Сбор данных из моделей в рабочей среде
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
В этой статье показывается, как собирать данные из модели Машинного обучения Azure, развернутой в кластере Azure Kubernetes Service (AKS). Собранные данные сохраняются в хранилище BLOB-объектов Azure.
Собранные данные помогут вам выполнять следующие действия.
Отслеживать смещения данных в собранных производственных данных.
Анализировать собранные данные с помощью Power BI или Azure Databricks.
Принимать более взвешенные решения о необходимости повторного обучения или оптимизации модели.
Повторно обучить модель, используя собранные данные.
Ограничения
- Функция сбора данных модели может работать только с образом Ubuntu 18.04.
Внимание
По состоянию на 03.10.2023 образ Ubuntu 18.04 теперь устарел. Поддержка образов Ubuntu 18.04 будет удалена начиная с января 2023 г. после достижения EOL 30 апреля 2023 г.
Функция MDC несовместима с любым другим образом, кроме Ubuntu 18.04, который недоступен после того, как образ Ubuntu 18.04 не рекомендуется.
Дополнительные сведения см. в следующей статье:
Примечание.
Функция сбора данных в настоящее время находится в предварительной версии, для рабочих рабочих нагрузок не рекомендуется использовать любые функции предварительной версии.
Какие данные собираются и куда они попадают
Вы можете собирать следующие данные:
Входные данные модели из веб-служб, развернутых в кластере AKS. Аудиозаписи, изображения и видео не собираются.
Прогнозирование моделей с использованием входных данных рабочей среды.
Примечание.
Предварительная агрегация и предварительные вычисления с этими данными сейчас не входят в службу сбора данных.
Выходные данные сохраняются в хранилище BLOB-объектов. Поскольку данные добавляются в хранилище BLOB-объектов, вы можете выбрать для проведения анализа инструмент по своему желанию.
Для пути к выходным данным в BLOB-объекте используется следующий синтаксис:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Примечание.
В версиях пакета SDK для Машинного обучения Azure для Python ниже 0.1.0a16 аргумент designation имеет имя identifier. Если вы разработали код с более ранней версией, необходимо установить соответствующее обновление.
Необходимые компоненты
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
У вас должны быть установлены рабочая область машинного обучения Azure, локальный каталог со сценариями и пакет SDK машинного обучения Azure для Python. Инструкции по их установке см. в статье о настройке среды разработки.
Для развертывания в AKS требуется обученная модель машинного обучения. Если у вас ее нет, см. руководство по обучению модели классификации изображений.
Вам нужен кластер AKS. Сведения о том, как его создать и выполнить в нем развертывание, см. в разделе Развертывание моделей машинного обучения в Azure.
Настройте свою среду и установите пакет SDK для мониторинга службы "Машинное обучение Azure".
Используйте образ Docker на основе Ubuntu 18.04, который поставляется с
libssl 1.0.0, основной зависимостью modeldatacollector. Вы можете ссылаться на предварительно созданные образы.
Включение сбора данных
Сбор данных можно включить независимо от того, какую модель вы развертываете с помощью службы "Машинное обучение Azure" или других средств.
Чтобы включить сбор данных, выполните следующие действия.
Откройте файл оценки.
Добавьте следующий код в начало файла:
from azureml.monitoring import ModelDataCollectorОбъявите переменные коллекции данных в функции
init:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])Параметр CorrelationId необязателен. Если ваша модель его не требует, этот параметр можно не использовать. При этом параметр CorrelationId упрощает сопоставление с другими данными, такими как LoanNumber или CustomerId.
Параметр Identifier впоследствии будет использоваться для создания структуры папок в большом двоичном объекте. Его можно использовать для отделения обработанных данных от необработанных.
Добавьте в функцию
run(input_df)следующие строки кода.data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobПри развертывании службы в AKS сбор данных не получает значение true автоматически. Обновите файл конфигурации, как показано в следующем примере:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)Вы также можете включить Application Insights для мониторинга службы, изменив эту конфигурацию:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Сведения о создании образа и развертывании модели машинного обучения см. в разделе Развертывание моделей машинного обучения в Azure.
Добавьте в зависимости conda среды веб-службы пакет PIP "Azure-Monitoring":
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Отключение сбора данных
Сбор данных может остановить в любой момент. Для отключения сбора данных использует код Python.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Проверка и анализ данных
Вы можете выбрать для анализа данных, собранных в хранилище BLOB-объектов, любой предпочитаемый инструмент.
Быстрый доступ к данным BLOB-объектов
Войдите на портал Azure.
Перейдите в рабочую область.
Выберите Хранилище.

Укажите путь к выходным данным BLOB-объекта, используя следующий синтаксис:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Анализ данных модели с помощью Power BI
Скачайте и установите приложение Power BI Desktop.
Выберите Получить данные, а затем Хранилище BLOB-объектов Azure.
Добавьте имя учетной записи хранения и введите ключ к хранилищу данных. Эти сведения можно найти, выбрав Параметры>Ключи доступа.
Выберите контейнер modeldata и нажмите кнопку Изменить.
В редакторе запросов щелкните столбец Имя и добавьте свою учетную запись хранения.
Введите путь к модели в фильтр. Если вы хотите искать только файлы за определенный год или месяц, просто разверните путь фильтра. Например, для просмотра данных только за март используйте следующий путь фильтра:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
Для отображения нужных данных отфильтруйте их по имени. Если вы сохранили прогнозы и входные данные, для них нужно создать отдельные запросы.
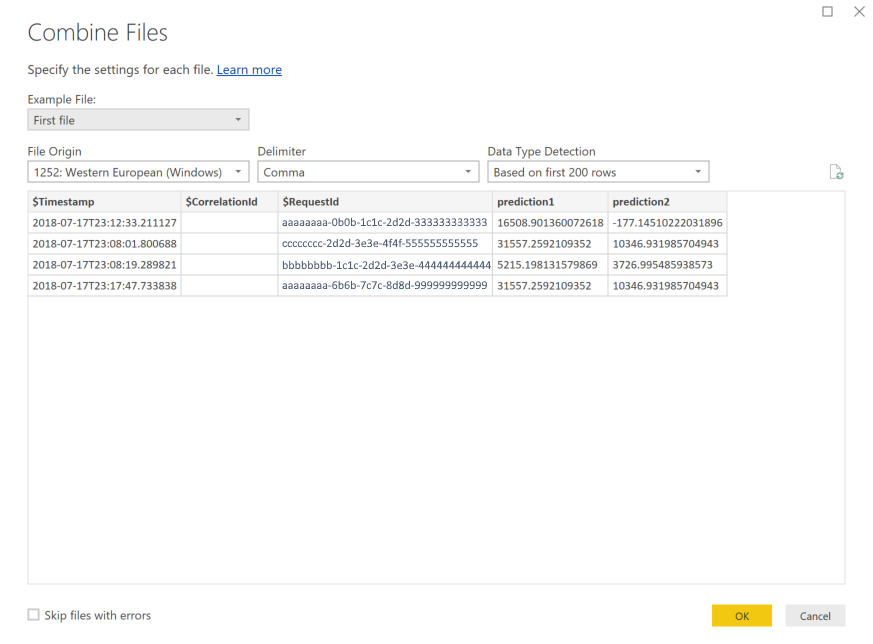
Нажмите на двойные стрелки вниз рядом с заголовком столбца Содержимое, чтобы объединить файлы.
Нажмите ОК. Будет выполнена предварительная загрузка данных.
Выберите Закрыть и применить.
Если вы добавили входные данные и прогнозы, таблицы будут автоматически упорядочены по значениям в столбце RequestId.
Приступите к созданию пользовательских отчетов о данных модели.




Анализ данных модели с помощью Azure Databricks
Создайте рабочую область Azure Databricks.
Перейдите к рабочей области Databricks.
В рабочей области Databricks выберите Отправить данные.

Выберите параметр Создать новую таблицу, а затем Другие источники данных>Хранилище BLOB-объектов Azure>Создать таблицу в записной книжке.
Обновите расположение данных. Рассмотрим пример:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"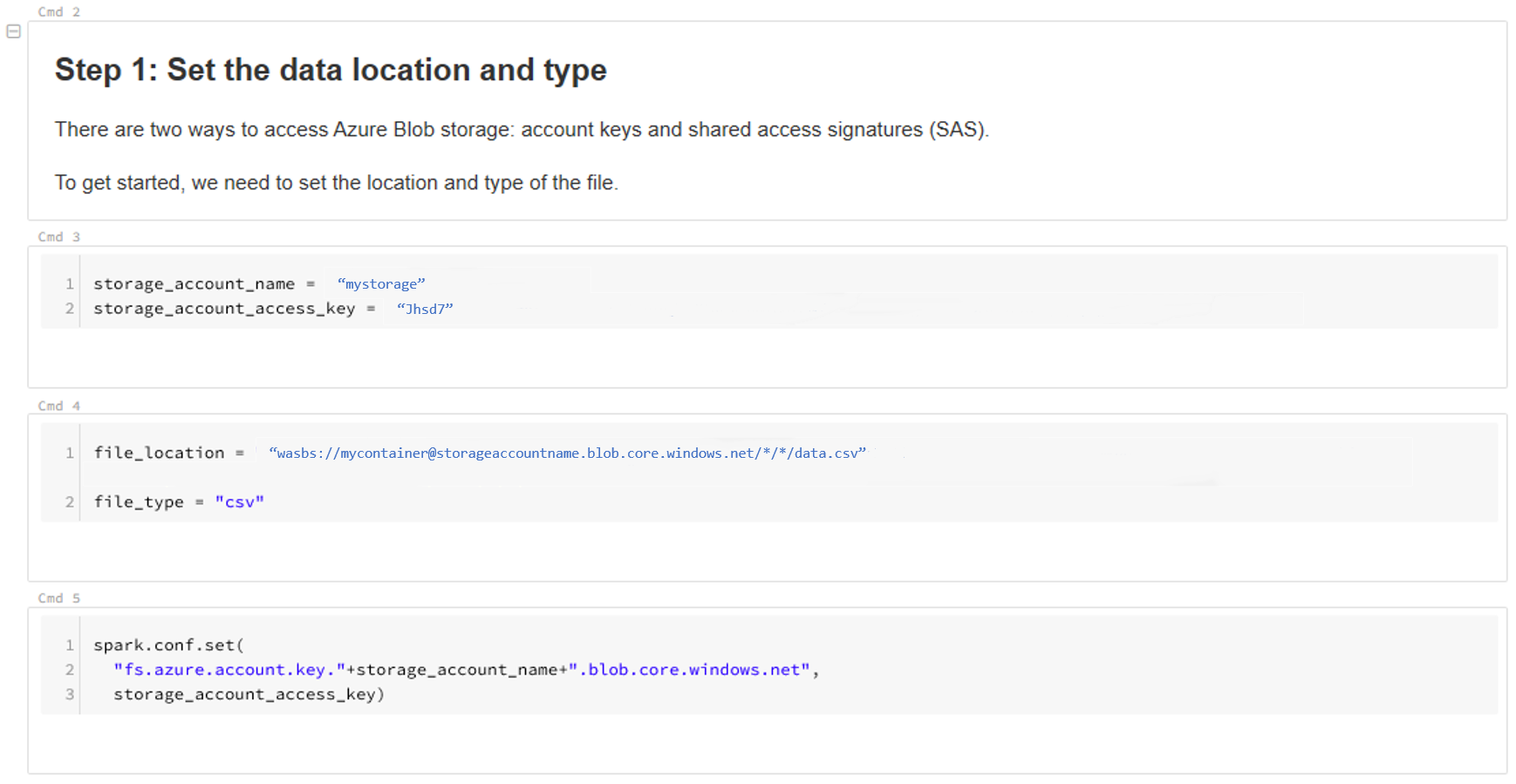
Следуйте инструкциям в шаблоне, чтобы просмотреть и проанализировать данные.



Следующие шаги
Обнаружение смещения для собранных данных.