Описание и обработка конвейера данных RAG
В этой статье вы узнаете о подготовке неструктурированных данных для использования в приложениях RAG. Неструктурированные данные ссылаются на данные без определенной структуры или организации, например PDF-документы, которые могут включать текст и изображения, или мультимедиа, например аудио или видео.
Неструктурированные данные не имеют предопределенной модели данных или схемы, делая невозможным выполнение запросов, опираясь только на структуру и метаданные. В результате неструктурированные данные требуют методов, которые могут понять и извлечь семантические значения из необработанного текста, изображений, аудио или другого содержимого.
Во время подготовки данных конвейер данных приложения RAG принимает необработанные неструктурированные данные и преобразует его в дискретные блоки, которые можно запрашивать на основе их релевантности к запросу пользователя. Ниже описаны основные этапы предварительной обработки данных. Каждый шаг имеет различные ручки, которые можно настроить - для подробного обсуждения этих ручек см. обзор качества.
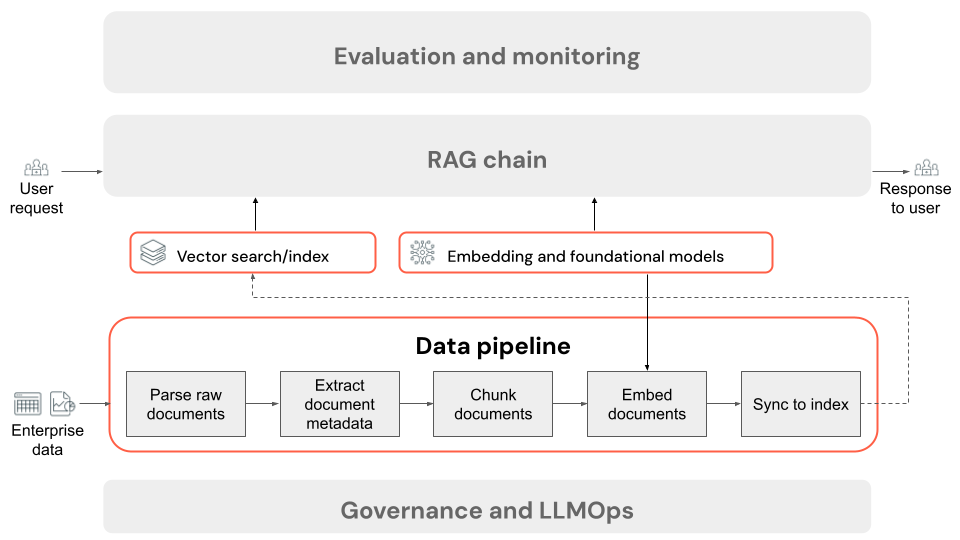
Подготовка неструктурированных данных для извлечения
В оставшейся части этого раздела мы описываем процесс подготовки неструктурированных данных для извлечения с помощью семантического поиска. Семантический поиск понимает контекстное значение и намерение запроса пользователя для предоставления более релевантных результатов поиска.
Семантический поиск — это один из нескольких подходов, которые можно использовать при реализации компонента извлечения приложения RAG через неструктурированные данные. В этих документах рассматриваются альтернативные стратегии извлечения в разделе настройки извлечения.
Шаги конвейера данных приложения RAG
Ниже приведены типичные шаги конвейера данных в приложении RAG с использованием неструктурированных данных:
- Анализ необработанных документов: начальный шаг включает преобразование необработанных данных в доступный формат. Это может включать извлечение текста, таблиц и изображений из коллекции PDF-файлов или использование методов оптического распознавания символов (OCR) для извлечения текста из изображений.
- Извлечение метаданных документа (необязательно). В некоторых случаях извлечение и использование метаданных документа, таких как заголовки документов, номера страниц, URL-адреса или другие сведения, могут более точно запрашивать правильные данные.
- документы блока. Чтобы обеспечить соответствие проанализированных документов модели внедрения и окне контекста LLM, мы разбиваем проанализированные документы на небольшие дискретные блоки. Получение этих концентрированных фрагментов, а не целых документов, дает LLM более целевой контекст, из которого можно генерировать ответы.
- Внедрение блоков. В приложении RAG, использующем семантический поиск, специальный тип языковой модели, называемый внедрением модели, преобразует каждый из блоков из предыдущего шага в числовые векторы или списки чисел, которые инкапсулируют значение каждого фрагмента содержимого. Важно, чтобы эти векторы представляли семантический смысл текста, а не только ключевых слов уровня поверхности. Это позволяет выполнять поиск на основе смысла, а не литеральных совпадений текста.
- Блоки индекса в векторной базе данных: последний шаг — загрузка векторных представлений блоков вместе с текстом блока в векторную базу данных. Векторная база данных — это специализированный тип базы данных, предназначенный для эффективного хранения и поиска векторных данных, таких как векторные представления. Для поддержания производительности при большом количестве блоков векторные базы данных обычно включают векторный индекс, который использует различные алгоритмы для упорядочивания и сопоставления векторных встраиваний с целью оптимизации эффективности поиска. Во время запроса запрос пользователя внедряется в вектор, а база данных использует векторный индекс для поиска наиболее похожих векторных векторов, возвращая соответствующие исходные блоки текста.
Процесс вычисления сходства может быть дорогостоящим. Векторные индексы, такие как Databricks Vector Search, ускоряют этот процесс, предоставляя механизм для эффективной организации и навигации по вложениям, часто с использованием сложных методов приближения. Это позволяет быстро ранжировать наиболее релевантные результаты без сравнения каждого внедрения к запросу пользователя по отдельности.
Каждый шаг в конвейере данных включает в себя инженерные решения, влияющие на качество приложения RAG. Например, выбор правильного размера блока на шаге 3 гарантирует, что LLM получает конкретную контекстную информацию, при выборе соответствующей модели внедрения на шаге 4 определяется точность блоков, возвращаемых во время извлечения.
Этот процесс подготовки данных называется автономным процессом подготовки данных, так как он происходит перед запросами системных ответов, в отличие от онлайн-шагов, инициируемых при отправке запроса пользователем.