Руководство: Анализ функциональных зависимостей в семантической модели
В этом руководстве вы развиваете предыдущую работу, выполненную аналитиком Power BI, которая хранится в виде семантических моделей (наборов данных Power BI). Используя SemPy (предварительная версия) в интерфейсе Synapse Data Science в Microsoft Fabric, вы анализируете функциональные зависимости, которые существуют в столбцах DataFrame. Этот анализ помогает обнаружить нетривиальные проблемы с качеством данных, чтобы получить более точные аналитические сведения.
В этом руководстве описано, как:
- Применение знаний домена для формирования гипотез о функциональных зависимостях в семантической модели.
- Ознакомьтесь с компонентами библиотеки Python семантической связи (SemPy), которые поддерживают интеграцию с Power BI и помогают автоматизировать анализ качества данных. К этим компонентам относятся:
- FabricDataFrame — структура, похожая на pandas и дополненная дополнительной семантической информацией.
- Полезные функции для извлечения семантических моделей из рабочей области Fabric в ноутбук.
- Полезные функции, которые автоматизируют оценку гипотез о функциональных зависимостях и определяют нарушения связей в семантических моделях.
Необходимые условия
Получите подписку Microsoft Fabric. Или зарегистрируйтесь для бесплатной пробной версии Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

Выберите рабочие области в области навигации слева, чтобы найти и выбрать вашу рабочую область. Эта рабочая область становится текущей рабочей областью.
Скачайте файл семантической модели Customer Profitability Sample.pbix из репозитория GitHub примеров структуры fabric .
В рабочей области выберите Импорт отчета>или отчета с разбивкой на страницы>с этого компьютера, чтобы загрузить файл Customer Profitability Sample.pbix в рабочую область.
Следуйте инструкциям в записной книжке
Этот учебник сопровождается записной книжкой powerbi_dependencies_tutorial.ipynb.
Чтобы открыть сопровождающую записную книжку для этого руководства, следуйте инструкциям в разделе "Подготовьте вашу систему для руководств по науке о данных", чтобы импортировать записную книжку в рабочую область.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Не забудьте присоединить lakehouse к ноутбуку перед запуском кода.
Настройка записной книжки
В этом разделе описана настройка среды записной книжки с необходимыми модулями и данными.
Установите
SemPyиз PyPI с помощью встроенной функции установки%pipв записной книжке.%pip install semantic-linkВыполните необходимые импорты модулей, которые потребуются вам позже:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Загрузка и предварительная обработка данных
В этом руководстве используется стандартная семантическая модель Customer Profitability Sample.pbix. Для описания семантической модели см. пример рентабельности клиентов для Power BI .
Загрузите данные Power BI в FabricDataFrames с помощью функции
read_tableSemPy:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Загрузите таблицу
Stateв FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()Хотя результат выполнения этого кода выглядит как DataFrame из библиотеки pandas, на самом деле вы инициализировали структуру данных под названием
FabricDataFrame, которая поддерживает некоторые полезные операции на основе pandas.Проверьте тип данных
customer:type(customer)Выходные данные подтверждают, что
customerимеет типsempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.'Объедините фреймы данных
customerиstate:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Определение функциональных зависимостей
Функциональная зависимость проявляется как связь "один ко многим" между значениями в двух (или более) столбцах в таблице данных. Эти связи можно использовать для автоматического обнаружения проблем с качеством данных.
Запустите функцию SemPy
find_dependenciesв объединенном кадре данных, чтобы определить существующие функциональные зависимости между значениями в столбцах:dependencies = customer_state_df.find_dependencies() dependenciesВизуализация определенных зависимостей с помощью
plot_dependency_metadataфункции SemPy:plot_dependency_metadata(dependencies)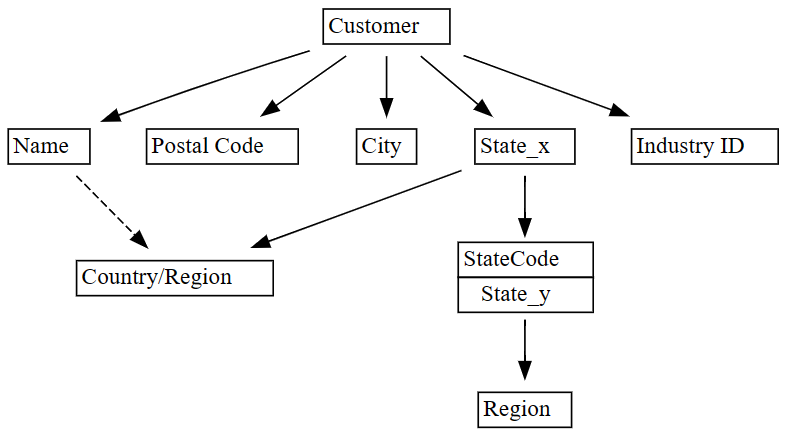
Как ожидается, график функциональных зависимостей показывает, что столбец
Customerопределяет некоторые столбцы, такие какCity,Postal CodeиName.Удивительно, что граф не показывает функциональную зависимость между
CityиPostal Code, вероятно, потому что между столбцами существует много нарушений. Вы можете использовать функцию SemPyplot_dependency_violationsдля визуализации нарушений зависимостей между определенными столбцами.

Изучение данных о проблемах с качеством
Нарисуйте граф с помощью функции визуализации
plot_dependency_violationsSemPy.customer_state_df.plot_dependency_violations('Postal Code', 'City')
На графике нарушений зависимостей отображаются значения
Postal Codeна левой стороне и значения дляCityсправа. Ребро соединяетPostal Codeс левой стороны сCityс правой стороны, если найдётся строка, содержащая оба этих значения. Края аннотированы с количеством таких строк. Например, есть две строки с почтовым кодом 20004, один с городом "Северная башня" и другой с городом "Вашингтон".Кроме того, на графике показаны несколько нарушений и много пустых значений.
Подтвердите число пустых значений для
Postal Code:customer_state_df['Postal Code'].isna().sum()50 строк имеют NA для почтового индекса.
Удалите строки с пустыми значениями. Затем найдите зависимости с помощью функции
find_dependencies. Обратите внимание на дополнительный параметрverbose=1, который предлагает представление о внутренних работах SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Условная энтропия для
Postal CodeиCityсоставляет 0,049. Это значение указывает на наличие нарушений функциональной зависимости. Перед исправлением нарушений добавьте пороговое значение условной энтропии из значения по умолчанию0.01до0.05, чтобы увидеть зависимости. Более низкие пороговые значения приводят к уменьшению числа зависимостей (или более высокой избирательности).Повышение порога условной энтропии от значения по умолчанию
0.01до0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))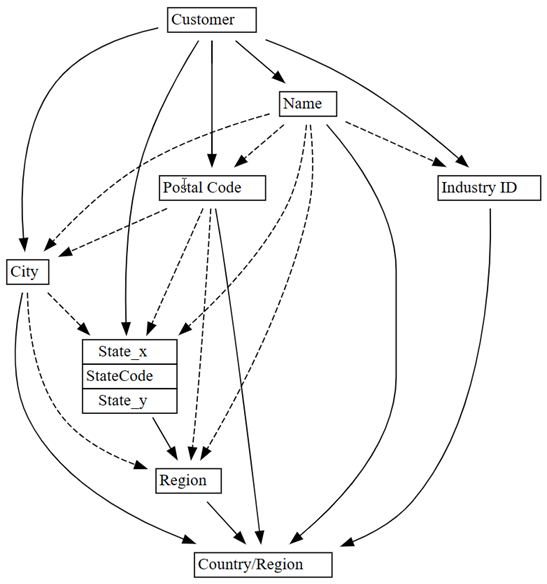
Если применить знания о домене, которая сущность определяет значения других сущностей, то этот граф зависимостей кажется точным.
Ознакомьтесь с дополнительными проблемами с качеством данных, обнаруженными. Например, пунктирная стрелка соединяет
CityсRegion, это указывает на то, что зависимость является только приблизительной. Эта приблизительная связь может означать, что существует частичная функциональная зависимость.customer_state_df.list_dependency_violations('City', 'Region')Внимательно изучите каждый из случаев, когда ненулевое значение
Regionприводит к нарушению.customer_state_df[customer_state_df.City=='Downers Grove']Результат показывает город Даунингс Гроув, расположенный в штатах Иллинойс и Небраска. Тем не менее, Даунерс-Гроув — это город в Иллинойсе, а не в Небраске.
Взгляните на город Фремонт:
customer_state_df[customer_state_df.City=='Fremont']В Калифорнии есть город, который называется Фремонт. Однако для Техаса поисковая система возвращает Premont, а не Фремонт.
Также подозрительно видеть нарушения зависимости между
NameиCountry/Region, что обозначено пунктирной линией в исходном графе нарушений зависимости (до удаления строк с пустыми значениями).customer_state_df.list_dependency_violations('Name', 'Country/Region')По-видимому, один клиент, SDI Design присутствует в двух регионах — Соединенных Штатах и Канаде. Это событие может не быть семантической нарушением, но может быть просто редким случаем. Тем не менее, стоит взглянуть:
Ознакомьтесь с клиентом SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']Дополнительные проверки показывают, что это на самом деле два разных клиента из разных отраслей промышленности с одинаковым именем.

Исследовательский анализ данных — это захватывающий процесс, и очистка данных тоже. Всегда есть что-то, что данные скрывают, в зависимости от того, как вы на это смотрите, что вы хотите узнать, и т. д. Семантическая ссылка предоставляет новые средства, которые можно использовать для получения дополнительных возможностей с данными.
Связанное содержимое
Ознакомьтесь с другими руководствами по семантической ссылке / SemPy:
- Руководство: Очистка данных с помощью функциональных зависимостей
- руководство по . Извлечение и вычисление мер Power BI из записной книжки Jupyter
- Учебник : Обнаружение связей в семантической модели, используя семантическую связь
- Руководство по . Обнаружение связей в наборе данных Synthea с помощью семантической связи
- Руководство по . Проверка данных с помощью SemPy и больших ожиданий (GX)