Улучшение качества приложения RAG
В этой статье представлен обзор того, как можно уточнить каждый компонент, чтобы повысить качество вашего приложения с поддержкой дополненной генерации информации (RAG).
Существует множество "регуляторов" для настройки в каждой точке, как в автономном конвейере данных, так и в сети RAG. Хотя существует множество других, статья сосредоточена на наиболее важных настройках, которые имеют наибольшее влияние на качество вашего RAG-приложения. Databricks рекомендует начать с этих настроек.
Два типа рекомендаций по качеству
С концептуальной точки зрения полезно рассматривать параметры качества RAG с помощью объектива двух ключевых типов проблем качества:
Качество поиска: вы извлекаете наиболее релевантную информацию для заданного запроса на поиск?
Трудно создать высококачественный результат RAG, если в контексте, предоставленном LLM, отсутствует важная информация или содержатся лишние сведения.
Качество генерируемого ответа: учитывая полученные сведения и исходный запрос пользователя, генерирует ли LLM наиболее точный, последовательный и полезный ответ?
Здесь проблемы могут проявляться как галлюцинации, несогласованные выходные данные или сбой непосредственного обращения к запросу пользователя.
Приложения RAG имеют два компонента, которые можно модифицировать для решения проблем качества: конвейер данных и цепочку. Это заманчиво предположить четкое разделение между проблемами извлечения (просто обновить конвейер данных) и проблемами генерации (обновить цепочку RAG). Тем не менее, реальность гораздо сложнее. На качество извлечения могут влиять как поток данных (например, стратегия анализа и разбиения на блоки, стратегия метаданных, модель встраивания), так и цепочка RAG (например, преобразование пользовательских запросов, количество полученных фрагментов, повторное ранжирование). Аналогичным образом, качество генерации неизменно зависит от плохой выборки (например, неуместные или отсутствующие сведения, влияющие на выходные данные модели).
Это совпадение подчеркивает необходимость комплексного подхода к улучшению качества RAG. Понимая, какие компоненты следует изменять как в конвейере данных, так и в цепочке RAG, а также как эти изменения влияют на общее решение, можно вносить целевые обновления для улучшения качества выходных данных RAG.
Рекомендации по качеству конвейера данных
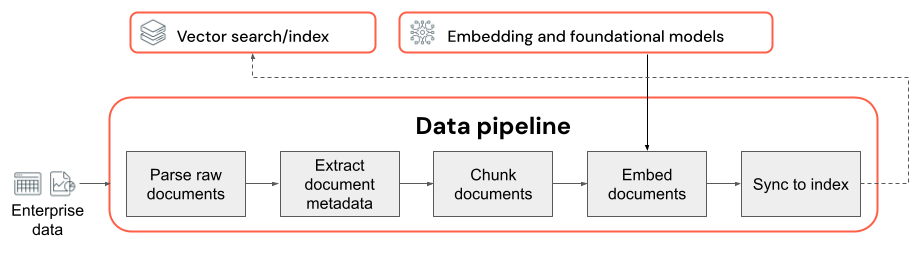
Основные аспекты конвейера данных:
- Состав корпуса входных данных.
- Как необработанные данные извлекаются и преобразуются в доступный формат (например, анализ PDF-документа).
- Разделение документов на небольшие блоки и форматирование этих блоков (например, стратегия блокирования и размер блока).
- Метаданные (например, название раздела или название документа), извлеченные о каждом документе и /или блоке. Как эти метаданные включены (или не включены) в каждый блок.
- Модель внедрения, используемая для преобразования текста в векторные представления для поиска сходства.
Цепочка RAG
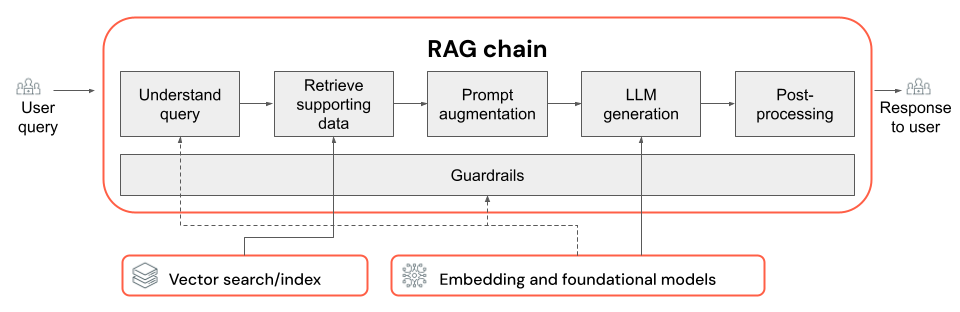
- Выбор LLM и его параметров (например, температуры и максимального количества токенов).
- Параметры извлечения (например, количество фрагментов или документов, полученных).
- Подход получения (например, ключевое слово против гибридного и семантического поиска, перезапись запроса пользователя, преобразование запроса пользователя в фильтры или повторное ранжирование).
- Как отформатировать запрос, используя извлеченный контекст, чтобы направить LLM на получение качественного результата.