Улучшение качества цепочки RAG
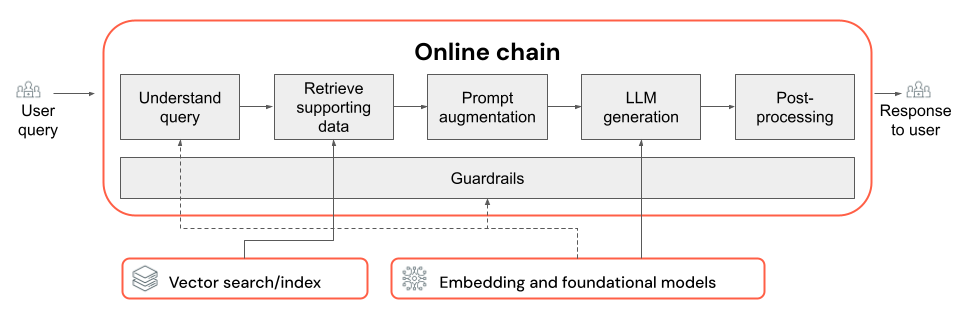
В этой статье описывается, как улучшить качество приложения RAG с помощью компонентов ЦЕПОЧКИ RAG.
Цепочка RAG принимает запрос пользователя в качестве входных данных, извлекает соответствующие сведения, учитывая этот запрос, и создает соответствующий ответ, полученный на основе полученных данных. Хотя точные шаги в цепочке RAG могут значительно отличаться в зависимости от варианта использования и требований, следующие ключевые компоненты, которые следует учитывать при создании цепочки RAG:
- Понимание запросов: анализ и преобразование запросов пользователей для лучшего представления намерений и извлечения соответствующих сведений, таких как фильтры или ключевые слова, для улучшения процесса извлечения.
- Извлечение: поиск наиболее релевантных фрагментов информации, заданных запросом на получение. В случае с неструктурированными данными это обычно включает в себя одно или сочетание семантического или ключевого слова поиска.
- Расширение запроса. Объединение запроса пользователя с извлеченными сведениями и инструкциями по созданию высококачественных ответов LLM.
- LLM: выбор наиболее подходящей модели (и параметров модели) для вашего приложения для оптимизации/баланса эффективности, задержки и затрат.
- После обработки и защиты: применение дополнительных шагов обработки и мер безопасности для обеспечения того, чтобы созданные LLM ответы были по теме, фактически согласованы и соответствуют определенным рекомендациям или ограничениям.
Итеративная реализация и оценка исправлений качества показывает, как выполнять итерацию по компонентам цепочки.
Понимание запросов
Использование пользовательского запроса непосредственно в качестве запроса извлечения может работать для некоторых запросов. Однако обычно рекомендуется переформатировать запрос перед этапом извлечения. Понимание запросов состоит из шага (или ряда шагов) в начале цепочки для анализа и преобразования пользовательских запросов, чтобы лучше представлять намерение, извлекать соответствующие сведения и в конечном итоге помочь последующему процессу извлечения. Ниже приведены подходы к преобразованию запроса пользователя для улучшения извлечения:
Перезапись запросов: перезапись запросов включает преобразование пользовательского запроса в один или несколько запросов, которые лучше представляют исходное намерение. Цель состоит в том, чтобы переформатировать запрос таким образом, чтобы повысить вероятность поиска наиболее релевантных документов. Это может быть особенно полезно при работе с сложными или неоднозначными запросами, которые могут не совпадать напрямую с терминологией, используемой в документах извлечения.
Примеры:
- Парафразирование журнала бесед в многоэтапном чате
- Исправление ошибок орфографии в запросе пользователя
- Замена слов или фраз в запросе пользователя синонимами для записи более широкого диапазона соответствующих документов
Внимание
Перезапись запросов должна выполняться вместе с изменениями компонента извлечения
Извлечение фильтров. В некоторых случаях запросы пользователей могут содержать определенные фильтры или критерии, которые можно использовать для сузки результатов поиска. Извлечение фильтра включает идентификацию и извлечение этих фильтров из запроса и передачу их на шаг извлечения в качестве дополнительных параметров. Это может помочь повысить релевантность извлеченных документов, сосредоточив внимание на определенных подмножествах доступных данных.
Примеры:
- Извлечение определенных периодов времени, упомянутых в запросе, таких как "статьи за последние 6 месяцев" или "отчеты с 2023 года".
- Определение упоминаний о конкретных продуктах, службах или категориях в запросе, таких как Databricks Professional Services или "ноутбуки".
- Извлечение географических сущностей из запроса, таких как имена городов или коды стран.
Примечание.
Извлечение фильтров должно выполняться вместе с изменениями в конвейере данных извлечения метаданных и компонентах цепочки извлекателя. Шаг извлечения метаданных должен обеспечить доступность соответствующих полей метаданных для каждого документа или блока, а шаг извлечения должен быть реализован для принятия и применения извлеченных фильтров.
Помимо перезаписи запросов и извлечения фильтров, важно учитывать, следует ли использовать один вызов LLM или несколько вызовов. При использовании одного вызова с тщательно созданным запросом может быть эффективным, существуют случаи, когда разбиение процесса понимания запросов на несколько вызовов LLM может привести к улучшению результатов. Это, кстати, обычно применимое правило большого пальца при попытке реализовать ряд сложных шагов логики в одном запросе.
Например, можно использовать один вызов LLM для классификации намерения запроса, другого для извлечения соответствующих сущностей, а третий — для перезаписи запроса на основе извлеченных сведений. Хотя этот подход может добавить некоторую задержку в общий процесс, он может обеспечить более подробный контроль и потенциально повысить качество извлеченных документов.
Многоэтапное понимание запросов для бота поддержки
Вот как компонент многошагового понимания запросов может искать бот службы поддержки клиентов:
- Классификация намерений. Используйте LLM для классификации запроса пользователя в предопределенные категории, такие как "сведения о продукте", "устранение неполадок" или "управление учетными записями".
- Извлечение сущностей: на основе идентифицированного намерения используйте другой вызов LLM для извлечения соответствующих сущностей из запроса, таких как имена продуктов, сообщаемые ошибки или номера учетных записей.
- Перезапись запросов: используйте извлеченные намерения и сущности для перезаписи исходного запроса в более конкретный и целевой формат, например"Моя цепочка RAG не может развернуться в службе моделей, я вижу следующую ошибку...".
Извлечение
Компонент получения ЦЕПОЧКИ RAG отвечает за поиск наиболее релевантных фрагментов информации, заданных запросом на получение. В контексте неструктурированных данных извлечение обычно включает одно или сочетание семантического поиска, поиска на основе ключевых слов и фильтрации метаданных. Выбор стратегии извлечения зависит от конкретных требований приложения, характера данных и типов запросов, которые требуется обрабатывать. Давайте сравним следующие параметры:
- Семантический поиск. Семантический поиск использует модель внедрения для преобразования каждого блока текста в векторное представление, которое захватывает его семантический смысл. Сравнивая векторное представление запроса извлечения с векторными представлениями блоков, семантический поиск может получить концептуально похожие документы, даже если они не содержат точных ключевых слов из запроса.
- Поиск на основе ключевых слов: поиск на основе ключевых слов определяет релевантность документов путем анализа частоты и распределения общих слов между запросом извлечения и индексированных документов. Чем чаще те же слова отображаются как в запросе, так и в документе, чем выше оценка релевантности, назначенная данному документу.
- Гибридный поиск: гибридный поиск объединяет преимущества семантического и ключевого слова, используя двухэтапный процесс извлечения. Во-первых, он выполняет семантический поиск для получения набора концептуально релевантных документов. Затем он применяет поиск на основе ключевых слов на этом сокращенном наборе, чтобы дополнительно уточнить результаты на основе точных совпадений ключевых слов. Наконец, он объединяет оценки из обоих шагов для ранжирования документов.
Сравнение стратегий извлечения
В следующей таблице сравнивается каждая из этих стратегий извлечения друг от друга:
| Семантический поиск | Поиск по ключевым словам | Гибридный поиск | |
|---|---|---|---|
| Простое объяснение | Если те же понятия отображаются в запросе и потенциальном документе, они актуальны. | Если те же слова отображаются в запросе и потенциальном документе, они актуальны. Чем больше слов из запроса в документе, тем более актуальным является этот документ. | Выполняет и семантический поиск, и поиск ключевых слов, а затем объединяет результаты. |
| Пример варианта использования | Поддержка клиентов, в которой запросы пользователей отличаются от слов в руководствах по продукту. Пример: "Как включить мой телефон?" и раздел вручную называется "переключение питания". | Служба поддержки клиентов, в которой запросы содержат определенные, не описательные технические термины. Пример: "Что делает модель HD7-8D?" | Запросы в службу поддержки клиентов, которые объединили как семантические, так и технические термины. Пример: "Как включить HD7-8D?" |
| Технические подходы | Использует внедрения для представления текста в непрерывном векторном пространстве, что позволяет выполнять семантический поиск. | Использует дискретные методы на основе токенов, такие как мешок слов, TF-IDF, BM25 для сопоставления ключевых слов. | Используйте метод повторного ранжирования для объединения результатов, таких как слияние взаимных ранжирований или модель повторного ранжирования. |
| Преимущества | Получение контекстно аналогичной информации запросу, даже если точные слова не используются. | Сценарии, требующие точного соответствия ключевых слов, идеально подходят для конкретных запросов, ориентированных на термины, например названия продуктов. | Объединяет лучший из обоих подходов. |
Способы улучшения процесса извлечения
Помимо этих основных стратегий извлечения, существует несколько методов, которые можно применить для дальнейшего улучшения процесса извлечения:
- Расширение запроса. Расширение запросов может помочь в захвате более широкого диапазона соответствующих документов с помощью нескольких вариантов запроса извлечения. Это можно сделать путем проведения отдельных поисков для каждого развернутого запроса или объединения всех развернутых поисковых запросов в одном запросе извлечения.
Примечание.
Расширение запросов должно выполняться вместе с изменениями компонента распознавания запросов (цепочка RAG). В этом шаге обычно создаются несколько вариантов запроса извлечения.
- повторное ранжирование: После получения начального набора блоков примените дополнительные критерии ранжирования (например, сортировка по времени) или модель повторного рангировщика, чтобы повторно упорядочить результаты. Повторное ранжирование может помочь определить приоритет наиболее релевантных фрагментов, заданных конкретным запросом на получение. Повторное использование моделей кросскодировщика, таких как mxbai-rerank и ColBERTv2 , может повысить производительность извлечения.
- Фильтрация метаданных. Используйте фильтры метаданных, извлеченные из шага понимания запросов, чтобы сузить пространство поиска на основе определенных критериев. Фильтры метаданных могут включать такие атрибуты, как тип документа, дата создания, автор или теги, относящиеся к домену. Объединение фильтров метаданных с семантической или ключевой строкой поиска позволяет создавать более целевое и эффективное извлечение.
Примечание.
Фильтрация метаданных должна выполняться вместе с изменениями компонентов распознавания запросов (цепочка RAG) и извлечения метаданных (конвейера данных).
Расширение запроса
Дополнение запроса — это этап, на котором запрос пользователя совмещается с извлеченной информацией и инструкциями в шаблоне запроса, чтобы направлять языковую модель для создания высококачественных ответов. Для обеспечения точных, обоснованных и согласованных ответов требуется выполнение итераций этого шаблона для оптимизации предоставленного запроса LLM (AKA инженерия запросов).
Существует целые руководства по проектированию запросов, но ниже приведены некоторые рекомендации, которые следует учитывать при итерации в шаблоне запроса:
- Укажите примеры
- Включите примеры хорошо сформированных запросов и их соответствующие идеальные ответы в самом шаблоне запроса (небольшое обучение). Это помогает модели понять нужный формат, стиль и содержимое ответов.
- Один из полезных способов придумать хорошие примеры заключается в определении типов запросов, с которыми борется цепочка. Создайте стандартные ответы для этих запросов и включите их в качестве примеров в запрос.
- Убедитесь, что приведенные примеры являются репрезентативными пользовательскими запросами, которые вы ожидаете во время вывода. Старайтесь охватывать разнообразный диапазон ожидаемых запросов, чтобы помочь модели лучше обобщать.
- Параметризация шаблона запроса
- Создайте шаблон запроса, чтобы быть гибким, параметризуя его, чтобы включить дополнительные сведения за пределами полученных данных и запроса пользователя. Это могут быть такие переменные, как текущая дата, контекст пользователя или другие соответствующие метаданные.
- Внедрение этих переменных в запрос во время вывода может включать более персонализированные или контекстные ответы.
- Рассмотрите возможность запроса в цепочке мысли
- Для сложных запросов, где прямые ответы не являются очевидными, рассмотрите возможность логической цепочки (CoT) с подсказкой. Эта стратегия разработки запросов разбивает сложные вопросы на более простые, последовательные шаги, направляющие LLM через логический процесс логики.
- Побудив модель "пошаговые меры", рекомендуется предоставить более подробные и обоснованные ответы, которые могут быть особенно эффективными для обработки многофакторных или открытых запросов.
- Запросы могут не передаваться по моделям
- Распознать, что запросы часто не передаются легко в разных языковых моделях. Каждая модель имеет собственные уникальные характеристики, где запрос, который хорошо работает для одной модели, может быть не столь эффективным для другой.
- Поэкспериментируйте с различными форматами и длинами запросов, ознакомьтесь с онлайн-руководствами (например, Cookbook OpenAI или Cookbook Anthropic), и будьте готовы подготовиться к адаптации и уточнению ваших запросов при переключении между моделями.
LLM
Компонент создания RAG цепочки принимает расширенный шаблон запроса из предыдущего шага и передает его в LLM. При выборе и оптимизации LLM для компонента создания ЦЕПОЧКИ RAG учитывайте следующие факторы, которые одинаково применимы к любым другим шагам, которые включают вызовы LLM:
- Экспериментируйте с различными моделями вне полки.
- Каждая модель имеет свои уникальные свойства, сильные стороны и слабые места. Некоторые модели могут лучше понимать определенные домены или лучше выполнять определенные задачи.
- Как упоминалось ранее, помните, что выбор модели также может повлиять на процесс разработки запросов, так как разные модели могут реагировать по-разному на те же запросы.
- Если в цепочке есть несколько шагов, для которых требуется LLM, например вызовы для понимания запросов в дополнение к шагу создания, рассмотрите возможность использования различных моделей для различных шагов. Более дорогие модели общего назначения могут быть переохвачены для задач, таких как определение намерения пользовательского запроса.
- При необходимости запустите небольшой и увеличить масштаб.
- Хотя это может быть заманчиво немедленно достичь самых мощных и способных моделей (например, GPT-4, Claude), это часто более эффективно начать с меньших, более легких моделей.
- Во многих случаях более мелкие альтернативы с открытым исходным кодом, такие как Llama 3 или DBRX, могут обеспечить удовлетворительные результаты по более низкой цене и с более быстрым временем вывода. Эти модели могут быть особенно эффективными для задач, которые не требуют очень сложных причин или обширных мировых знаний.
- При разработке и уточнении цепочки RAG непрерывно оценивает производительность и ограничения выбранной модели. Если вы обнаружите, что модель борется с определенными типами запросов или не предоставляет достаточно подробных или точных ответов, рассмотрите возможность масштабирования до более эффективной модели.
- Отслеживайте влияние изменения моделей на ключевые метрики, такие как качество отклика, задержка и затраты, чтобы обеспечить правильный баланс требований конкретного варианта использования.
- Оптимизация параметров модели
- Экспериментируйте с различными параметрами параметров, чтобы найти оптимальный баланс между качеством отклика, разнообразием и согласованности. Например, настройка температуры может контролировать случайность созданного текста, а max_tokens может ограничить длину отклика.
- Помните, что оптимальные параметры параметров могут отличаться в зависимости от конкретной задачи, запроса и требуемого стиля выходных данных. Итеративно тестируйте и уточняйте эти параметры на основе оценки созданных ответов.
- Настройка конкретной задачи
- При уточнении производительности рассмотрите возможность точной настройки небольших моделей для конкретных вложенных задач в цепочке RAG, таких как понимание запросов.
- Обучая специализированные модели для отдельных задач с цепочкой RAG, вы можете повысить общую производительность, уменьшить задержку и снизить затраты на вывод по сравнению с одной большой моделью для всех задач.
- Продолжение подготовки к обучению
- Если приложение RAG имеет дело с специализированным доменом или требует знаний, которые не хорошо представлены в предварительно обученном LLM, рассмотрите возможность выполнения непрерывного предварительного обучения (CPT) на данных, относящихся к домену.
- Продолжающееся предварительное обучение позволяет улучшить понимание конкретной терминологии или концепций модели, уникальных для вашего домена. В свою очередь это может снизить потребность в обширном проектировании запросов или нескольких примерах.
После обработки и защиты
После того как LLM создает ответ, часто необходимо применить методы после обработки или охранники, чтобы обеспечить соответствие выходных данных требуемому формату, стилю и содержимому. Этот заключительный шаг (или несколько шагов) в цепочке может помочь обеспечить согласованность и качество в созданных ответах. Если вы реализуете постобработку и защиту, рассмотрите некоторые из следующих элементов:
- Применение формата выходных данных
- В зависимости от варианта использования может потребоваться, чтобы созданные ответы придерживались определенного формата, например структурированного шаблона или определенного типа файла (например, JSON, HTML, Markdown и т. д.).
- Если требуются структурированные выходные данные, библиотеки, такие как "Инструктор " или "Контуры ", предоставляют хорошие отправные точки для реализации такого типа шага проверки.
- При разработке потребуется время, чтобы убедиться, что шаг после обработки достаточно гибкий для обработки вариантов в созданных ответах при сохранении требуемого формата.
- Поддержание согласованности стиля
- Если в приложении RAG есть определенные рекомендации по стилю или требования к тону (например, формальные и случайные, краткие и подробные), шаг после обработки может проверять и применять эти атрибуты стиля в созданных ответах.
- Фильтры содержимого и средства защиты безопасности
- В зависимости от характера приложения RAG и потенциальных рисков, связанных с созданным содержимым, может быть важно реализовать фильтры содержимого или предохранители безопасности, чтобы предотвратить вывод неуместных, оскорбительных или вредных сведений.
- Рекомендуется использовать такие модели, как Llama Guard или API специально предназначенные для con режим палатки ration и безопасности, таких как API модерации OpenAI, для реализации предохранителей безопасности.
- Обработка галлюцинации
- Защита от галлюцинации также может быть реализована как этап после обработки. Это может включать перекрестную ссылку на созданные выходные данные с извлеченными документами или использование дополнительных LLM для проверки фактической точности ответа.
- Разработайте резервные механизмы для обработки случаев, когда сформированный ответ не соответствует требованиям фактической точности, таким как создание альтернативных ответов или предоставление отказов пользователю.
- Обработка ошибок
- При выполнении любых шагов после обработки реализуйте механизмы для корректной работы с случаями, когда шаг сталкивается с проблемой или не может создать удовлетворительный ответ. Это может быть связано с созданием ответа по умолчанию или эскалацией проблемы к оператору человека для ручной проверки.