Интеграция LangChain в потоки запросов
Библиотека Python LangChain — это платформа для разработки приложений на основе больших языковых моделей (LLMs), агентов и средств зависимостей. В этой статье показано, как загрузить разработку LangChain с помощью потока запроса Машинное обучение Azure.

Интеграция LangChain с потоком запросов — это мощная комбинация, которая помогает создавать и тестировать пользовательские языковые модели с легкостью. Модули LangChain можно использовать для построения потока, а затем использовать процесс потока запроса для масштабирования экспериментов для массового тестирования, оценки и последующего развертывания. Например, можно проводить крупномасштабные эксперименты на основе больших наборов данных.
Если у вас уже есть локальный поток запроса на основе кода LangChain, его можно легко преобразовать в поток запросов Машинное обучение Azure для дальнейшего эксперимента. Или если вы предпочитаете напрямую использовать классы и функции пакета SDK LangChain, вы можете легко создавать потоки Машинное обучение Azure с узлами Python, которые используют пользовательский код LangChain.
Необходимые компоненты
- Локальный поток LangChain, который правильно протестирован и готов к развертыванию.
- Вычислительный сеанс, который может запустить поток запроса Машинное обучение путем добавления пакетов, перечисленных в файле requirements.txt, включая
langchain. Дополнительные сведения см. в разделе "Управление сеансом вычислений потока запросов".
Преобразование кода LangChain в поток запроса
Используйте следующий процесс, чтобы преобразовать локальный код LangChain в выполняемый поток запроса Машинное обучение Azure.
Преобразование учетных данных в подключение потока запроса
Код LangChain может определять переменные среды для хранения учетных данных, таких как ключ API AzureOpenAI, необходимый для вызова моделей AzureOpenAI. Например, в следующем коде показаны переменные среды, заданные для типа API OpenAI, ключа, базы и версии.
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_VERSION"] = "2023-05-15"
os.environ["OPENAI_API_BASE"] = "https://contosobamiopenai.openai.azure.com/"
os.environ["OPENAI_API_KEY"] = "abc123abc123abc123abc123abc123ab"
При запуске потока запроса Машинное обучение Azure в облаке лучше не предоставлять учетные данные в виде переменных среды. Чтобы безопасно хранить учетные данные и управлять ими отдельно от кода, следует преобразовать переменные среды в подключение потока запроса.
Чтобы создать подключение, безопасное хранение пользовательских учетных данных, таких как ключ API LLM или другие необходимые ключи, выполните следующие инструкции:
На странице потока запроса в рабочей области Машинное обучение Azure выберите вкладку "Подключения" и нажмите кнопку "Создать".
Выберите тип подключения из раскрывающегося списка. В этом примере выберите Custom.
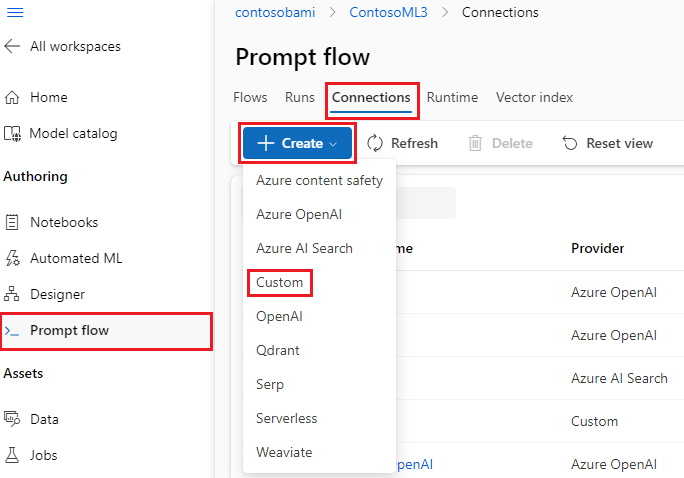
В правой области определите имя подключения, а затем добавьте пары "Ключ-значение" для хранения учетных данных и ключей, выбрав "Добавить пары "ключ-значение".
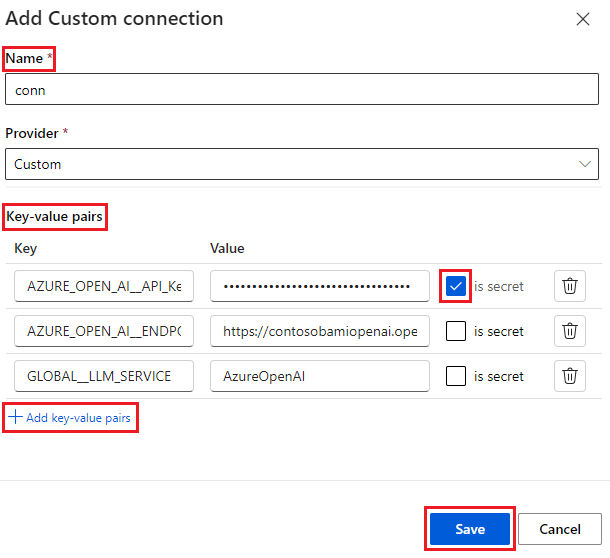
Чтобы сохранить зашифрованное значение ключа, установите флажок секрета рядом с одной или несколькими парами "ключ-значение". Для успешного создания настраиваемого подключения необходимо задать по крайней мере одно значение в качестве секрета.
Выберите Сохранить.
Настраиваемое подключение может заменить ключи и учетные данные или соответствующие переменные среды, явно определенные в коде LangChain. Сведения об использовании настраиваемого подключения в потоке см. в разделе "Настройка подключения".
Преобразование кода LangChain в поток запускаемого потока
Чтобы создать поток, выберите "Создать" на странице потока запроса в Студия машинного обучения Azure и выберите тип потока. На странице разработки потока запустите сеанс вычислений перед созданием потока. Выберите типы инструментов в верхней части страницы, чтобы вставить соответствующие узлы в поток. Подробные инструкции по разработке потоков см. в разделе "Разработка потока запроса".
Весь код LangChain может выполняться непосредственно в узлах Python в потоке, если вычислительный langchain сеанс содержит зависимость пакета.
Существует два способа преобразования кода LangChain в поток запроса Машинное обучение Azure. Тип потока для реализации зависит от вашего варианта использования.
Для улучшения управления экспериментами можно преобразовать код для использования Машинное обучение Azure Python и инструментов запроса в потоке. Вы извлекаете шаблон запроса из кода в узел запроса и помещаете оставшийся код в один или несколько узлов Или инструментов Python. Этот параметр позволяет легко настраивать запросы, выполняя варианты, и позволяет выбирать оптимальные запросы на основе результатов оценки.
В следующем примере показан поток, использующий узлы запроса и узлы Python:
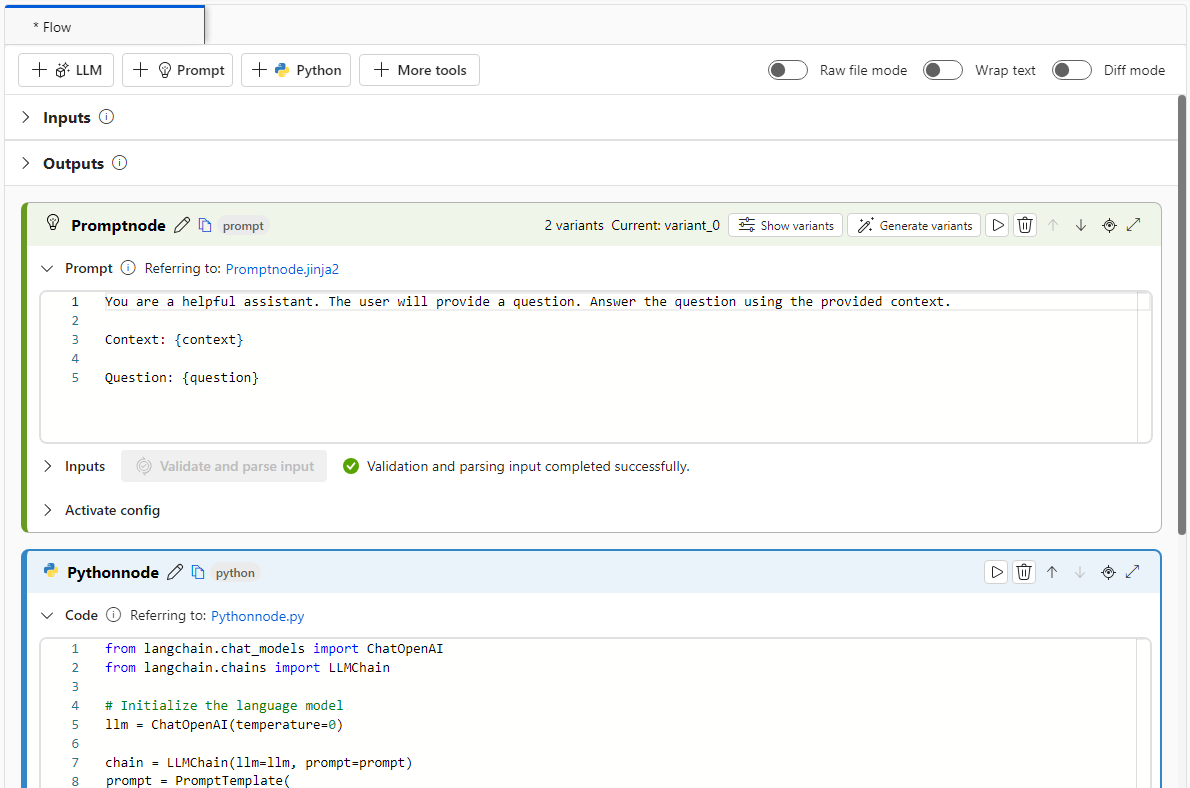
Для более простого процесса преобразования можно вызвать библиотеку LLM LangChain непосредственно из узлов Python. Весь код выполняется на узлах Python, включая определения запросов. Этот параметр поддерживает более быстрое пакетное тестирование на основе больших наборов данных или других конфигураций.
В следующем примере показан поток, использующий только узлы Python:
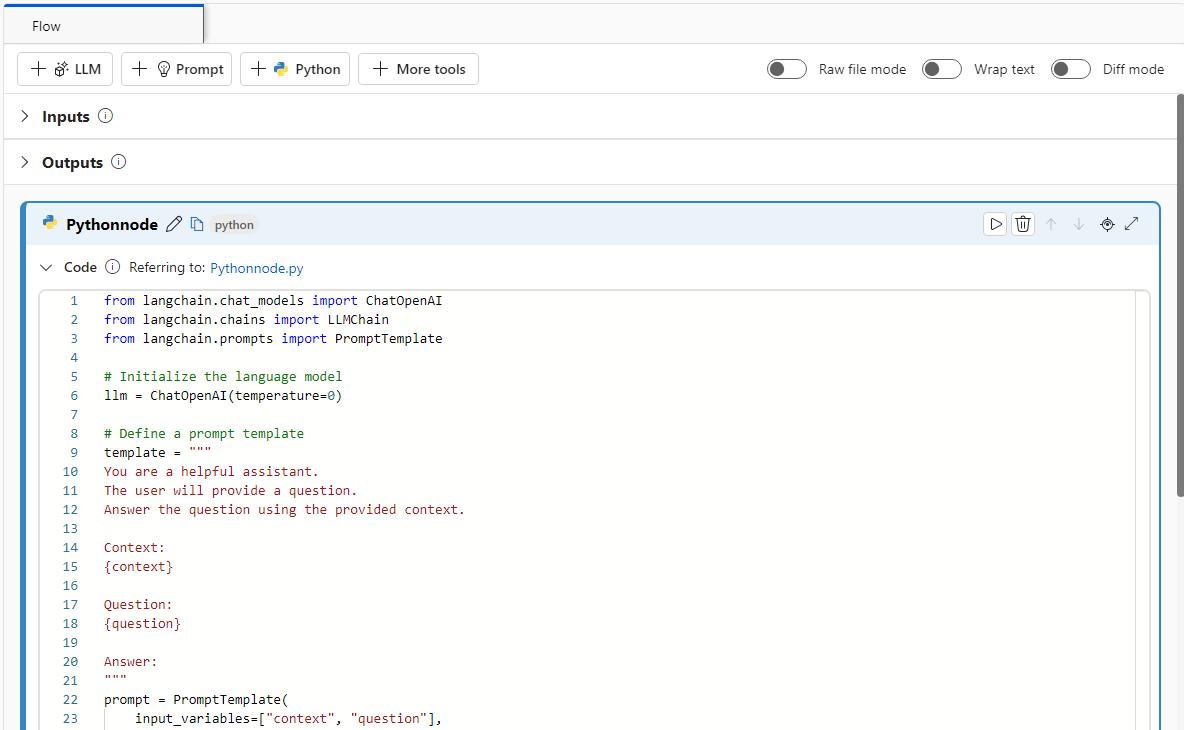


Настройка подключения
После структуры потока и перемещения кода на определенные узлы инструментов необходимо заменить исходные переменные среды соответствующими ключами из подключения. Чтобы использовать созданное пользовательское подключение, выполните следующие действия.
В коде Python импортируйте пользовательскую библиотеку подключений, введя
from promptflow.connections import CustomConnection.Примечание.
Чтобы импортировать подключение Azure OpenAI, используйте
from promptflow.connections import AzureOpenAIConnection.В функции средства определите входной параметр типа
CustomConnection.
Замените переменные среды, которые первоначально определили ключи или учетные данные соответствующими ключами из подключения.
Анализ входных данных в разделе входных данных пользовательского интерфейса узла и выбор пользовательского подключения из раскрывающегося списка "Значение " в пользовательском интерфейсе.
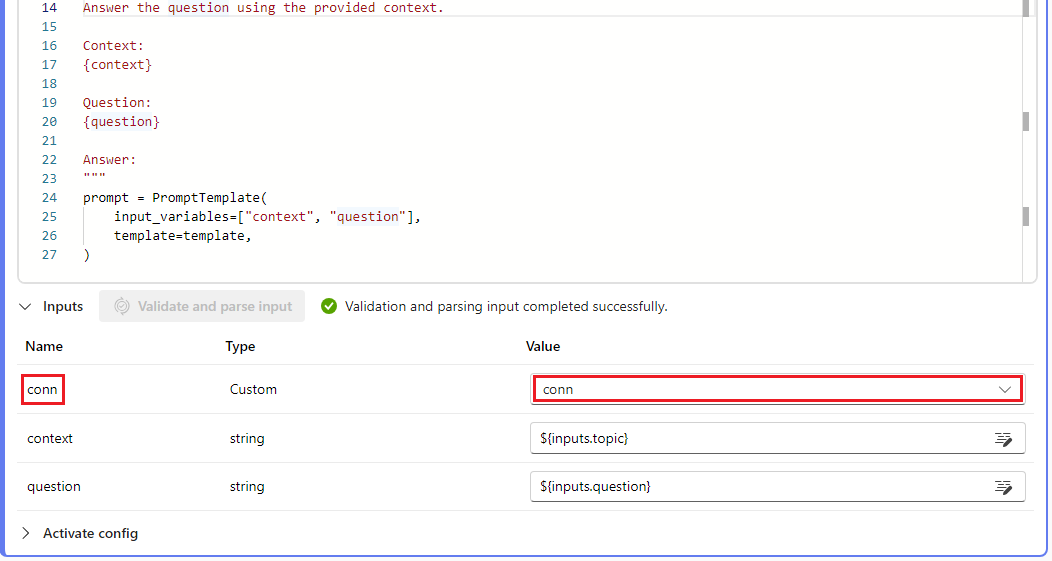
Не забудьте также настроить параметры подключения в любых других узлах, которые требуют их, например узлы LLM.


Настройка входных и выходных данных
Перед запуском потока настройте входные и выходные данные узла, а также общие входные и выходные данные потока. Этот шаг имеет решающее значение для обеспечения правильной передачи всех необходимых данных через поток и получения требуемых результатов. Дополнительные сведения см. в разделе "Входные и выходные данные потока".