Руководство по обнаружению связей в наборе данных Synthea с помощью семантической ссылки
В этом руководстве показано, как обнаруживать связи в общедоступном наборе данных Synthea с помощью семантической ссылки.
При работе с новыми данными или без существующей модели данных может быть полезно автоматически обнаруживать связи. Это обнаружение связей поможет вам:
- понимать модель на высоком уровне
- получите больше аналитических сведений во время исследовательского анализа данных
- проверка обновленных данных или новых, входящих данных и
- очистка данных.
Даже если отношения известны заранее, поиск связей может помочь лучше понять модель данных или определить проблемы с качеством данных.
В этом руководстве вы начинаете с простого базового примера, в котором вы экспериментируете только с тремя таблицами, чтобы связи между ними было легко понять. Затем вы показываете более сложный пример с большим набором таблиц.
В этом руководстве описано, как:
- Используйте компоненты семантической библиотеки Python (SemPy), которые поддерживают интеграцию с Power BI и помогают автоматизировать анализ данных. К этим компонентам относятся:
- FabricDataFrame — структура, напоминающая pandas, улучшенная за счет дополнительной семантической информации.
- Функции для извлечения семантических моделей из рабочей области Fabric в записную книжку.
- Функции, автоматизирующие обнаружение и визуализацию связей в семантических моделях.
- Устранение неполадок при обнаружении связей для семантических моделей с несколькими таблицами и взаимозависимостями.
Необходимые условия
Получите подписку Microsoft Fabric. Или зарегистрируйтесь для бесплатной пробной версии Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

- Выберите рабочие области в левой панели навигации, чтобы найти и выбрать свою рабочую область. Эта рабочая область становится текущей рабочей областью.
Следуйте инструкциям в записной книжке
Блокнот relationships_detection_tutorial.ipynb сопровождает это руководство.
Чтобы открыть сопровождающую записную книжку для этого руководства, следуйте инструкциям в Подготовьте вашу систему для руководств по обработке данных, чтобы импортировать записную книжку в рабочую область.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Не забудьте подключить lakehouse к ноутбуку перед началом выполнения кода.
Настройка записной книжки
В этом разделе описана настройка среды записной книжки с необходимыми модулями и данными.
Установите
SemPyиз PyPI с помощью возможности интегрированной установки%pipв записной книжке.%pip install semantic-linkВыполните необходимые импорты модулей SemPy, которые потребуются позже:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Импортируйте pandas для внедрения опции, которая помогает форматировать вывод.
import pandas as pd pd.set_option('display.max_colwidth', None)Извлеките образец данных. В этом руководстве вы используете набор данных Synthea синтетических медицинских записей (небольшая версия для простоты):
download_synthea(which='small')
Обнаружение связей в небольшом подмножестве таблиц Synthea
Выберите три таблицы из большего набора:
-
patientsуказывает сведения о пациенте -
encountersуказывает пациентов, которые имели медицинские встречи (например, медицинская встреча, процедура) -
providersуказывает, какие медицинские работники обслуживали пациентов
Таблица
encountersразрешает связь многие ко многим междуpatientsиprovidersи может быть описана как ассоциативная сущность .patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
Поиск связей между таблицами с помощью функции
find_relationshipsSemPy:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsВизуализировать отношения DataFrame в виде графа с помощью функции
plot_relationship_metadataSemPy.plot_relationship_metadata(suggested_relationships)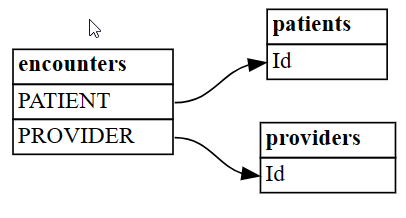
Функция описывает иерархию связей с левой стороны на правую сторону, которая соответствует таблицам "from" и "to" в выходных данных. Другими словами, независимые таблицы "от" на левой стороне используют свои внешние ключи, чтобы указать на их "к" таблицам зависимостей справа. В каждом блоке сущности отображаются столбцы, участвующие в стороне "от" или "до" связи.
По умолчанию связи создаются как "m:1" (не как "1:m") или "1:1". Связи "1:1" могут быть созданы одним или обоими способами в зависимости от того, превышает ли соотношение сопоставленных значений ко всем значениям
coverage_thresholdтолько в одном или обоих направлениях. Далее в этом руководстве описаны менее частые случаи связей m:m.

Устранение неполадок обнаружения связей
В базовом примере показано успешное обнаружение связей при очистке данных Synthea. На практике данные редко очищаются, что предотвращает успешное обнаружение. Существует несколько методов, которые могут быть полезны, когда данные не очищены.
В этом разделе этого руководства рассматривается обнаружение связей, когда семантическая модель содержит грязные данные.
Начните с управления исходными кадрами данных, чтобы получить "грязные" данные и распечатать размер грязных данных.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Для сравнения размеры печати исходных таблиц:
print(len(patients)) print(len(providers))Поиск связей между таблицами с помощью функции
find_relationshipsSemPy:find_relationships([patients_dirty, providers_dirty, encounters])В выходных данных кода показано, что связи не обнаружены из-за ошибок, введенных ранее для создания "грязной" семантической модели.
Используйте проверку
Проверка — это лучший инструмент для устранения ошибок обнаружения связей, так как:
- Он ясно объясняет, почему определенная связь не соответствует правилам внешнего ключа и вследствие этого не может быть обнаружена.
- Он работает быстро с большими семантических моделями, так как он фокусируется только на объявленных отношениях и не выполняет поиск.
Проверка может использовать любой кадр данных с столбцами, аналогичными столбцам, созданным find_relationships. В следующем коде кадр данных suggested_relationships ссылается на patients, а не на patients_dirty, но можно псевдонимировать кадры данных с помощью словаря:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Ослабить критерии поиска
В более мрачных сценариях вы можете попробовать освободить критерии поиска. Этот метод повышает вероятность ложных срабатываний.
Задайте
include_many_to_many=Trueи оцените, помогает ли она:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Результаты показывают, что связь от
encountersкpatientsобнаружена, но есть две проблемы:- Связь указывает направление от
patientsкencounters, что является обратным ожидаемому соотношением. Это связано с тем, что всеpatientsбыло охваченоencounters(Coverage Fromсоставляет 1,0), в то время какencountersтолько частично охватываютсяpatients(Coverage To= 0,85), так как строки пациентов отсутствуют. - Существует случайное совпадение в столбце
GENDERс низкой кардинальностью, которое по имени и значению совпадает в обеих таблицах, но не представляет значимого отношения "m:1". Низкую кратность показывают столбцыUnique Count FromиUnique Count To.
- Связь указывает направление от
Запустите заново
find_relationshipsдля нахождения только связей "m:1", но с уменьшенным значениемcoverage_threshold=0.5.find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Результат показывает правильное направление связей от
encountersкproviders. Однако связь отencountersкpatientsне обнаружена, так какpatientsне уникальна, поэтому она не может находиться на стороне "Один" связи "m:1".Ослабьте как
include_many_to_many=True, так иcoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Теперь оба отношения интереса видны, но есть гораздо больше шума:
- Совпадение с низким кратностью на
GENDERприсутствует. - На
ORGANIZATIONпоявилась более высокая кратность "m:m", что делает очевидным, чтоORGANIZATION, вероятно, является денормализованным столбцом в обеих таблицах.
- Совпадение с низким кратностью на
Сопоставление имен столбцов
По умолчанию SemPy рассматривает как совпадения только атрибутов, которые показывают сходство имен, используя тот факт, что конструкторы баз данных обычно называют связанные столбцы таким же образом. Это поведение помогает избежать ложных связей, которые чаще всего происходят с низкой кардинальностью целочисленных ключей. Например, если существуют 1,2,3,...,10 категории продуктов и 1,2,3,...,10 код состояния заказа, они будут путаться друг с другом при просмотре только сопоставлений значений без учета имен столбцов. Спрогнозные связи не должны быть проблемой с такими ключами, как GUID.
SemPy смотрит на сходство между именами столбцов и именами таблиц. Сопоставление является приблизительным и не учитывает регистр. Он игнорирует наиболее часто встречающиеся подстроки "декоратора", такие как "id", "code", "name", "key", "pk", "fk". В результате наиболее типичные случаи совпадения:
- Атрибут, называемый "column" в сущности foo, совпадает с атрибутом с названием "column" (а также "COLUMN" или "Column") в сущности bar.
- Атрибут с именем 'column' в сущности 'foo' совпадает с атрибутом с именем 'column_id' в сущности 'bar'.
- Атрибут с именем "bar" в сущности 'foo' соответствует атрибуту с именем "code" в 'bar'.
При первом сопоставлении имен столбцов обнаружение выполняется быстрее.
Соотнесите имена столбцов.
- Чтобы понять, какие столбцы выбираются для дальнейшей оценки, используйте параметр
verbose=2(verbose=1перечисляет только обрабатываемые сущности). - Параметр
name_similarity_thresholdопределяет, как сравниваются столбцы. Пороговое значение 1 указывает, что вам нужно только 100% совпадения.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);Выполнение в 100% сходства не учитывает небольшие различия между именами. В примере таблицы имеют форму множественного числа с суффиксом "s", что приводит к отсутствии точного совпадения. По умолчанию это хорошо обрабатывается с
name_similarity_threshold=0.8.- Чтобы понять, какие столбцы выбираются для дальнейшей оценки, используйте параметр
Повторное выполнение с помощью
name_similarity_threshold=0.8по умолчанию:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Обратите внимание, что идентификатор для множественной формы
patientsтеперь сравнивается с единственнойpatientбез добавления слишком большого количества других лишних сравнений ко времени выполнения.Повторное выполнение с помощью
name_similarity_threshold=0по умолчанию:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Изменение
name_similarity_thresholdна 0 — это другая крайняя, и это означает, что вы хотите сравнить все столбцы. Это редко необходимо и приводит к увеличению времени выполнения и ложным совпадениям, которые необходимо проверить. Наблюдайте за количеством сравнений в детализированном выводе.
Советы по устранению неполадок
- Начиная с точного соответствия для связей "m:1" (то есть по умолчанию
include_many_to_many=Falseиcoverage_threshold=1.0). Обычно это то, что вы хотите. - Используйте узкий фокус на небольших подмножествах таблиц.
- Используйте проверку для обнаружения проблем с качеством данных.
- Используйте
verbose=2, если вы хотите понять, какие столбцы считаются в контексте взаимосвязей. Это может привести к большому количеству выходных данных. - Помните о компромиссах аргументов поиска.
include_many_to_many=Trueиcoverage_threshold<1.0могут создавать ложные связи, анализ которых может быть сложнее и потребует фильтрации.
Обнаружьте связи в полном наборе данных Synthea
Простой базовый пример — это удобное средство обучения и устранения неполадок. На практике можно начать с семантической модели, например полного набора данных Synthea, который имеет гораздо больше таблиц. Изучите полный набор данных synthea следующим образом.
Прочитайте все файлы из каталога synthea/csv.
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Поиск связей между таблицами с помощью функции
find_relationshipsSemPy:suggested_relationships = find_relationships(all_tables) suggested_relationshipsВизуализировать связи:
plot_relationship_metadata(suggested_relationships)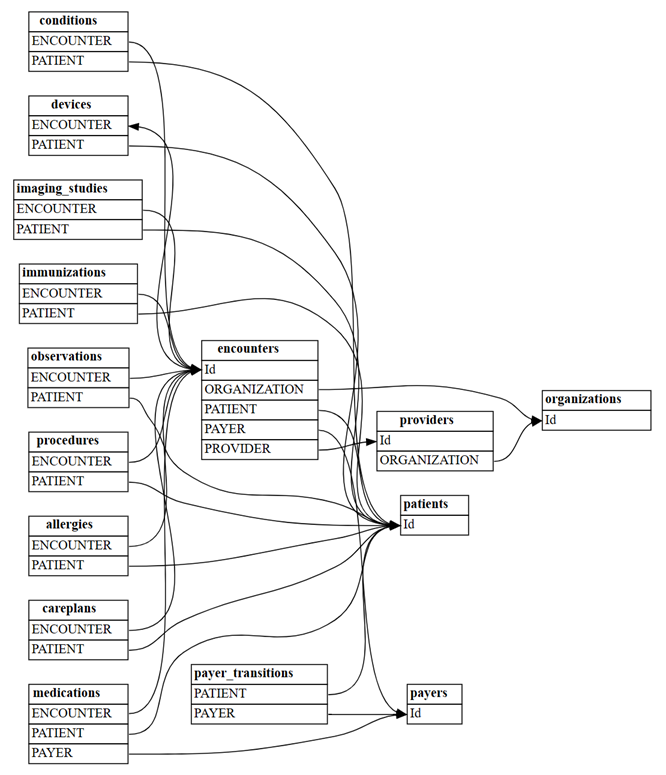
Подсчитывайте, сколько новых связей "m:m" будет обнаружено с помощью
include_many_to_many=True. Эти отношения являются дополнением к показанным ранее отношениям "m:1", поэтому необходимо отфильтровать поmultiplicity:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']Вы можете сортировать данные связи по различным столбцам, чтобы получить более глубокое представление об их природе. Например, можно упорядочить выходные данные по
Row Count FromиRow Count To, которые помогают определить самые большие таблицы.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)В другой семантической модели, возможно, важно сосредоточиться на количестве значений NULL
Null Count FromилиCoverage To.Этот анализ поможет вам понять, может ли какая-либо из связей быть недопустимыми, и если необходимо удалить их из списка кандидатов.

Связанное содержимое
Ознакомьтесь с другими руководствами по семантической ссылке / SemPy:
- Руководство: Очистка данных с помощью функциональных зависимостей
- Руководство: Анализ функциональных зависимостей в примере семантической модели
- Руководство по : обнаружение связей в семантической модели с помощью семантического звена
- руководство по . Извлечение и вычисление мер Power BI из записной книжки Jupyter