Учебник. Обучение и развертывание модели классификации изображений с помощью примера Jupyter Notebook
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
В этом руководстве необходимо обучить модель машинного обучения на удаленных вычислительных ресурсах. Вы используете рабочий процесс обучения и развертывания для Машинное обучение Azure в Записной книжке Python Jupyter Notebook. Затем можно использовать записную книжку как шаблон для обучения собственной модели машинного обучения со своими данными.
В руководстве показано, как обучить простую модель регрессии для функции логистики с помощью набора данных MNIST и Scikit-learn в Машинном обучении Azure. MNIST — это популярный набор данных, состоящий из 70 000 изображений в оттенках серого. Каждое изображение содержит рукописную цифру размером 28 x 28 пикселей, то есть числа от нуля до девяти. Целью является создание многоклассового классификатора для идентификации цифры, которую отображает данное изображение.
Узнайте, как выполнять следующие действия:
- Скачайте набор данных и просмотрите данные.
- Обучите модель классификации изображений и регистрируйте метрики с помощью MLflow.
- Разверните модель для вывода в режиме реального времени.
Необходимые компоненты
- Выполните краткое руководство. Начало работы с Машинное обучение Azure:
- Создайте рабочую область.
- Создать облачный вычислительный экземпляр для использования в среде разработки.
Запуск записной книжки из рабочей области
Машинное обучение Azure включает в себя облачный сервер записной книжки в вашей рабочей области в качестве предварительно настроенного интерфейса, не требующего установки. Используйте собственную среду, если вы предпочитаете контролировать среду, пакеты и зависимости.
Клонирование папки записной книжки
Выполните следующие действия по настройке эксперимента и выполните шаги в Студии машинного обучения. Этот объединенный интерфейс включает в себя средства машинного обучения для выполнения сценариев обработки и анализа данных для специалистов по анализу с любым уровнем квалификации.
Войдите в Студию машинного обучения Azure.
Выберите свою подписку и рабочую область, которую создали.
Выберите Записные книжки слева.
В верхней части экрана перейдите на вкладку Примеры.
Откройте папку SDK версии 1 .
Нажмите кнопку ... справа от папки Учебники, а затем выберите Клонировать.
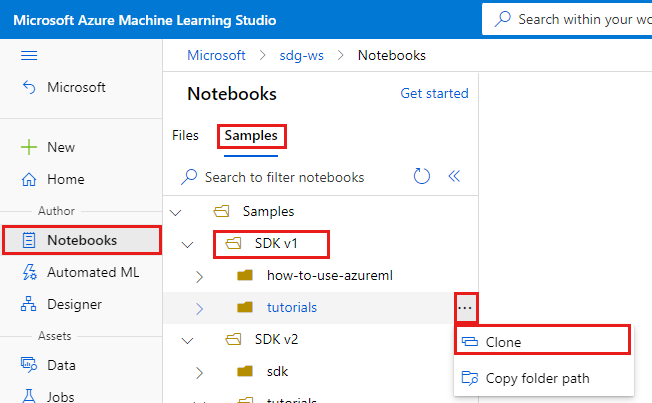
В списке папок отображается каждый пользователь, обращающийся к рабочей области. Выберите свою папку для клонирования папки Учебники.
Открытие клонированной записной книжки
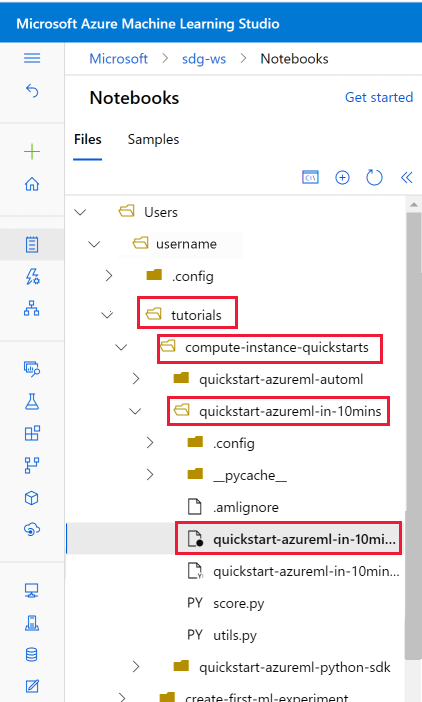
Откройте папку Учебники, которую вы клонировали в разделе Файлы пользователей.
Выберите файл quickstart-azureml-in-10mins.ipynb в папке tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins.
Установка пакетов
После запуска вычислительного экземпляра и появления ядра добавьте новую ячейку кода для установки пакетов, необходимых для работы с этим руководством.
Добавьте ячейку кода в верхней части записной книжки.
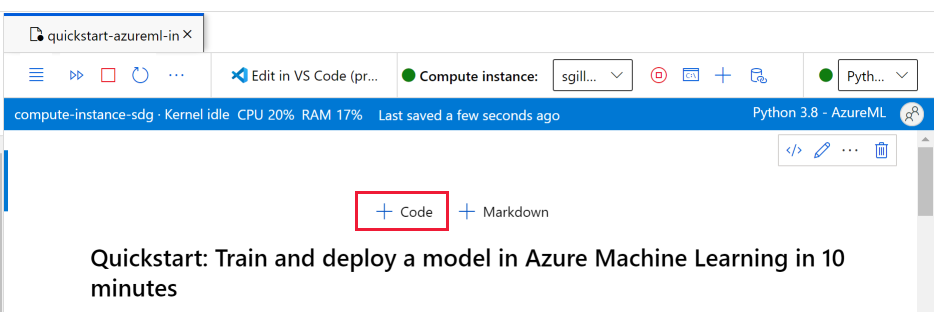
В ячейку добавьте приведенную ниже команду, а затем выполните ячейку с помощью инструмента Выполнить или с помощью клавиш SHIFT+ВВОД.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Может появиться несколько предупреждений об установке. Эти сообщения можно спокойно проигнорировать.
Запустите записную книжку
Это руководство и дополняющий его файл utils.py также доступны на сайте GitHub, если вы хотите использовать их в собственной локальной среде. Если вы не используете вычислительный экземпляр, добавьте %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib в указанную выше установку.
Внимание
Оставшаяся часть этой статьи содержит то же содержимое, что и записная книжка.
Перейдите в записную книжку Jupyter Notebook, если вы хотите выполнять код во время его просмотра. Чтобы выполнить одну ячейку кода в записной книжке, щелкните эту ячейку и нажмите клавиши SHIFT+ВВОД. Или запустите всю записную книжку, выбрав Запустить все в верхней части панели инструментов.
Импорт данных
Прежде чем начинать обучение модели, необходимо понимать, какие данные используются для ее обучения. Из этого раздела вы узнаете, как выполнять следующие действия.
- Скачивание набора данных MNIST
- Отображение некоторых примеров изображений
Наборы данных Azure Open используются для получения необработанных файлов данных MNIST. Открытые наборы данных Azure — это проверенные общедоступные наборы данных, которые можно использовать для добавления функций конкретных сценариев в решения машинного обучения для создания более эффективных моделей. Каждый набор данных использует соответствующий класс (в данном случае — MNIST) для получения данных различными способами.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Рассмотрим данные
Загрузите сжатые файлы в массивы numpy. Затем с помощью matplotlib постройте график 30 случайных изображений из набора данных с подписями над ними.
Обратите внимание, что для этого шага требуется load_data функция, включенная utils.py в файл. Этот файл находится в той же папке, что и эта записная книжка. Функция load_data выполняет анализ сжатых файлов, преобразовывая их в массивы numpy.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
В коде отображается случайный набор изображений со своими метками, как показано ниже:

Обучайте модель и регистрируйте метрики с помощью MLflow
Обучить модель с помощью следующего кода. Этот код использует автологирование MLflow для отслеживания метрик и артефактов модели журнала.
Для классификации данных вы будете использовать классификатор LogisticRegression из платформы SciKit Learn.
Примечание.
Обучение модели занимает около 2 минут.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Просмотр эксперимента
В меню слева в Студии машинного обучения Azure выберите Задания, а затем выберите свое задание (azure-ml-in10-mins-tutorial). Задание представляет собой совокупность нескольких запусков указанного скрипта или фрагмента кода. Несколько заданий можно сгруппировать в один эксперимент.
Сведения о запуске хранятся в соответствующем задании. Если имя не существует при отправке задания, при выборе запуска вы увидите различные вкладки, содержащие метрики, журналы, объяснения и т. д.
Управляйте версиями моделей с помощью реестра моделей
Используя регистрацию модели, вы можете сохранять и изменять модели в рабочей области. Зарегистрированные модели идентифицируются по имени и версии. При регистрации модели с уже существующим именем реестр увеличивает номер версии. Приведенный ниже код регистрирует и версионирует модель, которая была обучена ранее. После выполнения следующей ячейки кода вы увидите модель в реестре, выбрав "Модели" в меню слева в Студия машинного обучения Azure.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Развертывание модели для вывода в режиме реального времени
В этом разделе описано, как развернуть модель, чтобы приложение потребляло (вывод) модель через REST.
Создание конфигурации развертывания
Ячейка кода получает курируемую среду, в которой указаны все зависимости, необходимые для размещения модели (например, такие пакеты, как scikit-learn). Кроме того, вы создаете конфигурацию развертывания, в которой указывается объем вычислительных ресурсов, необходимых для размещения модели. В этом случае вычислительные ресурсы имеют 1 ЦП и 1 ГБ памяти.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Развертывание модели
Следующая ячейка кода развертывает модель в экземпляре контейнера Azure.
Примечание.
Развертывание занимает около 3 минут. Но это может быть дольше до тех пор, пока он не будет доступен для использования, возможно, до 15 минут.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
Файл скрипта оценки, на который ссылается предыдущий код, можно найти в той же папке, что и эта записная книжка, и имеет две функции:
- Функция
init, которая выполняется один раз при запуске службы. В этой функции вы обычно получаете модель из реестра и устанавливаете глобальные переменные - Функция
run(data), которая выполняется каждый раз при вызове службы. В этой функции обычно выполняется форматирование входных данных, выполнение прогноза и вывод прогнозируемого результата.
Просмотр конечной точки
После успешного развертывания модели можно просмотреть конечную точку, перейдя к конечным точкам в меню слева в Студия машинного обучения Azure. Вы увидите состояние конечной точки (работоспособное или неработоспособное), журналы и использование (как приложения могут использовать модель).
Тестирование службы модели
Вы можете протестировать модель, отправив необработанный HTTP-запрос для тестирования веб-службы.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Очистка ресурсов
Если вы не собираетесь продолжать использовать эту модель, удалите службу модели, используя:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Если вы хотите дополнительно контролировать затраты, остановите вычислительный экземпляр, нажав кнопку "Остановить вычисления" рядом с раскрывающимся списком Вычисления. Затем запустите вычислительный экземпляр снова в следующий раз, когда он понадобится.
Удаление всех ресурсов
Выполните следующие действия, чтобы удалить рабочую область Машинного обучения Azure и все вычислительные ресурсы.
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
В портал Azure в поле поиска введите группы ресурсов и выберите его из результатов.
Выберите созданную группу ресурсов из списка.
На странице "Обзор" выберите "Удалить группу ресурсов".
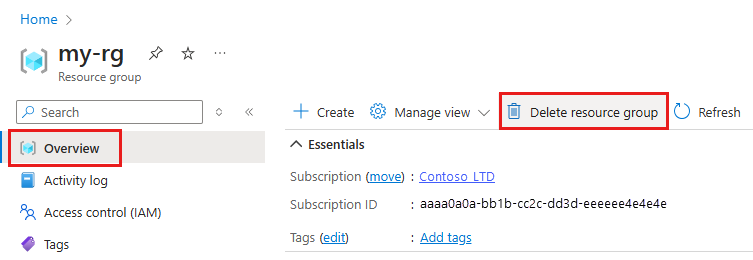
Введите имя группы ресурсов. Затем выберите Удалить.
Связанные ресурсы
- Сведения обо всех вариантах развертывания Машинного обучения Azure.
- Узнайте, как выполнить проверку подлинности в развернутой модели.
- Асинхронное создание прогнозов на больших объемах данных.
- Мониторинг моделей машинного обучения в Azure с помощью Application Insights.