Поиск векторов Mosaic AI
В этой статье представлен обзор решения векторной базы данных Databricks, Mosaic AI Vector Search, включая, что это такое и как это работает.
Что такое Mosaic AI Vector Search?
Mosaic AI Vector Search — это векторная база данных, встроенная в платформу Databricks для анализа данных и интегрированная с её средствами управления и повышения производительности. Векторная база данных — это база данных, оптимизированная для хранения и извлечения внедренных данных. Внедрение — это математические представления семантического содержимого данных, обычно текстовые или изображения. Внедрение создается большой языковой моделью и является ключевым компонентом многих создаваемых приложений ИИ, которые зависят от поиска документов или изображений, похожих друг на друга. Примерами являются системы RAG, системы рекомендаций, а также распознавание изображений и видео.
С помощью Mosaic AI Vector Search вы создаете векторный поисковый индекс из таблицы Delta. Индекс включает встроенные данные с метаданными. Затем можно запросить индекс с помощью REST API, чтобы определить наиболее похожие векторы и вернуть связанные документы. Индекс можно структурировать для автоматической синхронизации при обновлении базовой таблицы Delta.
Векторный поиск Mosaic AI поддерживает следующее:
- Гибридный поиск по подобию ключевых слов.
- Фильтрация.
- Списки управления доступом (ACL) для управления конечными точками поиска векторов.
- Синхронизировать только выбранные столбцы.
- Сохраните и синхронизируйте созданные эмбеддинги.
Как работает поиск векторов с помощью Mosaic AI?
Поиск векторов Mosaic AI использует алгоритм иерархически навигационного small world (HNSW) для определения приблизительных ближайших соседей и применяет метрику расстояния L2 для измерения сходства вложений векторов. Если вы хотите использовать сходство косинуса, необходимо нормализовать внедрение точек данных, прежде чем передавать их в векторный поиск. Когда точки данных нормализуются, ранжирование, созданное на расстоянии L2, совпадает с ранжированием, генерируемым косинусом сходства.
Поиск векторов Mosaic AI также поддерживает гибридный поиск с учетом схожести ключевых слов, который объединяет векторный поиск с традиционными технологиями поиска на основе ключевых слов. Этот подход соответствует точным словам в запросе, а также использует поиск сходства на основе векторов для отслеживания семантических связей и контекста запроса.
Интегрируя эти два метода, гибридный поиск по аналогии с ключевыми словами извлекает документы, содержащие не только точные ключевые слова, но и те, которые концептуально похожи, предоставляя более полные и соответствующие результаты поиска. Этот метод особенно полезен в приложениях RAG, где исходные данные имеют уникальные ключевые слова, такие как номера SKU или идентификаторы, которые не подходят для чистого поиска сходства.
Для получения дополнительных сведений об API см. справочник по SDK для Python и Запрос конечной точки векторного поиска.
Вычисление поиска сходства
Вычисление сходства использует следующую формулу:
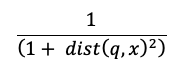
где dist — это расстояние между q запроса и записью индекса x:
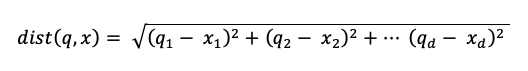
Алгоритм поиска ключевых слов
Оценки релевантности вычисляются с помощью Okapi BM25. Все текстовые или строковые столбцы, включая встраивание исходного текста и столбцы метаданных в текстовом или строковом формате, подвергаются поиску. Функция маркеризации разделяется по границам слова, удаляет знаки препинания и преобразует весь текст в нижний регистр.
Как объединяются поиск по подобия и поиск ключевых слов
Результаты поиска по подобию и поиска ключевых слов объединяются с помощью функции Reciprocal Rank Fusion (RRF).
RRF пересчитывает каждую оценку документов из каждого метода, используя новую оценку.
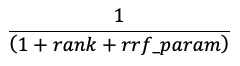
В приведенном выше уравнении ранг начинается с 0, суммирует оценки для каждого документа и возвращает документы с наивысшими оценками.
rrf_param определяет относительную важность более ранжированных и низкоранговых документов. Согласно литературе, rrf_param установлено равным 60.
Оценки нормализуются таким образом, чтобы самый высокий показатель равен 1, а наименьший показатель равен 0, используя следующее уравнение:
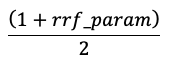
Варианты предоставления векторных вложений
Чтобы создать векторную базу данных в Databricks, необходимо сначала решить, как предоставить векторные представления. Databricks поддерживает три варианта:
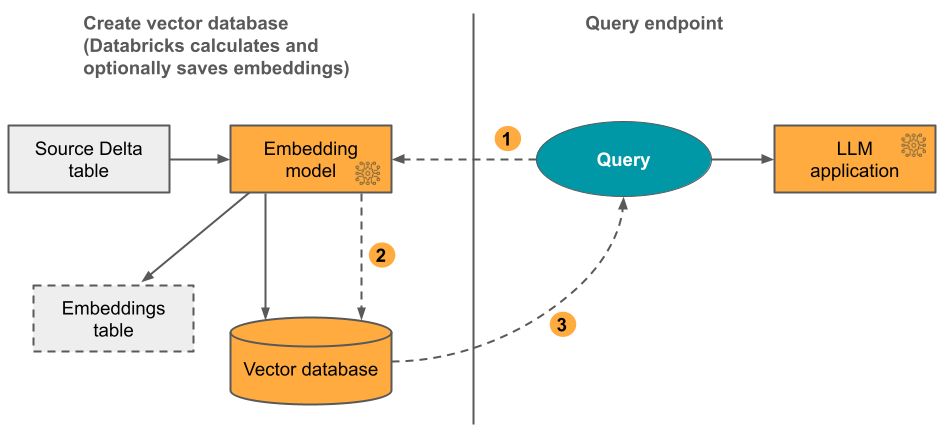
Вариант 1: Индекс разностной синхронизации с векторами, вычисленными с помощью Databricks Вы предоставляете исходную таблицу Delta, содержащую данные в текстовом формате. Databricks вычисляет встраиваемые представления с использованием заданной вами модели и при необходимости сохраняет их в таблицу в Unity Catalog. По мере обновления таблицы Delta индекс остается синхронизированным с таблицей Delta.
На схеме ниже показан соответствующий процесс:
- Вычисление векторных представлений запросов. Запрос может включать фильтры метаданных.
- Выполните поиск сходства, чтобы определить наиболее релевантные документы.
- Верните наиболее релевантные документы и добавьте их в запрос.
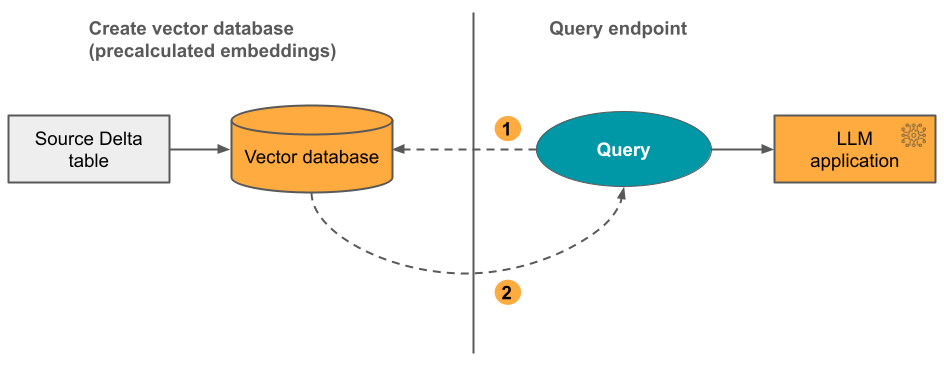
Вариант 2: Индекс Delta-синхронизации с самостоятельно управляемыми встраиваниями Вы предоставляете исходную таблицу Delta, содержащую предварительно вычисленные встраивания. По мере обновления таблицы Delta индекс остается синхронизированным с таблицей Delta.
На схеме ниже показан соответствующий процесс:
- Запрос состоит из внедрения и может включать фильтры метаданных.
- Выполните поиск сходства, чтобы определить наиболее релевантные документы. Верните наиболее релевантные документы и добавьте их в запрос.
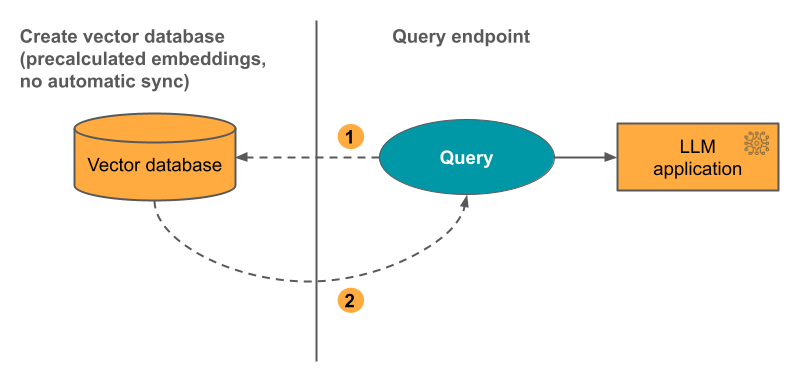
вариант 3. Индекс прямого векторного доступа необходимо вручную обновить с помощью REST API при изменении таблицы эмбеддингов.
На схеме ниже показан соответствующий процесс:
Настройка векторного поиска в Mosaic AI
Чтобы использовать Mosaic AI Vector Search, необходимо создать следующее:
Конечная точка векторного поиска. Эта конечная точка служит индексу векторного поиска. Вы можете запрашивать и обновлять конечную точку с помощью REST API или пакета SDK. Инструкции см. в статье "Создание конечной точки поиска вектора".
Конечные точки автоматически масштабируются, чтобы поддерживать размер индекса или количество одновременных запросов. Конечные точки не уменьшаются автоматически.
Индекс векторного поиска. Индекс векторного поиска создается из таблицы Delta и оптимизирован для предоставления приблизительного ближайшего соседского поиска в режиме реального времени. Цель поиска — определить документы, аналогичные запросу. Индексы векторного поиска отображаются и управляются каталогом Unity. Инструкции см. в статье "Создание индекса векторного поиска".
Кроме того, если вы решите вычислить векторные представления с помощью Databricks, можно использовать предварительно настроенную конечную точку API Foundation Model или создать конечную точку сервиса модели для сервиса модели векторных представлений по вашему выбору. См. API-интерфейсы базовой модели с оплатой за токен или Создание конечных точек обслуживания базовой модели для получения инструкций.
Чтобы запросить конечную точку обслуживания модели, используйте REST API или пакет SDK для Python. Запрос может определять фильтры на основе любого столбца в таблице Delta. Дополнительные сведения см. в разделе "Использование фильтров по запросам", справочнику по API или справочнику по пакету SDK для Python.
Требования
- Рабочая область с активированным каталогом Unity.
- Бессерверные вычисления включены. Инструкции см. в разделе "Подключение к бессерверным вычислениям".
- На исходной таблице должен быть включен поток изменений данных. См. раздел "Использование потока данных изменений Delta Lake" в Azure Databricks.
- Чтобы создать индекс векторного поиска, необходимо иметь CREATE TABLE привилегии в схеме каталога, в которой будет создан индекс.
Разрешение на создание конечных точек поиска векторов и управление ими настраивается с помощью списков управления доступом. См. ACL для векторного поиска.
защита данных и проверка подлинности
Databricks реализует следующие элементы управления безопасностью для защиты данных:
- Каждый запрос клиента к поиску векторов ИИ Мозаики логически изолирован, аутентифицирован и авторизован.
- Поиск вектора мозаики шифрует все данные в состоянии покоя (AES-256) и во время передачи (TLS 1.2+).
Векторный поиск мозаики ИИ поддерживает два режима проверки подлинности:
Токен учетной записи службы. Администратор может создать токен служебного принципала и использовать его в SDK или API. См. использование служебных принципалов. Для производственных сценариев использования Databricks рекомендует использовать токен служебного принципала.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Личный маркер доступа. Вы можете использовать персональный токен доступа для аутентификации с помощью векторного поиска Mosaic AI. См. токен аутентификации личного доступа. Если вы используете пакет SDK в среде записной книжки, пакет SDK автоматически создает маркер PAT для проверки подлинности.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
Управляемые клиентом ключи (CMK) поддерживаются в конечных точках, созданных 8 мая 2024 г. или после 8 мая 2024 г.
Отслеживание использования и затрат
Оплачиваемая система использования позволяет отслеживать использование и затраты, связанные с индексами и конечными точками векторного поиска. Вот пример запроса:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Дополнительные сведения о содержимом таблицы использования выставляемых счетов см. в справочнике по системным таблицам . Дополнительные запросы приведены в следующем примере записной книжки.
Векторный поиск системных таблиц запрашивает записную книжку
Ограничения размера ресурсов и данных
В следующей таблице перечислены ограничения размера ресурсов и данных для конечных точек и индексов векторного поиска:
| Ресурс | Степень детализации | Предел |
|---|---|---|
| Конечные точки поиска векторов | На рабочую область | 100 |
| Встраивания | Для каждой конечной точки | триста двадцать миллионов |
| Измерение внедрения | По индексу | 4096 |
| Индексы | Для каждой конечной точки | 50 |
| Столбцы | На каждый индекс | 50 |
| Столбцы | Поддерживаемые типы: Байт, короткое, целое число, длинное, плавающее, двойное, логическое значение, строка, метка времени, дата | |
| Поля метаданных | За индекс | 50 |
| Имя индекса | На единицу индекса | 128 символов |
Следующие ограничения применяются к созданию и обновлению индексов векторного поиска:
| Ресурс | Степень детализации | Предел |
|---|---|---|
| Размер строки для индекса Дельта-синхронизации | По индексу | 100 КБ |
| Внедрение размера исходного столбца для индекса Delta Sync | По индексу | 32764 байта |
| Ограничение на размер запроса массового upsert для индекса Direct Vector | По индексу | 10 МБ |
| Ограничение размера запроса массового удаления для индекса Direct Vector | За индекс | 10 МБ |
Следующие ограничения применяются к API запросов.
| Ресурс | Степень детализации | Предел |
|---|---|---|
| Длина текста запроса | За каждый запрос | 32764 байта |
| Максимальное количество возвращаемых результатов | Для каждого запроса | 10 000 |
Ограничение
Разрешения на уровне строк и столбцов не поддерживаются. Однако вы можете реализовать собственные списки управления доступом на уровне приложения с помощью API фильтра.