Результаты поиска фигуры или изменение композиции результатов поиска в службе "Поиск ИИ Azure"
В этой статье объясняется, как создавать результаты поиска и формировать результаты поиска в соответствии с вашими сценариями. Результаты поиска возвращаются в ответе запроса. Форма ответа определяется параметрами в самом запросе. Это следующие параметры.
- Количество совпадений, найденных в индексе (
count) - Количество совпадений, возвращаемых в ответе (50 по умолчанию, настраиваемое по
topумолчанию) или на страницу (skipиtop) - Оценка поиска для каждого результата, используемого для ранжирования (
@search.score) - Поля, включенные в результаты поиска (
select) - Логика сортировки (
orderby) - Выделение терминов в результатах, сопоставление по всему или частичному термину в тексте
- Необязательные элементы из семантического рангера (
answersв верхней частиcaptionsдля каждого совпадения)
Результаты поиска могут включать поля верхнего уровня, но большая часть ответа состоит из сопоставления документов в массиве.
Клиенты и API-интерфейсы для определения ответа запроса
Для настройки ответа запроса можно использовать следующие клиенты:
- Обозреватель поиска в портал Azure с помощью представления JSON, чтобы указать любой поддерживаемый параметр
- Документы — POST (REST API)
- Метод SearchClient.Search (Пакет SDK Azure для .NET)
- Метод SearchClient.Search (Пакет SDK Azure для Python)
- Метод SearchClient.Search (Azure для JavaScript)
- Метод SearchClient.Search (Azure для Java)
Композиция результатов
Результаты в основном табличные, состоящие из полей всех retrievable полей или ограничены только этими полями, указанными в параметре select . Строки — это соответствующие документы, которые обычно ранжируются в порядке релевантности, если логика запроса не исключает ранжирование релевантности.
Вы можете выбрать, какие поля находятся в результатах поиска. Хотя в документе поиска может быть большое количество полей, обычно требуется лишь несколько, чтобы представить каждый документ в результатах. В запросе добавьте select=<field list> , чтобы указать, какие retrievable поля должны отображаться в ответе.
Выберите поля, которые предлагают контрастность и различие между документами, предоставляя достаточную информацию, чтобы пригласить ответ на щелчки по части пользователя. На сайте электронной коммерции может присутствовать название продукта, описание, фирменная символика, цвет, размер, цена и рейтинг. Для встроенного индекса hotels-sample это могут быть поля select в следующем примере:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Советы по непредвиденным результатам
Иногда выходные данные запроса не отображаются. Например, вы можете обнаружить, что некоторые результаты, как представляется, дублируются, или результат, который должен отображаться в верхней части, расположен ниже в результатах. Если результаты поиска не соответствует ожиданиям, можно попробовать изменить запрос и проверить, не улучшились ли результаты, как описано ниже.
Измените
searchMode=any(по умолчанию) наsearchMode=all, чтобы потребовать соответствие всем указанным условиям, а не любому из них. Это особенно важно, если запрос содержит логические операторы.Поэкспериментируйте с различными лексическими анализаторами или пользовательскими анализаторами, чтобы узнать, изменятся ли результаты поиска. Анализатор по умолчанию разбивает дефисированные слова и сокращает слова на корневые формы, что обычно повышает надежность ответа на запрос. Однако, если необходимо сохранить дефисы или если строки содержат специальные символы, может потребоваться настроить пользовательские анализаторы, чтобы убедиться, что индекс содержит маркеры в правильном формате. Для получения дополнительной информации см. раздел Поиск частично введенных слов и шаблоны со специальными символами (дефисы, подстановочные знаки, регулярные выражения, шаблоны).
Подсчет совпадений
Параметр count возвращает количество документов в индексе, которое считается совпадением для запроса. Чтобы вернуть количество, добавьте count=true в запрос запроса. Нет максимального значения, введенного службой поиска. В зависимости от запроса и содержимого документов число может быть максимально высоким, чем каждый документ в индексе.
Количество точных значений, когда индекс является стабильным. Если система активно добавляет, обновляет или удаляет документы, это приблизительное число, за исключением документов, которые не полностью индексированы.
Количество не влияет на регулярное обслуживание или другие рабочие нагрузки в службе поиска. Однако при наличии нескольких секций и одной реплики можно столкнуться с краткосрочными колебаниями количества документов (несколько минут) при перезапуске секций.
Совет
Чтобы проверить операции индексирования, можно проверить, содержит ли индекс ожидаемое количество документов, добавив count=true в пустой search=* поисковый запрос. Результатом является полное количество документов в индексе.
При тестировании синтаксиса запросов можно быстро определить, count=true возвращаются ли изменения больше или меньше результатов, что может быть полезной обратной связью.
Количество результатов в ответе
Поиск azure AI использует разбиение на разных страницах на стороне сервера, чтобы предотвратить получение слишком большого количества документов одновременно. Параметры запроса, определяющие количество результатов в ответе, и topskip.
top ссылается на количество результатов поиска на странице.
skip — это интервал top, и он сообщает поисковой системе, сколько результатов пропустить перед получением следующего набора.
Размер страницы по умолчанию — 50, а максимальный размер страницы — 1000. Если указать значение больше 1000 и в индексе найдено более 1000 результатов, возвращаются только первые 1000 результатов. Если количество совпадений превышает размер страницы, ответ содержит сведения для получения следующей страницы результатов. Например:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
Верхние совпадения определяются оценкой поиска, если запрос является полным текстовым поиском или семантикой. В противном случае верхние совпадения являются произвольным порядком для точных запросов соответствия (где однородное @search.score=1.0 указывает произвольный рейтинг).
Задайте top для переопределения значение по умолчанию 50. Если вы используете гибридный запрос, вы можете указать maxTextRecallSize для возврата до 10 000 документов.
Для управления разбиением по страницам всех документов, возвращаемых в результирующем наборе, используйте top и skip вместе. Этот запрос возвращает первый набор из 15 соответствующих документов, а также количество общих совпадений.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
Этот запрос возвращает второй набор, пропуская первые 15, чтобы получить следующий 15 (16–30):
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
Результаты запросов с разбивкой на страницы не будут стабильными, если базовый индекс изменяется. Разбиение по страницам изменяет значение skip для каждой страницы, но каждый запрос является независимым и работает с текущим представлением данных, так как он существует в индексе во время запроса (другими словами, кэширование или моментальный снимок результатов, таких как те, которые находятся в базе данных общего назначения).
Ниже приведен пример того, в каком случае можно получить дубликаты. Предположим, что индекс имеет четыре документа.
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Теперь предположим, что вы хотите, чтобы результаты возвращались по два за раз, упорядоченные по рейтингу. Вы сделаете этот запрос для получения первой страницы: $top=2&$skip=0&$orderby=rating desc, что выдаст следующие результаты.
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
Предположим, что во время работ по обслуживанию в индекс между запросами добавляется пятый документ: { "id": "5", "rating": 4 }. Вскоре после этого вы выполните запрос для получения второй страницы: $top=2&$skip=2&$orderby=rating desc и получите следующие результаты.
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Обратите внимание, что документ 2 извлекается дважды. Это связано с тем, что новый документ 5 имеет большее значение рейтинга, поэтому он при сортировке попадает в индекс раньше документа 2 и появляется на первой странице. Хотя такое поведение может быть неожиданным, обычно оно характерно для поисковой системы.
Разбиение по страницам с большим количеством результатов
Альтернативный способ разбиения по страницам — использовать порядок сортировки и фильтр диапазона в качестве обходного skipрешения.
В этом обходном пути сортировка и фильтрация применяются к полю идентификатора документа или другому полю, уникальному для каждого документа. Уникальное поле должно иметь filterable и sortable указывать в индексе поиска.
Выполните запрос, чтобы вернуть полную страницу отсортированных результатов.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Выберите последний результат, возвращенный поисковым запросом. Ниже показан пример результата только значения идентификатора.
{ "id": "50" }Используйте это значение идентификатора в запросе диапазона, чтобы получить следующую страницу результатов. Это поле идентификатора должно иметь уникальные значения, в противном случае разбиение на страницы может содержать повторяющиеся результаты.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Разбиение на страницы заканчивается, когда запрос возвращает нулевых результатов.
Примечание.
sortable Атрибуты filterable можно включить только при первом добавлении поля в индекс, они не могут быть включены в существующем поле.
Упорядочение результатов
В запросе полнотекстового поиска результаты могут быть ранжированы следующим образом:
- оценка поиска
- оценка семантического повтора
- порядок сортировки
sortableв поле
Вы также можете повысить число совпадений, найденных в определенных полях, добавив профиль оценки.
Порядок по оценке поиска
Для запросов полнотекстового поиска результаты автоматически ранжируются по оценке поиска с помощью алгоритма BM25, вычисляемого на основе частоты терминов, длины документа и средней длины документа.
Диапазон @search.score не связан или равен 0 (но не включая) 1.00 в старых службах.
Для любого алгоритма @search.score значение равно 1.00 указывает некоррегированную или неуправляемую результирующий набор, где оценка 1.0 является единообразной для всех результатов. Неподписанные результаты возникают, когда форма запроса является нечетким поиском, подстановочными знаками или регулярными запросами или пустым поиском (search=*). Если необходимо наложить структуру ранжирования на некорпорированные результаты, рассмотрите orderby выражение для достижения этой цели.
Порядок по семантическому повторному рангу
Если вы используете семантический рангировщик, @search.rerankerScore определяет порядок сортировки результатов.
Диапазон @search.rerankerScore составляет от 1 до 4,00, где более высокий показатель указывает на более сильное семантические совпадения.
Заказ с orderby
Если согласованное упорядочение является требованием приложения, можно определить orderby выражение в поле. Для упорядочивания результатов можно использовать только поля, индексированные как "сортируемые".
Поля, часто используемые в рейтинге orderby , дате и расположении. Для фильтрации по расположению требуется, чтобы выражение фильтра вызывает geo.distance() функцию в дополнение к имени поля.
Числовые поля (, Edm.Int32, Edm.Int64) сортируются в числовом порядке (Edm.Doubleнапример, 1, 2, 10, 11, 20).
Строковые поля (Edm.ComplexTypeEdm.Stringподфилды) сортируются в порядке сортировки ASCII или порядке сортировки Юникода в зависимости от языка.
Числовое содержимое в строковых полях отсортировано по алфавиту (1, 10, 11, 2, 20).
Верхний регистр строки сортируются впереди нижнего регистра (APPLE, Apple, БАНАН, Банан, яблоко, банан). Вы можете назначить нормализатор текста для предварительной обработки текста перед сортировкой, чтобы изменить это поведение. Использование нижнего регистра токенизатора в поле не влияет на поведение сортировки, так как поиск Azure AI сортируется по неанализируемой копии поля.
Строки, которые приводят с diacritics, появляются последние (Äpfel, Öffnen, Üben)
Повышение релевантности с помощью профиля оценки
Другой подход, который способствует согласованности заказов, — использование пользовательского профиля оценки. Профили повышения обеспечивают более полный контроль над ранжированием элементов в результатах поиска с возможностью увеличения рейтинга соответствий, найденных в конкретных полях. Дополнительная логика оценки может помочь переопределить незначительные различия между репликами, так как оценки поиска для каждого документа находятся дальше друг от друга. Для этого подхода рекомендуется использовать алгоритм ранжирования.
Выделение совпадений
Выделение совпадений означает форматирование текста (например, выделение полужирным или желтым цветом), применяемое для сопоставления терминов в результате, что позволяет легко обнаружить совпадение. Выделение полезно для более длинных полей содержимого, таких как поле описания, где совпадение не сразу очевидно.
Обратите внимание, что выделение применяется к отдельным терминам. Для содержимого всего поля нет возможности выделения. Если вы хотите выделить фразу, необходимо указать соответствующие термины (или фразу) в строке запроса, заключенной в кавычки. Этот метод описан далее в этом разделе.
Инструкции по выделению совпадений предоставляются в запросе. Запросы, которые активируют расширение запросов в алгоритме поиска, например поиск нечетких совпадений и поиск с подстановочными знаками, имеют ограниченную поддержку выделения совпадений.
Требования к выделению попаданий
- Поля должны быть
Edm.StringилиCollection(Edm.String) - Поля должны быть атрибутами
searchable
Указание выделения в запросе
Чтобы вернуть выделенные термины, включите параметр выделения в запрос. Параметр имеет список полей с разделителями-запятыми.
По умолчанию разметка формата имеет значение <em>, но вы можете переопределить тег с помощью highlightPreTag и highlightPostTag параметрами. Клиентский код обрабатывает ответ (например, применение полужирного шрифта или желтого фона).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
По умолчанию поиск ИИ Azure возвращает до пяти выделений на поле. Это число можно изменить, добавив тире, за которым следует целое число. Например, "highlight": "description-10" возвращает до 10 выделенных терминов для сопоставления содержимого в поле описания.
Выделенные результаты
При добавлении выделения в запрос ответ включает в себя @search.highlights каждый результат, чтобы код приложения смог нацелиться на такую структуру. Список полей, указанных для выделения, включается в ответ.
В поиске ключевых слов каждый термин проверяется независимо. Запрос на "божественные секреты" возвращает совпадения для любого документа, содержащего любой термин.
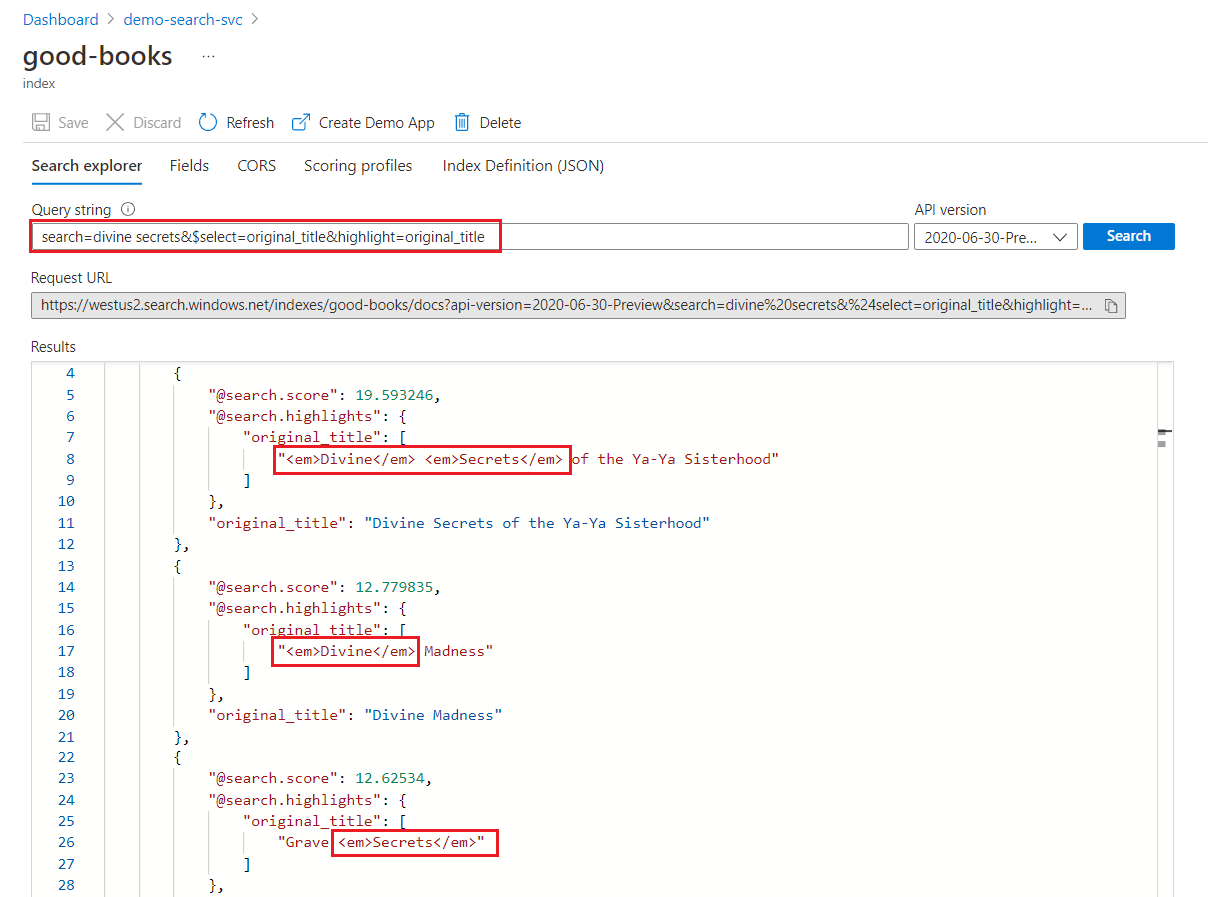
Выделение поиска ключевых слов
В выделенном поле форматирование применяется ко всем терминам. Например, на совпадении с "Божественной тайнами я-я сестры", форматирование применяется к каждому термину отдельно, даже если они последовательны.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Выделение поиска фраз
Форматирование целого термина применяется даже к поиску фраз, где несколько терминов заключены в двойные кавычки. В следующем примере представлен тот же запрос, за исключением того, что "божественные секреты" передаются как заключенная в кавычки фраза (некоторые клиенты REST требуют, чтобы вы избежали внутренние кавычки с обратной косой чертой \"):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Так как критерии теперь имеют оба термина, в индексе поиска найдено только одно совпадение. Ответ на предыдущий запрос выглядит следующим образом:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Выделение фраз в старых службах
служба , созданные до 15 июля 2020 г., реализуют другой интерфейс выделения для запросов фраз.
В следующих примерах предположим, что строка запроса, содержащая заключенную в кавычки фразу "суперкубок". До июля 2020 г. выделен любой термин в фразе:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Для служб поиска, созданных после июля 2020 года, возвращаются @search.highlightsтолько фразы, соответствующие полному запросу фраз:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Следующие шаги
Чтобы быстро создать страницу поиска для клиента, рассмотрите следующие варианты.
Создайте демонстрационное приложение в портал Azure, создает HTML-страницу с панелью поиска, фасетной навигацией и областью эскизов при наличии изображений.
Добавление поиска в приложение ASP.NET Core (MVC) — это учебник и пример кода, который создает функциональный клиент.
Добавление поиска в веб-приложения — это учебник по C# и пример кода, который использует библиотеки JavaScript React для взаимодействия с пользователем. Приложение развертывается с помощью Статические веб-приложения Azure и реализует разбивку на страницы.