Улучшение качества конвейера данных RAG
В этой статье описывается, как экспериментировать с выбором конвейера данных с практической точки зрения при реализации изменений конвейера данных.
Ключевые компоненты конвейера данных
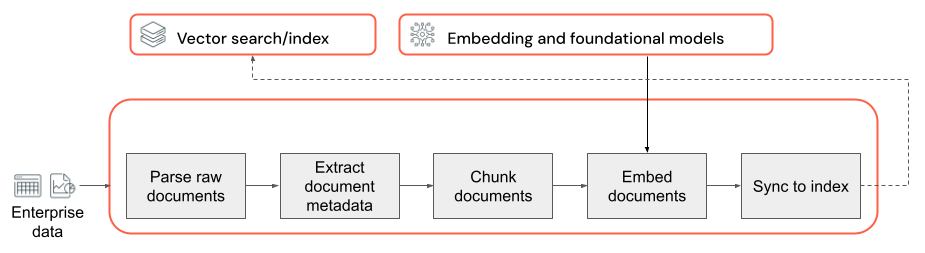
Основой любого приложения RAG с неструктурированными данными является конвейер данных. Этот конвейер отвечает за подготовку неструктурированных данных в формате, который можно эффективно использовать приложением RAG. Хотя этот конвейер данных может стать произвольным сложным, ниже перечислены ключевые компоненты, о которых необходимо думать при первом создании приложения RAG:
- Состав corpus: выбор нужных источников данных и содержимого в зависимости от конкретного варианта использования.
- Анализ. Извлечение соответствующих сведений из необработанных данных с помощью соответствующих методов синтаксического анализа.
- Фрагментирование: разбиение проанализированных данных на небольшие управляемые блоки для эффективного извлечения.
- Внедрение. Преобразование фрагментированных текстовых данных в числовое представление векторного представления, которое захватывает его семантический смысл.
Состав корпусов
Без правильного корпуса данных приложение RAG не может получить сведения, необходимые для ответа на запрос пользователя. Правильные данные полностью зависят от конкретных требований и целей приложения, что делает его важным для того, чтобы выделить время, чтобы понять нюансы доступных данных (см . раздел о сборе требований для этого руководства).
Например, при создании бота службы поддержки клиентов можно включить:
- Документы базы знаний
- Часто задаваемые вопросы
- Руководства и спецификации продуктов
- Руководства по устранению неполадок
Обратитесь к экспертам по домену и заинтересованным лицам с самого начала любого проекта, чтобы помочь определить и курировать соответствующее содержимое, которое может повысить качество и охват корпусов данных. Они могут предоставить аналитические сведения о типах запросов, которые пользователи, скорее всего, будут отправлять, и помочь определить приоритеты наиболее важных сведений для включения.
Разбор
Having определили источники данных для приложения RAG, следующим шагом является извлечение необходимых сведений из необработанных данных. Этот процесс, известный как синтаксический анализ, включает преобразование неструктурированных данных в формат, который можно эффективно использовать приложением RAG.
Конкретные методы анализа и средства, с которыми вы используете, зависят от типа данных, с которыми вы работаете. Например:
- Текстовые документы (PDF-файлы, документы Word): неструктурированные библиотеки, такие как неструктурированные и PyPDF2 , могут обрабатывать различные форматы файлов и предоставлять параметры настройки процесса синтаксического анализа.
- HTML-документы: библиотеки анализа HTML, такие как BeautifulSoup , можно использовать для извлечения соответствующего содержимого из веб-страниц. С их помощью можно перемещаться по структуре HTML, select находить определенные элементы и извлекать нужный текст или атрибуты.
- Изображения и сканированные документы: методы оптического распознавания символов (OCR) обычно требуются для извлечения текста из изображений. Популярные библиотеки OCR включают Tesseract, Amazon Textract, Azure AI Vision OCR и API Google Cloud Vision.
Рекомендации по анализу данных
При анализе данных рассмотрите следующие рекомендации.
- очистка данных: предварительно обработайте извлеченный текст, чтобы remove удалить любые ненужные или шумные сведения, такие как колонтитулы, нижние колонтитулы или специальные символы. Будьте осведомлены о снижении объема ненужных или неправильных данных, которые должна обрабатывать цепочка RAG.
- Обработка ошибок и исключений. Реализуйте механизмы обработки ошибок и ведения журнала для выявления и устранения проблем, возникающих во время процесса синтаксического анализа. Это помогает быстро выявлять и устранять проблемы. Это часто указывает на проблемы с качеством исходных данных.
- Настройка логики синтаксического анализа. В зависимости от структуры и формата данных может потребоваться настроить логику синтаксического анализа, чтобы извлечь наиболее релевантную информацию. Хотя это может потребовать дополнительных усилий заранее, инвестировать время, чтобы сделать это при необходимости, это часто предотвращает множество нижестоящих проблем качества.
- Оценка качества синтаксического анализа: регулярно оценивать качество проанализированных данных вручную, просматривая выборку выходных данных вручную. Это поможет вам определить любые проблемы или области для улучшения процесса синтаксического анализа.
Разделение на блоки
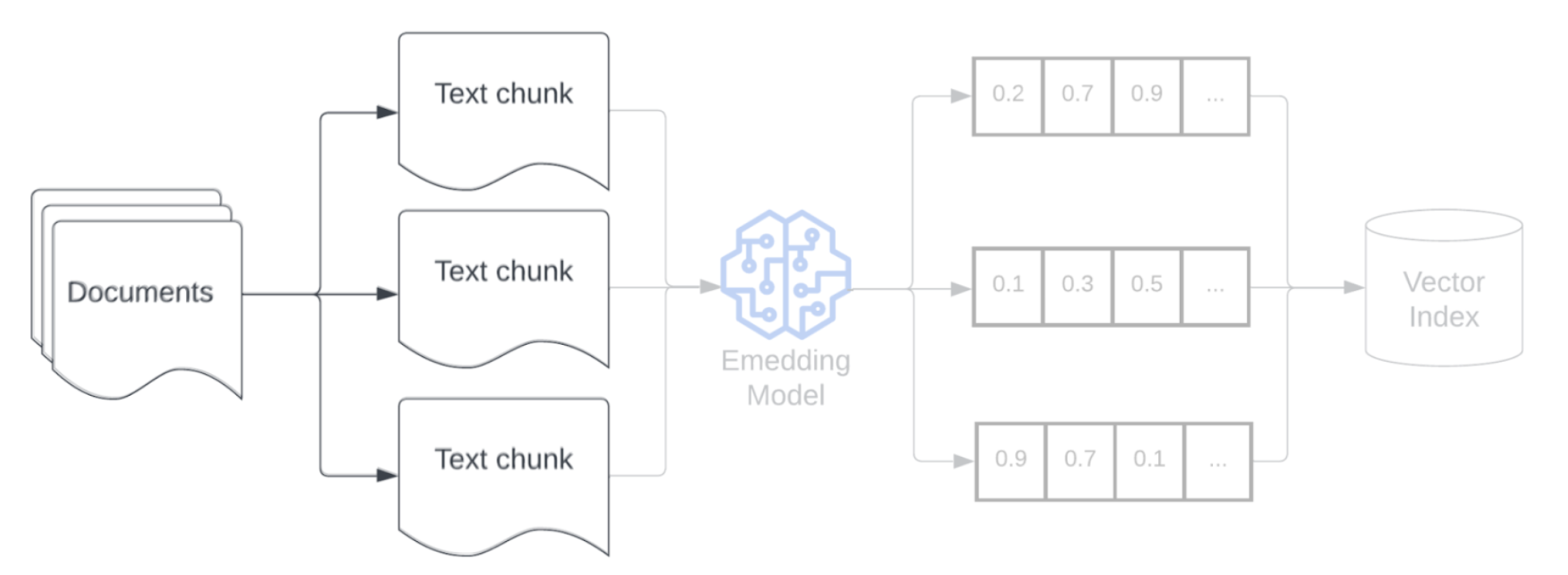
После анализа необработанных данных в более структурированном формате следующий шаг — разбить его на меньшие управляемые единицы, называемые блоками. Сегментирование больших документов на небольшие семантически концентрированные блоки гарантирует, что полученные данные соответствуют контексту LLM, минимизируя включение отвлекающих или неуместных сведений. Выбор, сделанный при фрагментации, напрямую влияет на то, что предоставляет полученные данные LLM, что делает его одним из первых уровней оптимизации в приложении RAG.
При блоке данных учитывайте следующие факторы:
- Стратегия блокирования: метод, используемый для разделения исходного текста на блоки. Это может включать в себя основные методы, такие как разделение по предложениям, абзацам или конкретным числам символов или маркеров, с помощью более сложных стратегий разделения документов.
- Размер блока: небольшие блоки могут сосредоточиться на конкретных деталях, но потерять некоторую окружающую информацию. Большие блоки могут записывать больше контекста, но также могут включать неуместные сведения.
- Перекрытие между блоками. Чтобы убедиться, что важная информация не теряется при разбиение данных на блоки, рассмотрите возможность включения некоторых перекрытий между смежными блоками. Перекрытие может обеспечить непрерывность и сохранение контекста между блоками.
- Семантическая согласованность: по возможности стремится создать блоки, которые семантические последовательно, то есть они содержат связанную информацию и могут стоять самостоятельно в качестве понятной единицы текста. Это можно сделать, учитывая структуру исходных данных, таких как абзацы, разделы или границы раздела.
- Метаданные: включая соответствующие метаданные в каждом блоке, например имя исходного документа, заголовок раздела или имена продуктов, могут улучшить процесс извлечения. Эта дополнительная информация в блоке может помочь сопоставить запросы извлечения с блоками.
Стратегии блокирования данных
Поиск правильного метода фрагментирования является итеративным и зависимым от контекста. Нет единого размера подход; Оптимальный размер блока и метод будет зависеть от конкретного варианта использования и характера обрабатываемых данных. Широко говоря, стратегии блокирования можно рассматривать следующим образом:
- Фрагментирование фиксированного размера: разделение текста на блоки предопределенного размера, например фиксированное количество символов или маркеров (например, LangChain CharacterTextSplitter). Хотя разделение по произвольному количеству символов и маркеров быстро и легко set вверх, обычно это не приведет к согласованной семантической последовательности блоков.
- Блоки на основе абзаца: используйте границы естественного абзаца в тексте для определения блоков. Этот метод может помочь сохранить семантику согласованности блоков, так как абзацы часто содержат связанные сведения (например, LangChain RecursiveCharacterTextSplitter).
- Блоки, относящиеся к формату: такие форматы, как markdown или HTML, имеют присущую им структуру, которую можно использовать для определения границ блоков (например, заголовков Markdown). Для этой цели можно использовать такие средства, как MarkdownChain MarkdownHeaderTextSplitter или разделителя заголовков/.
- Семантическое фрагментирование: такие методы, как моделирование тем, можно применять для определения семантических разделов в тексте. Эти подходы анализируют содержимое или структуру каждого документа, чтобы определить наиболее подходящие границы блоков на основе сдвигов в разделе. Хотя и более простые подходы, семантическая блокировка может помочь создать блоки, которые более выровнены с естественными семантические деления в тексте (пример этого см. в статье LangChain SemanticChunker ).
Пример. Исправление размера блока
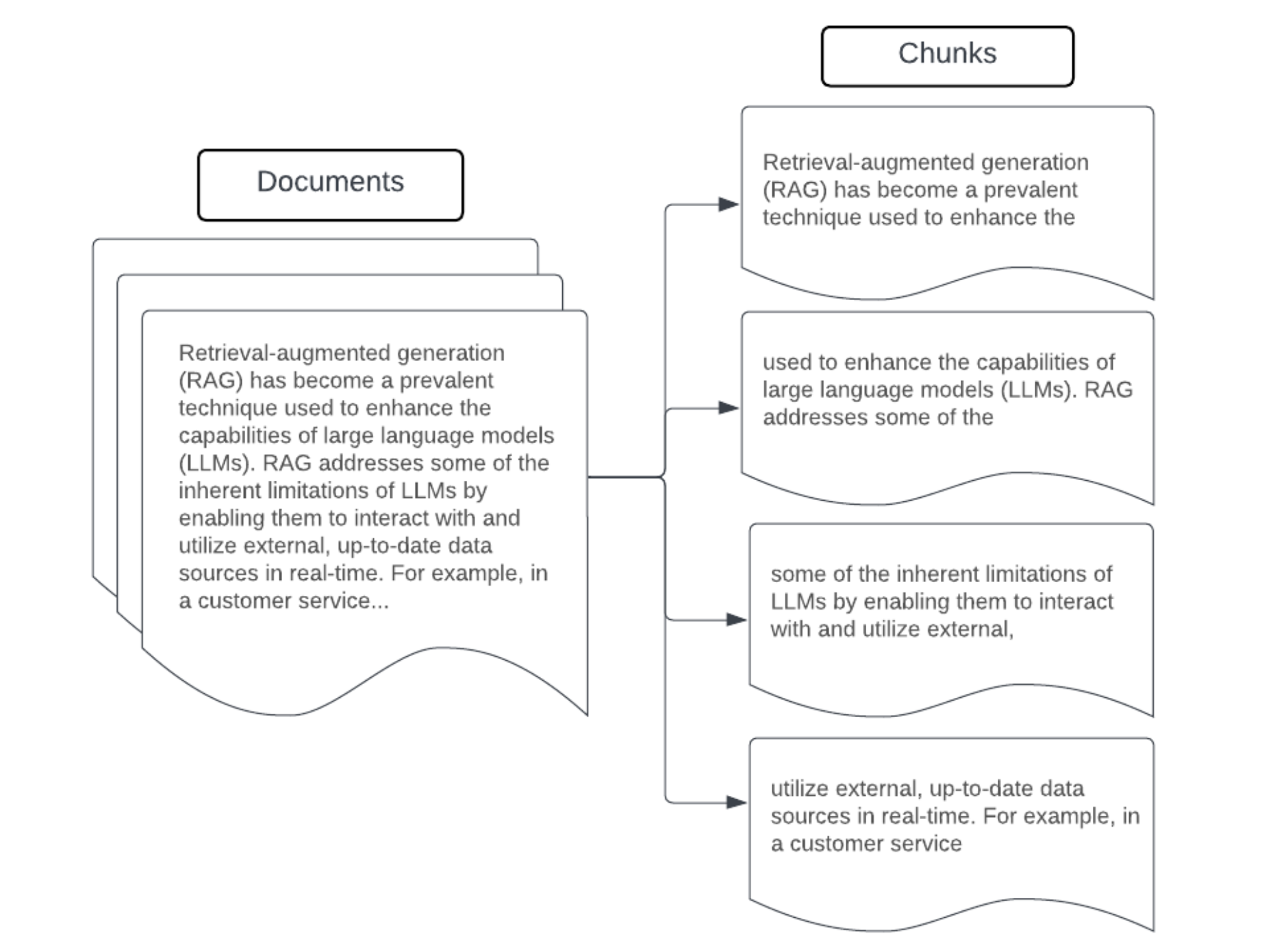
Пример фрагментирования фиксированного размера с помощью RecursiveCharacterCharacterTextSplitter langChain ChunkViz предоставляет интерактивный способ визуализации разных размеров блоков и перекрывающихся фрагментов values с разбиениями символов Langchain влияет на результирующий фрагмент.
Модель внедрения
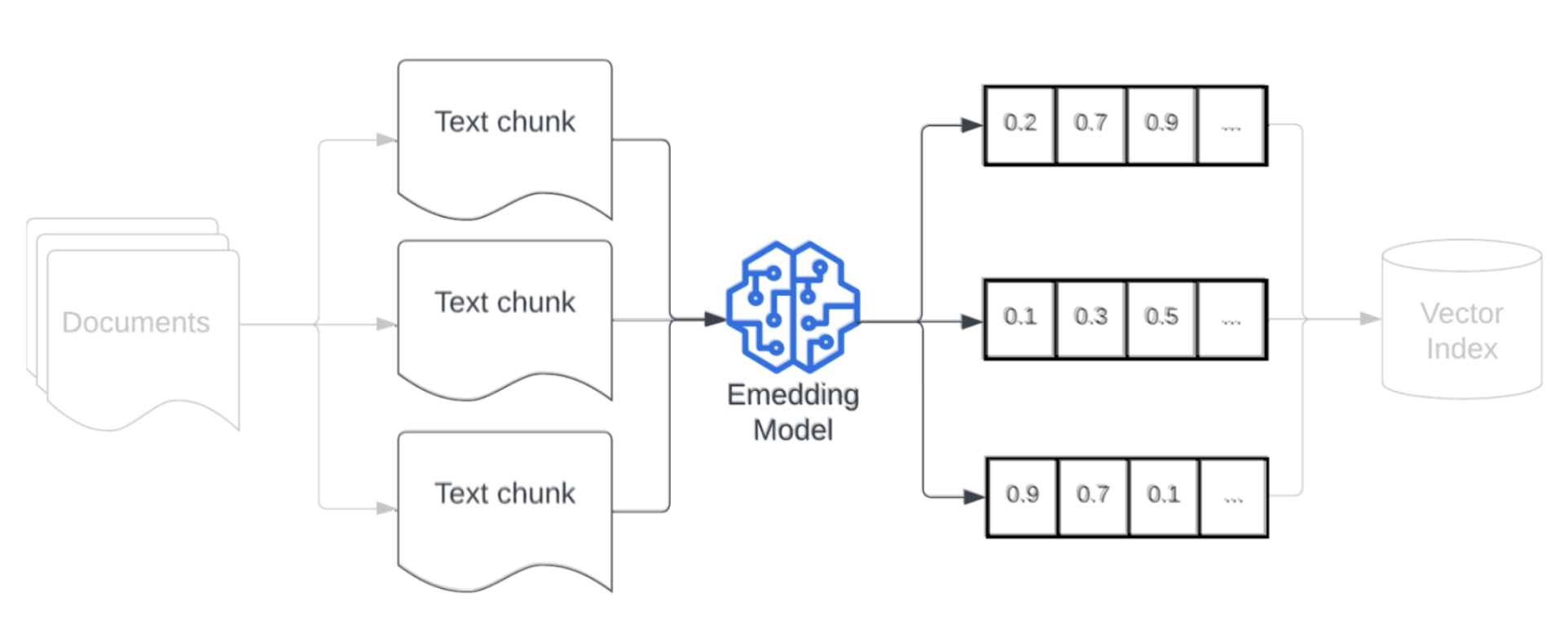
После фрагментирования данных следующим шагом является преобразование фрагментов текста в векторное представление с помощью модели внедрения. Модель внедрения используется для преобразования каждого фрагмента текста в векторное представление, которое фиксирует его семантический смысл. Предоставляя блоки в виде плотных векторов, внедрение позволяет быстро и точно извлекать наиболее релевантные блоки на основе их семантической сходства с запросом на получение. Во время запроса запрос будет преобразован с помощью той же модели внедрения, которая использовалась для внедрения блоков в конвейер данных.
При выборе модели внедрения учитывайте следующие факторы:
- Выбор модели. Каждая модель внедрения имеет свои нюансы, и доступные тесты могут не записывать конкретные характеристики данных. Экспериментируйте с различными моделями внедрения вне полки, даже теми, которые могут быть ниже ранжированы в стандартных списках лидеров, таких как MTEB. Ниже приведены некоторые примеры.
- Максимальные токены: учитывайте максимальное limit токенов для выбранной модели встраивания. Если вы отправляете блоки, размер которых превышает этот limit, они будут обрезаны, что может привести к потере важной информации. Например, bge-large-en-v1.5 имеет максимальный токен limit 512.
- Размер модели: более крупные модели внедрения обычно обеспечивают более высокую производительность, но требуют больше вычислительных ресурсов. Баланс между производительностью и эффективностью на основе конкретного варианта использования и доступных ресурсов.
- Тонкой настройке. Если приложение RAG работает с языком для конкретного домена (например, акронимами или терминологией внутренней компании), рассмотрите возможность точной настройки модели внедрения в данные, относящиеся к домену. Это может помочь модели лучше схватить нюансы и терминологию конкретного домена, и часто может привести к повышению производительности извлечения.