Смещение данных (предварительная версия) будет прекращено и заменено монитором моделей
Смещение данных (предварительная версия) будет прекращено в 09.01.2025, и вы можете начать использовать монитор моделей для задач смещения данных. Ознакомьтесь с приведенным ниже содержимым, чтобы понять замену, пробелы функций и действия по изменению вручную.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
Узнайте, как отслеживать смещения данных и задавать предупреждения при больших величинах смещения.
Примечание.
Машинное обучение Azure мониторинг модели (версия 2) предоставляет улучшенные возможности для смещения данных вместе с дополнительными функциями для мониторинга сигналов и метрик. Дополнительные сведения о возможностях мониторинга моделей в Машинное обучение Azure (версия 2) см. в разделе "Мониторинг моделей с помощью Машинное обучение Azure".
С помощью мониторов наборов данных Машинного обучения Azure (предварительная версия) можно выполнить следующее:
- анализ смещения данных для исследования его изменений со временем;
- отслеживание данных модели для определения различий между обучающими и рабочими наборами данных; начните со сбора данных моделей из развернутых моделей;
- мониторинг новых данных для выявления различий между любыми наборами контрольных и целевых данных;
- профилирование признаков в данных для отслеживания изменений статистических свойств со временем;
- настройку оповещений о смещении данных для раннего предупреждения о потенциальных проблемах;
- Если вы обнаружите, что данные слишком сильно смещены, создайте новую версию набора данных.
Набор данных Машинное обучение Azure используется для создания монитора. Набор данных должен включать столбец метки времени (timestamp).
Метрики смещения данных можно просмотреть с помощью пакета SDK для Python или в Студии машинного обучения Azure. Прочие метрики и сведения доступны на ресурсе Azure Application Insights, связанном с рабочим пространством Машинного обучения Azure.
Внимание
В настоящее время обнаружение смещения данных в наборах данных предоставляется в виде общедоступной предварительной версии. Предварительная версия предоставляется без соглашения об уровне обслуживания и не рекомендована для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Необходимые компоненты
Для создания и работы с мониторами набора данных необходимо следующее:
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу. Опробуйте бесплатную или платную версию Машинного обучения Azure уже сегодня.
- Рабочая область Машинного обучения Azure.
- Установленный пакет Azure Machine Learning SDK для Python, который включает пакет azureml-datasets.
- структурированные (табличные) данные с меткой времени, указанной в пути к файлам, в именах файлов или в столбце данных.
Предварительные требования (миграция на монитор моделей)
При переходе на монитор моделей проверьте предварительные требования, как упоминалось в этой статье, необходимые для мониторинга модели Машинное обучение Azure.
Что такое смещение данных?
Точность модели снижается с течением времени, в основном из-за смещения данных. При работе с моделями машинного обучения смещение данных — это изменение входных данных модели, которое приводит к ухудшению показателей работы модели. Мониторинг смещения данных позволяет выявлять такие проблемы с результативностью модели.
Причины смещения данных включают следующие:
- изменение в процессе более высокого уровня, такое как замена датчика, в результате которой единицы измерения меняются с дюймов на сантиметры;
- проблемы с качеством данных, такие как неисправный датчик, который всегда возвращает 0;
- естественное смещение данных, например изменение среднего значения температуры в зависимости от сезона;
- изменение соотношения между признаками, или ковариантный сдвиг.
Машинное обучение Azure упрощает определение смещений путем вычисления единой метрики, которая абстрагирует сложность сравниваемых наборов данных. Эти наборы данных могут содержать сотни признаков и десятки тысяч строк. После обнаружения смещения происходит детализация и определение того, какие признаки вызвали смещение. После этого можно просматривать метрики на уровне признаков для отладки и выявления основной причины смещения.
При таком подходе "сверху вниз" легче отслеживать данные по сравнению с традиционными методами на основе правил. Методы на основе правил, такие как определение допустимого диапазона данных или допустимых уникальных значений, занимают много времени и подвержены ошибкам.
В Машинном обучении Azure мониторы наборов данных используются для обнаружения смещений данных и оповещения о них.
Мониторы набора данных
Мониторы набора данных обеспечивают:
- обнаружение и оповещение о смещении в новых данных в наборе данных;
- анализ исторических данных для смещения;
- профилирование новых данных с течением времени.
Алгоритм смещения данных создает общую точку отчета для изменения данных и указывает, какие признаки отвечают за дальнейшее исследование. Мониторы набора данных создают множество других метрик путем профилирования новых данных в наборе timeseries данных.
Пользовательские оповещения можно настроить с помощью Azure Application Insights во всех метриках, создаваемых монитором. Мониторы наборов данных можно использовать для быстрого поиска проблем с данными и для сокращения времени отладки проблем за счет выявления вероятных причин.
Концептуально существует три основных сценария настройки мониторов набора данных в Машинном обучении Azure.
| Сценарий | Description |
|---|---|
| Мониторинг рабочих данных модели на предмет отклонения от данных обучения | Результаты из этого сценария можно интерпретировать как прокси-мониторинг точности модели, поскольку точность модели снижается при отслеживании смещения данных обучения. |
| Мониторинг набора данных временных рядов на предмет смещения относительно предыдущего периода времени. | Этот сценарий является более общим и может использоваться для мониторинга наборов данных, предшествующих формированию модели или следующих за ним. Целевой набор данных должен содержать столбец отметки времени. Контрольным набором данных может служить любой табличный набор данных с признаками, аналогичными целевому набору данных. |
| Анализ прошлых данных. | Этот сценарий можно использовать для изучения исторических данных и выработки информированных решений о параметрах мониторов набора данных. |
Мониторы наборов данных опираются на следующие службы Azure.
| Служба Azure | Description |
|---|---|
| Набор данных | В смещении используются наборы данных Машинного обучения Azure для получения данных обучения и сравнения данных для обучения модели. Создание профиля данных используется для выработки некоторых метрик, включаемых в отчеты, таких как минимум, максимум, уникальные значения и число уникальных значений. |
| конвейер и вычисления Машинное обучение Azure | Задание вычисления смещения размещается в конвейере Машинное обучение Azure. Это задание активируется по требованию или по расписанию для выполнения в вычислении, настроенном в момент создания монитора смещения. |
| Application Insights. | Смещение выдает в Application Insights метрики, принадлежащие рабочей области машинного обучения. |
| Хранилище BLOB-объектов Azure | Смещение создает метрики в формате JSON в хранилище BLOB-объектов Azure. |
Контрольные и целевые наборы данных
Вы отслеживаете Машинное обучение Azure наборы данных для смещения данных. При создании монитора набора данных вы ссылаетесь на следующие элементы:
- Контрольный набор данных — обычно это обучающий набор данных для модели.
- Целевой набор данных — обычно это входные данные модели, которые сравниваются с базовым набором данных по ходу времени. Эта возможность сравнения означает, что в целевом наборе данных должен быть задан столбец отметки времени.
Монитор сравнивает базовые и целевые наборы данных.
Миграция на монитор моделей
В мониторе моделей можно найти соответствующие понятия, как показано ниже, и дополнительные сведения см. в этой статье, введя данные рабочей среды в Машинное обучение Azure:
- Эталонный набор данных: аналогично базовому набору данных для обнаружения смещения данных, он устанавливается в качестве последнего рабочего набора данных вывода.
- Данные вывода в рабочей среде: аналогично целевому набору данных в обнаружении смещения данных, данные вывода рабочей среды можно собирать автоматически из моделей, развернутых в рабочей среде. Это также может быть вывод данных, которые вы храните.
Создание целевого набора данных
Для целевого набора данных необходимо определить набор признаков timeseries, задавая столбец отметки времени либо из столбца данных, либо из виртуального столбца, образуемого на основе шаблона путей к файлам. Создайте набор данных с меткой времени с помощью пакета SDK для Python или Студии машинного обучения Azure. Необходимо указать столбец, представляющий "отметку времени" (timestamp), чтобы добавить признак timeseries в набор данных. Если данные разделены по структуре папок, содержащей информацию о времени, например "{гггг/ММ/дд}", создайте виртуальный столбец с помощью параметра шаблона пути и задайте для него значение "метка времени раздела", чтобы использовать функции API временных рядов.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
МетодDataset класса with_timestamp_columns() определяет столбец метки времени для набора данных.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Совет
Полный пример использования признака timeseries в наборе данных см. в примере записной книжки или в документации по пакету SDK для наборов данных.

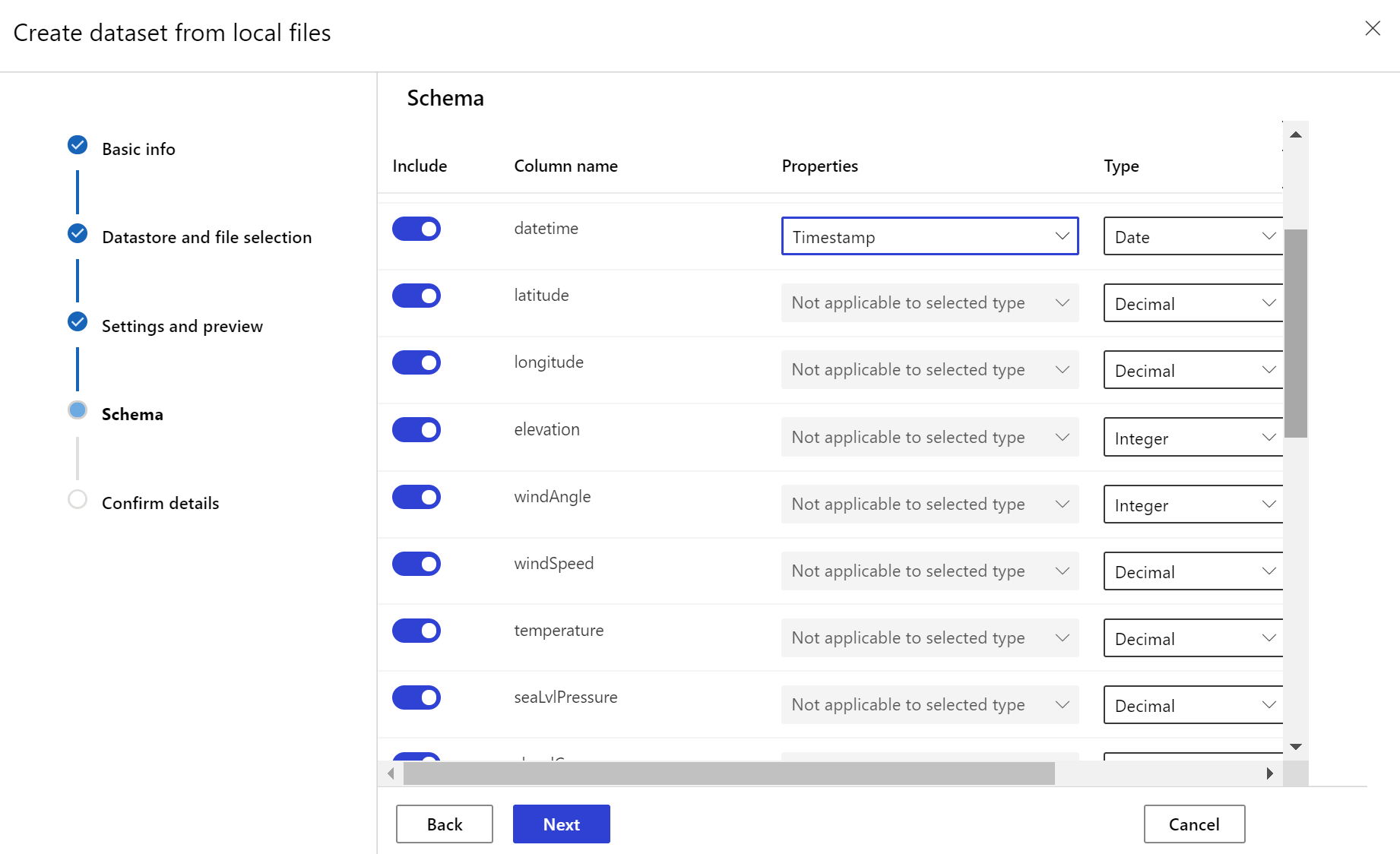
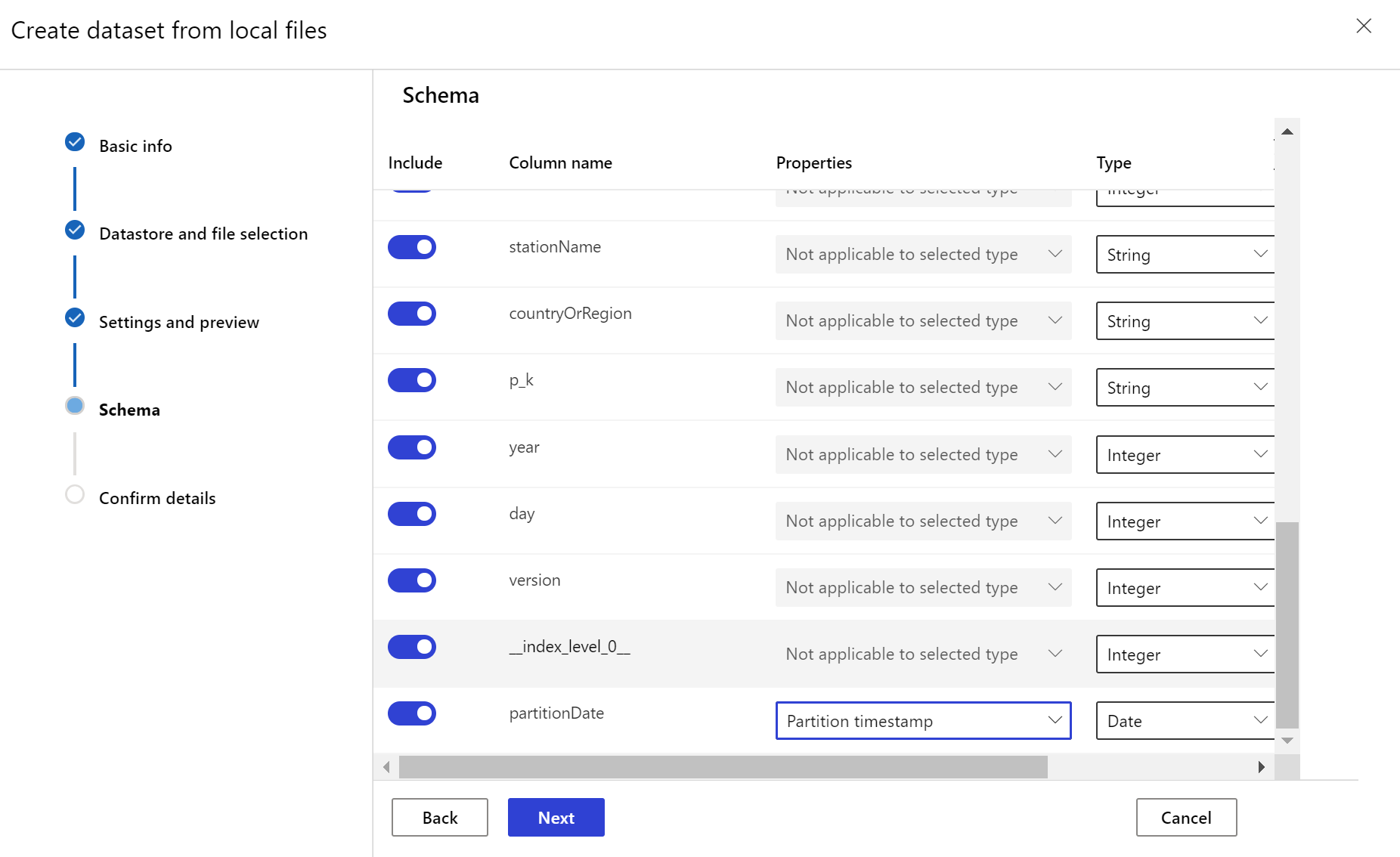
Создание монитора набора данных
Создание монитора набора данных для обнаружения и оповещения о смещении данных в новом наборе данных. Используйте либо пакет SDK для Python, либо Студия машинного обучения Azure.
Как описано далее, монитор набора данных выполняется с заданной частотой (ежедневно, еженедельно, ежемесячно) интервалами. Он анализирует новые данные, доступные в целевом наборе данных с момента последнего запуска. В некоторых случаях такой анализ последних данных может быть недостаточно:
- Новые данные из вышестоящего источника были отложены из-за сломанного конвейера данных, и эти новые данные не были доступны при запуске монитора набора данных.
- Набор данных временных рядов имел только исторические данные, и вы хотите проанализировать шаблоны смещения в наборе данных с течением времени. Например, сравните трафик, поступающий на веб-сайт, как в зимние, так и летние сезоны, чтобы определить сезонные закономерности.
- Вы не знакомы с мониторами набора данных. Вы хотите оценить, как функция работает с существующими данными, прежде чем настроить его для мониторинга будущих дней. В таких сценариях можно отправить выполнение по запросу с определенным диапазоном дат набора данных целевого набора данных для сравнения с базовым набором данных.
Функция обратной заполнения выполняет задание обратной заполнения для указанного диапазона дат начала и окончания. Задание обратной заполнения заполняет ожидаемые отсутствующие точки данных в наборе данных, как способ обеспечения точности и полноты данных.
Примечание.
Машинное обучение Azure мониторинг модели не поддерживает функцию резервной заполнения вручную, если требуется повторно выполнить повторную очистку монитора модели для диапазона времени спецификации, можно создать другой монитор модели для этого определенного диапазона времени.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Полные сведения см. в справочной документации по пакету SDK для Python.
В следующем примере показано, как создать монитор набора данных с помощью пакета SDK для Python:
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Совет
Полный пример настройки набора данных timeseries и средства обнаружения смещения данных см. в нашем примере записной книжки.
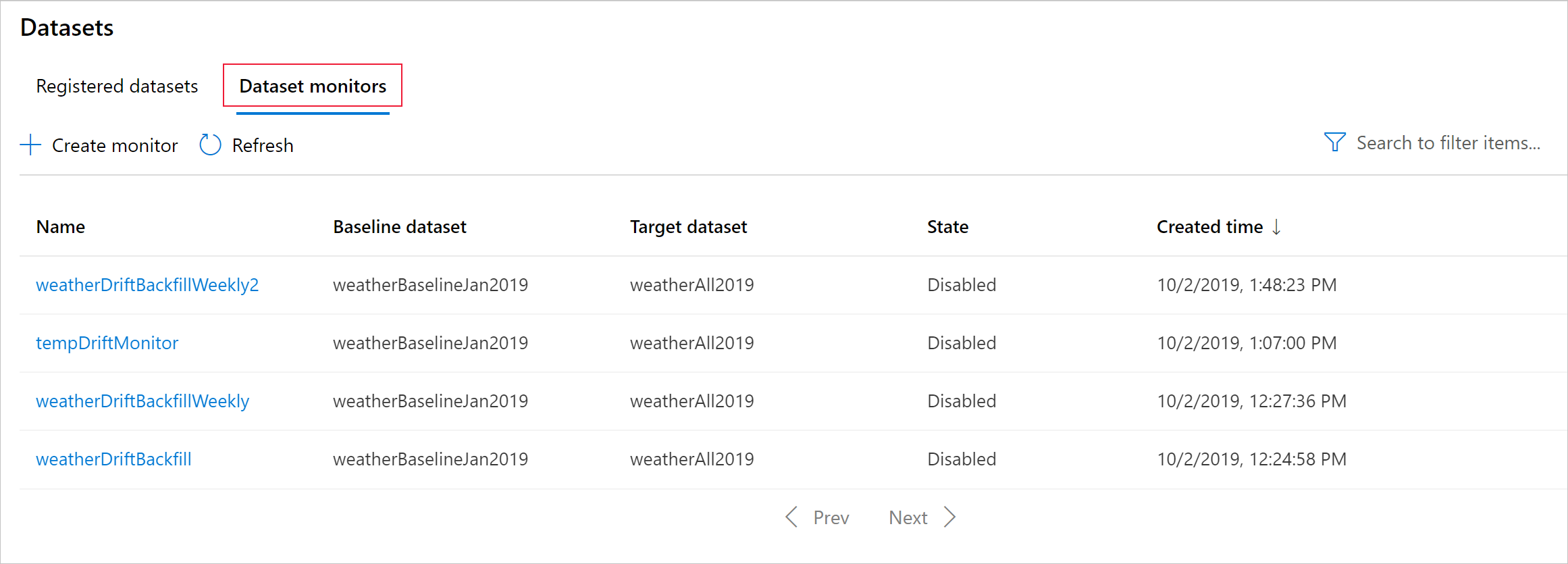
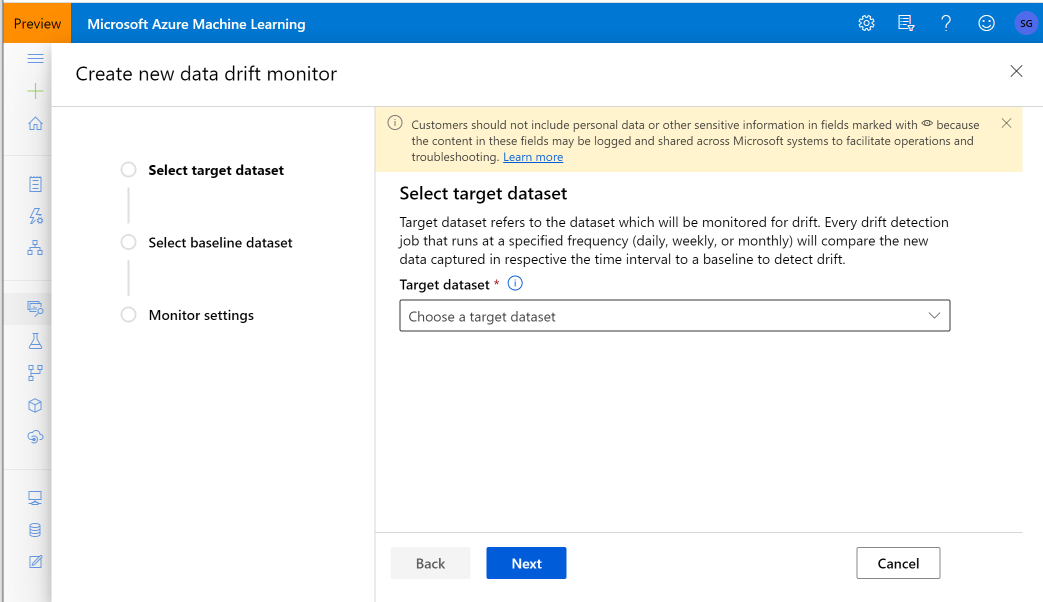
Создание монитора моделей (миграция на монитор моделей)
При переходе на монитор моделей, если вы развернули модель в рабочей среде в Машинное обучение Azure веб-конечной точке и включили сбор данных во время развертывания, Машинное обучение Azure собирает данные вывода в рабочей среде и автоматически сохраняет его в Майкрософт. Хранилище BLOB-объектов Azure. Затем можно использовать мониторинг модели Машинное обучение Azure для непрерывного мониторинга данных вывода в рабочей среде, и вы можете напрямую выбрать модель для создания целевого набора данных (производственные данные вывода в мониторе моделей).
При переходе на монитор моделей, если вы не развернули модель в рабочей среде в Машинное обучение Azure онлайн-конечной точке или не хотите использовать сбор данных, вы также можете настроить мониторинг модели с пользовательскими сигналами и метриками.
В следующих разделах содержатся дополнительные сведения о переходе на монитор моделей.
Создание монитора моделей с помощью автоматически собранных рабочих данных (миграция на монитор моделей)
Если вы развернули модель в рабочей среде в Машинное обучение Azure онлайн-конечной точке и включили сбор данных во время развертывания.
Для настройки встроенного мониторинга модели можно использовать следующий код:
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Создание монитора моделей с помощью компонента предварительной обработки пользовательских данных (миграция на монитор моделей)
При переходе на монитор моделей, если вы не развернули модель в рабочей среде в Машинное обучение Azure онлайн-конечной точке или не хотите использовать сбор данных, вы также можете настроить мониторинг модели с пользовательскими сигналами и метриками.
Если у вас нет развертывания, но у вас есть рабочие данные, можно использовать эти данные для непрерывного мониторинга моделей. Для мониторинга этих моделей необходимо иметь возможность:
- Сбор данных вывода рабочей среды из моделей, развернутых в рабочей среде.
- Зарегистрируйте данные вывода в рабочей среде в качестве Машинное обучение Azure ресурса данных и убедитесь в непрерывном обновлении данных.
- Предоставьте пользовательский компонент предварительной обработки данных и зарегистрируйте его в качестве компонента Машинное обучение Azure.
Необходимо предоставить пользовательский компонент предварительной обработки данных, если данные не собираются с сборщиком данных. Без этого компонента предварительной обработки данных система мониторинга модели Машинное обучение Azure не будет знать, как обрабатывать данные в табличной форме с поддержкой периода времени.
Пользовательский компонент предварительной обработки должен иметь следующие входные и выходные подписи:
| Ввод-вывод | Имя подписи | Тип | Описание | Пример значения |
|---|---|---|---|---|
| input | data_window_start |
литерал, строка | Время запуска окна данных в формате ISO8601. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
литерал, строка | Время окончания окна данных в формате ISO8601. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Собранные данные вывода рабочей среды, зарегистрированные в качестве Машинное обучение Azure ресурса данных. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Табличный набор данных, соответствующий подмножество схемы эталонных данных. |
Пример пользовательского компонента предварительной обработки данных см . в custom_preprocessing репозитория GitHub в azuremml-examples.
Общие сведения о результатах смещения данных
В этом разделе показаны результаты мониторинга набора данных, приведенные на странице Наборы данных / Мониторы набора данных в Студии Azure. Вы можете обновить параметры и проанализировать существующие данные за определенный период времени на этой странице.
Начните с получения подробных сведений о величине смещения данных и о том, какие признаки следует изучить дополнительно.
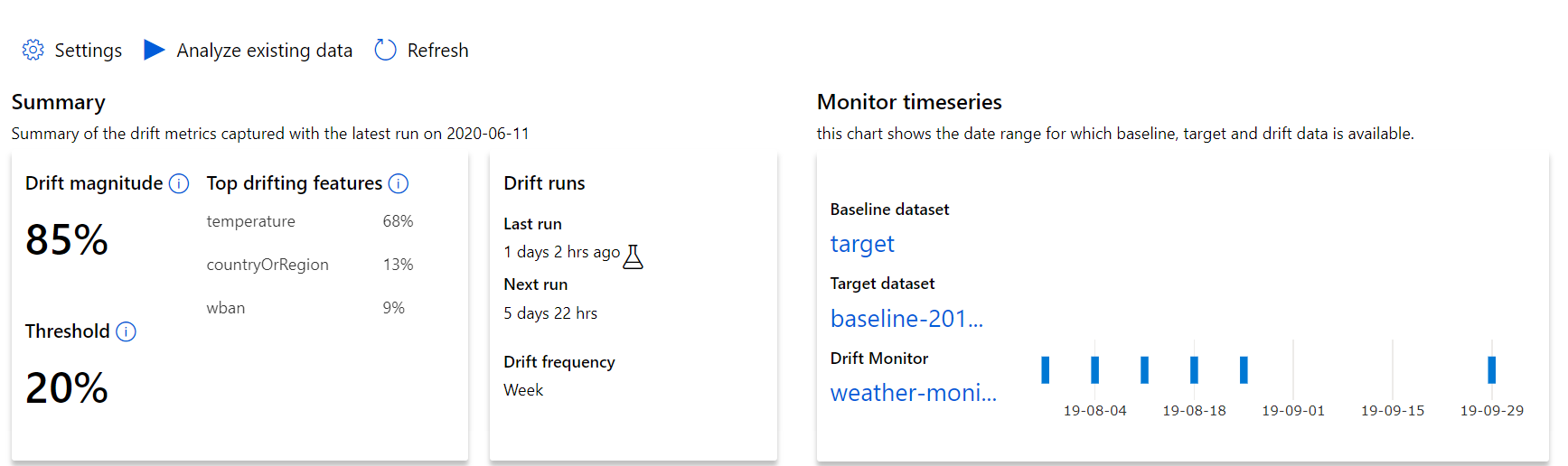
| Метрическая | Description |
|---|---|
| Величина смещения данных | Процентная доля смещения между контрольным и целевым наборами данных с течением времени. Этот процент от 0 до 100, 0 указывает идентичные наборы данных и 100 указывает, что модель смещения данных Машинное обучение Azure может полностью определить два набора данных отдельно. Предполагается наличие шума в выражении измеренного точного процентного значения, который зависит от того, какие методы машинного обучения используются для выработки значения этой величины. |
| Наиболее смещенные признаки | Отображает признаки из набора данных, которые подверглись наибольшему смещению, и поэтому вносят наибольший вклад в метрику величины смещения. Из-за ковариации основное распределение функции не обязательно должно измениться, чтобы иметь относительно высокую важность признаков. |
| За пороговое значение | Величина смещения данных за пределами заданного порогового значения активирует оповещения. Настройте пороговое значение в параметрах монитора. |
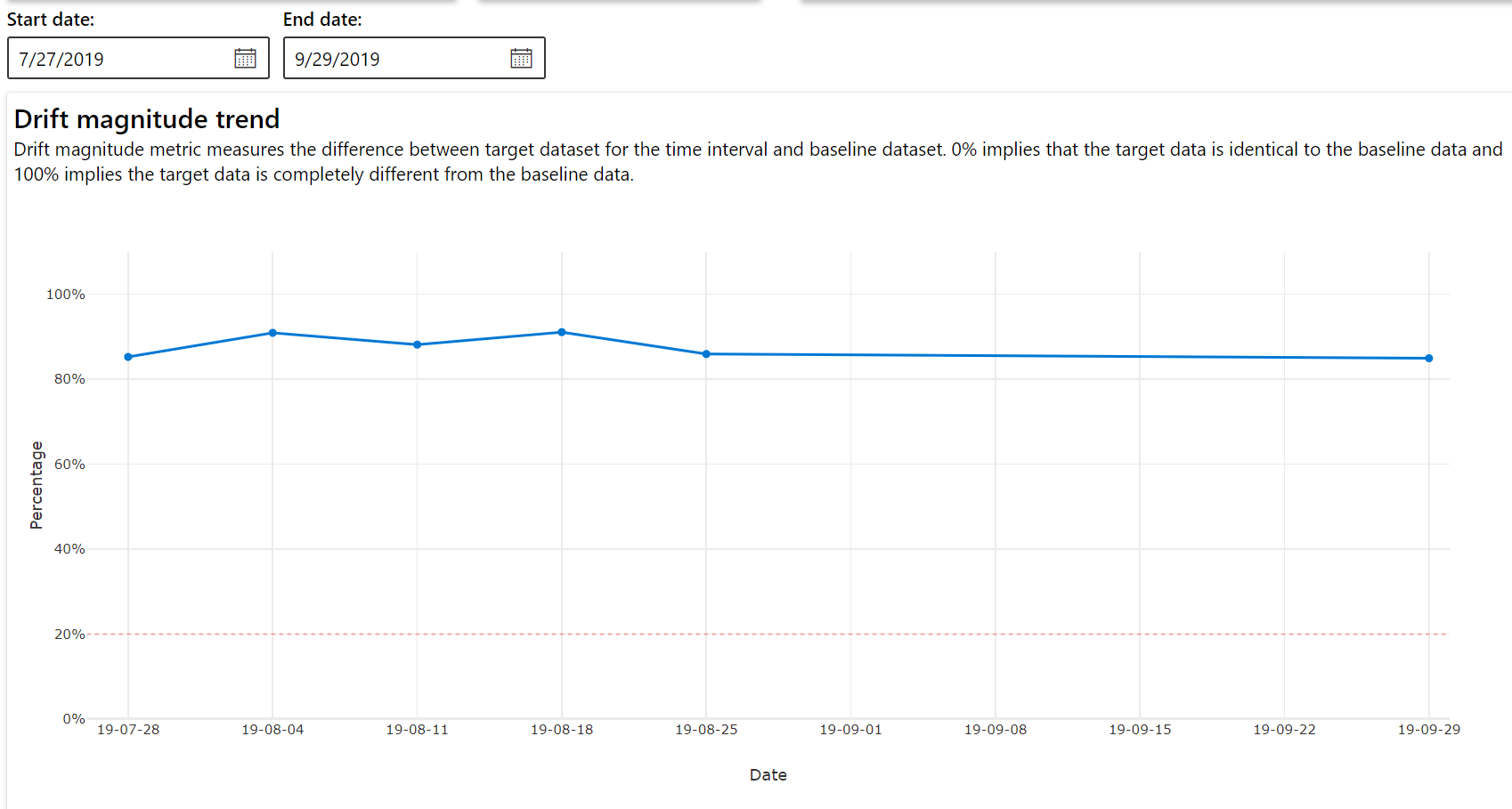
Тренд величины смещения
Позволяет узнать, насколько набор данных отличается от целевого набора данных за указанный период времени. Чем он ближе к 100%, тем более отличаются два набора данных.
Величина смещения по признакам
В этом разделе содержатся аналитические сведения об изменении распределения выбранной функции и других статистических данных с течением времени.
Целевой набор данных также профилируется по времени. Статистическое расстояние между контрольным распределением каждого признака сравнивается с целевым набором данных, с учетом времени. Концептуально это напоминает величину смещения данных. Однако это статистическое расстояние относится к отдельному признаку, а не ко всем признакам. Кроме того, доступны значения минимума, максимума и среднего.
В Студия машинного обучения Azure выберите панель в графе, чтобы просмотреть сведения о уровне компонентов для этой даты. По умолчанию отображается распределение базового набора данных и распределение того же признака в самом последнем задании.
Эти метрики также можно получить в пакете SDK для Python с помощью вызова метода get_metrics() объекта DataDriftDetector.
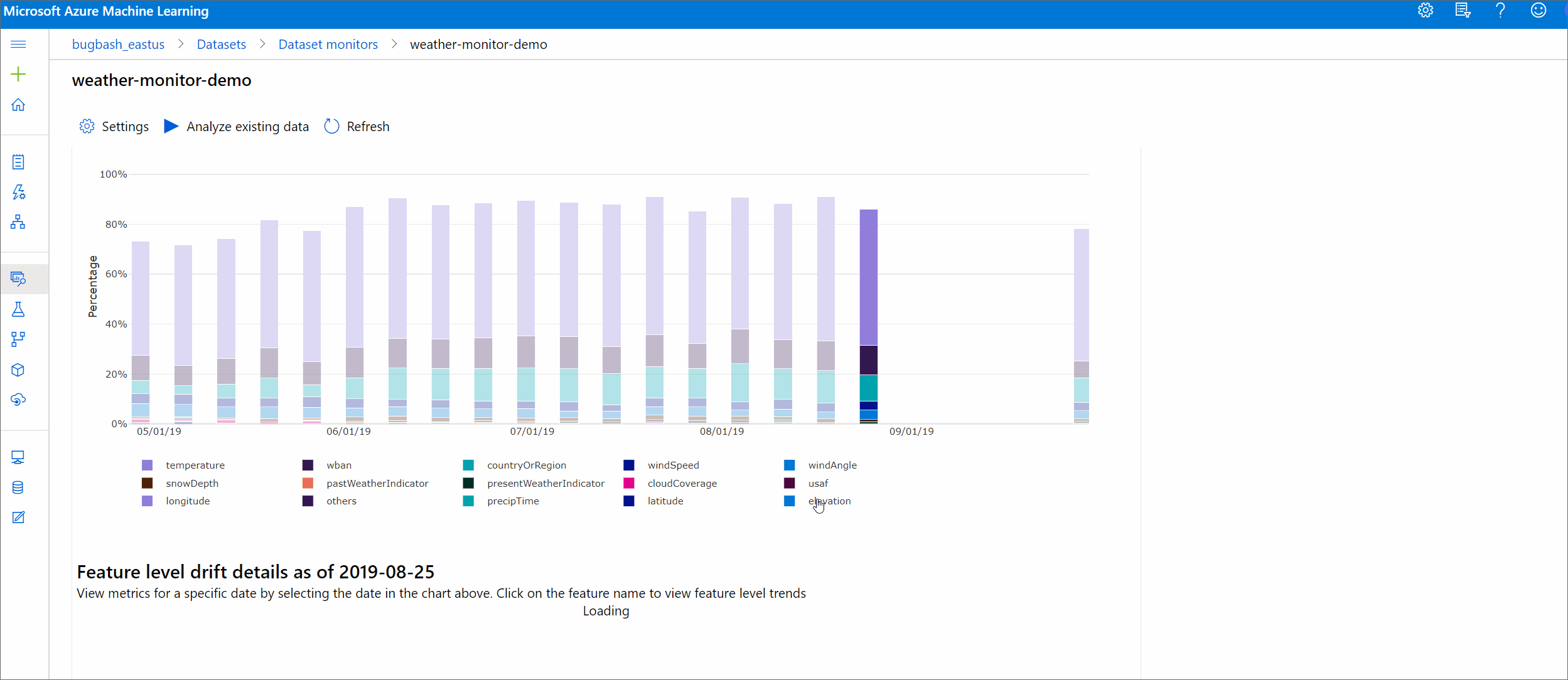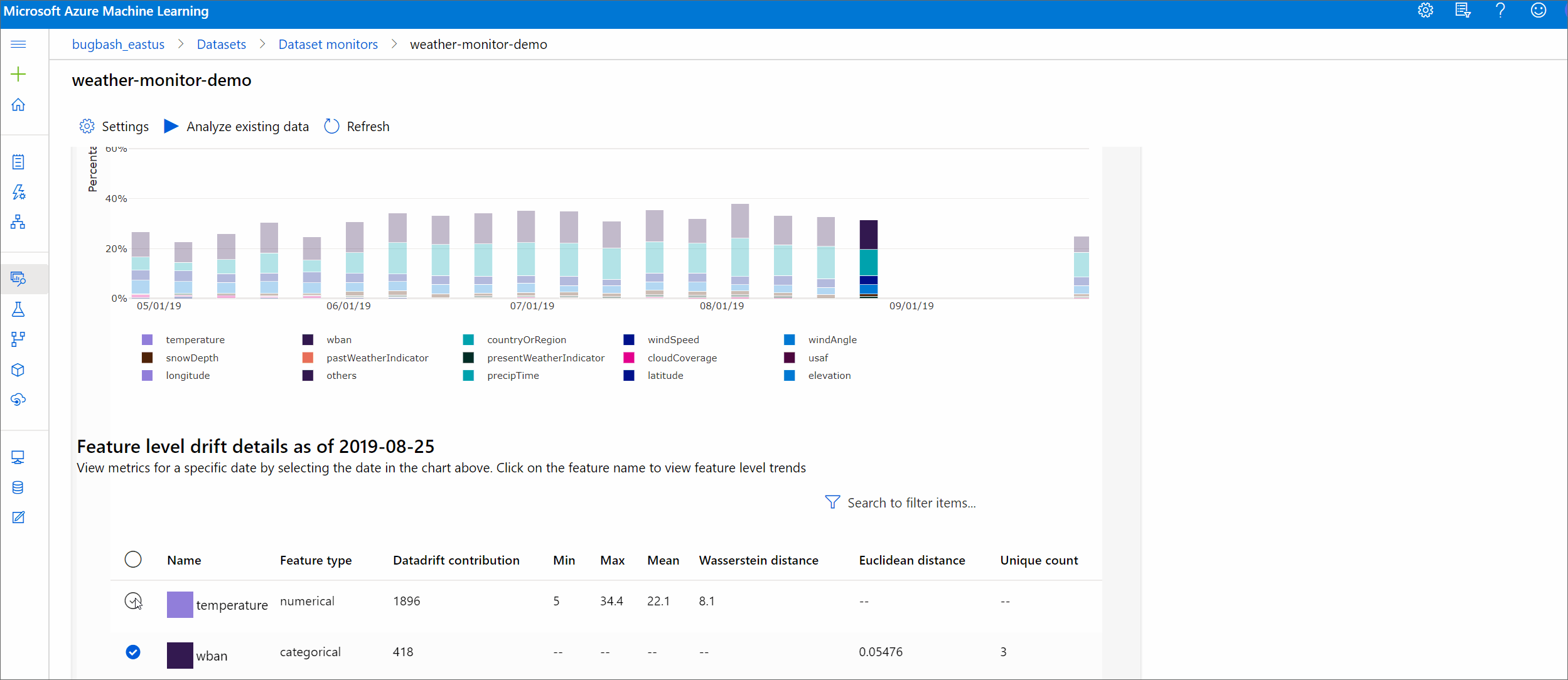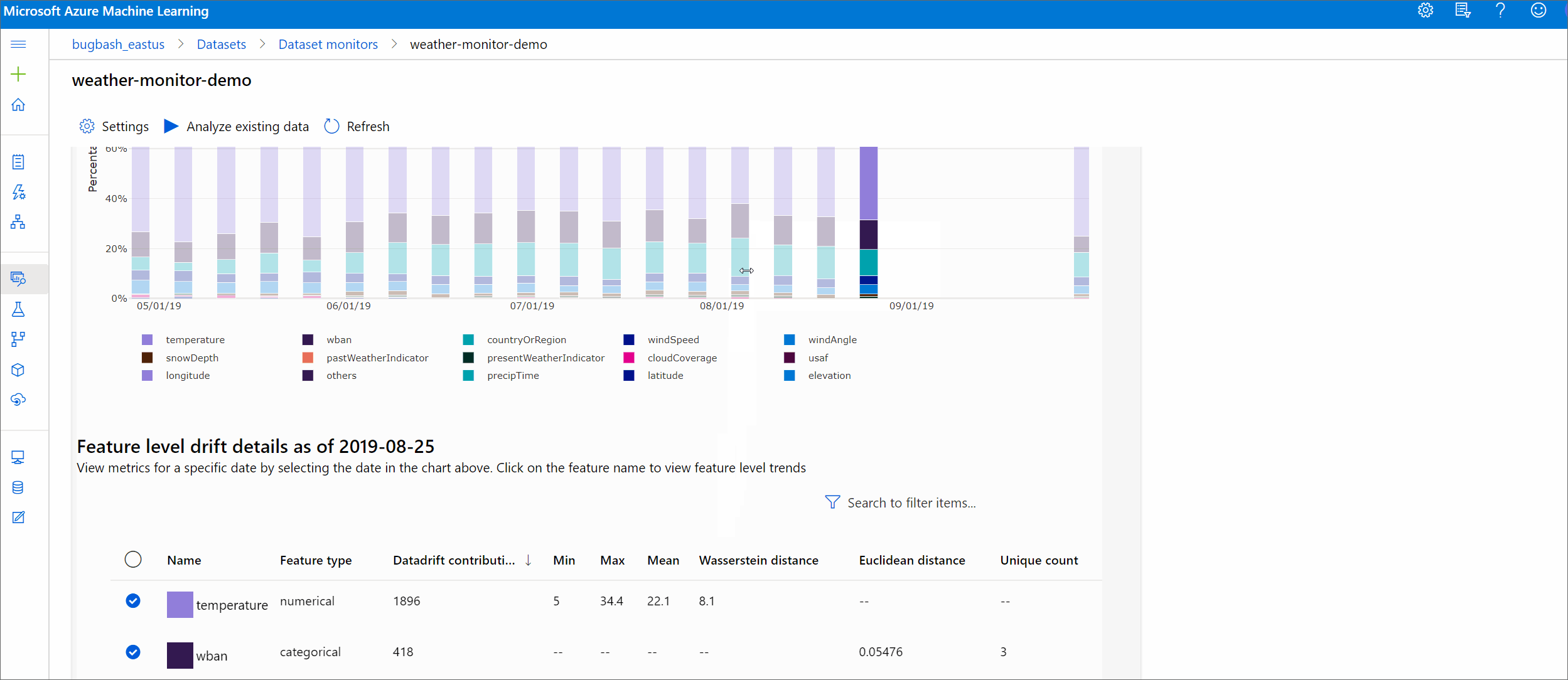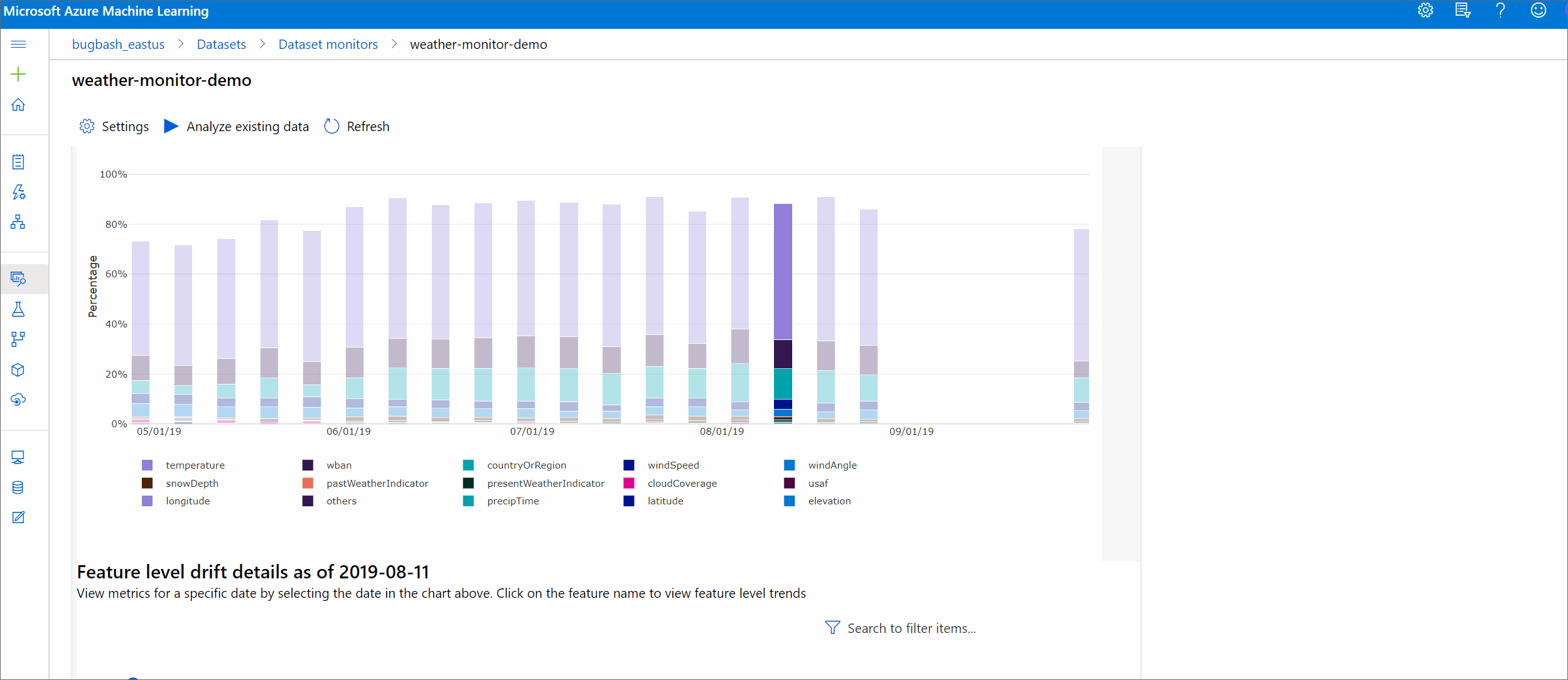
Сведения о функции
Наконец, выполните прокрутку вниз для просмотра сведений о каждом отдельном признаке. Используйте раскрывающиеся списки над диаграммой, чтобы выбрать признак, и дополнительно выберите метрику, которую необходимо просмотреть.
Метрики на диаграмме зависят от типа признака.
Числовые признаки
Метрическая Description Метрика Васерштейна Минимальный объем работы, требуемой для преобразования контрольного распределения в целевое распределение. Среднее значение Среднее значение признака. Минимальное значение Минимальное значение признака. Максимальное значение Максимальное значение признака. Категориальные признаки
Метрическая Description Евклидово расстояние Вычисляется для столбцов категорий. Евклидово расстояние вычисляется на двух векторах, сформированных из эмпирического распределения одного и того же столбца категорий из двух наборов данных. Значение 0 не указывает на разницу в эмпирических распределениях. Чем больше это значение отклоняется от 0, тем более смещен данный столбец. Тренды можно рассматривать с помощью графика временных рядов для этой метрики, что может оказаться полезным при обнаружении смещения признака. Уникальные значения Число уникальных значений (кардинальность) признака.
На этой диаграмме выберите одну дату для сравнения распределения признака между целевым объектом и этой датой для отображаемого признака. Применительно к числовым признакам это показывает два распределения вероятностей. Если признак является числовым, отображается линейчатая диаграмма.
Метрики, оповещения и события
Вы можете запросить метрики в ресурсе Azure Application Insights, связанном с рабочей областью машинного обучения. У вас есть доступ ко всем функциям Application Insights, включая настройку для пользовательских правил генерации оповещений и групп действий для активации действия, например функции Email/SMS/Push/Voice или Azure. Дополнительные сведения см. в полной документации по Application Insights.
Чтобы приступить к работе, перейдите на портал Azure и выберите страницу Обзор своей рабочей области. Связанный ресурс Application Insights находится в крайнем правом углу:

Выберите журналы (аналитика) в разделе "Мониторинг" на левой панели:
Метрики монитора набора данных хранятся в customMetrics. После настройки монитора набора данных можно написать и выполнить запрос для их просмотра:

После определения метрик для настройки правил оповещения создайте новое правило оповещения:
Можно использовать существующую группу действий или создать новую, чтобы определить действие, выполняемое при соблюдении заданных условий набора.
Устранение неполадок
Ограничения и известные проблемы для мониторов смещения данных
Диапазон времени при анализе исторических данных ограничивается 31 интервалом в параметре частоты монитора.
Ограничение в 200 признаков, если не указан список признаков (то есть используются все признаки).
Размер среды вычисления должен быть достаточно большим для обработки данных.
Убедитесь, что набор данных содержит данные в пределах начальной и конечной даты для данного задания монитора.
Мониторы набора данных работают только с наборами данных, содержащими 50 строк или более.
Столбцы или признаки в наборе данных подразделяются на категориальные или числовые в зависимости от условий в следующей таблице. Если функция не соответствует этим условиям , например, столбец строки типа с >100 уникальными значениями - функция удаляется из алгоритма смещения данных, но по-прежнему профилируется.
Тип компонента Тип данных Condition Ограничения Категориальный строка Число уникальных значений в признаке меньше 100 и меньше 5% от количества строк. Значение NULL считается собственной категорией. числовые; int, float Значения в функции являются числовым типом данных и не соответствуют условию категориальной функции. Признак исключается, если >15% значений равны нулю. Если вы создали монитор смещения данных, но не видите данные на странице мониторов наборов данных в Студия машинного обучения Azure, попробуйте следующее.
- Проверьте, правильный ли диапазон дат выбран в верхней части страницы.
- На вкладке Мониторы набора данных выберите ссылку эксперимента для проверки состояния задания. Эта ссылка находится на правом краю таблицы.
- Если задание завершилось успешно, проверьте журналы драйвера, чтобы увидеть, сколько метрик было создано и имеются ли предупреждения. Найдите журналы драйверов на вкладке "Выходные данные и журналы" после выбора эксперимента.
Если функция SDK
backfill()не создает ожидаемые выходные данные, может возникнуть проблема с проверкой подлинности. При создании вычислительных ресурсов для передачи в эту функцию не используйтеRun.get_context().experiment.workspace.compute_targets. Вместо этого используйте ServicePrincipalAuthentication, как показано ниже, чтобы создать вычисление, передаваемое в эту функциюbackfill():
Примечание.
Не закодируйте пароль субъекта-службы в коде. Вместо этого получите его из среды Python, хранилища ключей или другого безопасного метода доступа к секретам.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
Сборщик данных модели может занять до 10 минут, чтобы данные прибыли в учетную запись хранения BLOB-объектов. Однако обычно это занимает меньше времени. В скрипте или записной книжке подождите 10 минут, чтобы убедиться, что ячейки ниже успешно выполняются.
import time time.sleep(600)
Следующие шаги
- Перейдите в Студию машинного обучения Azure или в записную книжку Python, чтобы настроить монитор набора данных.
- Узнайте, как настроить смещение данных в моделях, развернутых в Службе контейнеров Azure.
- Настройте мониторы смещения набора данных с помощью Сетки событий Azure.