Настройка запросов с помощью вариантов
Создание хорошего запроса является сложной задачей, которая требует много творчества, ясности и релевантности. Хороший запрос может вызвать требуемые выходные данные из предварительно обученной языковой модели, в то время как неправильный запрос может привести к неточным, неуместным или нечувствительных выходных данных. Поэтому необходимо настроить запросы на оптимизацию производительности и надежности для различных задач и доменов.
Таким образом, мы введем концепцию вариантов , которые могут помочь вам проверить поведение модели в различных условиях, таких как различные формулировки, форматирование, контекст, температура или топ-k, сравнить и найти лучший запрос и конфигурацию, которая максимизирует точность, разнообразие или согласованность модели.
В этой статье показано, как использовать варианты для настройки запросов и оценки производительности различных вариантов.
Необходимые компоненты
Прежде чем читать эту статью, лучше пройти:
Как настроить запросы с помощью вариантов?
В этой статье мы будем использовать пример потока веб-классификации в качестве примера.
Откройте пример потока и удалите узел prepare_examples в качестве запуска.
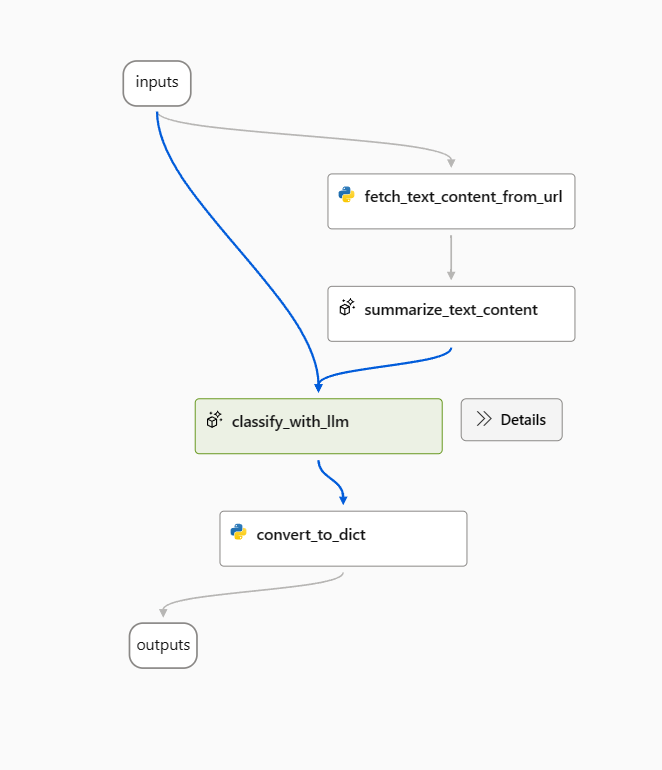
Используйте следующую строку в качестве базового запроса на узле classify_with_llm .

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
Для оптимизации этого потока может быть несколько способов, и ниже приведены два направления.
Для classify_with_llm узла: я узнал из сообщества и документов, что более низкая температура дает более высокую точность, но меньше творчества и сюрприза, поэтому более низкая температура подходит для задач классификации, а также несколько выстрелов запроса могут увеличить производительность LLM. Таким образом, я хотел бы проверить, как работает мой поток, когда температура изменяется с 1 до 0, и когда запрос с несколькими выстрелами примеров.
Для узла summarize_text_content : я также хочу проверить поведение потока при изменении сводки с 100 слов на 300, чтобы узнать, может ли больше текстового содержимого помочь повысить производительность.
Создание вариантов
- Нажмите кнопку "Показать варианты" в правом верхнем углу узла LLM. Существующий узел LLM variant_0 и является вариантом по умолчанию.
- Нажмите кнопку "Клонировать" на variant_0, чтобы создать variant_1, затем можно настроить параметры для разных значений или обновить запрос на variant_1.
- Повторите шаг, чтобы создать дополнительные варианты.
- Выберите " Скрыть варианты", чтобы остановить добавление дополнительных вариантов. Все варианты сложены. Вариант по умолчанию отображается для узла.
Для узла classify_with_llm на основе variant_0:
- Создайте variant_1, где температура изменяется с 1 до 0.
- Создайте variant_2, где температура составляет 0, и можно использовать следующий запрос, включая примеры с несколькими выстрелами.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
Для узла summarize_text_content на основе variant_0 можно создать variant_1, где 100 words он изменяется на 300 слова в запросе.
Теперь поток выглядит следующим образом: 2 варианта для summarize_text_content узла и 3 для classify_with_llm узла.

Выполнение всех вариантов с одной строкой данных и проверка выходных данных
Чтобы убедиться, что все варианты могут успешно выполняться и работать должным образом, можно запустить поток с одной строкой данных для тестирования.
Примечание.
Каждый раз, когда можно выбрать только один узел LLM с вариантами для выполнения, а другие узлы LLM будут использовать вариант по умолчанию.
В этом примере мы настраиваем варианты для summarize_text_content узла и classify_with_llm узла, поэтому необходимо выполнить два раза, чтобы протестировать все варианты.
- Нажмите кнопку "Запустить" в правом верхнем углу.
- Выберите узел LLM с вариантами. Другие узлы LLM будут использовать вариант по умолчанию.
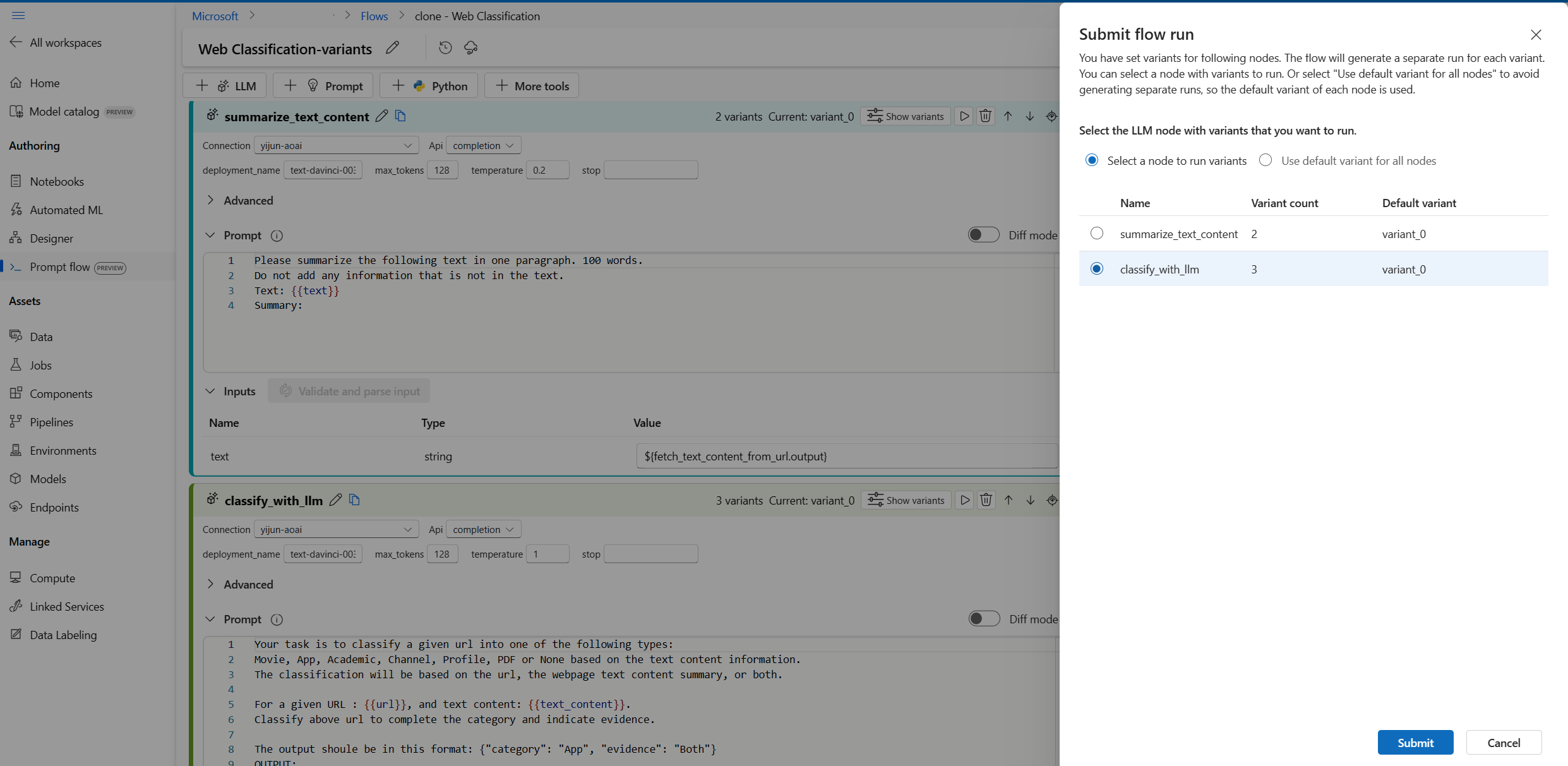
- Отправьте запуск потока.
- После завершения выполнения потока можно проверить соответствующий результат для каждого варианта.
- Отправьте другой поток с другим узлом LLM с вариантами и проверьте выходные данные.
- Можно изменить другие входные данные (например, использовать URL-адрес страницы Википедии) и повторить описанные выше действия, чтобы протестировать варианты для различных данных.

Оценка вариантов
При выполнении вариантов с несколькими отдельными фрагментами данных и проверки результатов с невооруженным глазом он не может отражать сложность и разнообразие реальных данных, тем временем выходные данные не измеримы, поэтому трудно сравнить эффективность различных вариантов, а затем выбрать лучшее.
Пакетное выполнение можно отправить, что позволяет протестировать варианты с большим объемом данных и оценить их с помощью метрик, чтобы помочь вам найти оптимальный вариант.
Сначала необходимо подготовить набор данных, который является достаточно репрезентативным из реальной проблемы, которую вы хотите решить с помощью потока запроса. В этом примере это список URL-адресов и их правды классификации. Мы будем использовать точность для оценки производительности вариантов.
Выберите " Оценить " в правом верхнем углу страницы.
Происходит мастер выполнения пакетной службы и оценки . Первым шагом является выбор узла для выполнения всех его вариантов.
Чтобы проверить, насколько хорошо работают различные варианты для каждого узла в потоке, необходимо запустить пакетный запуск для каждого узла с вариантами по одному. Это помогает избежать влияния вариантов других узлов и сосредоточиться на результатах вариантов этого узла. Это следует правилу управляемого эксперимента, что означает, что вы изменяете только одну вещь одновременно и сохраняете все остальное.
Например, можно выбрать узел classify_with_llm для выполнения всех вариантов, summarize_text_content узел будет использовать его по умолчанию для этого пакетного запуска.
Далее в параметрах пакетного запуска можно задать имя пакетного запуска, выбрать среду выполнения, отправить подготовленные данные.
Затем в параметрах оценки выберите метод оценки.
Так как этот поток предназначен для классификации, можно выбрать метод оценки точности классификации для оценки точности.
Точность вычисляется путем сравнения прогнозируемых меток, назначенных потоком (прогнозированием) с фактическими метками данных (земная истина) и подсчетом количества их совпадений.
В разделе сопоставления входных данных оценки необходимо указать истину земли из столбца категорий входного набора данных, а прогнозирование происходит из одного из выходных данных потока: категория.
После просмотра всех параметров можно отправить пакетный запуск.
После отправки запуска выберите ссылку, перейдите на страницу сведений о выполнении.
Примечание.
Выполнение может занять несколько минут.
Визуализация выходных данных
- После завершения выполнения пакетного выполнения и оценки на странице сведений о выполнении несколько раз выберите пакет для каждого варианта, а затем выберите визуализировать выходные данные. Вы увидите метрики из 3 вариантов для узла classify_with_llm и прогнозируемых выходных данных LLM для каждой записи данных.
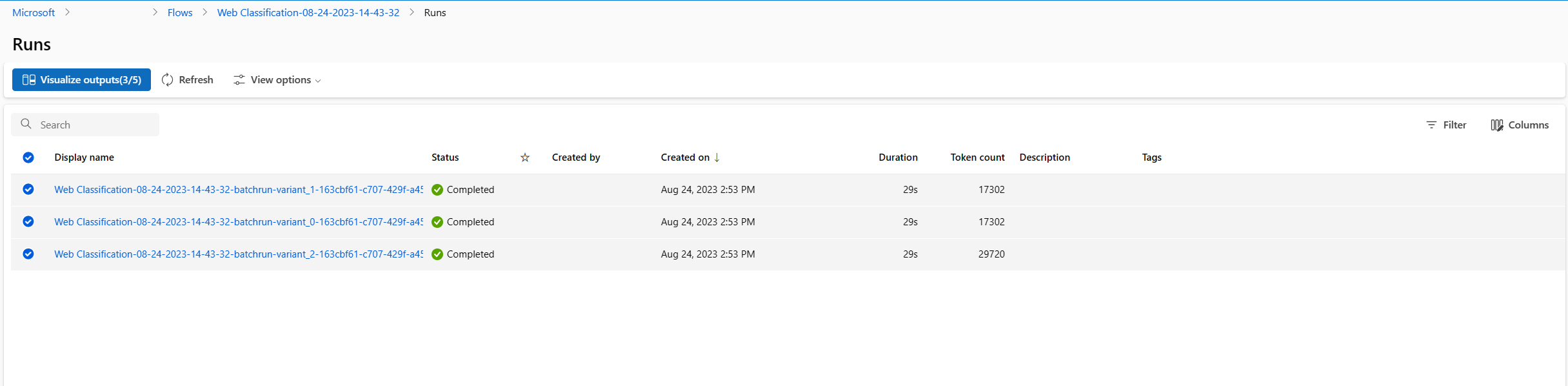
- После определения лучшего варианта можно вернуться на страницу разработки потока и задать этот вариант как вариант по умолчанию узла.
- Вы можете повторить описанные выше шаги, чтобы оценить варианты summarize_text_content узла.
Теперь вы завершили процесс настройки запросов с помощью вариантов. Этот метод можно применить к собственному потоку запроса, чтобы найти лучший вариант для узла LLM.