Релевантность в поиске ключевых слов (оценка BM25)
В этой статье объясняется алгоритм оценки релевантности BM25, используемый для вычисления показателей поиска для полнотекстового поиска. Релевантность BM25 является эксклюзивной для полнотекстового поиска. Фильтрация запросов, автозаполнение и предлагаемые запросы, поиск подстановочных знаков и нечеткие поисковые запросы не оцениваются или ранжируются по релевантности.
Алгоритмы оценки, используемые в полнотекстовом поиске
Поиск ИИ Azure предоставляет следующие алгоритмы оценки для полнотекстового поиска:
| Алгоритм | Использование | Диапазон |
|---|---|---|
BM25Similarity |
Исправлен алгоритм для всех служб поиска, созданных после июля 2020 года. Этот алгоритм можно настроить, но вы не можете переключиться на более старый (классический). | Неограниченный. |
ClassicSimilarity |
Значение по умолчанию для старых служб поиска, предшествующих июль 2020 г. В более старых службах вы можете принять участие в BM25 и выбрать алгоритм BM25 на основе индекса. | 0 < 1.00 |
BM25 и Classic — это функции извлечения TF-IDF, которые используют частоту терминов (TF) и обратную частоту документа (IDF) в качестве переменных для вычисления показателей релевантности для каждой пары запросов к документу, которая затем используется для ранжирования результатов. Хотя концептуально похоже на классический, BM25 коренится в вероятностном получении информации, которая создает более интуитивно понятные совпадения, как измеряется исследованием пользователей.
BM25 предлагает расширенные параметры настройки, например разрешить пользователю решить, как масштабируются оценки релевантности с частотой соответствующих терминов.
Как работает ранжирование BM25
Оценка релевантности относится к вычислению оценки поиска (@search.score), которая служит индикатором релевантности элемента в контексте текущего запроса. Диапазон не связан. Тем не менее, чем выше оценка, тем более релевантный элемент.
Оценка поиска вычисляется на основе статистических свойств строковых входных данных и самого запроса. Поиск ИИ Azure находит документы, соответствующие условиям поиска (некоторые или все в зависимости от searchMode), предпочитающие документы, содержащие множество экземпляров термина поиска. Оценка поиска возрастает, если условие поиска редко встречается в индексе данных, но часто — внутри документа. Основу для такого подхода к вычислению релевантности называют TF-IDF или частотой условия — инверсная частота в документе.
Оценки поиска могут повторяться в результирующем наборе. Если несколько попаданий имеют одну и ту же оценку поиска, порядок одного и того же оцененного элемента не определен и не является стабильным. Запустите запрос еще раз, и вы можете увидеть позицию смены элементов, особенно если вы используете бесплатную службу или оплачиваемую службу с несколькими репликами. Учитывая два элемента с одинаковым показателем, нет никакой гарантии того, что он отображается в первую очередь.
Чтобы разорвать связь между повторяющимися оценками, можно добавить предложение $orderby в первый заказ по оценке, а затем упорядочить по другому поле сортировки (например, $orderby=search.score() desc,Rating desc ).
Для оценки используются только поля, помеченные как searchable индекс или searchFields в запросе. В результатах поиска возвращаются только поля, помеченные как retrievableполя, указанные в select запросе, вместе с оценкой поиска.
Примечание.
@search.score = 1 указывает на результирующий набор без оценивания или без ранжирования. Оценка одинакова для всех результатов. Результаты без оценки возникают, когда форма запроса является нечетким поиском, подстановочными знаками или регулярными запросами, или пустым поиском (search=*иногда сопряжен с фильтрами, где фильтр является основным средством для возврата совпадения).
Следующий сегмент видео выполняет быстрый переадресацию в объяснение общедоступных алгоритмов ранжирования, используемых в службе "Поиск ИИ Azure". Дополнительные сведения можно получить, просмотрев полное видео.
Оценки в текстовых результатах
Каждый раз, когда результаты ранжируются, свойство содержит значение, @search.score используемое для упорядочивания результатов.
В следующей таблице определяется свойство оценки, алгоритм и диапазон.
| Метод поиска | Параметр | Алгоритм оценки | Диапазон |
|---|---|---|---|
| полнотекстовый поиск | @search.score |
Алгоритм BM25 с использованием параметров, указанных в индексе. | Неограниченный. |
Вариант оценки
Показатели поиска дают общее представление о релевантности, отражающее качество совпадений относительно других документов в том же результирующем наборе. Но оценки не всегда согласованы с одним запросом к следующему, поэтому при работе с запросами можно заметить небольшие несоответствия в том, как упорядочены документы поиска. Существует несколько объяснений, почему это может произойти.
| Причина | Description |
|---|---|
| Идентичные результаты | Если несколько документов имеют одинаковый рейтинг, то один из них может появиться первым. |
| Изменчивость данных | Содержимое индекса меняется по мере того, как вы добавляете, изменяете или удаляете документы. Частота терминов изменяется при обработке обновлений индекса с течением времени, что влияет на показатели поиска соответствующих документов. |
| Несколько реплик | Для служб, использующих несколько реплик, запросы к каждой реплике выдаются параллельно. Статистика индекса, используемая для вычисления оценки показателей поиска, вычисляется отдельно для каждой реплики, а результаты объединяются и упорядочиваются в ответе на запрос. Реплики в основном являются зеркальным отражением друг друга, но статистика может отличаться из-за наличия небольших различий. Например, одна реплика могла удалить документы, участвующие в статистике, которые были объединены из других реплик. Как правило, различия в статистике на каждую реплику более заметны в небольших индексах. В следующем разделе приведены дополнительные сведения об этом условии. |
Влияние сегментирования на результаты запроса
Сегмент — это блок индекса. Поиск ИИ Azure подразделяет индекс на сегменты , чтобы ускорить процесс добавления секций (путем перемещения сегментов в новые единицы поиска). В службе поиска управление сегментами — это сведения о реализации и неконфигурируемые, но зная, что индекс сегментирован, помогает понять случайные аномалии в поведении ранжирования и автозаполнения:
Аномалии с ранжированием: рейтинг поиска сначала рассчитывается на уровне сегментов, а затем объединяется в результирующий набор. В зависимости от особенностей содержимого сегментов совпадения из одного сегмента могут ранжироваться выше, чем из другого. Если вы заметите счетчик интуитивно понятных ранжирований в результатах поиска, скорее всего, это связано с эффектами сегментирования, особенно если индексы малы. Чтобы избежать подобных аномалий, перейдите на глобальный расчет рейтингов по всему индексу, но это приведет к снижению производительности.
Аномалии с автозаполнением: запросы автозаполнения, где совпадения подбираются по первым нескольким символам частично введенного ключевого слова, принимают параметр нечеткого соответствия, который допускает небольшие отклонения в написании. Для автозаполнения нечеткие совпадения возможны только по терминам в пределах текущего сегмента. Например, если сегмент содержит "Майкрософт" и частичный термин "micro", поисковая система будет соответствовать в этом сегменте, но не в других сегментах, которые содержат оставшиеся части индекса.
На схеме ниже показана связь между репликами, секциями, сегментами и единицами поиска. В этом примере один индекс состоит из четырех единиц поиска с двумя репликами и двумя секциями в службе. В каждой из четырех единиц поиска хранится только половина сегментов индекса. В единицах поиска в левом столбце хранится первая половина сегментов, составляющая первую секцию, в то время как в правом столбце отражена вторая половина сегментов, т. е. вторая секция. Поскольку реплики две, у каждого сегмента индекса по две копии. В единицах поиска в верхней строке хранится одна копия, составляющая первую реплику, а в нижней строке — вторая копия, представляющая вторую реплику.
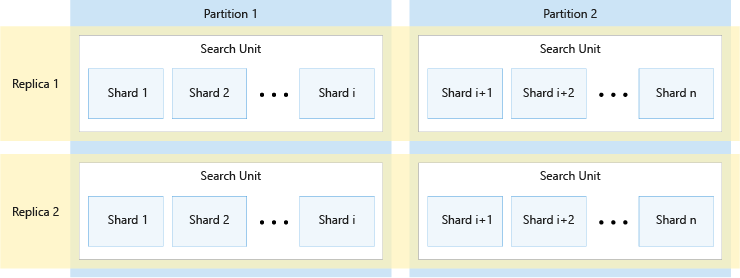
На схеме выше показан лишь один пример конфигурации. Поддерживаются различные сочетания секций и реплик — всего до 36 единиц поиска.
Примечание.
Количество реплик и секций должно быть делителем 12 (а именно 1, 2, 3, 4, 6, 12). Поиск по искусственному интеллекту Azure предварительно делит каждый индекс на 12 сегментов, чтобы его можно было распределять по равным частям по всем секциям. Например, если в вашей службе есть три секции и вы создаете индекс, то каждая секция будет содержать по четыре сегмента индекса. Как поиск azure AI сегментирует индекс является подробным описанием реализации, при условии изменения в будущих выпусках. Несмотря на то, что сегодня это число 12, вам не следует полагаться на то, что в будущем оно не изменится.
Статистика оценки и прикрепленные сеансы
Для масштабируемости поиск ИИ Azure распределяет каждый индекс по горизонтали через процесс сегментирования, что означает, что части индекса физически отделены.
По умолчанию оценка документа вычисляется на основе статистических свойств данных в сегменте. Этот подход, как правило, не является проблемой для большого объема данных. Он обеспечивает лучшую производительность, чем вычисление оценки на основе информации по всем сегментам. Тем не менее, использование этой оптимизации производительности может привести к тому, что два очень похожих (или даже идентичных) документа будут иметь разные оценки релевантности, если они окажутся в разных сегментах.
Если вы предпочитаете вычислить оценку на основе статистических свойств для всех сегментов, это можно сделать, добавив scoringStatistics=global в качестве параметра запроса (или добавьте "scoringStatistics": "global" в качестве основного параметра запроса).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
Использование scoringStatistics гарантирует, что все сегменты в одной реплике предоставляют одинаковые результаты. Тем не более чем разные реплики могут отличаться друг от друга, так как они всегда обновляются с последними изменениями в индексе. В некоторых сценариях может потребоваться, чтобы пользователи могли получать более согласованные результаты во время сеанса запроса. В таких случаях вы можете предоставить sessionId как часть запросов.
sessionId является уникальной строкой, которую вы создаете для ссылки на уникальный сеанс пользователя.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
До тех пор, пока используется то же sessionId самое, рекомендуется предпринять попытку нацелиться на ту же реплику, увеличивая согласованность результатов, которые будут видеть ваши пользователи.
Примечание.
Повторное использование одних и тех же значений sessionId может повлиять на балансировку нагрузки запросов по репликам, а также негативно повлиять на производительность службы поиска. Значение, используемое в качестве sessionId, не может начинаться с символа "_".
Настройка релевантности
В службе "Поиск ИИ Azure" для поиска ключевых слов и текстовой части гибридного запроса можно настроить параметры алгоритма BM25, а также настроить релевантность поиска и повысить оценку поиска с помощью следующих механизмов.
| Подход | Внедрение | Description |
|---|---|---|
| Конфигурация алгоритма BM25 | Поиск индекса | Настройте, как длина документа и частота терминов влияют на оценку релевантности. |
| Профили повышения | Поиск индекса | Укажите критерии повышения оценки поиска соответствия на основе характеристик контента. Например, вы можете повысить совпадения на основе их потенциала дохода, повысить новые элементы или, возможно, увеличить элементы, которые были в инвентаризации слишком долго. Профиль повышения — часть определения индекса, состоящая из взвешенных полей, функций и параметров. Можно обновить существующий индекс с изменениями профиля оценки без перестроения индекса. |
| Семантическое ранжирование | Запрос запроса | Применяет понимание машинного чтения к результатам поиска, повышая семантику релевантные результаты в верхней части. |
| Параметр featuresMode | Запрос запроса | Этот параметр в основном используется для распаковки оценки BM25, но его можно использовать в коде, который предоставляет пользовательское решение оценки. |
Параметр featuresMode (предварительная версия)
Запросы документов поиска поддерживают параметр featuresMode, который содержит дополнительные сведения о оценке релевантности BM25 на уровне поля.
@searchScore В то время как вычисляется для документа все (как релевантно это документ в контексте этого запроса), функцияMode показывает сведения о отдельных полях, как выражено в @search.features структуре. В этой структуре содержатся все поля, используемые в запросе (определенные поля используются с помощью конструкции searchFields из запроса или все поля с атрибутом доступные для поиска в индексе).
Для каждого поля @search.features укажите следующие значения:
- Число уникальных токенов, найденных в поле
- Оценка подобия или мера того, насколько содержимое поля сходно с термином из запроса
- Частота термина или количество раз, когда термин из запроса был найден в поле
Для запроса, предназначенного для полей "description" (описание) и "title" (заголовок), ответ, который содержит @search.features, может выглядеть следующим образом:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Вы можете использовать эти величины в пользовательских решениях оценки или применить эту информацию для отладки проблем, связанных с релевантностью поиска.
Параметр featuresMode не задокументирован в ИНТЕРФЕЙСАх REST API, но его можно использовать в вызове REST API предварительной версии для поиска документов для поиска текста (ключевого слова), ранжированного по BM25.
Число ранжированных результатов в ответе полнотекстового запроса
По умолчанию, если вы не используете разбиение на страницы, поисковая система возвращает 50 самых высоких совпадений для полнотекстового поиска. Параметр можно использовать top для возврата меньшего или большего числа элементов (до 1000 в одном ответе). Результаты страниц можно использовать skip и next использовать. Разбиение на страницы определяет количество результатов на каждой логической странице и поддерживает навигацию по содержимому. Дополнительные сведения см. в результатах поиска фигур.
Если полнотекстовый запрос является частью гибридного запроса, можно maxTextRecallSize задать для увеличения или уменьшения количества результатов из текстовой стороны запроса.
Полнотекстовый поиск имеет максимальное ограничение в 1000 совпадений (см . ограничения ответа API). После того как найдены 1000 совпадений, поисковая система больше не ищет.