM Azure и загрузить файлы DICOM, хранящиеся в вашей учетной записи Data Lake Storage Gen2 (в этом случае начните с шаг 5).
Проверьте и завершите настройку в разделе Развертывание API DICOM в Azure Health Data Services.
После развертывания службы DICOM Azure используйте API Store (STOW-RS) для загрузки файлов DCM. Проверьте это, загрузив файл DCM из данных образца изображения с помощью обозревателя файлов OneLake или Azure Storage Explorer.
В зависимости от предпочитаемого вами языка загрузите файлы DCM на сервер, используя один из следующих вариантов:
Проверьте, успешно ли была загружена загрузка файла:
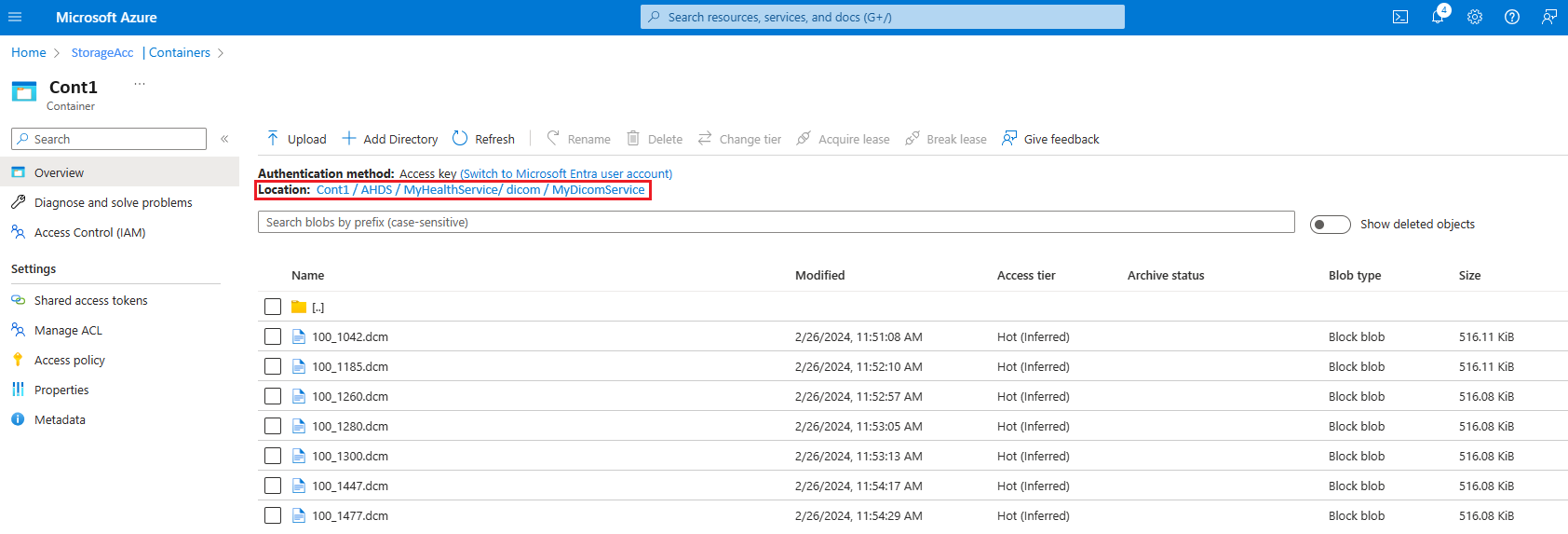
- На портале Azure выберите учетную запись хранения, связанную со службой DICOM.
- Перейдите в раздел Контейнеры и следуйте по пути
[ContainerName]/AHDS/[AzureHealthDataServicesWorkspaceName]/dicom/[DICOMServiceName]. - Проверьте, видите ли вы загруженный здесь файл DCM.
Заметка
- Имя файла может измениться при загрузке на сервер. Однако содержимое файла остается неизменным.
- Информацию об ограничениях на размер файла см. в разделе Размер файла для загрузки.
Создайте ярлык в бронзовом хранилище и озеро данных для файла DICOM, хранящегося в папке Data Lake Storage Gen2. Следуйте инструкциям в разделе Создание ярлыка Azure Data Lake Storage Gen2.
- Для службы DICOM Azure убедитесь, что вы используете учетную запись Data Lake Storage Gen2, созданную с помощью службы.
- Если вы не используете службу DICOM Azure, вы можете создать новую учетную запись Data Lake Storage Gen2 или использовать существующую. Чтобы узнать больше, см. раздел Создание учетной записи хранения для использования Azure Data Lake Storage.
Для обеспечения единообразия используйте следующую структуру папок для создания ярлыка:
Files\External\Imaging\DICOM\[Namespace]\[BYOSShortcutName]. ЗначениеNamespaceобеспечивает логическое разделение ярлыков из разных исходных систем. Например, вы можете использовать имя Data Lake Storage Gen2 дляNamespaceзначения.
Заметка
Ярлыки OneLake также поддерживают несколько систем хранения данных помимо Data Lake Storage Gen2. Полный список поддерживаемых типов хранилищ см. в разделе Сочетания клавиш OneLake.
Настройте администратора хранилище и озеро данных для включения BYOS:
Перейдите в healthcare#_msft_admin хранилище и озеро данных и откройте файл deploymentParametersConfiguration.json в
Files\system-configurations.Включите настройку BYOS в этом файле конфигурации. Используйте проводник OneLake, чтобы открыть файл deploymentParametersConfiguration.json из следующей папки:
OneLake - Microsoft\[WorkspaceName]\healthcare#_msft_admin.Lakehouse\Files\system-configurations. Используйте любой JSON-редактор или текстовый редактор (например, Windows Notepad), чтобы открыть файл, найдите параметрbyos_enabledи установите для него значение true.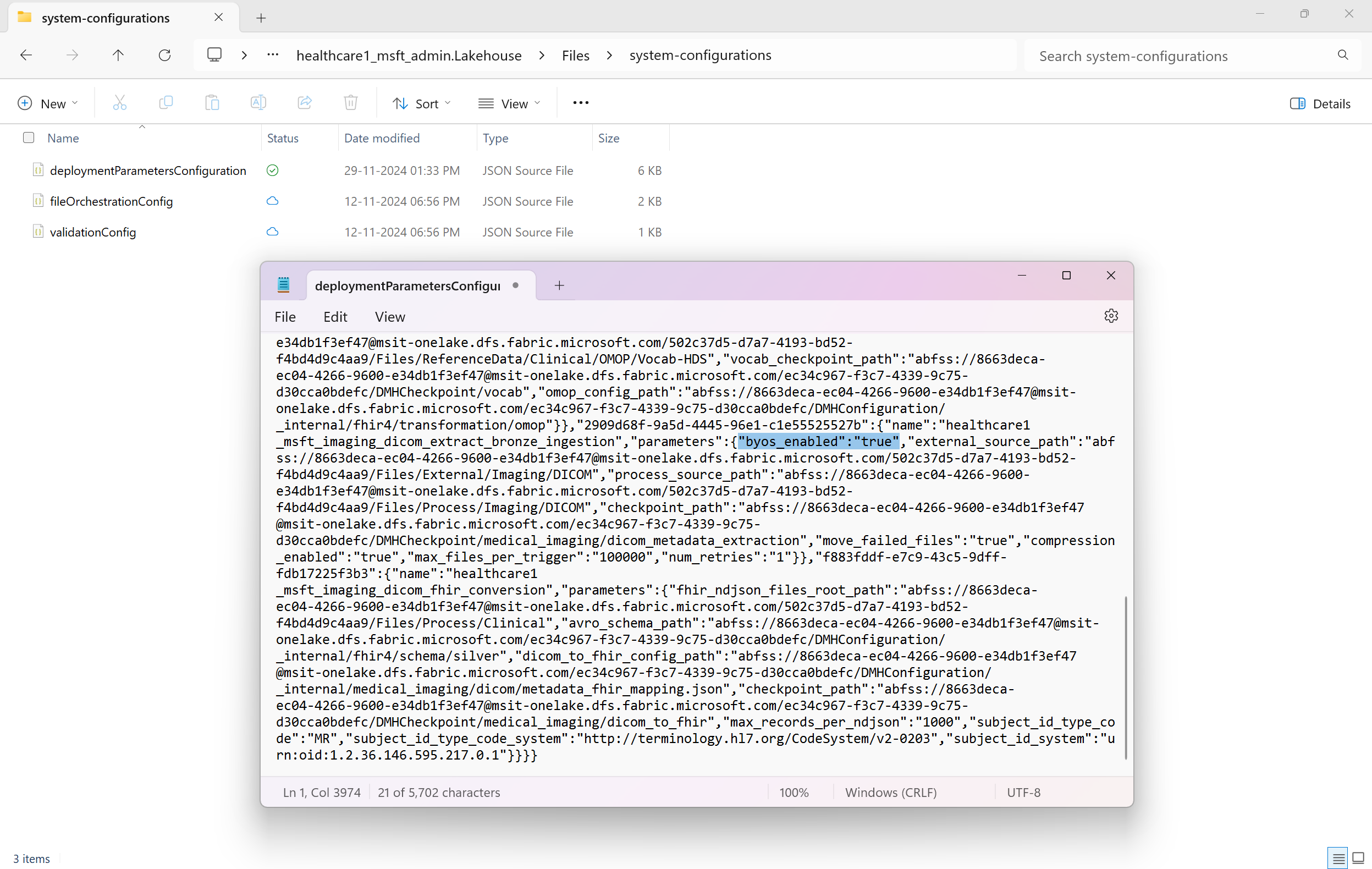
Функция преобразования данных DICOM теперь может получить доступ ко всем вашим файлам DICOM в их исходном расположении Data Lake Storage Gen2, независимо от иерархии/структуры папок. Вам не нужно вручную загружать файлы DICOM, как это делается в опции Загрузить . Начните выполнение с шаг 2: Запустите конвейер обработки данных изображений из предыдущего раздела, чтобы использовать конвейер обработки изображений и преобразовать данные DICOM.



Заметка
Чтобы понять ограничения интеграции со службой Azure Health Data Services DICOM, см. раздел Интеграция со службой DICOM.