Управление версиями и отслеживание наборов данных машинного обучения Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
В этой статье вы узнаете, как управлять версиями наборов данных машинного обучения и как их отслеживать с целью воспроизводимости. Закладки для управления версиями набора данных позволяют применять определенную версию набора данных для будущих экспериментов.
Возможно, вам потребуется версия ресурсов Машинное обучение Azure в следующих типичных сценариях:
- Когда новые данные становятся доступными для переобучения
- При применении различных подходов к подготовке данных или проектированию признаков
Необходимые компоненты
Пакет SDK Машинного обучения Azure для Python. Этот пакет SDK включает пакет наборов данных azureml-datasets
Рабочая область Машинного обучения Azure. Создайте новую рабочую область или получите существующую рабочую область с помощью этого примера кода:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Регистрация и получение версий наборов данных
Вы можете использовать версию, повторно использовать и совместно использовать зарегистрированный набор данных между экспериментами и коллегами. Можно зарегистрировать несколько наборов данных под одинаковым именем и получить определенную версию по имени и номеру версии.
Регистрация версии набора данных
Этот пример кода задает create_new_version параметр titanic_ds набора Trueданных для регистрации новой версии этого набора данных. Если рабочая область не имеет существующего titanic_ds набора данных, код создает новый набор данных с именем titanic_dsи задает ее версию 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Получение набора данных по имени
По умолчанию метод класса get_by_name() возвращает последнюю версию набора данных, Dataset зарегистрированного в рабочей области.
Этот код возвращает версию 1 titanic_ds набора данных.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Рекомендации по управлению версиями
При создании версии набора данных не создается дополнительная копия данных с рабочей областью. Так как наборы данных ссылаются на данные в службе хранилища, у вас есть один источник истины, управляемый службой хранилища.
Внимание
Если данные, на которые ссылается набор данных, перезаписываются или удаляются, вызов определенной версии набора данных не возвращает изменения.
При загрузке данных из набора данных всегда загружается текущее содержимое данных, на которое ссылается этот набор. Если вы хотите убедиться, что каждая версия набора данных воспроизводима, рекомендуется избежать изменения содержимого данных, на который ссылается версия набора данных. При появлении новых данных сохраните новые файлы данных в отдельную папку данных, а затем создайте новую версию набора данных для включения данных из этой новой папки.
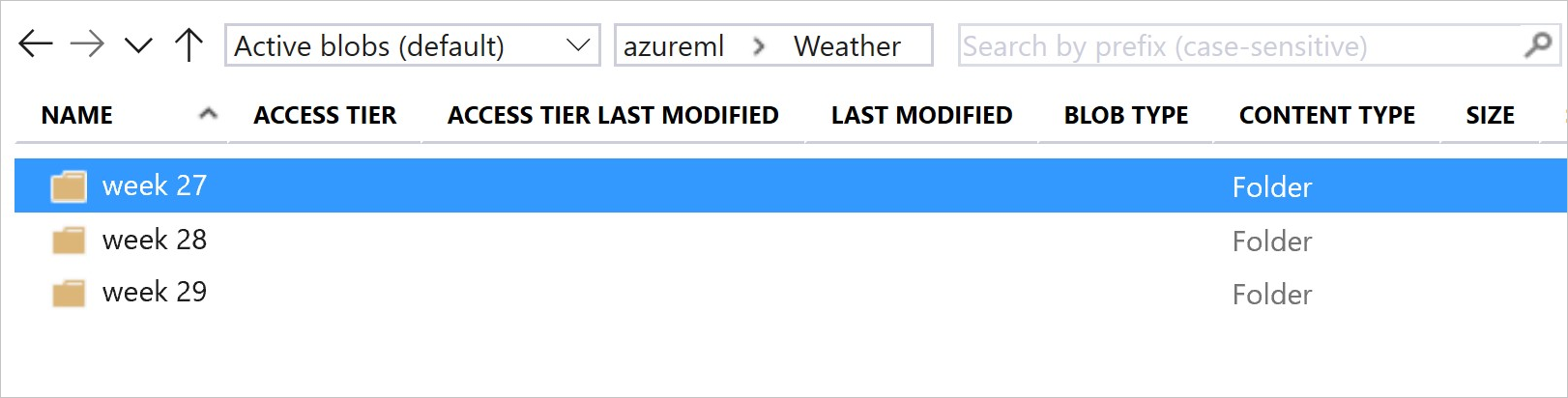
Этот образ и пример кода показывают рекомендуемый способ структурировать папки данных и создавать версии набора данных, ссылающиеся на эти папки:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Управление версиями набора выходных данных конвейера машинного обучения
Набор данных можно использовать как входные и выходные данные каждого шага конвейера машинного обучения. При повторном запуске конвейеров выходные данные каждого шага конвейера регистрируются как новая версия набора данных.
Машинное обучение конвейеры заполняют выходные данные каждого шага в новую папку каждый раз при повторном запуске конвейера. Затем наборы выходных данных с версиями становятся воспроизводимыми. Дополнительные сведения см . в наборах данных в конвейерах.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Отслеживание данных в экспериментах
Машинное обучение Azure отслеживает ваши данные во время эксперимента как входные и выходные наборы данных. В этих сценариях данные отслеживаются как входной набор данных:
DatasetConsumptionConfigКак объект илиinputsargumentsпараметрScriptRunConfigобъекта при отправке задания экспериментаЕсли скрипт вызывает определенные методы или
get_by_name()get_by_id(), например. Имя, назначенное набору данных во время регистрации этого набора данных в рабочей области, — отображаемое имя.
В этих сценариях данные отслеживаются как выходной набор данных:
OutputFileDatasetConfigПередайте объект черезoutputsargumentsили параметр при отправке задания эксперимента.OutputFileDatasetConfigОбъекты также могут сохранять данные между шагами конвейера. Дополнительные сведения см. в разделе "Перемещение данных между шагами конвейера машинного обучения"Регистрация набора данных в сценарии. Имя, назначенное набору данных при регистрации в рабочей области, отображается имя. В этом примере
training_dsкода отображается отображаемое имя:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Отправка дочернего задания с незарегистрированным набором данных в скрипте. Эта отправка приводит к тому, что анонимный сохраненный набор данных
Отслеживание наборов данных в заданиях экспериментов
Для каждого Машинное обучение эксперимента можно отслеживать входные наборы данных для объекта экспериментаJob. В этом примере кода используется get_details() метод для отслеживания входных наборов данных, используемых при выполнении эксперимента:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
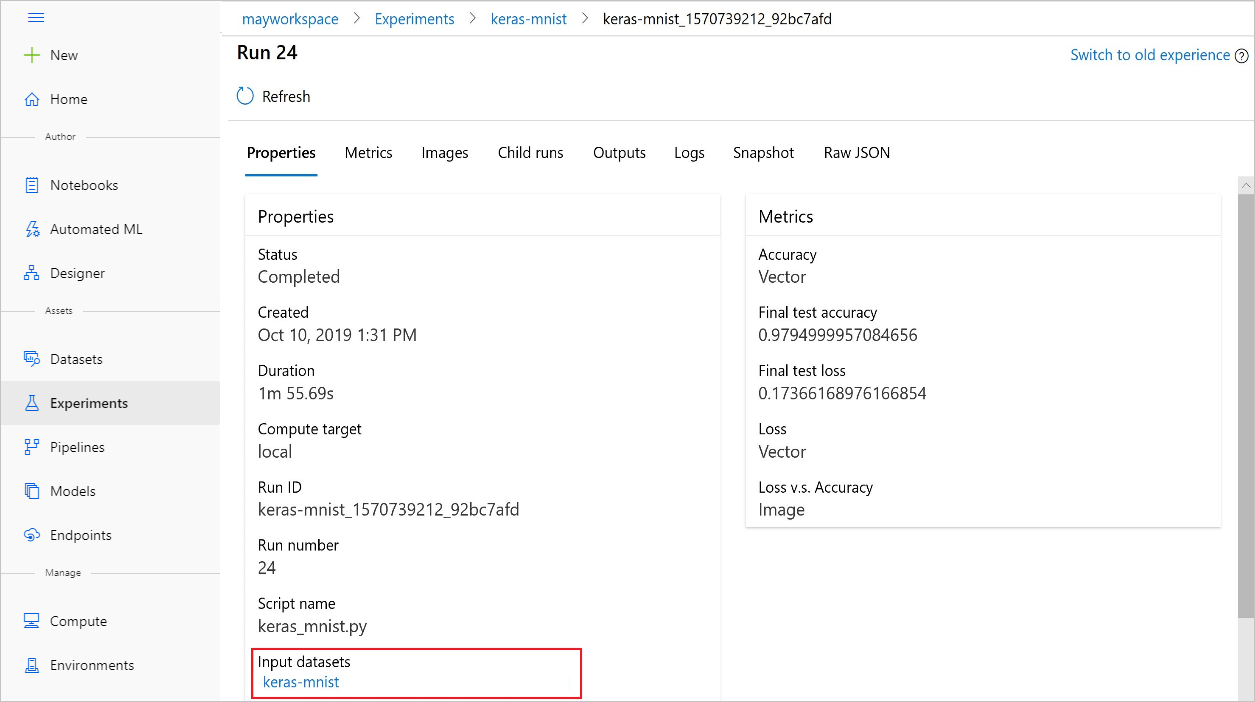
Вы также можете найти из input_datasets экспериментов с Студия машинного обучения Azure.
На этом снимку экрана показано, где найти входной набор данных эксперимента на Студия машинного обучения Azure. В этом примере начните с панели "Эксперименты" и откройте вкладку "Свойства " для определенного запуска эксперимента keras-mnist.
Этот код регистрирует модели с помощью наборов данных:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
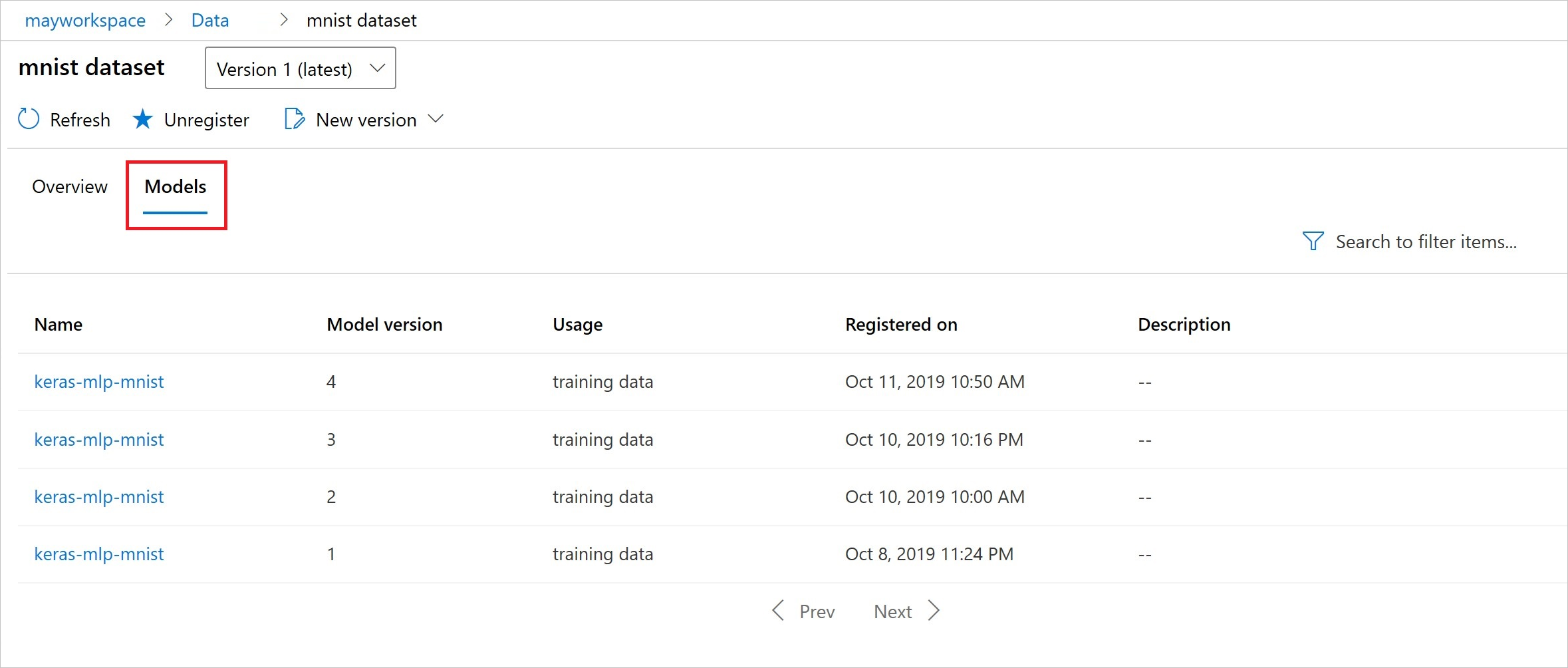
После регистрации вы увидите список моделей, зарегистрированных в наборе данных с помощью Python или студии.
Снимок экрана Тья находится на панели наборов данных в разделе "Ресурсы". Выберите набор данных и перейдите на вкладку "Модели " для списка моделей, зарегистрированных в наборе данных.